GCPとAWSでデータウェアハウスや分析を行うなら、どのサービスを選ぶべきか?

この問いに答えるには、機能の比較だけでは不十分です。DWHシステムや、それが依存する数多くのクラウドサービスの複雑な料金体系まで踏み込む必要があります。
機能比較は比較的わかりやすい一方で、料金比較が格段に難しいのには、主に2つの理由があります。
- DWHにデータを準備・ロードする工程では、複数のクラウドサービスが関わってきます。これらのサービスにはDWH本体とは別に、決して無視できないコストが発生します。
- DWH単体のコストを評価するにも、格納するデータの規模だけでなく、そのデータをクエリする方法と頻度も考慮する必要があります。クエリの種類や実行頻度によって、利用するDWHや選択する料金モデル次第でコストは大きく変動するからです。
大規模なクラウド運用をコスト効率よく行いたいというお客様からよく寄せられるこの疑問に答えるべく、本記事ではGCPとAWSのデータウェアハウスをエンドツーエンドのコストで詳細に比較します。具体的には、以下のコストを検証します。
- 実際のゲノミクスアプリケーションで使われる、TB級の大規模データセットの取得
- データウェアハウスへのロードを容易にするデータ変換
- 有用な結果を得るための、複雑な17件のクエリの実行コスト
(単純で恣意的なベンチマーククエリを実行する場合との対比です)
本記事の主眼はデータウェアハウス運用全体のコストですが、議論を補完し包括的な選定ガイドとなるよう、機能面の比較も併せて行います。
本記事のコスト計算を再現してみたい方は、本記事のGitリポジトリをご参照ください。ベンチマークの再現を可能な限り簡単かつ自動化できるようになっています。
また、読み進める中でコスト計算方法についてご質問が出てきた場合は、付録に詳細を記載していますのでご確認ください。
それでは、本題に入りましょう。
結論を後回しにせず、ベンチマークから導いたデータウェアハウス選定の推奨事項を冒頭でお示しします。
付加機能を考慮せず、コスト効率のみを重視する場合、安価と思われる順に以下のサービスをおすすめします。
- AWS Athena + AWS Glue Data Catalog(最安)
- AWS EMR + AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc + GCP Dataproc Metastore
- AWS Redshift(最も高価)
付加機能を重視する場合は、機能とコストを天秤にかけた次の順序をおすすめします。
- GCP BigQuery(全DWHオプションの中で最も価値が高い)
- AWS Athena + AWS Glue Data Catalog
- AWS EMR + AWS Glue Data Catalog
- GCP Dataproc + GCP Dataproc Metastore
- AWS Redshift(全DWHオプションの中で最も価値が低い)
これらの推奨理由について、本文で詳しく解説していきます。
パート1:データの取得と変換
現実的なTB規模の運用を可能な限り忠実に再現するため、ヒトゲノムデータを用います。この領域は本質的にTB規模であり、コスト効率のよい分析を実現するうえで独特の課題があるためです。
読みやすさを優先し、ゲノミクス用語の細部には立ち入りません。スケーラブルな科学技術系ワークロードに関心のある読者は、本ブログのGitリポジトリをご覧ください。ゲノミクスのワークロードをコスト効率よく実装するための、詳細かつ再現可能な例を掲載しています。
本記事で扱うのは、以下の2つのデータセットです。ゲノミクス以外の読者向けに概要をまとめると次のとおりです。
- gnomAD genomes v4.0:ゲノミクス研究で広く利用されているデータセットで、807,162人分の全ゲノムシーケンスデータから検出された変異の集団頻度データを含みます。集団頻度は、希少であるがゆえに臨床的に意義のある可能性が高い「まれな変異」を見つけ出す用途などに使われます。
