Quais serviços devo usar para data warehousing e analytics no GCP / AWS?

Para responder a essa pergunta, é preciso ir além de uma simples comparação de funcionalidades. O desafio é analisar com cuidado os modelos de precificação dos sistemas de DWH e dos diversos serviços de nuvem dos quais eles dependem.
Comparar funcionalidades entre as ofertas pode ser bem direto, mas comparar preços é bem mais complicado, por dois motivos principais:
- Os DWHs dependem de vários serviços de nuvem para preparar e carregar dados. Cada um deles tem um custo nada trivial, que se soma ao custo do próprio DWH.
- Avaliar o custo do DWH isoladamente exige considerar tanto o volume de dados armazenados quanto os métodos e a frequência com que esses dados serão consultados. Tipos diferentes de queries e frequências de execução geram custos bem distintos, dependendo do DWH usado e do modelo de preços escolhido.
Para responder melhor a essa dúvida comum entre clientes de nuvem que querem operar com eficiência de custo em escala, apresento abaixo uma comparação detalhada dos custos ponta a ponta das opções de data warehousing no GCP e na AWS. Vamos analisar o custo de:
- Recuperar grandes datasets, com vários TBs, usados em aplicações reais de genômica
- Transformações de dados que facilitam a carga em um data warehouse
- Executar 17 queries complexas que produzem resultados úteis
(em vez de, por exemplo, rodar queries de benchmark simples e arbitrárias)
Embora o foco principal deste artigo seja o custo total das operações de data warehousing, também farei comparações funcionais para enriquecer a discussão e oferecer um guia completo para a escolha do data warehouse.
Se quiser reproduzir qualquer um dos cálculos de custo apresentados, consulte o repositório Git deste artigo: ele torna a reprodução dos meus benchmarks o mais simples e automatizada possível.
E se surgirem dúvidas sobre como os custos foram calculados ao longo da leitura, dê uma olhada no Apêndice para mais detalhes.
Dito isso, vamos lá!
Em vez de deixar para o final, prefiro destacar logo de cara as recomendações para escolha de data warehouse, baseadas nos meus benchmarks.
Se o seu foco é exclusivamente eficiência de custo, sem considerar funcionalidades de valor agregado, recomendo os seguintes serviços, em ordem da maior probabilidade de sair mais barato à mais cara:
- AWS Athena com AWS Glue Data Catalog (mais barato)
- AWS EMR com AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc com GCP Dataproc Metastore
- AWS Redshift (mais caro)
Se você dá mais peso a funcionalidades de valor agregado, a recomendação é esta, equilibrando recursos e custo:
- GCP BigQuery (entrega o maior valor entre todas as opções de DWH)
- AWS Athena com AWS Glue Data Catalog
- AWS EMR com AWS Glue Data Catalog
- GCP Dataproc com GCP Dataproc Metastore
- AWS Redshift (entrega o menor valor entre todas as opções de DWH)
Continue a leitura para entender o raciocínio por trás dessas recomendações.
Parte 1: aquisição e transformação de dados
Para simular da melhor forma operações realistas em escala de TBs, vou trabalhar com dados do genoma humano, já que esse domínio é, por natureza, da ordem de múltiplos TBs e costuma trazer desafios únicos para alcançar analytics com eficiência de custo.
Vou evitar entrar em detalhes da terminologia genômica para manter o texto acessível. Mesmo assim, para quem se interessa por workloads científicos escaláveis, o repositório Git deste blog traz exemplos detalhados e reproduzíveis de implementação de workloads de genômica com eficiência de custo.
Vou trabalhar especificamente com os dois datasets a seguir, que, para um público leigo em genômica, podem ser resumidos assim:
- gnomAD genomes v4.0: o gnomAD é amplamente utilizado em pesquisa genômica, pois traz dados de frequência populacional sobre mutações descobertas a partir do sequenciamento de genoma completo de 807.162 indivíduos. Entre outros usos, as frequências populacionais ajudam a identificar mutações raras que, justamente por serem raras, têm maior probabilidade de ter relevância clínica.
- Por exemplo: uma mutação com frequência populacional de 25% está presente em 25% da população humana. Uma mutação comum como essa tem muito menos chance de gerar impacto clínico em um indivíduo do que, digamos, uma mutação rara (rara por causa da pressão evolutiva contra ela) que aparece em apenas 0,01% da população humana.
- No formato de arquivo flat, o gnomAD v4.0, quando bgzipped, tem cerca de 830 GB.
