¿Qué servicios conviene usar para data warehousing y analítica en GCP / AWS?

Responder esta pregunta exige ir más allá de comparar funcionalidades. Obliga a analizar a fondo los modelos de Precios de los sistemas DWH y de los múltiples servicios cloud de los que dependen.
Mientras que comparar funcionalidades entre ofertas suele ser sencillo, comparar precios resulta bastante más difícil por dos razones principales:
- Los DWH dependen de varios servicios cloud para preparar y cargar datos. Cada uno de ellos tiene un costo nada despreciable, además del costo del propio DWH.
- Evaluar el costo del DWH por sí solo exige considerar tanto el volumen de datos almacenados como los métodos y la frecuencia con que se consultarán. Distintos tipos de consultas y frecuencias de ejecución se traducen en costos muy diferentes según el DWH y el modelo de Precios elegido.
Para responder mejor a esta pregunta tan habitual entre los clientes cloud que buscan operar de forma eficiente a escala, a continuación se presenta una comparación detallada de los costos integrales de las opciones de data warehousing en GCP y AWS. Es decir, examinaremos el costo de:
- Recuperar grandes datasets de varios TB usados en aplicaciones reales de genómica
- Las transformaciones de datos que facilitan su carga en un data warehouse
- Ejecutar 17 consultas complejas que arrojan resultados útiles
(en lugar de, por ejemplo, ejecutar consultas benchmark simples y arbitrarias)
Si bien el costo total de las operaciones de data warehousing es el foco principal de este artículo, también incluiré comparaciones funcionales para redondear la discusión y ofrecer una guía integral para elegir un data warehouse.
Si quieres reproducir alguno de los cálculos de costos que aquí se discuten, consulta el repositorio de Git de este artículo, pensado para que reproducir mis benchmarks sea lo más simple y automatizado posible.
Además, si te surge alguna duda sobre cómo se calcularon los costos a medida que avanzas, consulta el Apéndice para más detalles.
Dicho esto, ¡vamos al grano!
En lugar de dejar lo importante para el final, quiero adelantar mis recomendaciones para elegir un data warehouse, derivadas de los benchmarks.
Si te enfocas únicamente en la eficiencia de costos sin considerar funcionalidades de valor agregado, recomendaría los siguientes servicios, ordenados de mayor a menor probabilidad de ser los más económicos:
- AWS Athena con AWS Glue Data Catalog (el más económico)
- AWS EMR con AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (el más costoso)
Si te importa más la funcionalidad de valor agregado, recomiendo los productos en el siguiente orden, que pondera funcionalidad frente a costo:
- GCP BigQuery (aporta el mayor valor entre las opciones de DWH)
- AWS Athena con AWS Glue Data Catalog
- AWS EMR con AWS Glue Data Catalog
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (aporta el menor valor entre las opciones de DWH)
Sigue leyendo para entender mejor el razonamiento detrás de estas recomendaciones.
Parte 1: adquisición y transformación de datos
Para simular de la mejor manera operaciones realistas a escala de TB, voy a trabajar con datos del genoma humano, ya que este dominio es por naturaleza de varios TB y suele plantear retos únicos para lograr una analítica eficiente en costos.
Me mantendré alejado de la jerga genómica para que el contenido sea accesible. Sin embargo, para los lectores interesados en workloads científicos escalables, el repositorio de Git de este blog incluye ejemplos detallados y reproducibles para implementar workloads de genómica con eficiencia de costos.
Trabajaré específicamente con los siguientes dos datasets, que para una audiencia no especializada en genómica pueden resumirse así:
- gnomAD genomes v4.0: gnomAD se usa con frecuencia en investigación genómica, ya que contiene datos de frecuencia poblacional de mutaciones descubiertas a partir de la secuenciación del genoma completo de 807.162 individuos. Entre otros usos, las frecuencias poblacionales permiten encontrar mutaciones raras que, justamente por ser raras, tienen mayor probabilidad de tener relevancia clínica.
- Por ejemplo: una mutación con una frecuencia poblacional del 25% está presente en el 25% de la población humana. Una mutación tan común tiene mucha menos probabilidad de tener un impacto clínico en un individuo que, digamos, una mutación rara (rara debido a la presión evolutiva en su contra) que aparece solo en el 0,01% de la población humana.
- En formato de archivo plano, gnomAD v4.0, cuando está bgzipped, ocupa unos 830 GB.
