Quels services utiliser pour le data warehousing et l'analytique sur GCP / AWS ?

Pour y répondre, il faut aller au-delà d'une simple comparaison de fonctionnalités. Cela impose d'examiner en détail les modèles tarifaires nuancés des systèmes DWH ainsi que les nombreux services cloud dont ils dépendent.
Si la comparaison fonctionnelle entre les offres peut être directe, la comparaison tarifaire est nettement plus complexe pour deux raisons principales :
- Plusieurs services cloud interviennent pour préparer et charger les données dans le DWH. Chacun engendre un coût généralement non négligeable, qui s'ajoute à celui du DWH.
- Évaluer le coût d'un DWH en lui-même suppose de prendre en compte à la fois le volume de données stockées et les méthodes ainsi que la fréquence des requêtes exécutées sur ces données. Différents types de requêtes et fréquences d'exécution génèrent des coûts très variables selon le DWH utilisé et le modèle tarifaire choisi.
Pour mieux répondre à cette question récurrente des clients cloud cherchant à opérer efficacement à grande échelle, vous trouverez ci-dessous un comparatif détaillé des coûts de bout en bout des options de data warehousing sur GCP et AWS. Nous examinerons donc le coût :
- De la récupération de jeux de données volumineux, de plusieurs téraoctets, utilisés dans des applications réelles de génomique
- Des transformations de données qui facilitent leur chargement dans un data warehouse
- De l'exécution de 17 requêtes complexes produisant des résultats utiles
(plutôt que, par exemple, l'exécution de requêtes de benchmark simples et arbitraires)
Bien que le coût global des opérations de data warehousing soit le sujet principal de cet article, je ferai également des comparaisons fonctionnelles pour étoffer la discussion et proposer un guide complet de sélection d'un data warehouse.
Si vous souhaitez reproduire les calculs de coûts présentés ici, consultez le repo Git associé à cet article : il rend la reproduction de mes benchmarks aussi simple et automatisée que possible.
Par ailleurs, si vous avez des questions sur la manière dont les coûts ont été calculés au fil de votre lecture, reportez-vous à l'annexe pour plus de détails.
Cela posé, entrons dans le vif du sujet !
Plutôt que de noyer l'essentiel, je préfère présenter d'emblée mes recommandations issues des benchmarks pour le choix d'un data warehouse.
Si vous vous concentrez uniquement sur l'efficacité tarifaire, sans considération pour les fonctionnalités à valeur ajoutée, je recommande les services suivants, classés du moins coûteux au plus coûteux :
- AWS Athena avec AWS Glue Data Catalog (le moins cher)
- AWS EMR avec AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc avec GCP Dataproc Metastore
- AWS Redshift (le plus cher)
Si vous accordez plus d'importance aux fonctionnalités à valeur ajoutée, je recommande les produits selon le classement suivant, qui pondère les fonctionnalités par rapport au coût :
- GCP BigQuery (l'option DWH qui apporte le plus de valeur)
- AWS Athena avec AWS Glue Data Catalog
- AWS EMR avec AWS Glue Data Catalog
- GCP Dataproc avec GCP Dataproc Metastore
- AWS Redshift (l'option DWH qui apporte le moins de valeur)
Poursuivez votre lecture pour mieux comprendre les raisons de ces recommandations.
Partie 1 : acquisition et transformation des données
Pour simuler au plus près des opérations réalistes à l'échelle du téraoctet, je travaillerai avec des données du génome humain : ce domaine se situe par nature à l'échelle de plusieurs téraoctets et présente souvent des défis spécifiques pour atteindre une analytique économiquement efficace.
Je resterai à l'écart du jargon génomique pour rester accessible. Pour les lecteurs intéressés par les workloads scientifiques scalables, le repo Git de ce blog propose des exemples détaillés et reproductibles pour mettre en œuvre des workloads de génomique de manière économique.
Je travaillerai spécifiquement avec les deux jeux de données suivants, qui se résument ainsi pour un public non spécialiste de la génomique :
- gnomAD genomes v4.0 : gnomAD est couramment utilisé en recherche génomique, car il contient des données de fréquence populationnelle sur les mutations identifiées à partir des données de séquençage du génome entier de 807 162 individus. Ces fréquences servent notamment à repérer les mutations rares qui, du fait de leur rareté, sont plus susceptibles d'avoir une signification clinique.
- Par exemple : une mutation présentant une fréquence populationnelle de 25 % se retrouve chez 25 % de la population humaine globale. Une mutation aussi commune a beaucoup moins de chances d'avoir un impact clinique sur un individu qu'une mutation rare (rare en raison de la pression évolutive qui s'exerce contre elle) qui n'apparaît que chez 0,01 % de la population humaine.
- Au format fichier plat, gnomAD v4.0, une fois bgzippé, pèse environ 830 Go.