- dbNSFP v4.6: outro grande dataset usado em pesquisa do genoma humano. O dbNSFP reúne — em um único arquivo — dezenas de previsões de impacto funcional e anotações para todas as mutações do genoma humano, unificando dados de várias dezenas de bancos de dados. A amplitude e a profundidade dos dados do dbNSFP ajudam profissionais clínicos a avaliar o impacto clínico das mutações.
- No formato de arquivo flat, o dbNSFP descompactado tem cerca de 250 GB.
Tanto o gnomAD quanto o dbNSFP são recursos cruciais em medicina de precisão.
O gnomAD está hospedado em buckets S3 e GCS, e o dbNSFP fica no S3, então recuperar esses datasets dentro das contas de nuvem é simples. Acontece que ambos são armazenados em formatos de arquivo flat pensados para pesquisadores que os exploram com ferramentas de bioinformática pouco escaláveis e voltadas ao meio acadêmico. O gnomAD, em particular, é armazenado em um formato de arquivo flat especializado da bioinformática (VCF bgzipped), que não é ideal para analytics em larga escala nem é um formato padrão aceito por DWHs.
Assim, o primeiro passo da nossa jornada para explorar custos de DWH é recuperar o gnomAD e o dbNSFP e, em seguida, transformar seus enormes arquivos flat em um formato amigável para data warehouse: o Parquet.
Uma das ferramentas mais econômicas para manipular grandes arquivos flat é o Apache Spark. Aliás, o Spark é uma das ferramentas mais econômicas para analytics em qualquer dataset grande, especialmente quando se trabalha com arquivos Parquet como entrada. Ele não é só um componente-chave em pipelines de dados em escala — pode até ser usado como DWH quando empregado para rodar analytics em arquivos Parquet armazenados em um bucket.
Com isso em mente, vamos primeiro analisar o custo de executar uma etapa de preparação de dados baseada em Spark.
O gráfico abaixo ilustra os custos de converter as duas fontes de dados de arquivos flat para Parquet, fazer o join entre elas e gravar o arquivo resultante em Parquet, provisionar um Hive metastore para manter os metadados do Parquet e armazenar todos os arquivos Parquet em um bucket:
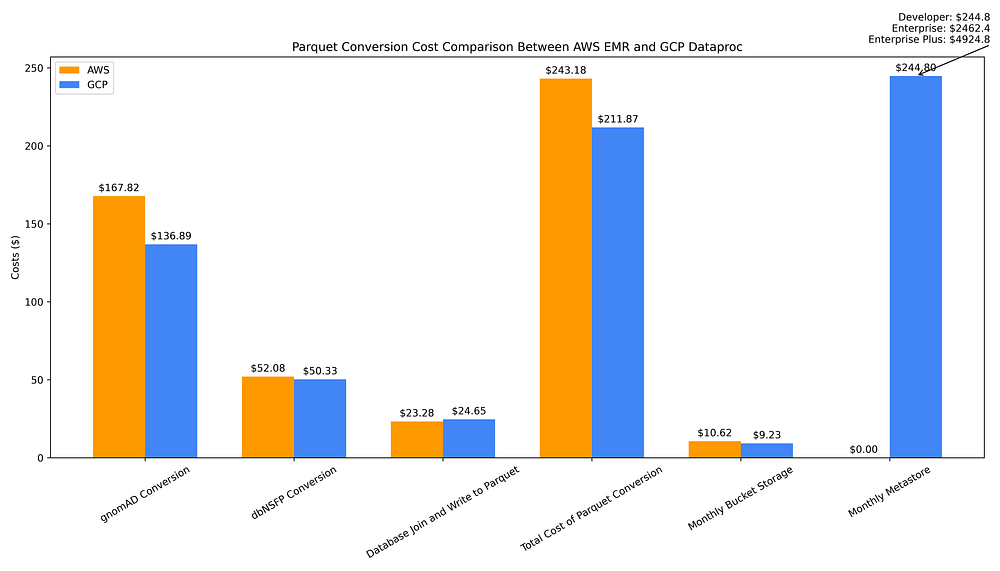
Comparação de custos de data warehousing GCP vs. AWS para conversão de arquivo flat → Parquet, armazenamento de Parquet e criação de Hive metastore
O custo total único de converter os arquivos flat dos dois bancos para Parquet e fazer o join em um Parquet de banco unificado fica, no conjunto, ligeiramente mais barato no GCP Dataproc (US$ 211,87) do que no AWS EMR (US$ 243,18). Isso se deve à sobretaxa do EMR aplicada às máquinas Graviton de 7ª geração de ponta, como as Spot instances r7g.16xlarge.