- dbNSFP v4.6: otro gran dataset usado en la investigación del genoma humano. dbNSFP reúne —en un solo archivo— decenas de predicciones y anotaciones de impacto funcional para todas las mutaciones del genoma humano, unificando datos de varias decenas de bases de datos. La amplitud y profundidad de los datos de dbNSFP ayuda a los clínicos a evaluar el impacto clínico de las mutaciones.
- En formato de archivo plano, dbNSFP sin comprimir ocupa unos 250 GB.
Tanto gnomAD como dbNSFP son recursos clave en medicina de precisión.
gnomAD está alojado tanto en buckets de S3 como de GCS, y dbNSFP está alojado en S3, así que recuperar estos datasets desde cuentas cloud es sencillo. Sin embargo, ambos datasets se almacenan en formatos de archivo plano pensados para investigadores que los exploran con herramientas bioinformáticas de enfoque académico y poca escalabilidad. gnomAD, en particular, se almacena en un formato bioinformático especializado de archivo plano (VCF bgzipped) que ni es ideal para analítica a gran escala ni es un formato estándar aceptado por los DWH.
Por lo tanto, el primer paso de nuestro recorrido para explorar costos de DWH consiste en recuperar gnomAD y dbNSFP, y luego transformar sus enormes archivos planos a un formato amigable para data warehouses: Parquet.
Una de las herramientas más eficientes en costos para manipular grandes archivos planos es Apache Spark. De hecho, Spark es una de las herramientas más eficientes en costos para hacer analítica sobre cualquier dataset grande, sobre todo cuando se trabaja con archivos Parquet como entrada. Spark no solo suele ser una pieza clave en pipelines de datos a escala, sino que incluso puede usarse como un DWH al ejecutar analítica sobre archivos Parquet almacenados en un bucket.
Con eso en mente, revisemos primero el costo de ejecutar una etapa de preparación de datos basada en Spark.
El gráfico siguiente ilustra los costos de convertir las dos fuentes de datos de archivos planos a Parquet, unirlas y escribir ese archivo combinado en Parquet, aprovisionar un metastore Hive para mantener la metadata Parquet y almacenar todos los archivos Parquet en un bucket:
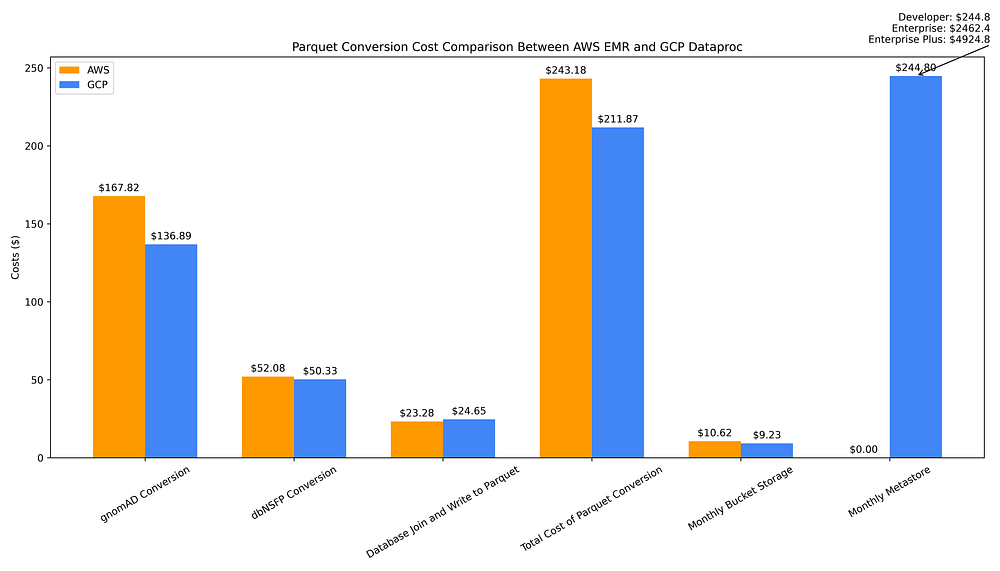
Comparación de costos de data warehousing GCP vs. AWS para conversión de archivos planos → Parquet, almacenamiento Parquet y creación de metastore Hive
El costo único total de convertir los archivos planos de ambas bases de datos a Parquet y unirlos en un archivo Parquet combinado resulta ligeramente más económico con GCP Dataproc (US$211,87) que con AWS EMR (US$243,18). Esto se debe al recargo elevado de EMR aplicado a las máquinas Graviton de 7ª generación de última tecnología, como las instancias Spot r7g.16xlarge.
