Welche Services sollte ich für Data Warehousing und Analytics auf GCP bzw. AWS einsetzen?

Wer diese Frage beantworten will, kommt mit einem reinen Funktionsvergleich nicht weit. Man muss die fein austarierten Preismodelle der DWH-Systeme und der zahlreichen Cloud-Services, auf denen sie aufsetzen, genau unter die Lupe nehmen.
Während sich Funktionen recht unkompliziert gegenüberstellen lassen, ist der Preisvergleich aus zwei Hauptgründen deutlich kniffliger:
- DWHs sind auf eine ganze Reihe weiterer Cloud-Services angewiesen, um Daten aufzubereiten und ins DWH zu laden. Jeder dieser Services verursacht Kosten, die zusätzlich zu den DWH-Kosten meist nicht zu vernachlässigen sind.
- Eine Bewertung der reinen DWH-Kosten erfordert sowohl die im DWH gespeicherte Datenmenge als auch die Methoden und die Häufigkeit, mit der diese Daten abgefragt werden, einzubeziehen. Unterschiedliche Abfragetypen und Ausführungsfrequenzen verursachen je nach genutztem DWH und gewähltem Preismodell stark unterschiedliche Kosten.
Um diese häufige Frage von Cloud-Kunden, die kosteneffizient skalieren wollen, fundiert zu beantworten, folgt unten ein detaillierter End-to-End-Kostenvergleich der Data-Warehousing-Optionen von GCP und AWS. Wir betrachten dabei die Kosten für:
- das Abrufen großer, mehrere TB umfassender Datensätze aus realen Genomik-Anwendungen
- Datentransformationen, die das Laden in ein Data Warehouse ermöglichen
- die Ausführung von 17 komplexen Abfragen, die nutzbare Ergebnisse liefern
(im Gegensatz etwa zu einfachen, beliebigen Benchmark-Abfragen)
Auch wenn die Gesamtkosten von Data-Warehousing-Operationen im Mittelpunkt dieses Artikels stehen, ziehe ich zusätzlich funktionale Vergleiche heran, um die Diskussion abzurunden und einen ganzheitlichen Leitfaden für die Auswahl eines Data Warehouse zu bieten.
Wenn Sie die hier diskutierten Kostenberechnungen selbst nachvollziehen möchten, finden Sie im Git-Repo zu diesem Artikel alles, was Sie brauchen, um meine Benchmarks möglichst einfach und automatisiert zu reproduzieren.
Falls beim Lesen Fragen zur Kostenberechnung aufkommen, finden Sie weitere Details im Anhang.
So weit die Vorrede – legen wir los!
Statt die Pointe zu verstecken, stelle ich meine aus den Benchmarks abgeleiteten Empfehlungen zur DWH-Auswahl gleich vorab vor.
Wenn Sie sich ausschließlich auf Kosteneffizienz konzentrieren und Mehrwertfunktionen außer Acht lassen, empfehle ich folgende Services – geordnet von voraussichtlich günstig bis teuer:
- AWS Athena mit AWS Glue Data Catalog (am günstigsten)
- AWS EMR mit AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc mit GCP Dataproc Metastore
- AWS Redshift (am teuersten)
Wenn Ihnen Mehrwertfunktionen wichtiger sind, empfehle ich folgende Reihenfolge, die Funktionsumfang und Kosten gegeneinander abwägt:
- GCP BigQuery (bietet den größten Mehrwert aller DWH-Optionen)
- AWS Athena mit AWS Glue Data Catalog
- AWS EMR mit AWS Glue Data Catalog
- GCP Dataproc mit GCP Dataproc Metastore
- AWS Redshift (bietet den geringsten Mehrwert aller DWH-Optionen)
Lesen Sie weiter, um die Begründung hinter diesen Empfehlungen besser nachvollziehen zu können.
Teil 1: Datenbeschaffung und -transformation
Um realistische Operationen im TB-Bereich möglichst praxisnah zu simulieren, arbeite ich mit menschlichen Genomdaten – ein Bereich, der von Natur aus mehrere TB umfasst und an kosteneffiziente Analytics oft besondere Anforderungen stellt.
Genomik-Terminologie streife ich nur am Rande, damit der Artikel zugänglich bleibt. Wer sich für skalierbare wissenschaftliche Workloads interessiert, findet im Git-Repo zu diesem Blog detaillierte, reproduzierbare Beispiele zur kosteneffizienten Umsetzung von Genomik-Workloads.
Konkret arbeite ich mit den folgenden zwei Datensätzen, die sich für ein nicht genomik-affines Publikum so zusammenfassen lassen:
- gnomAD genomes v4.0: gnomAD wird in der Genomforschung häufig eingesetzt, da es Populationshäufigkeitsdaten zu Mutationen aus Whole-Genome-Sequencing-Daten von 807.162 Personen enthält. Populationshäufigkeiten lassen sich unter anderem nutzen, um seltene Mutationen aufzuspüren, die – gerade weil sie selten sind – mit höherer Wahrscheinlichkeit klinisch relevant sind.