O custo de armazenar os arquivos Parquet de saída em buckets regionais é parecido entre as nuvens — você economiza apenas US$ 1,39 por mês ao guardar os dados Parquet em um bucket GCS (US$ 9,23) em vez de S3 (US$ 10,62).
Já os custos operacionais de longo prazo associados ao uso desses arquivos Parquet são bem maiores no GCP, pois o serviço totalmente gerenciado de metastore tem custo por hora, enquanto na AWS o Glue Data Catalog é praticamente gratuito — pelo menos até você atingir uso em larga escala.
Com o Glue Data Catalog, você só começa a ser cobrado depois de ultrapassar 1 milhão de objetos armazenados, e mesmo assim por meros US$ 1 a cada 100.000 objetos por mês acima do free tier de 1 milhão. As requisições ao Data Catalog também são gratuitas até 1 milhão de chamadas; a partir daí, você paga apenas US$ 1 por milhão de requisições adicionais por mês.
Compare o metastore da AWS, que vai de gratuito a um custo trivial, com o custo mensal de US$ 245 do Dataproc Metastore. Esse custo do Dataproc considera o uso do tier Developer, que tem "escalabilidade limitada e nenhuma tolerância a falhas". Para analytics em maior escala, você precisaria do tier Enterprise, escalável e com tolerância a falhas, que tem um custo mensal de US$ 2.462. Há ainda um tier Enterprise Plus pouco documentado, que dobra esse custo mensal para US$ 4.924 (em conversas com um PM do GCP, fui informado de que o Plus inclui uma configuração de Alta Disponibilidade).
Assim, embora os custos únicos de conversão de dados e criação de metadados sejam um pouco mais altos na AWS, e os custos de armazenamento de longo prazo sejam mais ou menos equivalentes, no quesito uso de arquivos Parquet como data warehouse, a AWS sai na frente graças ao custo trivial de manter um metastore de Parquet. Um Hive metastore é essencial tanto para melhorar a eficiência de custo das consultas em arquivos Parquet quanto para torná-los mais fáceis e práticos de acessar — por exemplo, ao permitir consultas via nomes de 'tabela' em vez de consultar diretamente o caminho do arquivo. Por isso, considero esse um componente obrigatório em um data warehouse baseado em Parquet.
Parte 2: o custo de 17 queries analíticas complexas
Já comparamos o custo de transformar terabytes de arquivos flat para o formato Parquet e o de hospedar um metastore para acelerar o tempo de execução das queries. Agora vamos examinar o custo de rodar queries nesses datasets usando vários serviços de data warehouse na nuvem.
Um resumo das 17 queries que serão executadas em cada DWH está no Apêndice, para evidenciar a complexidade das consultas. Para quem curte genômica, há explicações ainda mais detalhadas nos comentários dos arquivos de código.
Opção 1: clusters Spark efêmeros como data warehouse
Vamos começar partindo do princípio de que nosso data warehouse é composto por clusters Spark efêmeros consultando arquivos Parquet armazenados em buckets:
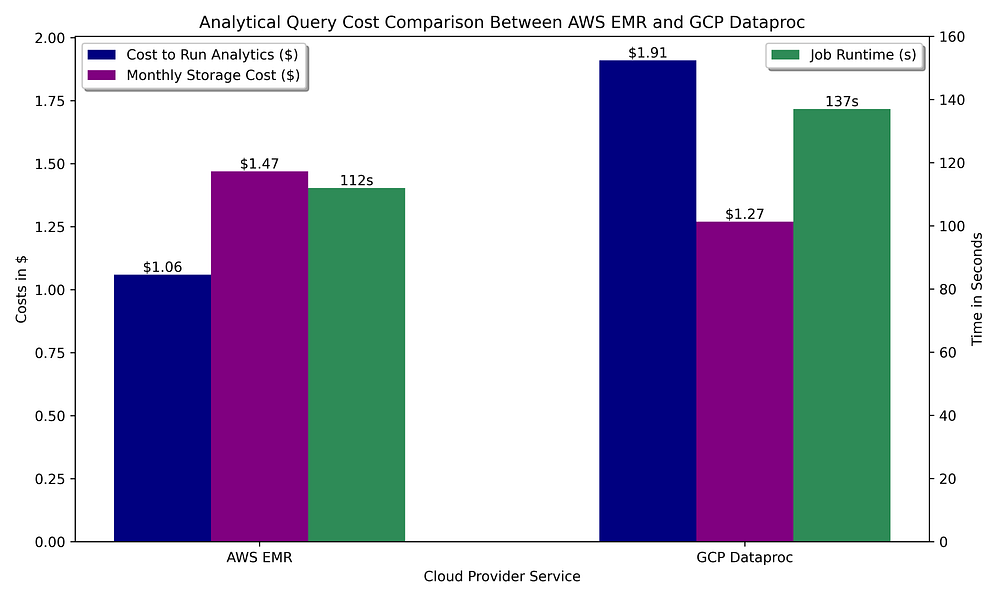
Comparação de custos de data warehousing GCP vs. AWS para rodar queries OLAP com Apache Spark e armazenamento Parquet do dataset consultado
Assim como na etapa de preparação de dados com Spark, rodar analytics nas ofertas Spark gerenciadas tem custo similar nas duas nuvens. Aqui, a AWS leva uma pequena vantagem sobre o GCP: a configuração de auto-término por inatividade do EMR aceita até 60 segundos de ociosidade antes de encerrar o cluster, enquanto o auto-término do Dataproc só desce até 5 minutos. Como essas queries não levam muito tempo para concluir, o tempo mínimo de inatividade suportado para encerramento do cluster joga contra o GCP.