- 例:集団頻度25%の変異は、人類全体の25%に存在することを意味します。このような一般的な変異は、進化的圧力により0.01%しか保有していないようなまれな変異と比べ、個人への臨床的影響を及ぼす可能性は格段に低くなります。
- フラットファイル形式の場合、gnomAD v4.0はbgzip圧縮時でも約830GBに達します。
- dbNSFP v4.6:ヒトゲノム研究で使われるもう一つの大規模データセット。数十のデータベースを統合し、ヒトゲノム上のすべての変異に対する数十種類の機能的影響予測およびアノテーションを単一ファイルにまとめています。dbNSFPの広範かつ詳細なデータは、臨床医が変異の臨床的影響を評価する上で役立ちます。
- フラットファイル形式の場合、dbNSFPは非圧縮で約250GBになります。
gnomADとdbNSFPは、いずれもプレシジョン・メディシンにおいて極めて重要なリソースです。
gnomADはS3とGCSバケットの両方で、dbNSFPはS3でホストされているため、これらのデータセットをクラウドアカウントに取得すること自体は容易です。ただし、いずれもスケーラビリティに乏しい学術向けのバイオインフォマティクスツールでの探索を想定したフラットファイル形式で保管されています。特にgnomADはbgzip圧縮VCFという特殊なバイオインフォマティクス用フラットファイル形式で保存されており、大規模分析には不向きで、DWHが受け付ける標準形式でもありません。
そのためDWHコストを検証する第一歩として、まずgnomADとdbNSFPを取得し、巨大なフラットファイルをデータウェアハウスに適した形式であるParquetに変換する必要があります。
大規模なフラットファイルを扱う上で最もコスト効率の高いツールの一つがApache Spark です。実のところ、あらゆる大規模データセットの分析において、Sparkは最もコスト効率の高いツールの一つで、特にParquetファイルを入力として扱う場合に威力を発揮します。Sparkは大規模データパイプラインの中核を担うだけでなく、バケットに保管されたParquetファイルへの分析を実行することで、DWHとして利用することもできます。
これを踏まえ、まずSparkベースのデータ準備ステップの実行コストを見ていきましょう。
下のグラフは、2つのデータソースをフラットファイルからParquetに変換し、両者を結合してマージ済みファイルをParquetとして書き出し、Parquetメタデータ管理用のHive metastoreをプロビジョニングし、すべてのParquetファイルをバケットに保管するまでのコストを示しています。
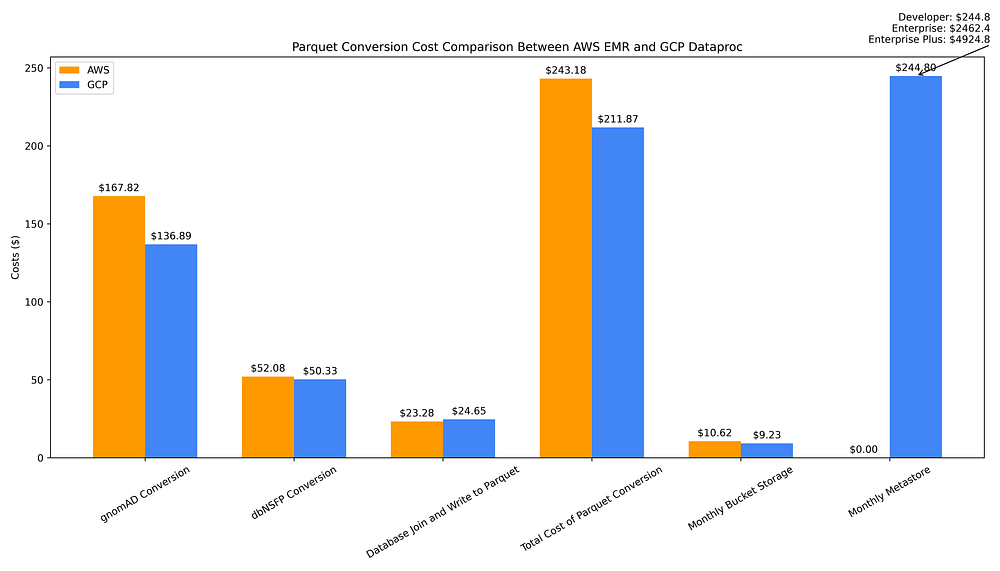
GCP vs. AWS:フラットファイル → Parquet変換、Parquet保管、Hive metastore作成のコスト比較
両データベースのフラットファイルをParquetに変換し、統合データベースのParquetファイルとして結合する一連の一回限りのコストは、合計でGCP Dataproc(211.87ドル)のほうがAWS EMR(243.18ドル)よりわずかに安く済みました。これは、r7g.16xlargeスポットインスタンスのような最新世代Gravitonマシンに対して高額なEMRサーチャージが課されるためです。
出力したParquetファイルをリージョンバケットに保管するコストはクラウド間でほぼ同等で、S3(10.62ドル)ではなくGCSバケット(9.23ドル)に保管しても、月あたりの差はわずか1.39ドルにとどまります。
しかし、Parquetファイルを長期的に運用する際のコストはGCPのほうが大幅に高くなります。GCPのフルマネージド型メタデータストアサービスは時間課金が発生する一方、AWSのGlue Data Catalogは大規模利用に達するまで実質的に無料だからです。