- Beispiel: Eine Mutation mit 25 % Populationshäufigkeit kommt bei 25 % der Gesamtbevölkerung vor. Eine derart häufige Mutation hat mit deutlich geringerer Wahrscheinlichkeit klinische Auswirkungen auf eine Person als etwa eine seltene Mutation (die aufgrund evolutionären Selektionsdrucks selten ist), die nur bei 0,01 % der Bevölkerung auftritt.
- Im Flat-File-Format ist gnomAD v4.0 im bgzipped Zustand ca. 830 GB groß.
- dbNSFP v4.6: Ein weiterer großer Datensatz aus der humangenetischen Forschung. dbNSFP fasst – in einer einzigen Datei – Dutzende funktionaler Impact-Vorhersagen und Annotationen für sämtliche Mutationen im menschlichen Genom zusammen, indem Daten aus mehreren Dutzend Datenbanken vereint werden. Die Breite und Tiefe der Daten in dbNSFP hilft Klinikern, die klinische Relevanz von Mutationen einzuschätzen.
- Im Flat-File-Format ist dbNSFP unkomprimiert ca. 250 GB groß.
Sowohl gnomAD als auch dbNSFP sind essenzielle Ressourcen der Präzisionsmedizin.
gnomAD wird in S3- und in GCS-Buckets gehostet, dbNSFP auf S3 – das Abrufen dieser Datensätze in Cloud-Konten ist also unkompliziert. Beide Datensätze liegen jedoch in Flat-File-Formaten vor, die für Forscher konzipiert sind, die mit schlecht skalierbarem, akademisch geprägtem Bioinformatik-Tooling arbeiten. gnomAD wird insbesondere in einem spezialisierten Bioinformatik-Flat-File-Format (bgzipped VCF) gespeichert, das weder ideal für Large-Scale-Analytics noch ein in DWHs akzeptiertes Standardformat ist.
Schritt eins unserer Reise durch die DWH-Kosten besteht daher darin, gnomAD und dbNSFP zunächst abzurufen und ihre riesigen Flat-Files in ein Data-Warehouse-freundliches Format zu überführen: Parquet.
Eines der kosteneffizientesten Tools für die Verarbeitung großer Flat-Files ist Apache Spark. Tatsächlich gehört Spark zu den kosteneffizientesten Tools für Analytics auf beliebigen großen Datensätzen, insbesondere wenn Parquet-Dateien als Input dienen. Spark ist nicht nur häufig eine Schlüsselkomponente in skalierbaren Daten-Pipelines, sondern lässt sich auch selbst als DWH einsetzen, wenn man damit Analytics auf in einem Bucket gespeicherten Parquet-Dateien ausführt.
Werfen wir vor diesem Hintergrund zunächst einen Blick auf die Kosten eines Spark-basierten Datenaufbereitungsschritts.
Das folgende Diagramm zeigt die Kosten für die Konvertierung der beiden Datenquellen von Flat-Files in Parquet, das Joinen beider Quellen, das Schreiben dieser zusammengeführten Datei als Parquet, das Bereitstellen eines Hive-Metastores zur Verwaltung der Parquet-Metadaten sowie das Speichern aller Parquet-Dateien in einem Bucket:
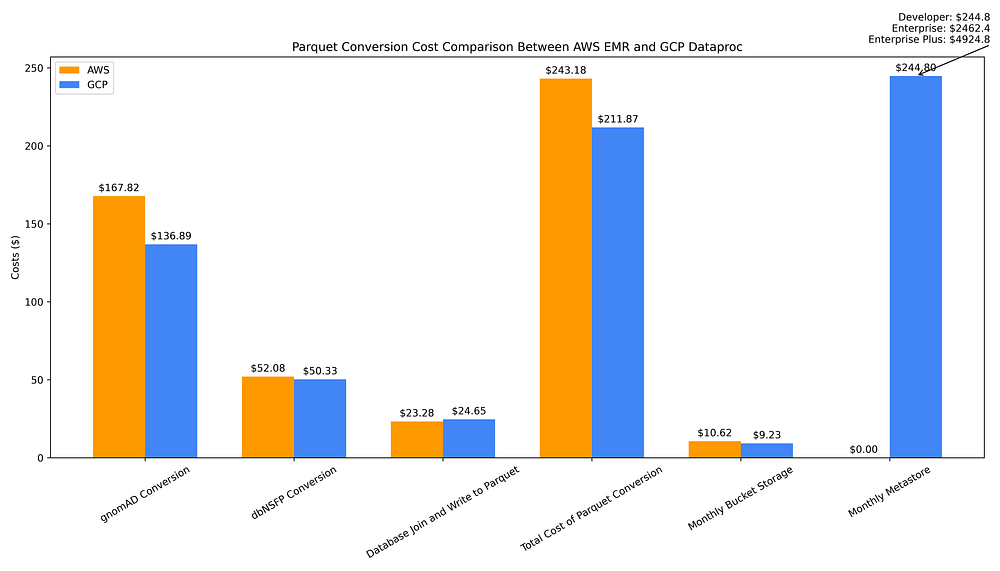
Vergleich der Data-Warehousing-Kosten von GCP vs. AWS für die Konvertierung Flat-File → Parquet, Parquet-Speicherung und Erstellung des Hive-Metastores
Die einmaligen Gesamtkosten für die Konvertierung der Flat-Files beider Datenbanken nach Parquet inklusive Zusammenführung in eine kombinierte Parquet-Datei fallen mit GCP Dataproc (211,87 $) leicht günstiger aus als mit AWS EMR (243,18 $). Ursache ist der hohe EMR-Aufschlag auf hochmoderne Graviton-Maschinen der 7. Generation wie r7g.16xlarge Spot Instances.