O Spark oferece a mesma funcionalidade nas duas nuvens, então não há vantagem funcional real de uma sobre a outra. Com a execução mais barata e rápida do EMR em clusters de vida curta e o metastore gratuito, contra o alto custo de hospedar um Hive metastore no GCP, analytics baseados em Spark pendem fortemente a favor da AWS.
Opção 2: ofertas serverless de DWH
E se quisermos substituir o Spark como DWH por um serviço de data warehouse totalmente gerenciado e serverless do provedor de nuvem — em que as queries podem ser feitas só com SQL — para evitar escrever código Spark?
Abaixo, comparamos os custos de data warehousing da AWS usando Athena e Redshift Serverless contra o GCP BigQuery on-demand. As mesmas 17 queries OLAP usadas na Etapa 2 Opção 1 são utilizadas para esses DWHs. É nessa comparação que a relação custo-benefício das opções de DWH fica clara:
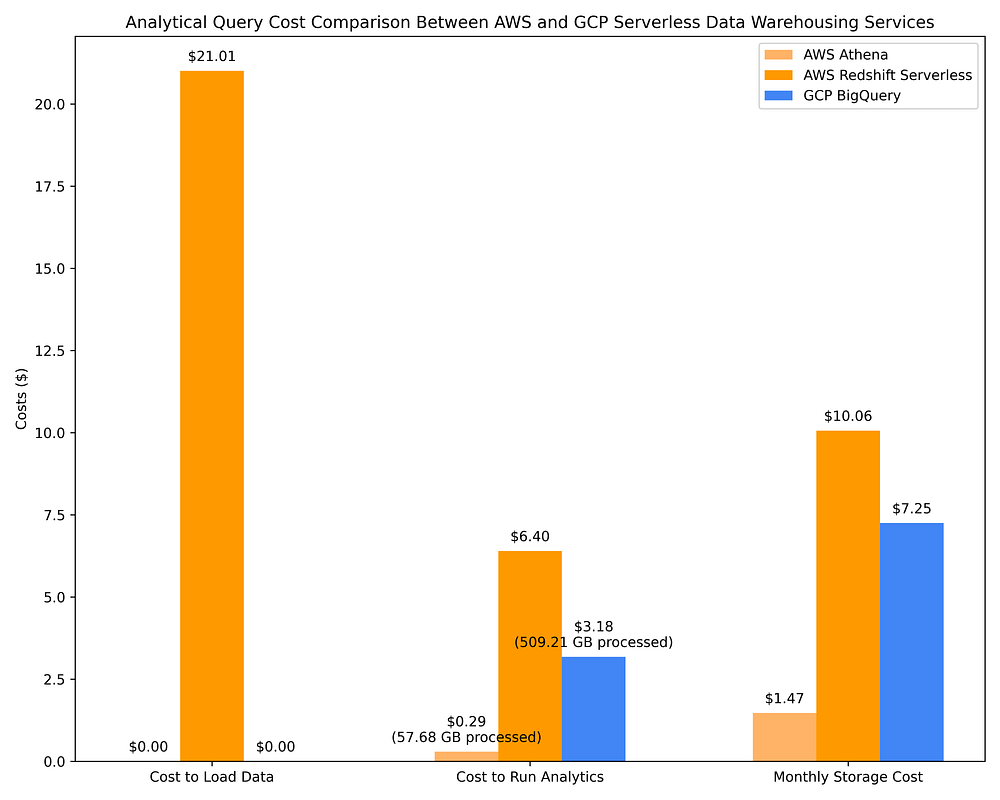
Comparação de custos de data warehousing GCP vs. AWS para rodar queries OLAP com serviços de DWH serverless e armazenamento do dataset consultado
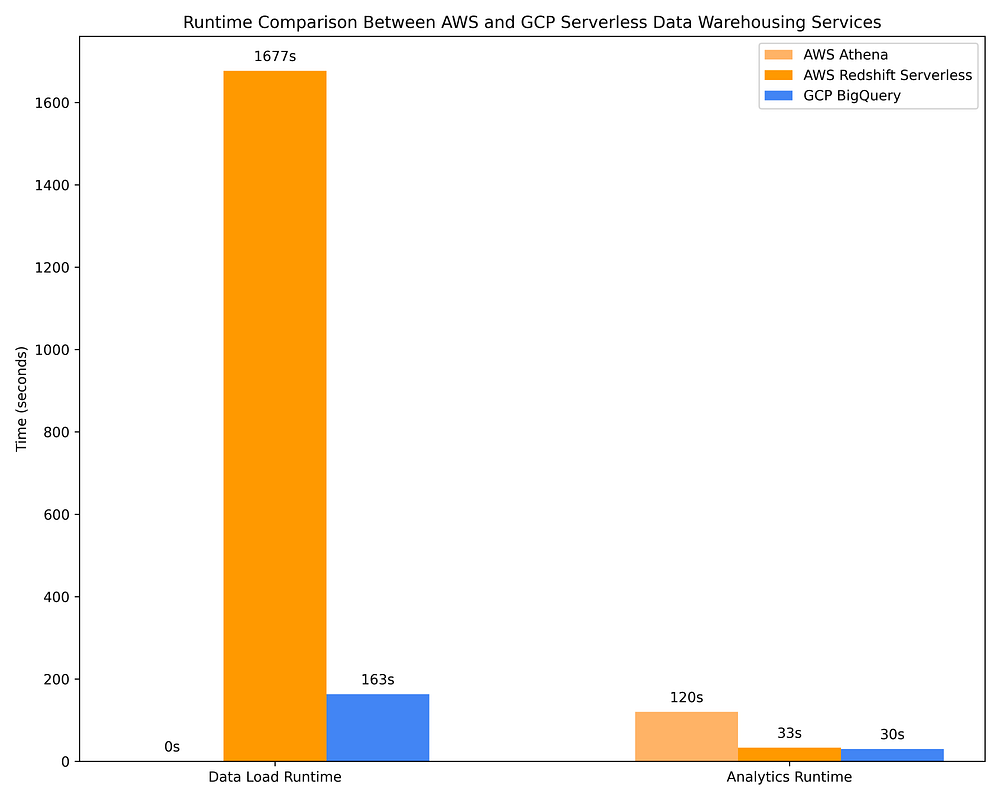
Comparação de tempos de execução de data warehousing GCP vs. AWS para carregar dados e rodar queries OLAP em serviços de DWH serverless
O Redshift e o BigQuery calculam metadados de coluna otimizadores de query no momento em que os dados são inseridos em uma tabela. Esses metadados otimizam as consultas, por exemplo, ativando filtros pushdown predicate que reduzem o volume de dados