Glue Data Catalogでは、保存オブジェクト数が100万を超えるまでは無料、それ以降は100万オブジェクトの無料枠を超えた分について月あたり10万オブジェクトごとにわずか1ドルが課金されるだけです。Data Catalogへのリクエストも100万件までは無料、それを超えた分について月あたり100万リクエストごとに1ドルが課金されるのみです。
無料~ごくわずかな費用で済むAWSのメタストアと対照的に、Dataproc Metastoreは月額245ドルです。このDataprocコストはDeveloperティアの利用を前提としており、これは「スケーラビリティに制限があり、フォールトトレランスはありません」。大規模分析用途では、スケーラブルでフォールトトレラントなEnterpriseティアが必要となり、その月額は2,462ドルです。さらに、ドキュメントが乏しいEnterprise Plusティアではこの月額が倍の4,924ドルになります(GCPプロダクトマネージャーとの議論から、Plusは高可用性構成を意味することがわかりました)。
このように、一回限りのデータ変換とメタデータ作成コストはAWSのほうがわずかに高く、長期的な保管コストはほぼ同等ですが、Parquetファイルをデータウェアハウスとして利用するという観点では、Parquetメタストアのコストが極めて低いAWSに軍配が上がります。Hive metastoreは、Parquetファイルへのクエリのコスト効率を高めるだけでなく、ファイルパスを直接指定する代わりに「テーブル」名でクエリできるなど、アクセス性を高める上でも欠かせません。そのため、Parquetベースのデータウェアハウスにおいてmetastoreは必須コンポーネントだと考えています。
パート2:複雑な17件の分析クエリのコスト
ここまで、TB規模のフラットファイルをParquet形式に変換するコストと、それらのファイルへのクエリを高速化するためのメタデータストアをホストするコストを比較してきました。次に、これらのデータセットに対して複数のクラウドデータウェアハウスサービスでクエリを実行するコストを検証します。
各DWHで実行する17件のクエリの概要は付録に記載しており、実行されるクエリの複雑さがおわかりいただけると思います。ゲノミクスに関心のある読者向けには、コードファイル内のコメントでさらに詳しい説明を提供しています。
選択肢1:データウェアハウスとしてのエフェメラルSparkクラスター
まずは、データウェアハウスがバケット上のParquetファイルをクエリするエフェメラルなSparkクラスターで構成されると仮定して話を進めましょう。
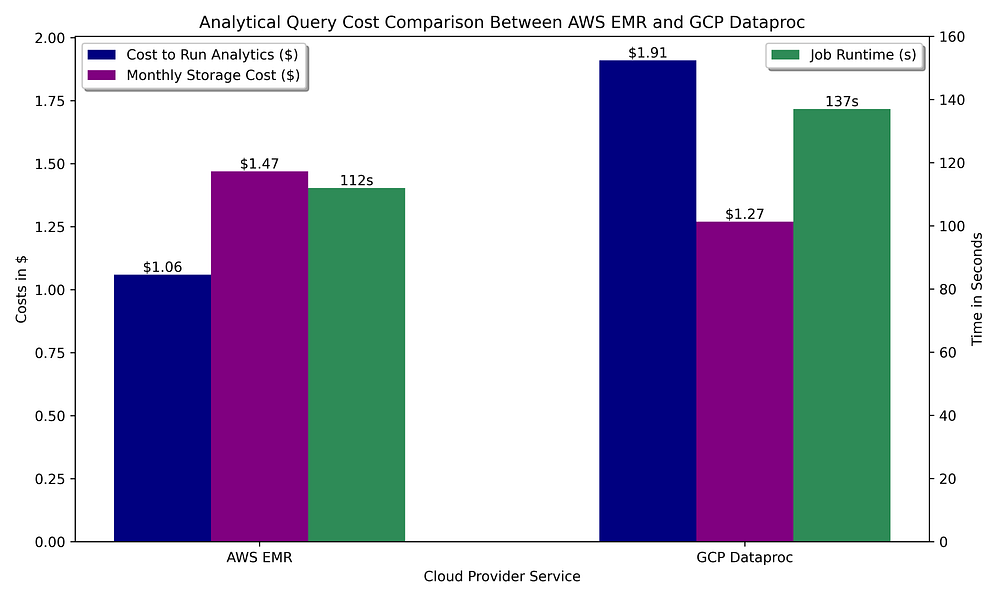
GCP vs. AWS:Apache SparkとParquet保管によるOLAPクエリ実行のコスト比較
Sparkを使ったデータ準備ステップと同様に、マネージドSparkでの分析実行コストは両クラウドで同水準です。このケースではAWSにわずかに分があります。EMRのアイドル時自動終了は最短60秒からクラスター終了を設定できるのに対し、Dataprocは最短でも5分までしか設定できないためです。これらのクエリは完了までに長時間を要さないので、最小アイドル時間の差がGCPに不利に働きます。
Sparkの機能は両クラウドで同一のため、機能面で実質的なアドバンテージはどちらにもありません。EMRは短命クラスターでより安価かつ高速に実行でき、メタストアも無料です。一方GCPはHive metastoreのホストコストが高いため、Sparkベースの分析は大きくAWSに傾きます。
選択肢2:サーバーレスDWHサービス
では、Sparkコードを書かずに済むよう、SparkをDWHとして使うのではなく、クラウドプロバイダーのフルマネージド・サーバーレスのデータウェアハウスサービス(SQLだけでクエリできるもの)に置き換えるとどうなるでしょうか?