Die Kosten für die Speicherung der Parquet-Output-Dateien in regionalen Buckets sind über die Clouds hinweg vergleichbar – Sie sparen lediglich 1,39 $ pro Monat, wenn Sie die Parquet-Output-Daten in einem GCS-Bucket (9,23 $) statt auf S3 (10,62 $) ablegen.
Die langfristigen Betriebskosten für die Nutzung dieser Parquet-Dateien fallen auf GCP jedoch deutlich höher aus, da der vollständig verwaltete Metadaten-Service hier stündliche Kosten verursacht – im Gegensatz zu AWS, wo der Glue Data Catalog im Wesentlichen kostenlos ist, zumindest bis zur Nutzung in größerem Maßstab.
Beim Glue Data Catalog müssen Sie zunächst mehr als 1 Mio. gespeicherte Objekte überschreiten, bevor jenseits des Free Tiers von 1 Mio. Objekten magere 1 $ pro 100.000 Objekte und Monat anfallen. Auch Anfragen an den Data Catalog sind bis 1 Mio. pro Monat kostenlos; darüber hinaus zahlen Sie lediglich 1 $ pro Million zusätzlicher Anfragen.
Dem kostenlosen bis vernachlässigbaren AWS-Metastore stehen monatliche Kosten von 245 $ für den Dataproc Metastore gegenüber. Diese Dataproc-Kosten beziehen sich auf die Developer-Stufe, die laut Google "eingeschränkte Skalierbarkeit und keine Fehlertoleranz" bietet. Für Analytics in größerem Maßstab benötigen Sie die skalierbare, fehlertolerante Enterprise-Stufe – mit monatlichen Kosten von 2.462 $. Zusätzlich gibt es eine schlecht dokumentierte Enterprise-Plus-Stufe, die diese Monatskosten auf 4.924 $ verdoppelt (Gespräche mit einem GCP PM ergaben, dass "Plus" eine High-Availability-Konfiguration bedeutet).
Während die einmaligen Kosten für Datenkonvertierung und Metadatenerstellung auf AWS also leicht höher liegen und die langfristigen Speicherkosten in etwa gleich sind, hat AWS bei der Nutzung von Parquet-Dateien als Data Warehouse klar die Nase vorn – dank der vernachlässigbaren Kosten eines Parquet-Metastores. Ein Hive-Metastore ist sowohl für die Kosteneffizienz von Abfragen auf Parquet-Dateien als auch für deren komfortable Nutzung essenziell – etwa, weil sich Dateien so über "Tabellen"-Namen statt direkt über den Dateipfad abfragen lassen. Aus meiner Sicht ist er daher eine notwendige Komponente eines Parquet-basierten Data Warehouse.
Teil 2: Die Kosten von 17 komplexen Analyseabfragen
Wir haben verglichen, was es kostet, Terabytes an Flat-Files in das Parquet-Format zu überführen und einen Metadaten-Store zu hosten, um Abfragen darauf zu beschleunigen. Schauen wir uns nun die Kosten für die Ausführung von Abfragen auf diesen Datensätzen mit verschiedenen Cloud-Data-Warehouse-Services an.
Eine Übersicht der 17 Abfragen, die gegen jedes DWH ausgeführt werden, finden Sie im Anhang – sie verdeutlicht die Komplexität der Tests. Wer sich für Genomik interessiert, findet zusätzliche, ausführliche Erläuterungen in den Kommentaren der Code-Dateien.