- dbNSFP v4.6 : un autre jeu de données volumineux utilisé dans la recherche sur le génome humain. dbNSFP rassemble — dans un fichier unique — des dizaines de prédictions d'impact fonctionnel et d'annotations pour toutes les mutations du génome humain en unifiant les données de plusieurs dizaines de bases. L'étendue et la profondeur des données de dbNSFP aident les cliniciens à évaluer l'impact clinique des mutations.
- Au format fichier plat, dbNSFP non compressé pèse environ 250 Go.
gnomAD et dbNSFP sont tous deux des ressources cruciales en médecine de précision.
gnomAD est hébergé à la fois sur des buckets S3 et GCS, et dbNSFP sur S3, ce qui rend la récupération de ces jeux de données dans des comptes cloud relativement simple. Cependant, l'un comme l'autre sont stockés dans des formats de fichiers plats conçus pour des chercheurs qui les explorent avec des outils bioinformatiques académiques peu scalables. gnomAD, en particulier, est stocké dans un format de fichier plat bioinformatique spécialisé (VCF bgzippé) qui n'est ni idéal pour l'analytique à grande échelle, ni un format standard accepté par les DWH.
La première étape de notre exploration des coûts DWH consiste donc à récupérer gnomAD et dbNSFP, puis à transformer leurs énormes fichiers plats dans un format adapté aux data warehouses : Parquet.
L'un des outils les plus rentables pour manipuler de gros fichiers plats est Apache Spark. Spark est d'ailleurs l'un des outils les plus économiques pour l'analytique sur n'importe quel jeu de données volumineux, en particulier avec des fichiers Parquet en entrée. Spark est non seulement souvent un composant clé du data pipelining à grande échelle, mais il peut même servir de DWH lorsqu'il exécute des analytiques sur des fichiers Parquet stockés dans un bucket.
Cela posé, examinons d'abord le coût d'exécution d'une étape de préparation des données basée sur Spark.
Le graphique ci-dessous illustre les coûts liés à la conversion des deux sources de données depuis des fichiers plats vers Parquet, à leur jointure et à l'écriture du fichier fusionné en Parquet, au provisionnement d'un metastore Hive pour gérer les métadonnées Parquet, ainsi qu'au stockage de tous les fichiers Parquet dans un bucket :
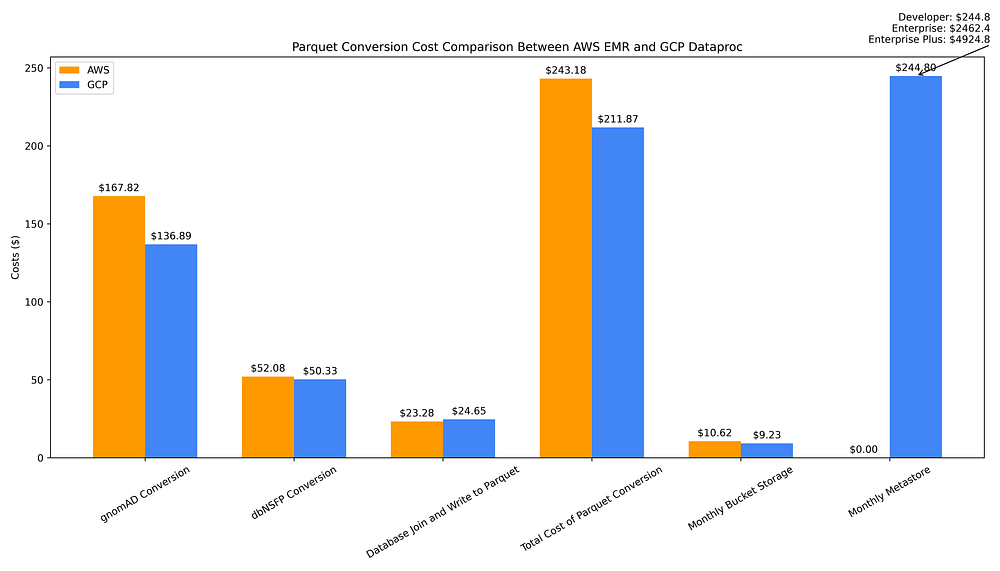
Comparaison des coûts de data warehousing GCP vs AWS pour la conversion de fichiers plats vers Parquet, le stockage Parquet et la création d'un metastore Hive
Le coût total ponctuel de la conversion des fichiers plats des deux bases de données en Parquet, puis de leur jointure dans un fichier Parquet fusionné, est globalement légèrement moins élevé avec GCP Dataproc (211,87 $) qu'avec AWS EMR (243,18 $). Cela s'explique par la surcharge tarifaire élevée appliquée par EMR aux machines Graviton de 7e génération, telles que les instances Spot r7g.16xlarge.