El costo de almacenar los archivos Parquet de salida en buckets regionales es comparable entre ambas nubes: solo te ahorras US$1,39 al mes almacenando los datos Parquet de salida en un bucket de GCS (US$9,23) en lugar de S3 (US$10,62).
Sin embargo, los costos operativos a largo plazo asociados al uso de estos archivos Parquet son bastante mayores en GCP, ya que su servicio de metastore totalmente gestionado tiene un costo por hora, mientras que en AWS es prácticamente gratis con Glue Data Catalog, al menos hasta llegar a un uso a gran escala.
Con Glue Data Catalog, tendrías que superar el millón de objetos almacenados para empezar a pagar apenas US$1 por cada 100.000 objetos almacenados al mes por encima del nivel gratuito de 1 millón. Las solicitudes a Data Catalog también son gratuitas hasta el primer millón; a partir de ahí, solo se cobran US$1 por cada millón de solicitudes adicionales al mes.
Compara el metastore de AWS, cuyo costo va de gratuito a trivial, con el costo mensual de US$245 de Dataproc Metastore. Ese costo de Dataproc asume el uso del nivel Developer, que tiene "escalabilidad limitada y sin tolerancia a fallos". Para analítica a mayor escala, necesitarías el nivel Enterprise, escalable y tolerante a fallos, con un costo mensual de US$2.462. Además, existe un nivel Enterprise Plus poco documentado que duplica este costo mensual a US$4.924 (en conversaciones con un PM de GCP me indicaron que Plus implica obtener una configuración de Alta Disponibilidad).
Así, aunque los costos únicos de conversión de datos y creación de metadata son ligeramente mayores en AWS, y los costos de almacenamiento a largo plazo son similares, en cuanto al uso de archivos Parquet como data warehouse, AWS gana gracias al costo trivial de tener un metastore Parquet. Un metastore Hive resulta esencial tanto para mejorar la eficiencia de costos al consultar archivos Parquet como para hacerlos más fáciles y cómodos de acceder —por ejemplo, permitiendo consultarlos por nombres de 'tabla' en lugar de la ruta del archivo directamente—, así que lo considero un componente obligatorio en un data warehouse respaldado por Parquet.