Option 1: Ephemere Spark-Cluster als Data Warehouse
Beginnen wir mit der Annahme, dass unser Data Warehouse aus ephemeren Spark-Clustern besteht, die in einem Bucket gespeicherte Parquet-Dateien abfragen:
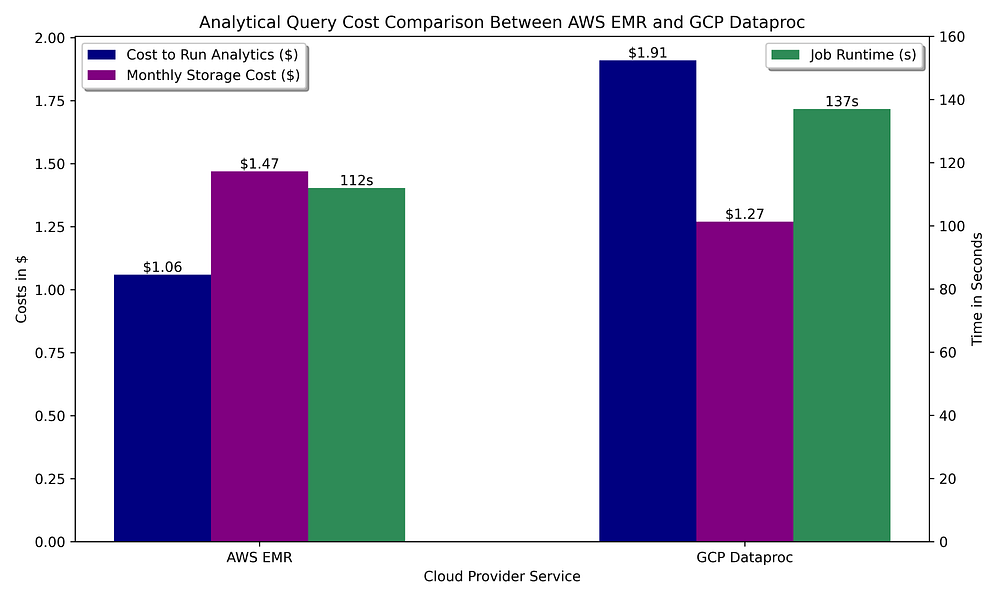
Vergleich der Data-Warehousing-Kosten GCP vs. AWS für OLAP-Abfragen mit Apache Spark und Parquet-Speicherung des abgefragten Datensatzes
Wie beim Spark-basierten Datenaufbereitungsschritt fallen die Analytics-Kosten auf den Managed-Spark-Angeboten in beiden Clouds ähnlich aus. AWS hat hier einen Vorteil gegenüber GCP, weil EMRs Auto-Termination bereits ab 60 Sekunden Idle-Zeit greift, während Dataproc minimal 5 Minuten zulässt. Da die Abfragen nur kurze Zeit benötigen, schlägt diese minimale unterstützte Idle-Dauer bis zur Cluster-Terminierung gegen GCP aus.
Die Spark-Funktionalität ist in beiden Clouds identisch – funktionale Vorteile gibt es also nicht. Mit der günstigeren, schnelleren Ausführung auf kurzlebigen EMR-Clustern und einem kostenlosen Metastore – im Vergleich zu den hohen Kosten eines Hive-Metastores auf GCP – fällt der Vergleich bei Spark-basierten Analytics deutlich zugunsten von AWS aus.
Option 2: Serverless-DWH-Angebote
Was, wenn wir Spark als DWH durch einen vollständig verwalteten, serverlosen Data-Warehouse-Service eines Cloud-Anbieters ersetzen wollen – mit Abfragen ausschließlich per SQL, um Spark-Code zu vermeiden?
Im Folgenden sehen Sie Kostenvergleiche von AWS Data Warehousing mit Athena und Redshift Serverless gegenüber GCP BigQuery on-demand. Es kommen dieselben 17 OLAP-Abfragen zum Einsatz wie in Schritt 2 Option 1. Erst dieser Vergleich macht die Kosteneffizienz der DWH-Optionen wirklich deutlich:
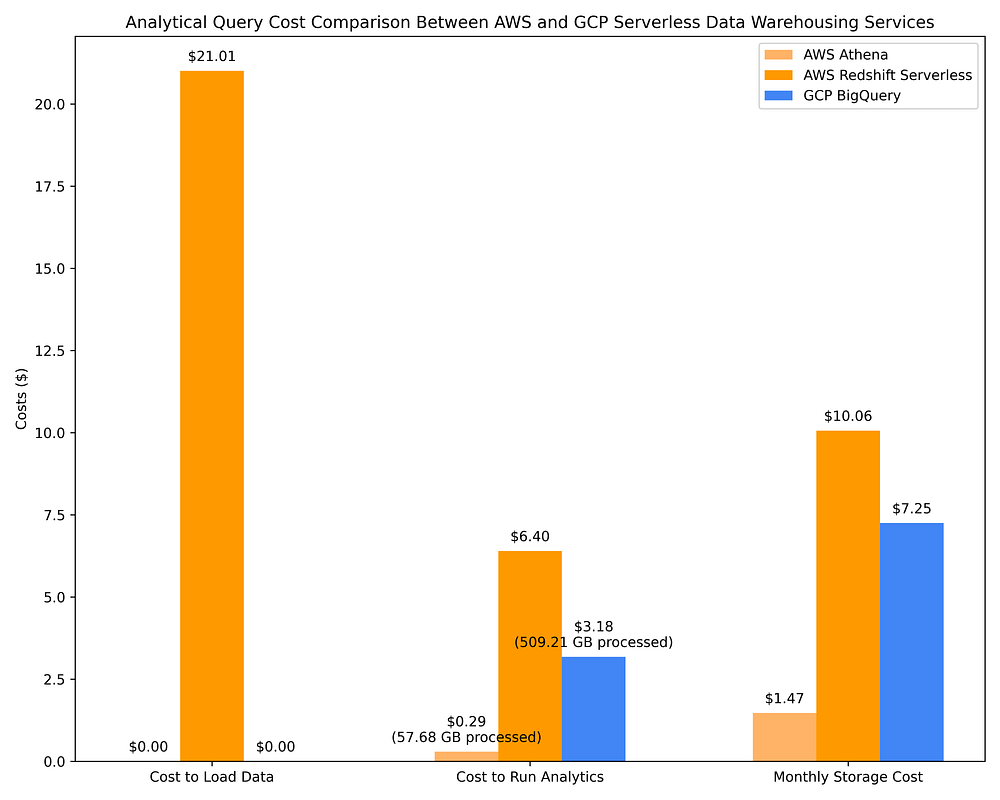
Vergleich der Data-Warehousing-Kosten GCP vs. AWS für OLAP-Abfragen mit Serverless-DWH-Services und Speicherung des abgefragten Datensatzes