Le coût de stockage des fichiers Parquet de sortie dans des buckets régionaux est comparable d'un cloud à l'autre — vous n'économisez que 1,39 $ par mois en stockant les données Parquet de sortie sur un bucket GCS (9,23 $) plutôt que sur S3 (10,62 $).
En revanche, les coûts opérationnels à long terme liés à l'utilisation de ces fichiers Parquet sont nettement plus élevés sur GCP : son service de stockage de métadonnées entièrement managé est facturé à l'heure, alors qu'il est essentiellement gratuit sur AWS via Glue Data Catalog, du moins jusqu'à atteindre une utilisation à grande échelle.
Avec Glue Data Catalog, il faut dépasser 1 million d'objets stockés pour commencer à payer une somme dérisoire de 1 $ pour 100 000 objets stockés par mois au-delà du palier gratuit d'1 million d'objets. Les requêtes vers Data Catalog sont également gratuites jusqu'à 1 million de requêtes, après quoi vous n'êtes facturé que 1 $ par million de requêtes au-delà d'1 million par mois.
À comparer avec ce metastore AWS, dont le coût va de gratuit à insignifiant, le coût mensuel de 245 $ de Dataproc Metastore. Ce coût Dataproc suppose l'utilisation du tier Developer, qui présente une scalabilité limitée et aucune tolérance aux pannes. Pour de l'analytique à plus grande échelle, il faudrait passer au tier Enterprise, scalable et tolérant aux pannes, dont le coût mensuel s'élève à 2 462 $. Il existe en outre un tier Enterprise Plus, peu documenté, qui double ce coût mensuel à 4 924 $ (des échanges avec un PM GCP indiquent que Plus signifie obtenir une configuration en haute disponibilité).
Ainsi, bien que les coûts ponctuels de conversion des données et de création de métadonnées soient légèrement plus élevés sur AWS, et que les coûts de stockage à long terme soient à peu près équivalents, pour l'utilisation des fichiers Parquet comme data warehouse, AWS l'emporte grâce au coût négligeable de son metastore Parquet. Un metastore Hive est essentiel à la fois pour améliorer l'efficacité tarifaire des requêtes sur les fichiers Parquet et pour rendre leur accès plus simple et plus pratique — par exemple, en permettant de les requêter via des noms de tables plutôt qu'en interrogeant directement le chemin du fichier — c'est pourquoi je le considère comme un composant indispensable d'un data warehouse adossé à Parquet.
Partie 2 : le coût de 17 requêtes analytiques complexes
Nous avons comparé le coût de la transformation de téraoctets de fichiers plats au format Parquet ainsi que celui de l'hébergement d'un metastore pour ces fichiers, afin d'accélérer les temps d'exécution des requêtes. Examinons à présent le coût d'exécution des requêtes sur ces jeux de données via plusieurs services de data warehouse cloud.
Un récapitulatif des 17 requêtes exécutées sur chaque DWH est fourni en annexe pour souligner leur complexité. Pour les lecteurs orientés génomique, des explications détaillées supplémentaires sont disponibles via les commentaires des fichiers de code.
Option 1 : clusters Spark éphémères en guise de data warehouse
Commençons par supposer que notre data warehouse se compose de clusters Spark éphémères interrogeant des fichiers Parquet stockés dans un bucket :
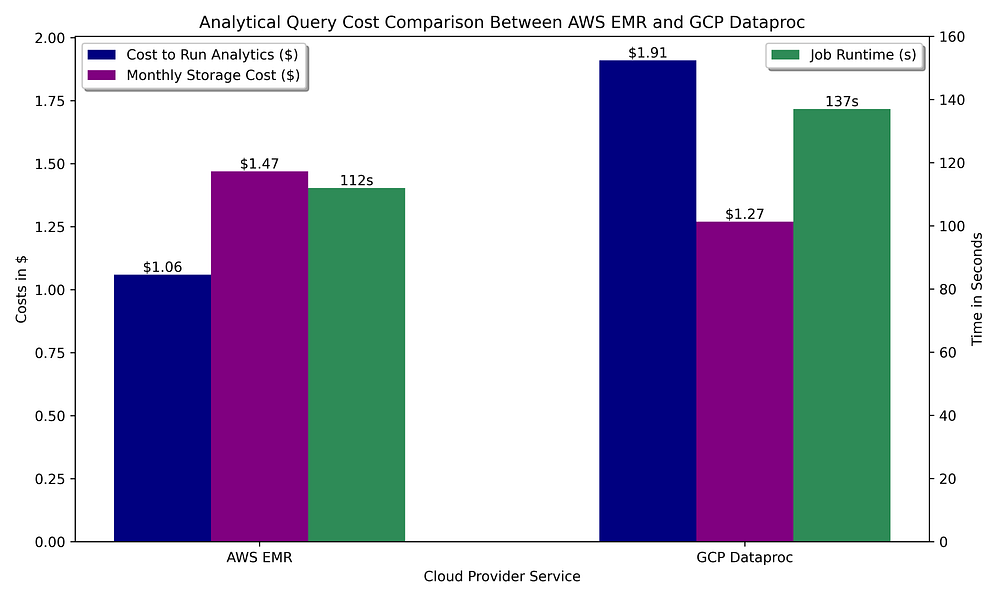
Comparaison des coûts de data warehousing GCP vs AWS pour l'exécution de requêtes OLAP avec Apache Spark et le stockage Parquet du jeu de données interrogé
Comme pour l'étape de préparation des données via Spark, l'exécution d'analytiques sur les offres Spark managées présente un coût similaire dans les deux clouds. Dans ce cas, AWS l'emporte sur GCP grâce à la configuration d'auto-terminaison à l'inactivité d'EMR, qui peut descendre jusqu'à 60 secondes d'inactivité avant de terminer le cluster, alors que celle de Dataproc ne peut descendre qu'à 5 minutes. Comme ces requêtes ne nécessitent pas beaucoup de temps pour s'exécuter, le délai d'inactivité minimal supporté avant la terminaison du cluster joue en défaveur de GCP.