下記は、AthenaとRedshift Serverlessを使ったAWSのデータウェアハウスと、GCP BigQueryのオンデマンドのコスト比較です。ステップ2の選択肢1で使用したのと同じ17件のOLAPクエリをこれらのDWHでも実行しています。この比較によって、各DWHのコスト効率の差がはっきりと見えてきます。
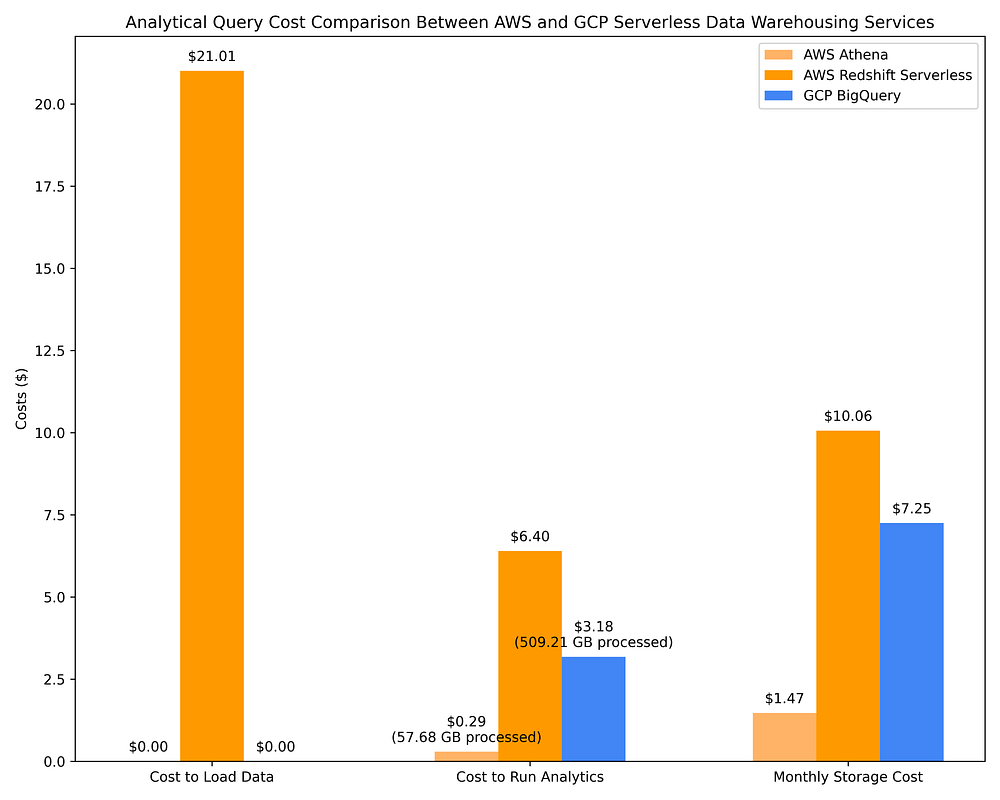
GCP vs. AWS:サーバーレスDWHサービスでのOLAPクエリ実行とデータセット保管のコスト比較
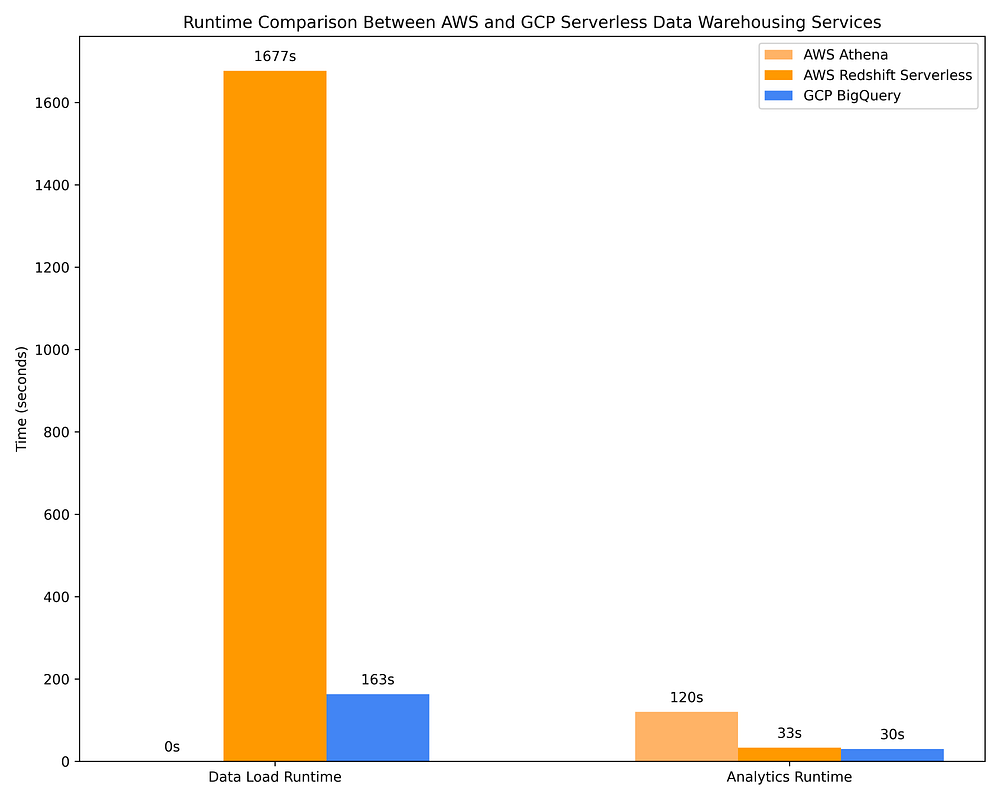
GCP vs. AWS:サーバーレスDWHサービスへのデータロードとOLAPクエリ実行の所要時間比較
RedshiftとBigQueryは、データがテーブルに挿入される際にクエリ最適化のためのカラムメタデータを計算します。このメタデータは、たとえばクエリ実行時にスキャンが必要なデータ量を削減するプッシュダウン述語フィルタを可能にし、クエリを最適化します。これにより、スキャンしたデータ量(TB単位)に基づいて直接(BigQuery)、あるいは間接的に(Redshiftはクエリ実行に必要なRPU数を経由)課金されるクエリのコストが削減されます。
Parquetファイルにはメタデータが含まれており、Sparkを使って追加のメタデータを計算しHive metastoreに保存しておけば、それらにヒットするOLAPクエリも非常によく似たクエリ最適化用カラムメタデータを利用できます。
サーバーレスDWHを使うにせよ、ParquetファイルをクエリするSparkクラスターを使うにせよ、事前計算されたカラムメタデータを活用することで、TB規模のデータに対する非常に複雑なクエリも、利用可能なメタデータのおかげで通常数秒で完了し、スキャン量はわずか数GB~数MBに抑えられます。これが、上のAWS Athenaのコスト例で、数TBのデータに対する17件の複雑なクエリを実行しても、スキャン量わずか57.68GBで25セント程度のコストに収まる理由です。
ここで示したコスト比較や、選択肢2のパート1での比較から、AWS Athena、AWS EMR、GCP Dataprocを通じてParquetファイルとmetastoreの組み合わせをクエリする方が、クラウドネイティブなデータウェアハウスサービスでクエリするよりもはるかにコスト効率に優れることがわかります。これらのシステムがいずれも、列指向ファイルシステムに対するカラムメタデータの活用というクエリプラン最適化の同じ原理に基づいていることを考えると、なかなか興味深い発見です。
とはいえ、サーバーレスDWHはカラムメタデータに基づくクエリ最適化において、それほど効率的とは言えません。たとえばBigQueryは、AWS Glue Data Catalog経由でParquetファイルをクエリするAWS Athenaに比べて約10倍のデータをスキャンし、結果として約10倍のコストが発生します。BigQueryのクエリコストは、AWS EMRやGCP DataprocでスポットインスタンスやプリエンプティブルインスタンスのエフェメラルSparkクラスターに同じクエリを実行する場合の2倍を超えます。BigQueryはAWS Athena、AWS EMR、GCP Dataprocより約4倍速くクエリを完了できる可能性がありますが、その代償としてコストは約10倍になります。ユースケース次第で、この追加コストに見合う価値があるかどうかは異なります。