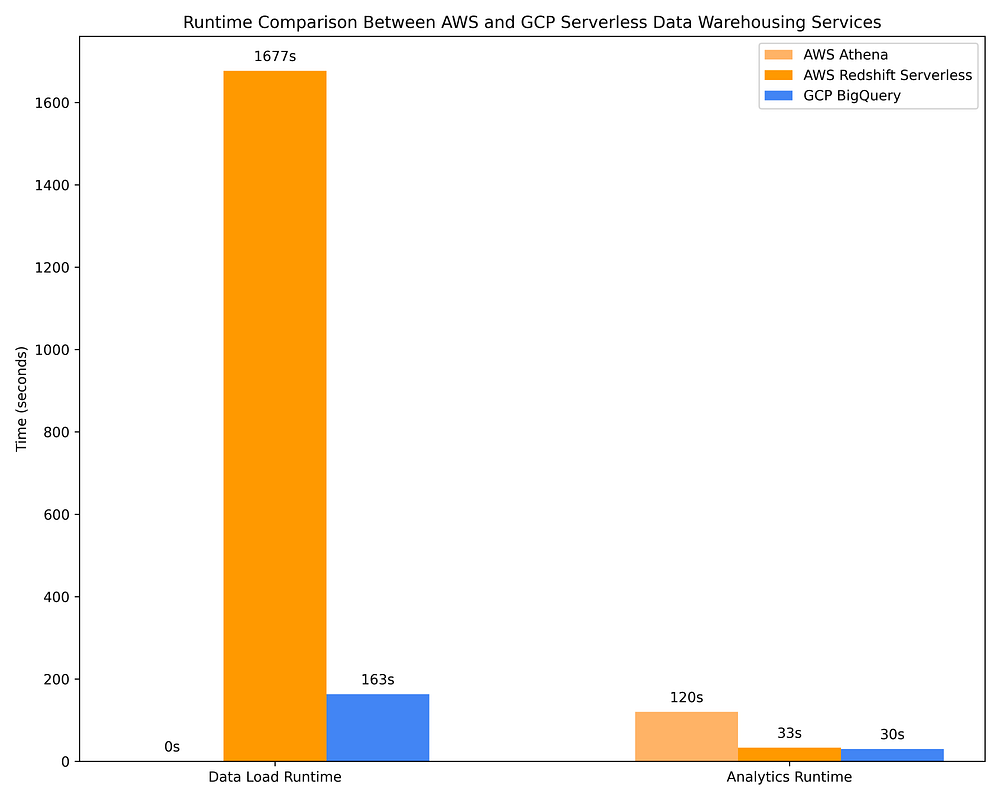
Vergleich der Data-Warehousing-Laufzeiten GCP vs. AWS für das Laden von Daten und das Ausführen von OLAP-Abfragen auf Serverless-DWH-Services
Redshift und BigQuery berechnen abfrageoptimierende Spalten-Metadaten beim Einfügen von Daten in eine Tabelle. Solche Metadaten optimieren Abfragen etwa durch Pushdown-Predicate-Filter, die die für eine Abfrage zu scannende Datenmenge reduzieren. Das senkt wiederum die Kosten von Abfragen, die nach gescannten TBs abgerechnet werden – entweder direkt (BigQuery) oder indirekt (Redshift über die für eine Abfrage benötigten RPUs).
Parquet-Dateien enthalten Metadaten; berechnen und speichern Sie zusätzliche Metadaten dazu mit Spark in einem Hive-Metastore, nutzen OLAP-Abfragen darauf sehr ähnliche abfrageoptimierende Spalten-Metadaten.
Ob Sie ein Serverless-DWH oder Spark-Cluster zur Abfrage von Parquet-Dateien einsetzen – Sie nutzen vorberechnete Spalten-Metadaten, die hochkomplexe Abfragen auf TBs an Daten typischerweise in Sekunden abschließen lassen, während nur wenige GB oder MB tatsächlich gescannt werden. Genau deshalb können beispielsweise 17 komplexe Abfragen gegen mehrere TB Daten kaum mehr als ein Vierteldollar kosten und nur 57,68 GB scannen, wie die AWS-Athena-Kosten oben zeigen.
Die Kostenvergleiche oben sowie aus Option 2 in Teil 1 zeigen, dass die Abfrage von Parquet-Dateien in Kombination mit einem Hive-Metastore – via AWS Athena, AWS EMR und GCP Dataproc – deutlich kosteneffizienter ist als die Abfrage über cloud-native Data-Warehouse-Services. Ein recht spannender Befund, wenn man bedenkt, dass alle diese Systeme auf demselben Prinzip basieren: Optimierung des Abfrageplans über Spalten-Metadaten in einem spaltenbasierten Dateisystem.