Les fonctionnalités Spark sont identiques dans chaque cloud, donc aucun cloud ne dispose d'un véritable avantage fonctionnel. Avec une exécution moins coûteuse et plus rapide d'EMR sur des clusters de courte durée et un metastore gratuit, à opposer au coût élevé d'hébergement d'un metastore Hive sur GCP, l'analytique basée sur Spark penche fortement en faveur d'AWS.
Option 2 : offres DWH serverless
Et si l'on remplaçait Spark comme DWH par un service de data warehouse entièrement managé et serverless du fournisseur cloud — où les requêtes peuvent s'exécuter uniquement en SQL — afin d'éviter d'écrire du code Spark ?
Vous trouverez ci-dessous une comparaison des coûts du data warehousing AWS via Athena et Redshift Serverless face à GCP BigQuery on-demand. Les mêmes 17 requêtes OLAP utilisées à l'étape 2 Option 1 sont employées pour ces DWH. C'est avec cette comparaison que l'efficacité tarifaire des options DWH apparaît clairement :
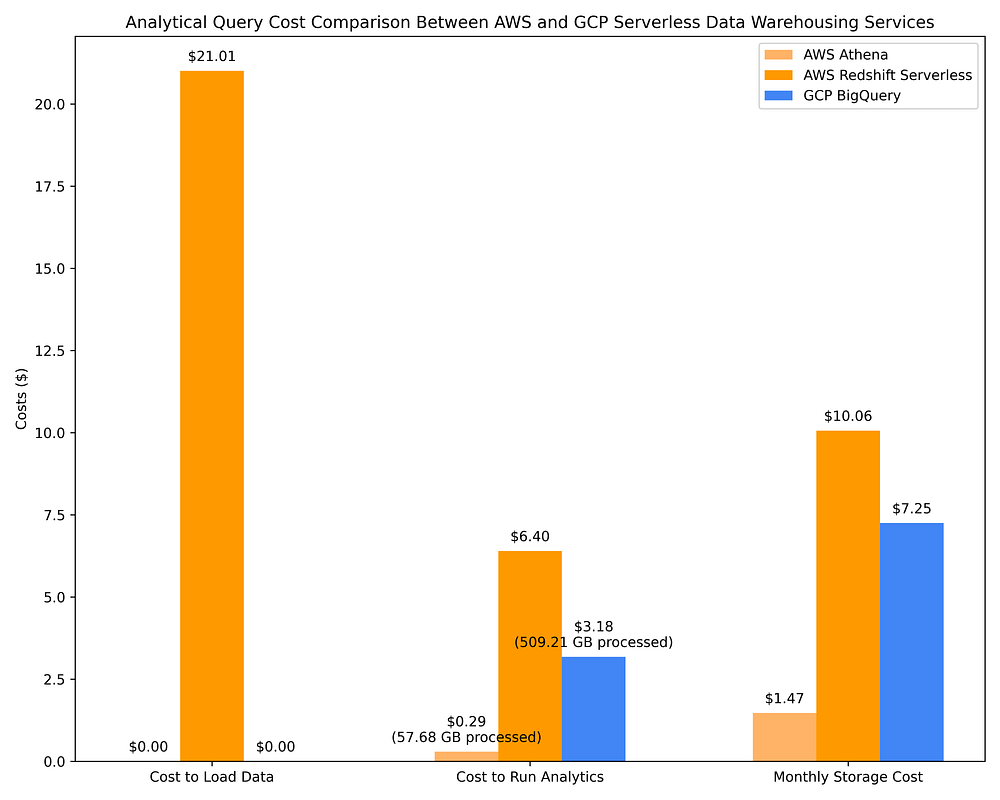
Comparaison des coûts de data warehousing GCP vs AWS pour l'exécution de requêtes OLAP avec des services DWH serverless et le stockage du jeu de données interrogé
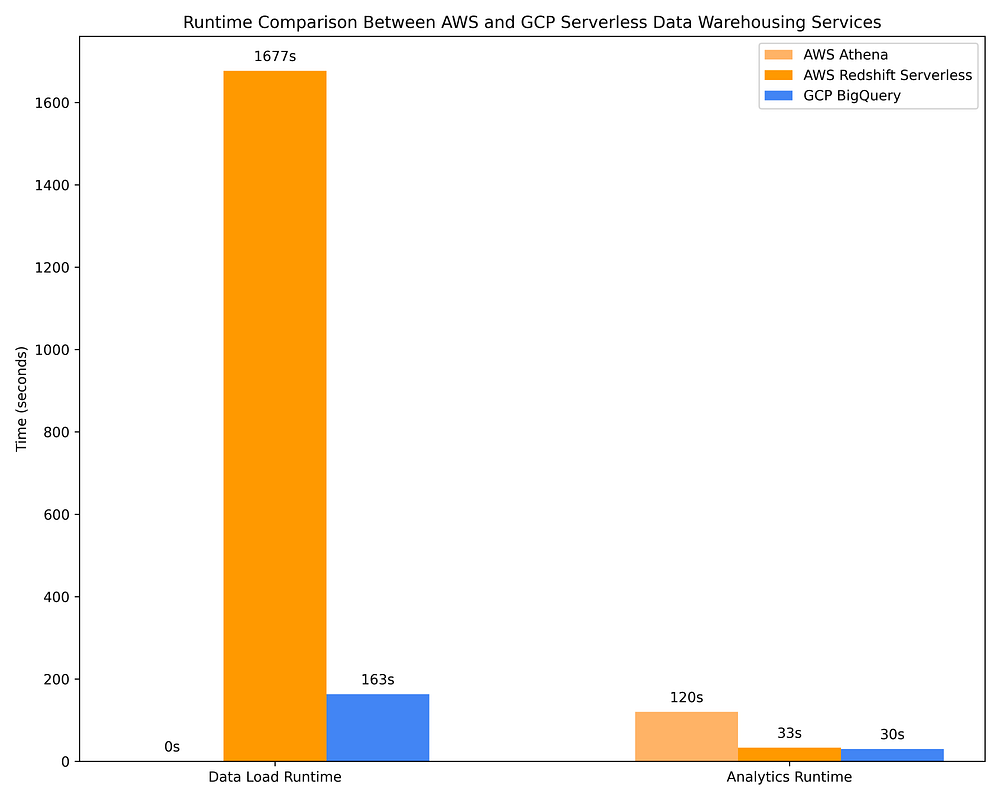
Comparaison des temps d'exécution de data warehousing GCP vs AWS pour le chargement de données et l'exécution de requêtes OLAP sur des services DWH serverless
Redshift et BigQuery calculent des métadonnées de colonnes optimisant les requêtes lorsque les données sont insérées dans une table. Ces métadonnées optimisent les requêtes en activant, par exemple, des filtres de prédicat de pushdown qui réduisent la quantité de données à scanner