
Quando un problema critico colpisce l'infrastruttura cloud, ogni secondo conta. Serve un aiuto rapido e preciso. Ma anche senza fretta, nessuno vuole perdere tempo a compilare moduli interminabili: si vuole descrivere il problema e lasciare che del resto si occupi qualcun altro.
La sfida: un supporto AI più reattivo e interattivo
In DoiT c'è Ava, che La assiste sulle domande di FinOps e cloud. A volte, però, è meglio confrontarsi con un esperto in carne e ossa. È qui che entra in gioco il nostro sistema Case IQ: aiuta i clienti a fornire i dettagli tecnici corretti all'apertura di un ticket e mette i nostri Customer Reliability Engineer (CRE) nelle condizioni di risolvere i problemi rapidamente.
L'idea è nata durante il nostro hackathon dell'estate 2024, costruita sulle API di OpenAI. Abbiamo però deciso di alzare l'asticella, lavorando sulla latenza dei suggerimenti per rendere il sistema più scattante e interattivo.
L'esperimento: cinque modelli a confronto su latenza, costo e prestazioni
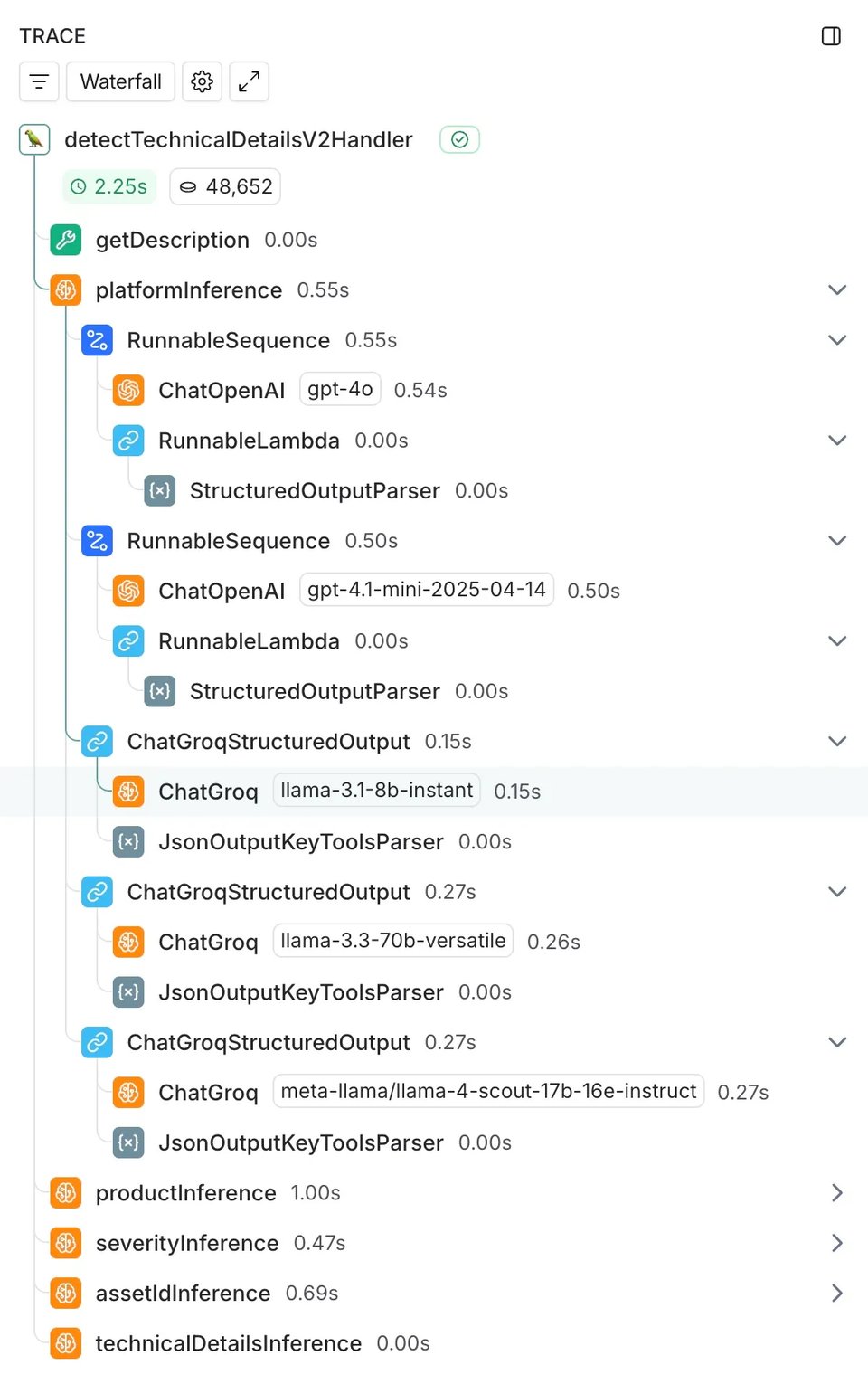
Per affrontare il tema, abbiamo progettato un esperimento di 2 settimane mettendo a confronto il modello attualmente in uso (GPT-4o di OpenAI) con quattro alternative:
- GPT-4.1 mini (il modello più recente e veloce di OpenAI)
- Llama 3.1 8B (modello più compatto e ultra-rapido sull'hardware specializzato di Groq)
- Llama 3.3 70B (modello più grande e performante su Groq)
- Llama 4 Scout 17B (modello in preview dell'ultima famiglia di Meta, con capacità promettenti)
L'obiettivo principale era trovare un modello con latenze inferiori rispetto al baseline di GPT-4o. Mettevamo in conto un (piccolo) calo nella qualità delle risposte pur di ottenere questo risultato, considerando l'eventuale taglio dei costi come un piacevole effetto collaterale.
