
Bei kritischen Problemen in der Cloud-Infrastruktur zählt jede Sekunde. Sie brauchen schnelle und präzise Hilfe. Doch auch ohne Zeitdruck wollen Sie keine wertvolle Zeit mit langen Formularen verlieren – Sie wollen Ihr Problem schildern, der Rest soll von allein laufen.
Die Herausforderung: KI-gestützten Support reaktionsschneller und interaktiver machen
Bei DoiT haben wir Ava, die Sie bei FinOps- und Cloud-Fragen unterstützt. Manchmal möchten Sie eine Sache aber direkt mit einem menschlichen Experten besprechen. Genau hier setzt unser Case IQ-System an: Es hilft Kunden, beim Anlegen eines Tickets gleich die richtigen technischen Details mitzuliefern, damit unsere Customer Reliability Engineers (CREs) alles zur Hand haben, um Probleme schnell zu lösen.
Die Idee entstand bei unserem Hackathon im Sommer 2024 und basierte ursprünglich auf OpenAI-APIs. Wir wollten uns mit dem Status quo aber nicht zufriedengeben, sondern besonders die Latenz unserer Empfehlungen drücken – damit sich das System spürbar reaktionsschneller und interaktiver anfühlt.
Das Experiment: fünf Modelle im Vergleich – Latenz, Kosten und Performance
Dazu haben wir ein zweiwöchiges, umfassendes Experiment aufgesetzt und unser aktuelles Modell (OpenAIs GPT-4o) mit vier Alternativen verglichen:
- GPT-4.1 mini (das neuere, schnellere Modell von OpenAI)
- Llama 3.1 8B (kleineres, ultraschnelles Modell auf der spezialisierten Hardware von Groq)
- Llama 3.3 70B (größeres, leistungsfähigeres Modell auf Groq)
- Llama 4 Scout 17B (Preview-Modell aus Metas neuester Modellfamilie mit vielversprechenden Fähigkeiten)
Das Hauptziel: ein Modell finden, das niedrigere Latenzen liefert als die GPT-4o-Baseline. Einen (kleinen) Abstrich bei der Antwortqualität hatten wir einkalkuliert – etwaige Kosteneinsparungen waren ein willkommener Nebeneffekt.
Wir haben die Modelle bei fünf Aufgaben getestet, die Case IQ beim Anlegen eines Vorgangs ausführt:
- Plattform-Erkennung: Auf welche konkrete Plattform bezieht sich die Anfrage?
- Produkt-Identifikation: Welcher Cloud-Dienst ist betroffen?
- Schweregrad-Bewertung: Wie dringend ist das Problem?
- Asset-Identifikation: Welches Projekt oder Konto ist betroffen?
- Extraktion technischer Details: Welche konkreten Informationen brauchen unsere Engineers?
In zwei Wochen haben wir 21.517 Traces aus 755 echten Kundenvorgängen verarbeitet und dabei Latenz, Kosten und Genauigkeit gemessen.
Die technische Grundlage, die diesen Vergleich so einfach machte, war unsere bestehende LangChain-Integration. Da wir LangChain bereits für unsere GPT-4o-Implementierung nutzten, ließen sich die Vergleichsmodelle unkompliziert anbinden: Wir ergänzten ChatGroq-Aufrufe parallel zu unserer bestehenden ChatOpenAI-Integration und ließen sie asynchron laufen, um unser Produktivsystem nicht zu beeinträchtigen.
Für die umfassende Instrumentierung haben wir LangSmith eingesetzt – damit erfassen wir automatisch Latenzmessungen, Token-Verbrauch, Fehlerraten sowie Input-/Output-Logs über alle Traces hinweg.