pour exécuter une requête. Cela réduit, par extension, le coût des requêtes facturées en fonction du nombre de To de données scannés, soit directement (BigQuery), soit indirectement (Redshift via le nombre de RPU nécessaires à l'exécution d'une requête).
Les fichiers Parquet contiennent des métadonnées et, si vous calculez et stockez des métadonnées supplémentaires sur ces fichiers dans un metastore Hive avec Spark, les requêtes OLAP qui les interrogent exploiteront des métadonnées de colonnes optimisant les requêtes très similaires.
Que vous utilisiez un DWH serverless ou des clusters Spark interrogeant des fichiers Parquet, vous tirez parti de métadonnées de colonnes pré-calculées qui permettent à des requêtes très complexes sur des To de données de s'exécuter en général en quelques secondes, tout en n'ayant scanné que quelques Go ou Mo, grâce aux métadonnées disponibles. C'est pourquoi, par exemple, l'exécution de 17 requêtes complexes sur plusieurs To de données peut coûter à peine plus de 25 cents après n'avoir scanné que 57,68 Go, comme on le voit ci-dessus dans les coûts d'AWS Athena.
Les comparaisons de coûts présentées ci-dessus, ainsi que dans l'option 2 partie 1, révèlent que l'interrogation de fichiers Parquet associée à un metastore Hive via AWS Athena, AWS EMR et GCP Dataproc est bien plus efficace en termes de coût que l'interrogation via des services de data warehouse cloud-native. C'est une observation intéressante, sachant que tous ces systèmes reposent sur le même principe d'optimisation du plan de requête en exploitant les métadonnées de colonnes pour un système de fichiers en colonnes.