Parte 2: el costo de 17 consultas analíticas complejas
Ya comparamos el costo de transformar terabytes de archivos planos al formato Parquet y de alojar un metastore para esos archivos a fin de acelerar los tiempos de consulta. Ahora examinemos el costo de ejecutar consultas contra estos datasets usando varios servicios de data warehouse en la nube.
En el Apéndice se incluye un resumen de las 17 consultas que se ejecutarán contra cada DWH, para resaltar la complejidad de las mismas. Para quienes estén interesados en genómica, hay explicaciones detalladas adicionales en los comentarios de los archivos de código.
Opción 1: clusters Spark efímeros como data warehouse
Empecemos asumiendo que nuestro data warehouse consiste en clusters Spark efímeros que consultan archivos Parquet almacenados en un bucket:
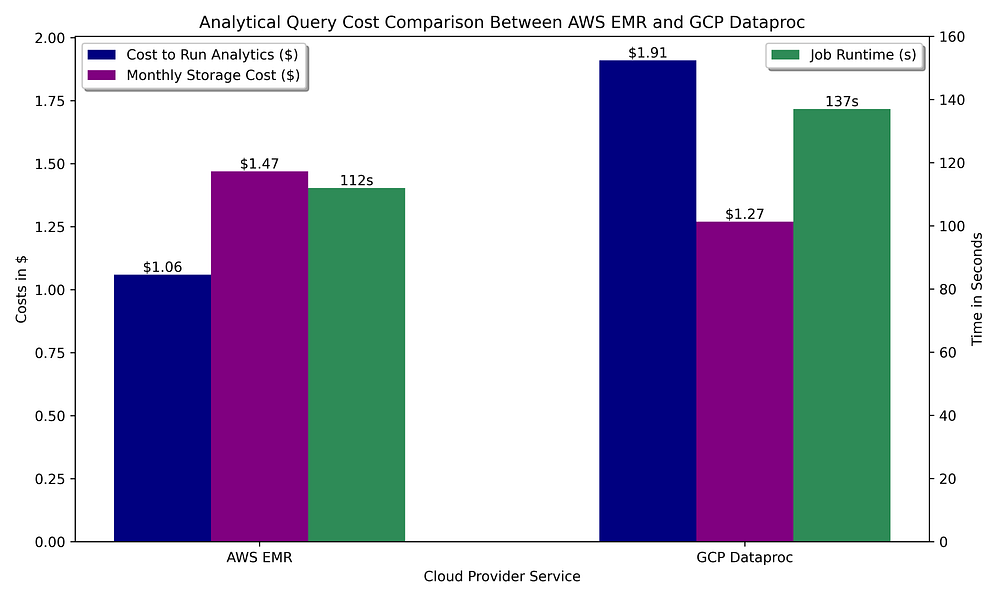
Comparación de costos de data warehousing GCP vs. AWS para ejecutar consultas OLAP con Apache Spark y almacenamiento Parquet del dataset consultado
Al igual que en la etapa de preparación de datos con Spark, ejecutar analítica en las ofertas Spark gestionadas tiene un costo similar en ambas nubes. En este caso, AWS le saca ventaja a GCP gracias a que la configuración de auto-terminación por inactividad de EMR permite hasta 60 segundos de inactividad antes de terminar el cluster, mientras que la de Dataproc solo puede llegar a 5 minutos como mínimo. Dado que estas consultas no tardan mucho en completarse, el tiempo mínimo de inactividad soportado para terminar el cluster juega en contra de GCP.