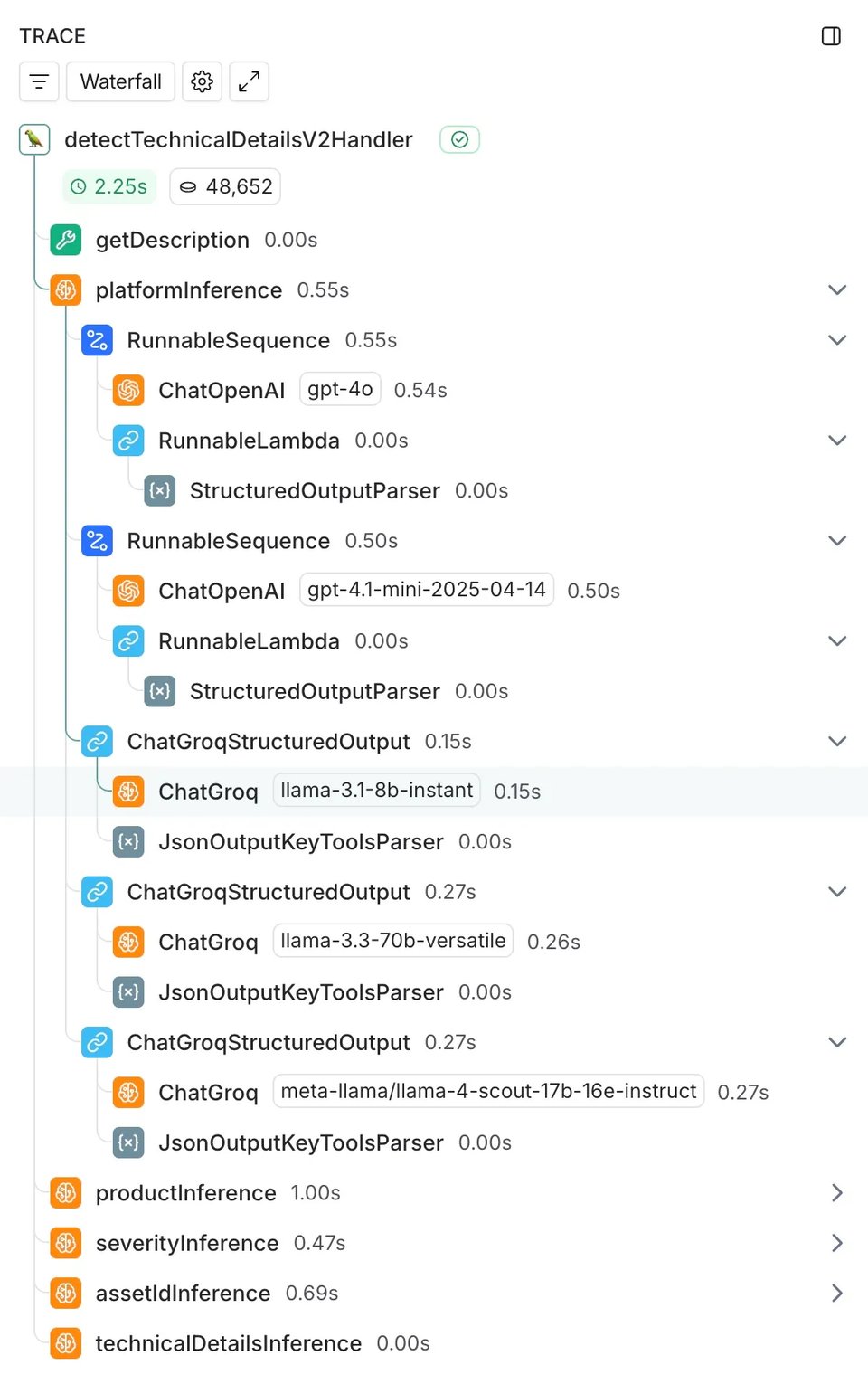
Die Ergebnisse: deutlich mehr Tempo bei minimalen Qualitätseinbußen
Die Ergebnisse haben unsere Erwartungen übertroffen:
⚡ 4–5x schneller
- Plattform-Erkennung: 571ms → 249ms (4,1x schneller, mit Llama 3.3 70B)
- Produkt-Erkennung: 851ms → 406ms (2,1x schneller, mit Llama 3.1 8B)
- Schweregrad-Erkennung: 605ms → 126ms (2,6x schneller, mit Llama 3.3 70B)
- Asset-Erkennung: 593ms → 220ms (2,7x schneller, mit Llama 3.3 70B)
- Extraktion technischer Details: 1.914ms → 334ms (5,7x schneller, mit Llama 3.1 8B)
💰 Bis zu 50x niedrigere Kosten
Tempo stand im Vordergrund – doch die Kosteneinsparungen waren bemerkenswert: Manche Aufgaben laufen jetzt zu einem Fünfzigstel der Kosten, und das ohne Qualitätsverlust.