AWS Redshiftは、もともとプロビジョン型キャパシティサービスとして始まり、後に準サーバーレス版が実装されたサービスです(「サーバーレス」サービスでも、Redshift Processing Unit(RPU)のスケーリング設定という形でキャパシティプランニングが必要です)。その出自を踏まえると、Redshift Serverlessは「サーバーレス」料金がスキャンしたTB単位のデータ量ではなくプロビジョンされたリソースに依存し続けているため、依然としてオンデマンドDWHの中で最も高価です。さらにRedshiftはクラウドネイティブなサーバーレスデータウェアハウスというよりPostgresに近い動作をし、AWS IAMとの組み込み統合がない(これによりデータ共有や狭範囲のテーブル/カラム/行レベル権限の付与が難しくなる)ことや、BigQueryと比べてテーブルへのデータロードに約9倍の時間と無視できないコストがかかることを考えると……個人的にはRedshiftをおすすめできません。データエンジニアがPostgresに非常に精通していて、かつ何らかの事情で他のデータウェアハウスを使えない場合に限って、有利と言えるでしょう。
どのデータウェアハウスを選ぶべきか?
推奨:コストだけが懸念事項の場合
コストだけが考慮事項であり、ユースケースがバックエンドとしてのParquetファイルに対応している場合(つまり、クエリ対象のデータセットがリアルタイムストリーミングデータに依存していない場合)は、Parquetファイルをバケットに保管し、AWS Athenaのようなサーバーレスクエリエンジンや、AWS EMR・GCP Dataprocのようなエフェメラルクラスターサービスでクエリすることをおすすめします。BigQueryやRedshiftといったサーバーレスデータウェアハウスは利便性、リアルタイムストリーミングへのより優れた対応、そしてこの後説明する多数の付加機能を提供してくれますが、それには相応のコストが伴います。
注意点として、運用規模が一定以上に大きくなると、BigQueryもRedshiftも人為的な制限に達し、オンデマンドからスロット/CPUリソースベースの料金モデルへ移行せざるを得なくなります。この移行は、同等のオンデマンドよりもコストがかさむ可能性が高いです。
BigQueryのオンデマンドはスキャンTBあたりで課金されますが、すべてのクエリにわたって使えるのは2,000スロット(約2,000コア・約2TBのメモリ)に限られます。また、BigQuery MLクエリのような主要なBigQuery機能は、BQ on-demandやBQ Editions Standardでは利用できません。次のいずれかが必要になると見込まれる場合、3つあるBigQuery Editionsのリソースベース料金ティアのいずれかへ移行する必要があります。
- 2,000コア / 2TBのメモリを超える容量(Standard)
- SQLを使ったBQ内でのML学習および予測の実行(Enterprise)
- 行レベル・カラムレベルのアクセス制御(Enterprise)
- マテリアライズドビュー(Enterprise)
Redshift Serverlessのスケーラビリティのコスト効率にも同様の制約があり、解決にはフラットレートクラスターが必要になります。