Dennoch sind Serverless-DWH-Angebote bei der Abfrageoptimierung anhand von Spalten-Metadaten bei Weitem nicht so effektiv. BigQuery scannt etwa rund 10× mehr Daten als AWS Athena, wenn Parquet-Dateien über den AWS Glue Data Catalog abgefragt werden – mit entsprechend rund 10× höheren Kosten. Die Abfragekosten von BigQuery liegen außerdem bei mehr als dem Doppelten derselben Abfragen auf ephemeren Spark-Clustern mit Spot-/Preemptible-Instanzen auf AWS EMR / GCP Dataproc. BigQuery erledigt seine Abfragen zwar etwa 4× schneller als AWS Athena, AWS EMR und GCP Dataproc, allerdings zu rund 10× höheren Kosten. Ob das den Mehrpreis wert ist, hängt vom Use Case ab.
AWS Redshift ist ein Service, der ursprünglich als Provisioned-Capacity-Service startete und erst viel später eine quasi-serverlose Variante erhielt (das "Serverless"-Angebot erfordert nach wie vor Kapazitätsplanung in Form der Skalierungskonfiguration für Redshift Processing Units, kurz RPU). Aufgrund dieser Wurzeln bleibt Redshift Serverless die teuerste der On-Demand-DWH-Optionen, vor allem weil das "Serverless"-Pricing weiterhin auf bereitgestellten Ressourcen statt auf gescannten TBs basiert. Redshift verhält sich zudem eher wie Postgres als wie ein cloud-natives Serverless Data Warehouse, hat keine eingebetteten Integrationen mit AWS IAM (was Datenfreigabe und feingranulare Tabellen-/Spalten-/Zeilen-Berechtigungen erschwert) und benötigt rund 9× länger als BigQuery, um Daten zu nicht trivialen Kosten in Tabellen zu laden … aus diesen Gründen kann ich Redshift persönlich nicht empfehlen. Es lohnt sich nur, wenn Ihre Data Engineers sehr Postgres-affin sind und – aus welchen Gründen auch immer – mit keiner anderen Data-Warehouse-Option arbeiten können.
Welches Data Warehouse sollten Sie wählen?
Empfehlung: Wenn nur die Kosten zählen
Sind allein die Kosten ausschlaggebend und lässt Ihr Use Case Parquet-Dateien als Backend zu (sprich: Ihre abgefragten Datensätze hängen nicht von Echtzeit-Streamingdaten ab), empfehle ich, Parquet-Dateien in einem Bucket zu speichern und mit einer Serverless-Query-Engine wie AWS Athena oder einem ephemeren Cluster-Service wie AWS EMR oder GCP Dataproc abzufragen. Serverless-Data-Warehouse-Angebote wie BigQuery und Redshift bieten Komfort, eine bessere Unterstützung für Echtzeit-Streaming-Use-Cases und viele weitere Mehrwertfunktionen, auf die ich gleich eingehe – das alles hat allerdings seinen Preis.
Wichtig zu wissen: Ab einer ausreichend großen Betriebsskala stoßen BigQuery und Redshift an künstliche Grenzen, die einen Wechsel vom On-Demand- zu einem ressourcenbasierten Preismodell (Slots/CPU) erzwingen. Dieser Wechsel ist meist teurer als das äquivalente On-Demand-Modell.
BigQuery on-demand rechnet pro gescanntem TB ab; allerdings stehen über alle Abfragen hinweg nur 2.000 Slots (~2.000 Cores und ~2 TB Speicher) zur Verfügung. Wichtige BigQuery-Funktionen wie BigQuery-ML-Abfragen lassen sich weder mit BQ on-demand noch mit BQ Editions Standard nutzen. Wenn Sie eines der folgenden Features benötigen, müssen Sie auf eine der drei ressourcenbasierten BigQuery-Editions-Stufen wechseln:
- Mehr als 2.000 Cores / 2 TB Speicher (Standard)
- ML-Training und -Vorhersagen innerhalb von BQ via SQL (Enterprise)
- Zeilen- und Spalten-Zugriffskontrollen (Enterprise)
- Materialized Views (Enterprise)
Die Kosteneffizienz der Skalierbarkeit von Redshift Serverless ist ähnlich begrenzt und erfordert ebenfalls einen Flat-Rate-Cluster, um diese Grenzen zu überwinden.
Ressourcenbasierte Preismodelle können komplex sein (besonders bei BigQuery Editions [1] [2] [3]) und es ist schwierig – wenn nicht unmöglich – zu einer wirklich belastbaren Kostenschätzung zu gelangen, ohne alle Workloads einige Tage lang auf einem ressourcenbasierten Deployment laufen zu lassen und daraus Monats- bzw. Jahreskosten abzuleiten. Es gibt Eigenheiten wie den fehlerbehafteten Slot-Autoscaler von BigQuery Editions (er skaliert nur in Schritten von 100 Slots und rechnet pro Slot-Menge mindestens 1 Minute ab, unabhängig davon, ob Abfragen die hochskalierten Slots überhaupt nutzen) sowie die unbekannte Variable, wie viele Slots Ihre Abfragen kollektiv tatsächlich brauchen – beides lässt sich nur durch einen vollständigen, produktionsähnlichen Test auf dem Flat-Rate-Modell sauber abbilden.
Unabhängig von den Pricing-Details habe ich bei vielen DoiT-Kunden beobachtet, dass Flat-Rate-Modelle in der Regel teurer sind als das On-Demand-Modell. Solange Sie nicht 24/7/365 OLAP-Abfragen ausführen – und nur dann, wenn diese durchgehend dieselbe Menge an Compute-Ressourcen verlangen –, wird Flat-Rate gegenüber On-Demand kaum nennenswerte Einsparungen bringen.