a ser escaneado para executar uma query. Isso, por extensão, reduz o custo das queries cobradas com base nos TBs de dados escaneados, seja diretamente (BigQuery) ou indiretamente (Redshift, via número de RPUs necessárias para executar a query).
Os arquivos Parquet trazem metadados, e se você calcular e armazenar metadados adicionais para esses arquivos em um Hive metastore usando Spark, as queries OLAP que os acessarem vão aproveitar metadados de coluna otimizadores muito parecidos.
Seja usando um DWH serverless ou clusters Spark consultando arquivos Parquet, você está tirando proveito de metadados de coluna pré-calculados, que permitem que queries altamente complexas sobre TBs de dados sejam concluídas, em geral, em segundos, tendo escaneado apenas alguns GBs ou MBs, graças aos metadados disponíveis. Por isso, por exemplo, rodar 17 queries complexas contra vários TBs de dados pode custar pouco mais de 25 centavos depois de escanear apenas 57,68 GB, como se vê nos custos do AWS Athena acima.
As comparações de custos mostradas acima, e também na Opção 2 da Parte 1, revelam que consultar arquivos Parquet em conjunto com um Hive metastore via AWS Athena, AWS EMR e GCP Dataproc é muito mais econômico do que consultar com serviços de data warehouse nativos da nuvem. É um achado bem interessante, considerando que todos esses sistemas se baseiam no mesmo princípio de otimização de plano de query usando metadados de coluna em um sistema de arquivos colunares.