リソースベースの料金モデルは複雑になり得(特にBigQuery Editionsはその傾向が顕著です[1][2][3])、すべてのワークロードをリソースベースのデプロイ上で数日間実行し、そこから月次/年次コストを予測する以外に、本当に正確なコスト見積もりを得るのは困難、もしくは不可能です。BigQuery Editionの欠陥のあるスロットオートスケーラー(100スロット単位でしかスケーリングせず、オートスケールされたスロットがクエリで使われているかにかかわらず、特定のスロット量に対して最低1分間が課金される)などの癖や、すべてのクエリの実行に集計でどれだけのスロットが必要となるかという予測不可能な変数があり、フラットレートモデルで本番運用を完全にシミュレートしたテストを実施しないと織り込みようがありません。
料金詳細にかかわらず、多数のDoiTのお客様を見てきた経験から、フラットレート料金モデルは概してオンデマンドモデルよりも高くつきます。OLAPクエリを24時間365日体制で実行する予定があり、かつそれらのクエリが時間を通じて常に同じ計算リソース量を要求するというケースを除き、フラットレートはオンデマンド料金と比べてほとんど(あるいはまったく)節約にならないでしょう。
以上を踏まえると、付加機能を考慮せず、コスト効率のみを重視する場合、安価と思われる順に以下のサービスをおすすめします。
- AWS Athena + AWS Glue Data Catalog(最安)
- AWS EMR + AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc + GCP Dataproc Metastore
- AWS Redshift(最も高価)
ただし、議論はここで終わりません。サーバーレスDWHのコストを、それが提供する機能と慎重に天秤にかけることが重要です。
推奨:コストと機能性を天秤にかける場合
SparkコードやAthena SQLでParquetファイルをクエリする方法は非常にコスト効率が高い一方で、限界もあります。BigQueryのようなサービスがもたらす豊富な機能の利点を享受できなくなるのです。
多くの場合にBigQueryが追加コストを払う価値があると私が考える主な利点を以下に挙げます。
- アクセシビリティ。BQのUIは美しく、使いやすく、習得も容易です。Apache Sparkのような複雑なシステムの習得には消極的になりがちなデータサイエンティストにとって、データの保管とクエリのための洗練されたSQLベースUIはありがたい存在です。
- ポイントインタイムリカバリ。PITはBQに組み込まれており、デフォルトで最大7日間のタイムトラベルが設定されています。一方Parquet側では、誤って削除されたファイルの復元のためにバケットのバージョニングを有効化することはできますが、SQLコマンド一発でテーブルを復元するほど便利ではありません。Apache IcebergやDelta Lakeのようなデータレイクハウスプロジェクトを使えばParquetファイルにSQLベースのPITリカバリを実現できますが、私が試した簡単なテストではレイクハウスはクエリ実行時間を少なくとも2~3倍に増やしました。データレイクハウスに依存することで、Apache SparkのみでParquetデータをクエリすることによる高パフォーマンスなコスト面のアドバンテージを失うことになります。