Vor diesem Hintergrund empfehle ich, wenn Sie sich ausschließlich auf Kosteneffizienz konzentrieren und Mehrwertfunktionen außer Acht lassen, folgende Services – geordnet von voraussichtlich günstig bis teuer:
- AWS Athena mit AWS Glue Data Catalog (am günstigsten)
- AWS EMR mit AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc mit GCP Dataproc Metastore
- AWS Redshift (am teuersten)
Damit ist die Diskussion aber noch nicht zu Ende. Es lohnt sich, die Kosten von Serverless-DWH-Systemen sorgfältig gegen die damit ermöglichten Funktionen abzuwägen.
Empfehlung: Wenn Kosten und Funktionsumfang gegeneinander abgewogen werden
Parquet-Dateien per Spark-Code oder Athena-SQL abzufragen, kann hochgradig kosteneffizient sein – allerdings hat dieser Ansatz Grenzen. Sie verzichten auf den Funktionsreichtum, den Services wie BigQuery mitbringen.
Im Folgenden einige der zentralen Vorteile, die BigQuery in vielen Fällen den Mehrpreis wert machen:
- Zugänglichkeit. Die BQ-UI ist schön gestaltet, einfach zu bedienen und schnell zu erlernen. Data Scientists – die unter Umständen wenig Lust haben, sich in Apache Spark und andere komplexe Systeme einzuarbeiten – freuen sich über eine angenehme, SQL-basierte Oberfläche zum Speichern und Abfragen von Daten.
- Point-in-Time-Recovery. PIT ist in BQ standardmäßig integriert, mit Time Travel von bis zu 7 Tagen als Default. Im Vergleich dazu könnten Sie zwar Bucket Versioning aktivieren, um versehentlich gelöschte Parquet-Dateien wiederherzustellen – das ist aber deutlich umständlicher als das Wiederherstellen einer Tabelle mit einem einzigen SQL-Befehl. Data-Lakehouse-Projekte wie Apache Iceberg und Delta Lake können SQL-basierte PIT-Recovery für Parquet-Dateien ermöglichen, doch in kurzen Tests, die ich durchgeführt habe, erhöhen Lakehouses die Abfragelaufzeit um mindestens das 2- bis 3-Fache. Mit einem Data Lakehouse verlieren Sie also den Performance- und Kostenvorteil, den die direkte Abfrage von Parquet-Daten via Apache Spark bietet.
- Native IAM-Integrationen. Da BQ auf GCP IAM aufbaut, lassen sich Daten erstaunlich einfach und auf sehr granularer Ebene teilen und absichern. Datasets und Tabellen lassen sich problemlos mit anderen GCP-Nutzern teilen. Sie können sogar einschränken, welche Spalten und Zeilen ein Nutzer einsehen darf. Solche Sharing- und Granular-Access-Funktionen bietet ein Parquet-basiertes Dateisystem nicht.
- Native Integrationen mit Real-Time-Streaming-Services. Wenn Echtzeit-Datenaufnahme entscheidend ist, integriert sich BigQuery nativ mit PubSub und Dataflow. Damit können Abfragen Echtzeit-Streamingdaten mit maximal wenigen Sekunden Latenz erreichen. In dieser Hinsicht hebt sich BigQuery von allen anderen DWH-Systemen ab; selbst die Echtzeit-Datenaufnahme von Snowflake kann mehrere Minuten brauchen, bis Daten verfügbar sind. Daten nahezu in Echtzeit abfragebereit zu machen, ist meines Wissens mit einem Parquet-basierten Dateisystem nicht möglich.
- Native Integrationen mit … so ziemlich allem. BigQuery hat einen UI/UX-Aspekt, den man nicht unterschätzen sollte. Mit BQ on-demand sehen Sie die geschätzten Kosten einer Abfrage, bevor Sie sie überhaupt starten. Angenommen, die Kosten sind in Ordnung und Sie führen die Abfrage aus: Mit einem einzigen Klick exportieren Sie die Ergebnisse nach Looker Studio, wo automatisch eine Visualisierung erstellt wird – basierend darauf, was der ML-gestützte Algorithmus von Looker Studio aus Ihren Abfrageergebnissen für sinnvoll hält. Genauso einfach lassen sich Abfrageergebnisse für Machine Learning in GCPs Vertex AI verschieben, ML-Modelle direkt in BigQuery via BQ ML SQL erstellen und deployen, Abfrageergebnisse nach Google Drive exportieren und so weiter. BigQuery ist nicht nur ein Data Warehouse. BigQuery ist Teil eines Service-Ökosystems, das scheinbar komplett um BigQuery herum aufgebaut ist.
Anders als BigQuery bringt Redshift leider mehr Kopfzerbrechen als Nutzen. In Sachen Kosteneffizienz und Funktionsreichtum landet es bei mir auf dem letzten Platz. Es verhält sich eher wie Postgres als wie ein Data Warehouse – wer es sinnvoll nutzen will, muss sich intensiv mit Tabellen-Tuning sowie der Anlage und Berechtigungsverwaltung von Nutzern und Gruppen innerhalb von Redshift auseinandersetzen, da seine IAM-Steuerung getrennt von AWS IAM bleibt.