La funcionalidad de Spark es idéntica en cada nube, por lo que no hay una ventaja funcional real para ninguna. Con la ejecución más barata y rápida de EMR en clusters de corta duración y un metastore gratuito frente al alto costo de alojar un metastore Hive en GCP, la analítica basada en Spark se inclina con fuerza a favor de AWS.
Opción 2: ofertas DWH serverless
¿Qué pasa si queremos reemplazar Spark como DWH por un servicio de data warehouse serverless y totalmente gestionado del proveedor cloud —donde las consultas se pueden ejecutar solo con SQL— para evitar escribir código Spark?
A continuación se muestra la comparación de costos de data warehousing en AWS usando Athena y Redshift Serverless frente a GCP BigQuery on-demand. Se utilizan las mismas 17 consultas OLAP usadas en la Opción 1 del Paso 2 para estos DWH. Es con esta comparación que la eficiencia de costos de las opciones de DWH se hace evidente:
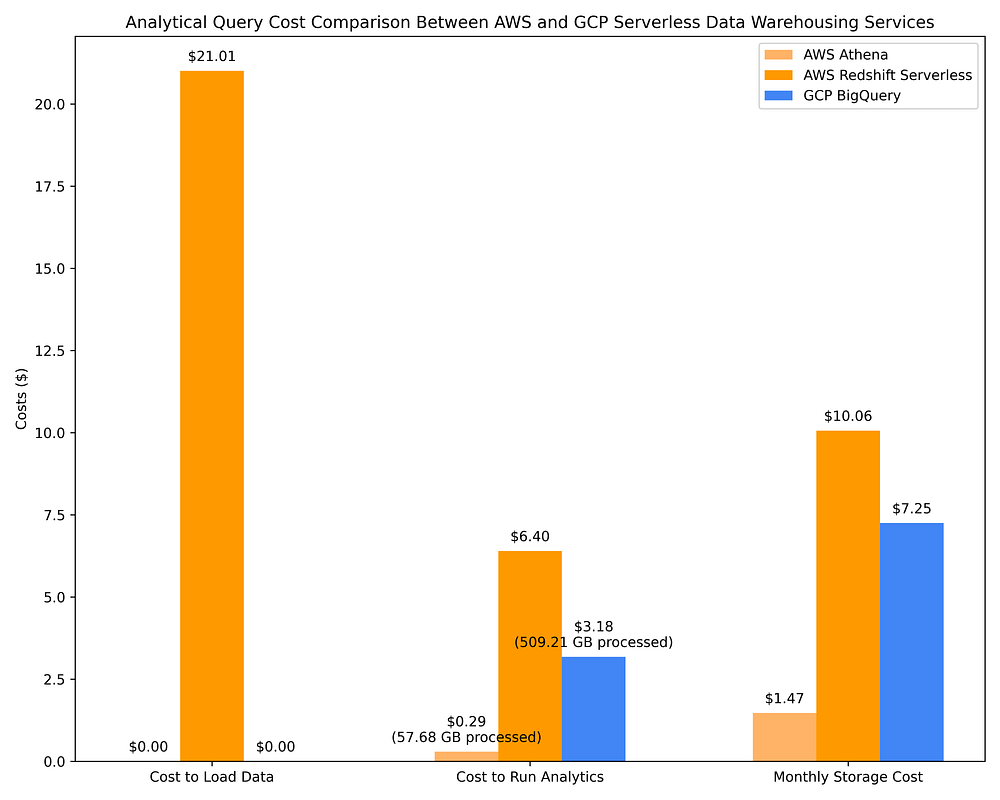
Comparación de costos de data warehousing GCP vs. AWS para ejecutar consultas OLAP con servicios DWH serverless y almacenamiento del dataset consultado
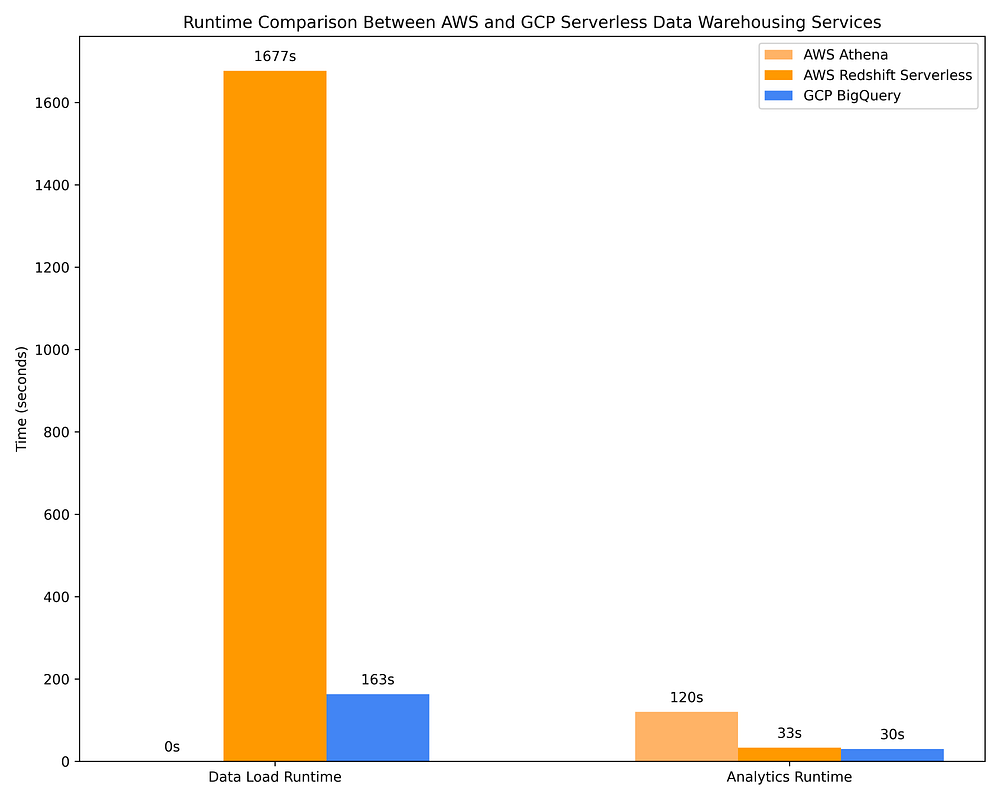
Comparación de tiempos de ejecución de data warehousing GCP vs. AWS para cargar datos y ejecutar consultas OLAP contra servicios DWH serverless
Redshift y BigQuery calculan metadata de columnas para optimizar consultas cuando se insertan datos en una tabla. Esa metadata optimiza las consultas, por ejemplo, habilitando filtros de pushdown predicate que reducen la cantidad de datos que se debe escanear para ejecutar una consulta. Esto, por extensión, reduce el costo de las consultas que se cobran según los TB de datos escaneados, ya sea directamente (BigQuery) o indirectamente (Redshift, vía la cantidad de RPUs requeridas para ejecutar una consulta).
Los archivos Parquet contienen metadata, y si calculas y almacenas metadata adicional sobre esos archivos en un metastore Hive usando Spark, las consultas OLAP que los ataquen se beneficiarán de una metadata de columnas optimizadora muy similar.