Néanmoins, les offres DWH serverless sont loin d'être aussi efficaces pour optimiser les requêtes à partir des métadonnées de colonnes. BigQuery, par exemple, scanne environ 10 fois plus de données qu'AWS Athena lors de l'interrogation de fichiers Parquet via AWS Glue Data Catalog, et facture environ 10 fois plus en conséquence. Les coûts de requête de BigQuery sont également plus de 2 fois supérieurs à ceux de l'exécution de ces mêmes requêtes sur des clusters Spark éphémères avec des instances Spot/préemptives sur AWS EMR / GCP Dataproc. BigQuery peut compléter ses requêtes environ 4 fois plus vite qu'AWS Athena, AWS EMR et GCP Dataproc, mais cela se paie environ 10 fois plus cher. Selon votre cas d'usage, ce surcoût peut ou non se justifier.
AWS Redshift est un service qui a démarré comme un service à capacité provisionnée et qui a implémenté une version quasi-serverless beaucoup plus tard (l'offre serverless nécessite une planification de capacité sous la forme d'une configuration de scaling des Redshift Processing Units, ou RPU). Compte tenu de ses origines, Redshift Serverless reste l'option DWH on-demand la plus chère, en grande partie parce que sa tarification serverless reste basée sur les ressources provisionnées plutôt que sur les To de données scannés. Sachant que Redshift se comporte par ailleurs davantage comme Postgres qu'un data warehouse cloud-native, et compte tenu de l'absence d'intégrations natives avec AWS IAM (ce qui complique le partage de données et les autorisations à granularité fine au niveau des tables/colonnes/lignes), ainsi que du fait qu'il met environ 9 fois plus de temps que BigQuery pour charger les données dans les tables, à un coût non négligeable… personnellement, je ne peux pas recommander Redshift. Il n'est avantageux que si vos data engineers connaissent très bien Postgres et seulement s'ils ne peuvent, pour quelque raison que ce soit, travailler avec aucune autre option de data warehouse.
Quel data warehouse choisir ?
Recommandation : si le coût est la seule préoccupation
Si le coût est la seule considération, et si votre cas d'usage prend en charge les fichiers Parquet en backend (autrement dit, si vos jeux de données interrogés ne dépendent pas de données en streaming temps réel), je recommande d'utiliser des fichiers Parquet stockés dans un bucket et de les interroger avec un moteur de requête serverless comme AWS Athena, ou avec un service de cluster éphémère tel qu'AWS EMR ou GCP Dataproc. Les offres de data warehouse serverless comme BigQuery et Redshift offrent du confort, un meilleur support pour les cas d'usage de streaming temps réel, ainsi que de nombreuses autres fonctionnalités à valeur ajoutée que je détaillerai bientôt — mais tout cela a un coût substantiel.
À noter qu'à une échelle opérationnelle suffisamment importante, BigQuery et Redshift atteindront des limitations artificielles qui vous obligeront à passer d'un modèle on-demand à un modèle de tarification basé sur les slots/CPU. Cette transition coûtera vraisemblablement plus cher que l'équivalent on-demand.
BigQuery on-demand facture par To scanné ; cependant, il est limité à seulement 2 000 slots (~2 000 cœurs et ~2 To de mémoire) pour l'ensemble des requêtes. Vous ne pouvez pas non plus utiliser les fonctionnalités clés de BigQuery, comme les requêtes BigQuery ML, avec BQ on-demand ni même avec BQ Editions Standard. Si vous anticipez avoir besoin de l'un des éléments suivants, vous devez basculer vers l'un des trois tiers de tarification basée sur les ressources de BigQuery Editions :
- Plus de 2 000 cœurs / 2 To de mémoire (Standard)
- Exécution d'entraînements et de prédictions ML dans BQ via SQL (Enterprise)
- Contrôles d'accès au niveau des lignes et des colonnes (Enterprise)
- Vues matérialisées (Enterprise)
L'efficacité tarifaire de la scalabilité de Redshift serverless est limitée de manière similaire et nécessite également un cluster à tarif fixe pour être contournée.
Les modèles de tarification basés sur les ressources peuvent être complexes (en particulier pour BigQuery Editions [1] [2] [3]) et il est difficile — voire impossible — d'arriver à une estimation de coût réellement précise sans exécuter l'ensemble des workloads sur un déploiement basé sur les ressources pendant quelques jours, puis d'en déduire des prévisions de coûts mensuels/annuels. Il existe des particularités, comme l'autoscaler de slots défaillant de BigQuery Edition (il ne scale que par incréments de 100 slots et facture un minimum d'1 minute pour une quantité de slots donnée, que les requêtes utilisent ou non ces slots autoscalés), ainsi que la variable inconnaissable du nombre de slots que l'ensemble de vos requêtes nécessitera collectivement, qui ne peuvent être prises en compte sans simplement exécuter tous les workloads dans un test simulant la production complète sur le modèle à tarif fixe.