- ネイティブなIAM統合。BQはGCP IAMに依存しているため、データの共有や、そのデータへのアクセス制御を非常にきめ細かいレベルで実現でき、しかも驚くほど簡単です。データセットやテーブルを他のGCPユーザーと共有するのも容易です。特定のカラムや特定の行を閲覧できるユーザーを制限することすらできます。共有や詳細なアクセス制御は、Parquetベースのファイルシステムでは得られないものです。
- ネイティブなリアルタイムストリーミングサービス統合。リアルタイムデータ取り込みが重要であれば、BigQueryはPub/SubおよびDataflowとネイティブに統合されています。これらのサービスにより、最大でも数秒のレイテンシでクエリがリアルタイムストリーミングデータにヒットできるようになります。BigQueryはこの点で他のあらゆるDWHシステムと一線を画しています。Snowflakeのリアルタイムデータ取り込みでさえ、利用可能になるまで数分かかることがあります。私の知る限り、ほぼリアルタイムでクエリ可能にすることは、Parquetベースのファイルシステムでは不可能です。
- ほぼあらゆるサービスとのネイティブ統合。BigQueryには軽視すべきでないUI/UX上の側面があります。BQのオンデマンドでは、クエリを実行する前にその推定コストを確認できます。コストを許容してクエリを実行したとしましょう。ボタン1クリックでそのクエリ結果をLooker Studioにエクスポートでき、Looker StudioのMLアルゴリズムがクエリ結果から可視化したいと推測した内容に基づいて、自動的にビジュアライゼーションが構築されます。同様に、機械学習のためにクエリ結果をGCPのVertex AIに移したり、BQ ML SQLを通じてBigQuery内でMLモデルを直接構築・デプロイしたり、クエリ結果をGoogle Driveにエクスポートしたりすることも簡単です。BigQueryは単なるデータウェアハウスではありません。BigQueryを中心に構築されたといってもよいサービスエコシステムの一部なのです。
BigQueryと違い、Redshiftは残念ながらメリットよりも頭痛の種をもたらします。コスト効率と機能性の両面で最下位に位置付けます。データウェアハウスというよりPostgresに近い動作をするため、使いこなすには、テーブルパフォーマンスの調整や、Redshift内のユーザー/グループ作成と権限管理に精通する必要があります(Redshift内のIAMコントロールはAWS IAMと別系統のままだからです)。
AWS IAMでRedshiftに認証することは技術的には可能ですが、これはTrusted Identity Propagation(SSO)を介して実現するもので、つまり別々の2つのIAMシステム間のインターフェースを構築する必要があります。SSOのセットアップと組み合わせるカスタムAWS IAMポリシーは、AWSユーザーへのRedshiftインスタンスへのアクセス権を付与する際に大まかな権限しか付与できません。AWS IAMエンティティができることのスコープを高レベルの操作以上に制限(たとえばクラスターの作成・変更・削除を可能にする以上のもの、あるいはインスタンスへのフルアクセスやフル読み取り専用アクセスを付与するよりも細かいもの)する必要がある場合は、Redshiftインスタンスのクラスター内のIAMシステムでテーブルレベルに絞り込んだロールを作成し、AWS IAMユーザーのポリシーを更新してSSO経由の認証時にその新クラスターのIAMロールを引き継ぐようにする必要があります……結局のところ、利用可能な代替手段と比べて、はるかに複雑なセットアップになります。