Abbiamo testato i modelli su cinque attività che Case IQ esegue alla creazione di un'interazione:
- Rilevamento della piattaforma: a quale piattaforma specifica si riferisce la richiesta
- Identificazione del prodotto: quale servizio cloud necessita di assistenza?
- Valutazione della gravità: quanto è urgente il problema?
- Identificazione dell'asset: quale progetto o account è coinvolto?
- Estrazione dei dettagli tecnici: quali informazioni servono ai nostri Engineer?
In due settimane abbiamo elaborato 21.517 trace su 755 interazioni reali con i clienti, misurando latenza, costo e accuratezza.
A semplificare il confronto è stata la nostra integrazione già attiva con LangChain. Visto che la stavamo già usando per l'implementazione di GPT-4o, aggiungere i modelli di confronto è stato immediato: abbiamo affiancato chiamate ChatGroq all'integrazione ChatOpenAI esistente, eseguendole in modo asincrono per non avere impatti sull'ambiente di produzione.
Per la strumentazione ci siamo affidati a LangSmith, che cattura automaticamente latenza, utilizzo dei token, tassi di errore e log di input/output su tutti i trace.
I risultati: più velocità a fronte di un piccolo compromesso sulla qualità
I risultati hanno superato le aspettative:
⚡ Velocità da 4 a 5 volte superiore
- Rilevamento piattaforma: 571ms → 249ms (4,1 volte più veloce, con Llama 3.3 70B)
- Rilevamento prodotto: 851ms → 406ms (2,1 volte più veloce, con Llama 3.1 8B)
- Rilevamento gravità: 605ms → 126ms (2,6 volte più veloce, con Llama 3.3 70B)
- Rilevamento asset: 593ms → 220ms (2,7 volte più veloce, con Llama 3.3 70B)
- Estrazione dettagli tecnici: 1.914ms → 334ms (5,7 volte più veloce, con Llama 3.1 8B)
💰 Costi ridotti fino a 50 volte
Anche se la velocità era l'obiettivo principale, il risparmio sui costi è stato sorprendente: alcune attività sono diventate 50 volte più economiche da eseguire, mantenendo intatta la qualità.
🎯 Prestazioni in linea
Dalla revisione manuale di interazioni reali con i clienti è emerso che, a fronte di un'accuratezza del 92–96% di GPT-4o, le alternative più rapide hanno mantenuto prestazioni solide:
- Llama 3.3 70B: accuratezza dell'88–96% con velocità da 2 a 3 volte superiore
- Llama 3.1 8B: accuratezza del 55–88% con velocità da 4 a 5 volte superiore
La strategia vincente: un approccio ibrido
Anziché scegliere un singolo modello "migliore", siamo arrivati alla conclusione che la soluzione ottimale richiedesse modelli diversi:
- Llama 3.1 8B per il rilevamento di prodotto e dettagli tecnici (essendo attività interdipendenti, è qui che la velocità conta di più)
- Llama 3.3 70B per rilevamento di piattaforma, gravità e identificazione dell'asset (Llama 3.1 8B sembrava avere difficoltà su questo fronte, anche se riteniamo ci sia margine di ottimizzazione lavorando sui prompt)
Il risultato? Il tempo totale di risposta scende da oltre 3 secondi a meno di 1 secondo: una velocità complessiva da 3 a 4 volte superiore. In più, con questo approccio ibrido prevediamo un risparmio sui costi di circa il 93% sulla spesa totale.
Cosa significa per Lei
⚡ Risposte quasi istantanee: quando descrive un problema della Sua infrastruttura cloud, CaseIQ può ora analizzarlo e richiedere i dettagli tecnici corretti quasi all'istante.
🔄 Canali di supporto in tempo reale: questi guadagni di velocità aprono nuove possibilità. Stiamo valutando di portare il supporto direttamente su Slack e su altre piattaforme di messaggistica già usate dai nostri clienti.
🚀 Migliore risoluzione al primo contatto: descrizioni dei problemi più accurate e complete per i nostri specialisti significano tempi di risposta più rapidi e meno scambi avanti e indietro.
Conclusioni e prossimi passi
Tutti i dettagli tecnici sono affascinanti (e li trova qui), ma il vero apprendimento è duplice:
- La selezione strategica dei modelli funziona: una scelta accurata di provider e modello, unita a decisioni architetturali intelligenti, può portare a miglioramenti drastici della latenza (da oltre 3 secondi al sotto-secondo) e, in più, a riduzioni di costo significative.
- La valutazione umana è insostituibile: le metriche automatizzate offrono baseline utili, ma la revisione manuale resta essenziale per capire le prestazioni reali quando si ha a che fare con testo e persone; ci sono sempre sfumature che solo l'occhio umano sa cogliere.
In DoiT crediamo nel principio "powered by technology, perfected by people". Questi miglioramenti garantiscono che, quando ha bisogno dell'expertise umana dei nostri CRE, la nostra AI abbia già fatto il lavoro preliminare per arrivare alle risposte nel minor tempo possibile.
—
Vuole provare con mano il nuovo Case IQ? Ci contatti oggi stesso e scopra come possiamo aiutarLa.