Indépendamment des détails tarifaires, j'ai constaté chez de nombreux clients DoiT que les modèles de tarification à tarif fixe coûtent généralement plus cher que le modèle on-demand. À moins de prévoir l'exécution de requêtes OLAP 24h/24, 7j/7, 365 jours par an, et uniquement si ces requêtes sollicitent systématiquement la même quantité de ressources de calcul dans le temps, il est peu probable que le tarif fixe vous fasse économiser de l'argent — voire pas du tout — par rapport à la tarification on-demand.
Compte tenu des informations ci-dessus, si vous vous concentrez uniquement sur l'efficacité tarifaire, sans considération pour les fonctionnalités à valeur ajoutée, je recommande les services suivants, classés du moins coûteux au plus coûteux :
- AWS Athena avec AWS Glue Data Catalog (le moins cher)
- AWS EMR avec AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc avec GCP Dataproc Metastore
- AWS Redshift (le plus cher)
Je ne clôturerais cependant pas la discussion ici. Il est important de mettre soigneusement en balance le coût des systèmes DWH serverless avec les fonctionnalités qu'ils permettent.
Recommandation : si le coût est mis en balance avec les fonctionnalités
Interroger des fichiers Parquet avec du code Spark ou du SQL Athena peut être très rentable, mais cette approche a ses limites. Vous passerez à côté de la richesse fonctionnelle qu'apportent des services comme BigQuery.
Voici quelques-uns des avantages clés qui, à mon sens, justifient le surcoût de BigQuery dans de nombreux cas :
- Accessibilité. L'UI de BQ est élégante, simple à utiliser et facile à apprendre. Les data scientists — souvent moins enclins à apprendre Apache Spark et d'autres systèmes complexes — apprécieront de disposer d'une UI agréable, basée sur SQL, pour stocker et interroger les données.
- Récupération à un point dans le temps (PIT). La PIT est intégrée à BQ, avec un time travel pouvant aller jusqu'à 7 jours par défaut. À l'inverse, bien que vous puissiez activer le versioning des buckets pour permettre la restauration de fichiers Parquet supprimés par erreur, c'est moins pratique que de restaurer une table avec une seule commande SQL. Des projets de data lakehouse comme Apache Iceberg et Delta Lake permettent une récupération PIT basée sur SQL sur des fichiers Parquet, mais lors de tests succincts que j'ai menés, les lakehouses augmentent le temps d'exécution des requêtes d'au moins 2 à 3 fois. En vous reposant sur un data lakehouse, vous perdez les avantages de coût et de performance liés à l'utilisation exclusive d'Apache Spark pour interroger les données Parquet.
- Intégrations IAM natives. La dépendance de BQ à l'IAM GCP rend possible et étonnamment facile le partage de données et le contrôle d'accès à un niveau très granulaire. Il est simple de partager des datasets et des tables avec d'autres utilisateurs GCP. Vous pouvez même limiter la capacité des utilisateurs à consulter des colonnes et des lignes spécifiques. Le partage et le contrôle d'accès granulaire ne sont pas des fonctionnalités que vous obtiendrez avec un système de fichiers basé sur Parquet.
- Intégrations natives aux services de streaming temps réel. Si l'ingestion de données en temps réel est essentielle, BigQuery s'intègre nativement avec PubSub et Dataflow. Ces services permettent aux requêtes d'atteindre des données en streaming temps réel avec au plus quelques secondes de latence. BigQuery se distingue de tous les autres systèmes DWH à cet égard ; même l'ingestion de données en temps réel de Snowflake peut prendre plusieurs minutes avant d'être disponible. Rendre des données disponibles pour requête en quasi-temps réel n'est pas possible, à ma connaissance, avec un système de fichiers basé sur Parquet.
- Intégrations natives avec… presque tout. Il y a un aspect UI/UX dans BigQuery qu'il ne faut pas sous-estimer. Avec BQ on-demand, vous pouvez voir le coût estimé d'une requête avant même de l'exécuter. Disons que le coût d'une requête vous convient et que vous l'exécutez. D'un seul clic, vous pouvez exporter les résultats de cette requête vers Looker Studio, où une visualisation est automatiquement construite en fonction de ce que l'algorithme ML de Looker Studio estime que vous voudrez visualiser à partir de vos résultats. Il est tout aussi facile de transférer les résultats de requête vers Vertex AI de GCP pour le machine learning, de construire/déployer un modèle ML directement dans BigQuery via BQ ML SQL, ou d'exporter les résultats de requête vers Google Drive, et ainsi de suite. BigQuery n'est pas qu'un simple data warehouse. BigQuery fait partie d'un écosystème de services qui semble entièrement construit autour de lui.