対照的にBigQueryでは、たとえばデータセット、テーブル、さらにはテーブル内の特定の行や列へのGCPユーザーのアクセスを、BigQuery UIで該当するエンティティをクリックし、その狭範囲の権限をGCP IAMユーザーに直接付与するだけで制限できます。Redshiftでは、テーブルレベルの細かい権限を正しく設定するために半ダースほどのドキュメントページを精査する必要があり、しかもそれらの権限はRedshiftのIAMロール内にしか存在しない細かいポリシーに依存しているため、AWS IAMで付与されたポリシーを閲覧するだけでは監査できません。一方BigQueryでは、UIを少し触るだけで詳細な権限を設定でき、かつBQが認証をGCP IAMのみに依存しているため、誰がどのテーブルにアクセスできるか、あるいは誰がテーブル内の特定の機微な列や行を閲覧できるかを判断する監査も比較的容易です。
Redshiftと他サービスとの統合も同様に煩雑です。SageMakerに接続してML学習を行ったり、QuickSightに接続してクエリ結果を可視化したりすることは、いずれも技術的には可能ですが、BigQueryが類似のVertex AI(ML)やLooker(BI)サービスに対して提供している、セットアップ不要で即座に動作する設定と比べると、より煩雑な統合手順を踏む必要があります。
サーバーレス版・プロビジョン型キャパシティ版のどちらを使うにせよ、Redshiftに伴う非常に高いコストを考えると……個人的にはRedshiftを使うメリットは見出せません。AWSの内部にも、より優れた選択肢が複数存在します(AWS AthenaおよびAWS Glue Data Catalogと組み合わせたAWS EMRなど)。
付加機能と総コストのバランスを取りたい場合は、以下の順序でデータウェアハウスをおすすめします。
- GCP BigQuery(全DWHオプションの中で最も価値が高い)
- AWS Athena + AWS Glue Data Catalog
- AWS EMR + AWS Glue Data Catalog
- GCP Dataproc + GCP Dataproc Metastore
- AWS Redshift(全DWHオプションの中で最も価値が低い)
付録
各パートの総コスト算出を簡素化・高速化するため、DoiT NavigatorのReporting機能を活用しました。このプラットフォームは、すべてのクラウドプロバイダーにまたがる支出を一元化し、複雑なグルーピングおよびフィルタリング条件を持つレポートを簡単に作成できます。たとえば、日別・クラウドプロバイダー別・サービス別・SKU別のクラウド支出の内訳を、わずかな操作で数秒以内に取得可能です。本記事で紹介している支出データの収集にも、この種のレポートが頻繁に活用されました。
コスト計算の詳細とクエリの複雑さに関する説明は、本ブログとペアになっているコードベース(Appendix.md)をご覧ください。
ここで紹介した推奨事項を活用して、組織内でGCPまたはAWSデータウェアハウスを成功させる方法について、まだご質問はありますか?
ぜひDoiT Internationalまでお問い合わせください。シニアエンジニアのみで構成された当社は、高度なクラウドコンサルティング、アーキテクチャ設計、デバッグに関するアドバイスを専門としています。