Zwar ist es technisch möglich, sich mit AWS IAM bei Redshift zu authentifizieren, dies geschieht jedoch über Trusted Identity Propagation (SSO) – Sie müssen also nach wie vor eine Schnittstelle zwischen zwei separaten IAM-Systemen einrichten – und die individuellen AWS-IAM-Policies, die zusammen mit dem SSO-Setup einem AWS-Nutzer Zugriff auf die Redshift-Instanz gewähren, können nur grobe Rechte vergeben. Wenn Sie den Aktionsumfang einer AWS-IAM-Entität über Aktionen auf hoher Ebene hinaus einschränken möchten (z. B. feiner als "Cluster erstellen, ändern, löschen" oder als Vollzugriff bzw. reiner Lesezugriff auf eine Instanz), müssen Sie eine Rolle im IAM-System der Redshift-Instanz anlegen, die einen eingeschränkten, tabellenbezogenen Geltungsbereich erhält, und anschließend die Policy des AWS-IAM-Nutzers so anpassen, dass die Authentifizierung über SSO diese neue Cluster-IAM-Rolle annimmt … unterm Strich ist das ein dramatisch komplizierteres Setup als die verfügbaren Alternativen.
In BigQuery hingegen können Sie den Zugriff eines GCP-Nutzers auf ein Dataset, eine Tabelle oder sogar einzelne Zeilen oder Spalten innerhalb einer Tabelle einschränken, indem Sie das jeweilige Element einfach in der BigQuery-UI anklicken und dem GCP-IAM-Nutzer unmittelbar die entsprechenden, eng gefassten Berechtigungen erteilen. Bei Redshift müssen Sie sich ein halbes Dutzend Doku-Seiten zu Gemüte führen, um sicherzustellen, dass Sie granular auf Tabellenebene wirkende Berechtigungen korrekt einrichten – Berechtigungen, die sich nicht allein durch Sichtung der in AWS IAM vergebenen Policies auditieren lassen, weil sie auf granularen Policies beruhen, die nur innerhalb der IAM-Rollen von Redshift existieren. In BigQuery hingegen lassen sich granulare Berechtigungen mit kurzem Klick durch die UI vergeben, und weil BQ ausschließlich auf GCP IAM zur Authentifizierung setzt, lässt sich relativ einfach auditieren, wer Zugriff auf welche Tabellen hat oder welche sensiblen Spalten oder Zeilen einsehen darf.
Auch Redshift-Integrationen mit anderen Services sind eher unrund. Eine Anbindung an SageMaker für ML-Training oder an Quicksight zur Visualisierung von Abfrageergebnissen ist technisch zwar möglich, erfordert aber Integrationsschritte, die deutlich aufwendiger sind als das Out-of-the-Box-Setup von BigQuery für seine vergleichbaren Services Vertex AI (ML) und Looker (BI).
Angesichts der außergewöhnlich hohen Kosten von Redshift – egal ob Serverless- oder Provisioned-Capacity-Variante – sehe ich persönlich keinen Vorteil in seinem Einsatz. Es gibt mehrere bessere Optionen, auch innerhalb von AWS selbst (AWS Athena und AWS EMR in Kombination mit AWS Glue Data Catalog).
Wenn Sie Mehrwertfunktionen und Gesamtkosten ausbalancieren möchten, empfehle ich Data Warehouses in folgender Reihenfolge:
- GCP BigQuery (bietet den größten Mehrwert aller DWH-Optionen)
- AWS Athena mit AWS Glue Data Catalog
- AWS EMR mit AWS Glue Data Catalog
- GCP Dataproc mit GCP Dataproc Metastore
- AWS Redshift (bietet den geringsten Mehrwert aller DWH-Optionen)
Anhang
Für die Ermittlung der Gesamtkosten in jedem Teil habe ich die Reporting-Funktionen des DoiT Navigator genutzt – das beschleunigt und vereinfacht den Prozess deutlich. Die Plattform vereint Ausgaben über alle Cloud-Anbieter hinweg und ermöglicht das einfache Erstellen von Reports mit komplexen Gruppierungs- und Filterkriterien. Eine Aufschlüsselung der Cloud-Ausgaben nach Tag, Cloud-Anbieter, Service und SKU erhalten Sie beispielsweise innerhalb weniger Sekunden – diese Art von Report habe ich häufig genutzt, um die in diesem Artikel berichteten Ausgabedaten unkompliziert zusammenzustellen.
Details zur Kostenberechnung sowie Erläuterungen zur Komplexität der Abfragen finden Sie im Code-Repository, das diesen Blogbeitrag begleitet: Appendix.md
Haben Sie noch Fragen, wie Sie diese Empfehlungen nutzen, um GCP- oder AWS-Data-Warehousing in Ihrem Unternehmen erfolgreich umzusetzen?
Sprechen Sie uns bei DoiT International an. Unser Team besteht ausschließlich aus erfahrenen Senior Engineers, und wir sind spezialisiert auf fortgeschrittene Cloud-Beratung – von Architekturdesign bis hin zu Debugging.