Contrairement à BigQuery, Redshift offre malheureusement plus de tracas que de bénéfices. Je le placerais en dernière position en termes d'efficacité tarifaire et de richesse fonctionnelle. Il se comporte davantage comme Postgres que comme un data warehouse, et de ce fait, bien l'utiliser nécessite de se familiariser intimement avec l'ajustement des performances des tables, ainsi qu'avec la création d'utilisateurs/groupes et de permissions au sein de Redshift, ses contrôles IAM restant distincts d'AWS IAM.
Bien qu'il soit techniquement possible de s'authentifier sur Redshift avec AWS IAM, cela passe par Trusted Identity Propagation (SSO) — ce qui signifie que vous devez tout de même mettre en place une interface entre deux systèmes IAM distincts — et les politiques AWS IAM personnalisées qu'il faut construire et associer à la configuration SSO pour accorder à un utilisateur AWS l'accès à l'instance Redshift ne peuvent accorder que des permissions larges. Si vous devez restreindre la portée de ce qu'une entité AWS IAM peut faire au-delà des actions de haut niveau (par exemple au-delà de la création, modification ou suppression d'un cluster, ou plus finement que l'octroi d'un accès complet ou en lecture seule complète à une instance), alors vous devez créer un rôle via le système IAM de l'instance Redshift auquel est attribuée une portée restreinte au niveau de la table, puis mettre à jour la politique de l'utilisateur AWS IAM pour que l'authentification via SSO endosse le rôle IAM de ce nouveau cluster… au final, c'est une configuration nettement plus compliquée comparée aux alternatives disponibles.
À l'inverse, dans BigQuery par exemple, vous pouvez restreindre l'accès d'un utilisateur GCP à un dataset, à une table, voire à des lignes ou colonnes spécifiques au sein d'une table, en cliquant simplement sur l'entité concernée dans l'UI BigQuery et en accordant directement les permissions à portée restreinte à l'utilisateur GCP IAM. Redshift exige la consultation d'une demi-douzaine de pages de documentation pour s'assurer de configurer correctement des permissions granulaires au niveau des tables — des permissions qui ne peuvent pas être auditées uniquement en consultant les politiques accordées dans AWS IAM, en raison de la dépendance à des politiques granulaires qui n'existent que dans les rôles IAM de Redshift. Dans BigQuery, en revanche, vous pouvez configurer des permissions granulaires en bricolant brièvement l'UI, et comme BQ s'appuie uniquement sur GCP IAM pour l'authentification, déterminer qui a accès à quelles tables, ou même qui est autorisé à consulter des colonnes ou lignes sensibles spécifiques au sein des tables, est relativement simple à auditer.
Les intégrations de Redshift avec d'autres services sont tout aussi laborieuses. Le connecter à SageMaker pour effectuer un entraînement ML, ou à Quicksight pour visualiser les résultats de requêtes, est techniquement faisable, mais nécessite des étapes d'intégration plus contraignantes que la configuration zéro effort, prête à l'emploi, qu'offre BigQuery pour ses services équivalents Vertex AI (ML) et Looker (BI).
Compte tenu du coût exceptionnellement élevé associé à Redshift, que vous utilisiez sa version serverless ou à capacité provisionnée… je n'y vois personnellement aucun bénéfice. Plusieurs meilleures options existent, y compris au sein même d'AWS (AWS Athena et AWS EMR associés à AWS Glue Data Catalog).
Si vous souhaitez équilibrer fonctionnalités à valeur ajoutée et coût total, je recommande les data warehouses selon le classement suivant :
- GCP BigQuery (l'option DWH qui apporte le plus de valeur)
- AWS Athena avec AWS Glue Data Catalog
- AWS EMR avec AWS Glue Data Catalog
- GCP Dataproc avec GCP Dataproc Metastore
- AWS Redshift (l'option DWH qui apporte le moins de valeur)
Annexe
Les capacités de reporting de DoiT Navigator ont été mises à profit pour simplifier et accélérer le calcul des coûts totaux de chaque partie. Cette plateforme unifie les dépenses entre tous les fournisseurs cloud et permet de créer facilement des rapports avec des critères de regroupement et de filtrage complexes. Par exemple, une ventilation des dépenses cloud par jour, fournisseur cloud, service et SKU peut être obtenue en quelques secondes avec une relative facilité ; ce type de rapport a été fréquemment utilisé pour collecter sans effort les données de dépenses présentées dans cet article.
Les détails des calculs de coûts et les explications sur la complexité des requêtes sont disponibles dans la base de code associée à ce blog : Appendix.md
Vous avez encore des questions sur la manière d'appliquer ces recommandations pour réussir votre data warehousing GCP ou AWS au sein de votre organisation ?
Contactez-nous chez DoiT International. Composés exclusivement de talents senior en ingénierie, nous sommes spécialisés dans le conseil cloud avancé, la conception architecturale et le débogage.