Mesmo assim, as ofertas serverless de DWH estão longe de ser tão eficazes em otimizar queries com base em metadados de coluna. O BigQuery, por exemplo, escaneia cerca de 10x mais dados do que o AWS Athena ao consultar arquivos Parquet via AWS Glue Data Catalog, cobrando cerca de 10x mais por isso. Os custos de query do BigQuery também ficam >2x acima dos de rodar essas mesmas queries em clusters Spark efêmeros com instâncias Spot/preemptíveis no AWS EMR / GCP Dataproc. O BigQuery pode até concluir as queries cerca de 4x mais rápido do que AWS Athena, AWS EMR e GCP Dataproc, mas isso vem com um custo cerca de 10x maior. Dependendo do seu caso de uso, esse custo adicional pode ou não compensar.
O AWS Redshift começou como um serviço de capacidade provisionada e implementou uma versão quase serverless bem depois (a oferta 'serverless' exige planejamento de capacidade na forma de configuração de scaling de Redshift Processing Units, ou RPUs). Por causa dessas raízes, o Redshift Serverless segue sendo a opção on-demand mais cara entre os DWHs, em grande parte porque sua precificação 'serverless' continua atrelada a recursos provisionados, e não a TBs de dados escaneados. Considerando que o Redshift se comporta mais como o Postgres do que como um data warehouse serverless nativo da nuvem, somando a isso a falta de integrações embutidas com o AWS IAM (o que dificulta o compartilhamento de dados e permissões granulares por tabela/coluna/linha) e o fato de levar cerca de 9x mais tempo do que o BigQuery para carregar dados em tabelas a um custo nada trivial… eu, particularmente, não recomendo o Redshift. Ele só vale a pena se seus engenheiros de dados forem muito familiarizados com Postgres e se eles não puderem, por algum motivo, trabalhar com qualquer outra opção de data warehouse.
Qual data warehouse você deve escolher?
Recomendação: se custo é a única preocupação
Se custo é o único critério e seu caso de uso comporta arquivos Parquet como backend (ou seja, os datasets consultados não dependem de dados de streaming em tempo real), recomendo armazenar arquivos Parquet em um bucket e consultá-los com um motor de queries serverless como o AWS Athena ou um serviço de cluster efêmero como AWS EMR ou GCP Dataproc. Ofertas serverless de data warehouse como BigQuery e Redshift trazem conveniência, melhor suporte a casos de uso de streaming em tempo real e muitos outros recursos de valor agregado que vou abordar daqui a pouco — mas tudo isso vem com um custo significativo.
Vale notar que, em uma escala operacional grande o suficiente, BigQuery e Redshift esbarram em limitações artificiais que exigem migrar do modelo on-demand para um modelo de precificação baseado em recursos (slots/CPU). Essa migração provavelmente vai custar mais do que o equivalente on-demand.
O BigQuery on-demand cobra por TB escaneado; só que é limitado a apenas 2.000 slots (cerca de 2.000 cores e cerca de 2 TB de memória) para uso entre todas as queries. Você também não pode usar recursos-chave do BigQuery, como queries do BigQuery ML, com BQ on-demand ou mesmo com BQ Editions Standard. Se você prevê precisar de qualquer um dos itens abaixo, terá que migrar para um dos três tiers de precificação baseada em recursos do BigQuery Editions:
- Mais de 2.000 cores / 2 TB de memória (Standard)
- Rodar treinamento e previsões de ML dentro do BQ usando SQL (Enterprise)
- Controles de acesso em nível de linha e coluna (Enterprise)
- Materialized views (Enterprise)
A relação custo-benefício da escalabilidade serverless do Redshift é igualmente limitada e também exige um cluster de tarifa fixa para resolver.
Modelos de precificação baseados em recursos podem ser complexos (especialmente o BigQuery Editions [1] [2] [3]) e difíceis — se não impossíveis — de estimar com real precisão sem rodar todos os workloads em um deployment baseado em recursos por alguns dias e, a partir disso, projetar custos mensais/anuais. Há peculiaridades, como o autoscaler de slots falho do BigQuery Editions (ele só escala em incrementos de 100 slots e cobra no mínimo 1 minuto para uma dada quantidade de slots, independentemente de as queries estarem usando ou não esses slots autoescalados), além da variável imprevisível de quantos slots, no total, todas as suas queries vão exigir para rodar. Esses fatores não conseguem ser estimados sem simplesmente rodar todos os workloads em um teste que simule por completo a produção no modelo de tarifa fixa.