🎯 Performance auf hohem Niveau
Eine manuelle Auswertung echter Kundenvorgänge zeigte: Während GPT-4o eine Genauigkeit von 92–96 % erreichte, hielten unsere schnelleren Alternativen klar mit:
- Llama 3.3 70B: 88–96 % Genauigkeit bei 2–3x Tempogewinn
- Llama 3.1 8B: 55–88 % Genauigkeit bei 4–5x Tempogewinn
Die Gewinnerstrategie: ein hybrider Ansatz
Statt uns auf ein einziges "bestes" Modell festzulegen, kamen wir zu dem Schluss, dass eine insgesamt optimale Lösung mehrere Modelle braucht:
- Llama 3.1 8B für Produkt- und technische Detail-Erkennung (da diese Aufgaben voneinander abhängen, zählt hier vor allem Tempo)
- Llama 3.3 70B für Plattform- und Schweregrad-Erkennung sowie Asset-Identifikation (Llama 3.1 8B tat sich hier schwerer – wobei wir noch Optimierungspotenzial durch besseres Prompting sehen)
Das Ergebnis? Die Gesamt-Antwortzeit sinkt von über 3 Sekunden auf unter 1 Sekunde – also 3–4x schneller insgesamt. Hinzu kommt: Mit diesem hybriden Ansatz erwarten wir Kosteneinsparungen von rund 93 % auf unsere Gesamtrechnung.
Was das für Sie bedeutet
⚡ Antworten nahezu in Echtzeit: Wenn Sie Ihr Problem in der Cloud-Infrastruktur schildern, analysiert CaseIQ es jetzt fast augenblicklich und fragt direkt die passenden technischen Details ab.
🔄 Support-Kanäle in Echtzeit: Die Tempogewinne eröffnen neue Möglichkeiten. Wir prüfen, Support direkt in Slack oder anderen Messaging-Plattformen anzubieten – dort, wo unsere Kunden ohnehin unterwegs sind.
🚀 Bessere First-Time-Resolution: Präzisere und vollständigere Problembeschreibungen für unsere Spezialisten bedeuten schnellere Reaktionszeiten und weniger Hin und Her.
Fazit und Ausblick
Die vollständigen technischen Details haben ihren eigenen Reiz (und sind hier verfügbar) – die zentralen Erkenntnisse lassen sich aber in zwei Punkten zusammenfassen:
- Strategische Modellauswahl zahlt sich aus: Eine durchdachte Wahl von Anbieter und Modell, kombiniert mit klugen Architekturentscheidungen, bringt dramatische Latenzverbesserungen (von über 3 Sekunden in den Sub-Sekundenbereich) – mit massiven Kosteneinsparungen als Bonus.
- An menschlicher Bewertung führt kein Weg vorbei: Automatisierte Metriken liefern eine nützliche Basis, doch wenn es um Texte und Menschen geht, bleibt die manuelle Prüfung unverzichtbar, um die tatsächliche Performance zu verstehen. Es gibt immer Nuancen, die nur Menschen wirklich beurteilen können.
Bei DoiT leben wir den Anspruch "powered by technology, perfected by people". Diese Verbesserungen sorgen dafür, dass unsere KI die Vorarbeit bereits geleistet hat, wenn Sie die menschliche Expertise unserer CREs benötigen – damit Sie Ihre Antworten so schnell wie möglich bekommen.
—
Möchten Sie das verbesserte Case IQ selbst erleben? Sprechen Sie noch heute mit uns und erfahren Sie, wie wir Sie unterstützen.