Independentemente dos detalhes de precificação, observei em vários clientes da DoiT que modelos de tarifa fixa, em geral, custam mais do que o modelo on-demand. A menos que você planeje rodar queries OLAP 24/7/365, e somente se essas queries pedirem consistentemente a mesma quantidade de recursos de computação ao longo do tempo, é improvável que a tarifa fixa traga uma economia relevante — se é que vai economizar — em comparação com a precificação on-demand.
Diante disso, se o seu foco é exclusivamente eficiência de custo, sem considerar funcionalidades de valor agregado, recomendo os seguintes serviços, em ordem da maior probabilidade de sair mais barato à mais cara:
- AWS Athena com AWS Glue Data Catalog (mais barato)
- AWS EMR com AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc com GCP Dataproc Metastore
- AWS Redshift (mais caro)
Mas eu não encerraria a conversa por aqui. É importante ponderar com cuidado o custo dos sistemas serverless de DWH em relação às funcionalidades que eles habilitam.
Recomendação: se o custo for ponderado com a funcionalidade
Consultar arquivos Parquet com código Spark ou SQL no Athena pode ser muito econômico, mas essa abordagem tem limitações. Você abre mão das vantagens em riqueza de funcionalidades que serviços como o BigQuery trazem.
Abaixo, algumas das principais vantagens que, na minha opinião, fazem o BigQuery valer o custo extra em muitos casos:
- Acessibilidade. A interface do BQ é bonita, fácil de usar e fácil de aprender. Cientistas de dados — que podem ter menos vontade de aprender Apache Spark e outros sistemas complexos — vão gostar de ter uma interface bacana, baseada em SQL, para armazenar e consultar dados.
- Recuperação a um ponto no tempo. PIT é nativo do BQ, com time travel de até 7 dias como padrão. Em contrapartida, embora você possa ativar o versionamento do bucket para permitir a restauração de arquivos Parquet excluídos por engano, isso não é tão prático quanto restaurar uma tabela com um único comando SQL. Projetos de data lakehouse como Apache Iceberg e Delta Lake permitem recuperação PIT baseada em SQL em arquivos Parquet, mas, em testes rápidos que rodei, lakehouses aumentam o tempo de execução das queries em pelo menos 2 a 3x. Ao recorrer a um data lakehouse, você abre mão das vantagens de alto desempenho e baixo custo de usar apenas o Apache Spark para consultar dados Parquet.
- Integrações nativas com IAM. A dependência do BQ em relação ao GCP IAM torna possível — e surpreendentemente fácil — compartilhar dados e controlar o acesso a eles em um nível bem granular. É simples compartilhar datasets e tabelas com outros usuários do GCP. Você pode até limitar a capacidade dos usuários de visualizar colunas e linhas específicas. Compartilhamento e controle de acesso granular não são algo que você terá em um sistema de arquivos baseado em Parquet.
- Integrações nativas com serviços de streaming em tempo real. Se a ingestão de dados em tempo real é fundamental, o BigQuery se integra nativamente com PubSub e Dataflow. Esses serviços permitem que queries acessem dados de streaming em tempo real com, no máximo, alguns segundos de latência. O BigQuery se diferencia de todos os outros sistemas de DWH nesse quesito; até a ingestão de dados em tempo real do Snowflake pode levar vários minutos para ficar disponível. Disponibilizar dados para consulta em tempo quase real, até onde sei, não é possível com um sistema de arquivos baseado em Parquet.
- Integrações nativas com… quase tudo. Há um aspecto de UI/UX no BigQuery que não dá para subestimar. Com o BQ on-demand, você consegue ver o custo estimado de uma query antes mesmo de executá-la. Digamos que esteja tudo bem com o custo da query e você a execute. Com um único clique, você pode exportar os resultados dessa query para o Looker Studio, onde uma visualização é construída automaticamente com base no que o algoritmo de ML do Looker Studio acha que você vai querer visualizar a partir dos resultados. É igualmente fácil mover os resultados das queries para o Vertex AI do GCP para machine learning, ou construir/implantar um modelo de ML diretamente dentro do BigQuery via BQ ML SQL, ou exportar resultados para o Google Drive, e por aí vai. O BigQuery não é só um data warehouse. O BigQuery é parte de um ecossistema de serviços construído, aparentemente, todo em torno do BigQuery.
Diferente do BigQuery, o Redshift, infelizmente, traz mais dor de cabeça do que benefícios. Eu o colocaria em último lugar em custo-benefício e em riqueza de recursos. Ele se comporta mais como o Postgres do que como um data warehouse e, por isso, usá-lo bem exige se familiarizar profundamente com ajustes de performance de tabela, além de criação de usuários/grupos e permissões dentro do Redshift, já que seus controles de IAM permanecem separados do AWS IAM.
Embora seja tecnicamente possível autenticar no Redshift com AWS IAM, isso é feito por meio de Trusted Identity Propagation (SSO) — ou seja, você ainda precisa configurar uma interface entre dois sistemas IAM separados — e as políticas customizadas do AWS IAM que precisam ser construídas e pareadas com a configuração do SSO para conceder a um usuário AWS acesso à instância do Redshift só conseguem conceder permissões amplas. Se você precisa limitar o escopo do que uma entidade do AWS IAM pode fazer além de ações de alto nível (por exemplo, além de permitir criar, modificar ou excluir um cluster, ou algo mais granular do que, digamos, conceder acesso total ou somente leitura a uma instância), então é preciso criar uma role usando o sistema IAM da própria instância Redshift, com escopo restrito a nível de tabela, e depois atualizar a política do usuário AWS IAM para que a autenticação via SSO assuma a role IAM desse novo cluster… no fim das contas, é uma configuração drasticamente mais complicada quando comparada com as alternativas disponíveis.
Em contraste, no BigQuery, por exemplo, você pode limitar o acesso de um usuário do GCP a um dataset, a uma tabela, ou até a linhas ou colunas específicas dentro de uma tabela, simplesmente clicando na entidade relevante na interface do BigQuery e concedendo essas permissões de escopo restrito diretamente ao usuário GCP IAM. O Redshift exige que você consulte meia dúzia de páginas de documentação para garantir que está configurando corretamente permissões granulares em nível de tabela — permissões que não podem ser auditadas só visualizando políticas concedidas no AWS IAM, por causa da dependência de políticas granulares que existem somente dentro das roles IAM do Redshift. Já no BigQuery, você consegue configurar permissões granulares mexendo rapidamente na interface, e como o BQ depende exclusivamente do GCP IAM para autenticação, descobrir quem tem acesso a quais tabelas, ou até quem pode visualizar colunas ou linhas sensíveis específicas, é relativamente simples de auditar.
As integrações do Redshift com outros serviços são igualmente desajeitadas. Conectá-lo ao SageMaker e fazer treinamento de ML, ou conectá-lo ao Quicksight para visualizar resultados de queries, são tecnicamente possíveis, mas exigem etapas de integração mais trabalhosas em comparação com o setup zero — funciona logo de cara — que o BigQuery oferece para os serviços similares Vertex AI (ML) e Looker (BI).
Considerando o custo excepcionalmente alto associado ao Redshift, seja na versão serverless ou de capacidade provisionada… eu, particularmente, não vejo benefício em usá-lo. Há várias opções melhores, inclusive dentro da própria AWS (AWS Athena e AWS EMR pareados com AWS Glue Data Catalog).
Se você quer equilibrar funcionalidades de valor agregado com o custo total, recomendo os data warehouses na seguinte ordem:
- GCP BigQuery (entrega o maior valor entre todas as opções de DWH)
- AWS Athena com AWS Glue Data Catalog
- AWS EMR com AWS Glue Data Catalog
- GCP Dataproc com GCP Dataproc Metastore
- AWS Redshift (entrega o menor valor entre todas as opções de DWH)
Apêndice
Os recursos de Reporting do DoiT Navigator foram usados para simplificar e acelerar a apuração do custo total de cada Parte. Essa plataforma unifica os gastos em todos os provedores de nuvem e permite criar relatórios com critérios complexos de agrupamento e filtragem com facilidade. Por exemplo, dá para obter em segundos, com bastante praticidade, um detalhamento dos gastos com nuvem por dia, provedor, serviço e SKU; esse tipo de relatório foi muito utilizado para reunir, sem esforço, os dados de gastos apresentados neste artigo.
Detalhes dos cálculos de custo e explicações sobre a complexidade das queries podem ser encontrados na base de código que acompanha este blog: Appendix.md
Ainda tem dúvidas sobre como aplicar essas recomendações para alcançar o sucesso com data warehousing no GCP ou na AWS dentro da sua organização?
Fale com a gente na DoiT International. Formada exclusivamente por talentos sêniores de engenharia, somos especialistas em consultoria avançada em nuvem, com foco em design arquitetural e suporte para debugging.