Ya sea que uses un DWH serverless o clusters Spark consultando archivos Parquet, estás aprovechando metadata de columnas precalculada que permite que consultas altamente complejas contra TB de datos se completen típicamente en segundos tras haber escaneado solo unos pocos GB o MB, gracias a la metadata disponible. Por eso, por ejemplo, ejecutar 17 consultas complejas contra varios TB de datos puede costar poco más de un cuarto de dólar tras escanear solo 57,68 GB, como se ve en los costos de AWS Athena arriba.
Las comparaciones de costos mostradas arriba, así como en la Opción 2 de la Parte 1, revelan que consultar archivos Parquet emparejados con un metastore Hive a través de AWS Athena, AWS EMR y GCP Dataproc resulta mucho más eficiente en costos que consultar con servicios de data warehouse nativos de la nube. Es un hallazgo bastante interesante considerando que todos estos sistemas se basan en el mismo principio de optimización del plan de consulta usando metadata de columnas para un sistema de archivos columnar.
Aun así, las ofertas DWH serverless no son ni de lejos tan efectivas optimizando consultas con base en metadata de columnas. BigQuery, por ejemplo, escanea unas 10 veces más datos que AWS Athena al consultar archivos Parquet vía AWS Glue Data Catalog, y cobra ~10 veces más como resultado. Los costos de consulta de BigQuery también superan en más del doble a los de ejecutar esas mismas consultas en clusters Spark efímeros con instancias Spot/preemptibles en AWS EMR / GCP Dataproc. BigQuery puede completar sus consultas ~4 veces más rápido que AWS Athena, AWS EMR y GCP Dataproc, pero esto tiene un costo ~10 veces mayor. Según tu caso de uso, esto puede o no valer el costo adicional.
AWS Redshift es un servicio que comenzó como un servicio de capacidad aprovisionada e implementó una versión casi-serverless mucho después (la oferta 'serverless' requiere planificación de capacidad mediante la configuración de escalado de Redshift Processing Unit, o RPU). Por su origen, Redshift Serverless sigue siendo la opción DWH on-demand más cara, en gran parte porque sus precios 'serverless' siguen dependiendo de los recursos aprovisionados en lugar de los TB de datos escaneados. Considerando que Redshift se comporta más como Postgres que como un data warehouse serverless nativo de la nube, que carece de integraciones embebidas con AWS IAM (lo que dificulta compartir datos con facilidad y aplicar permisos de alcance reducido a nivel de tabla/columna/fila) y que tarda ~9 veces más que BigQuery en cargar datos en tablas con un costo nada trivial… personalmente no puedo recomendar Redshift. Solo resulta ventajoso si tus ingenieros de datos están muy familiarizados con Postgres y, además, no pueden, por la razón que sea, trabajar con ninguna otra opción de data warehouse.
¿Qué data warehouse deberías elegir?
Recomendación: si el costo es la única preocupación
Si el costo es la única consideración, y si tu caso de uso admite archivos Parquet como backend (es decir, los datasets que consultas no dependen de datos en streaming en tiempo real), te recomiendo usar archivos Parquet almacenados en un bucket y consultarlos con un motor de consultas serverless como AWS Athena o un servicio de cluster efímero como AWS EMR o GCP Dataproc. Las ofertas de data warehouse serverless como BigQuery y Redshift ofrecen comodidad, mejor soporte para casos de uso de streaming en tiempo real y muchas otras funcionalidades de valor agregado que cubriré en breve, pero todo esto tiene un costo importante.
Vale la pena señalar que, a una escala operativa lo suficientemente grande, BigQuery y Redshift alcanzarán limitaciones artificiales que te obligarán a pasar de un modelo on-demand a un modelo de Precios basado en recursos por slots/CPU. Lo más probable es que este cambio cueste más que el equivalente on-demand.
BigQuery on-demand cobra por TB escaneado; sin embargo, está limitado a solo 2.000 slots (~2.000 cores y ~2 TB de memoria) para uso en todas las consultas. Tampoco puedes usar funciones clave de BigQuery, como las consultas BigQuery ML, con BQ on-demand ni siquiera con BQ Editions Standard. Si anticipas necesitar alguna de las siguientes, debes pasar a uno de los tres niveles de Precios de BigQuery Editions basados en recursos:
- Más de 2.000 cores / 2 TB de memoria (Standard)
- Ejecutar entrenamientos y predicciones de ML dentro de BQ usando SQL (Enterprise)
- Controles de acceso a nivel de fila y columna (Enterprise)
- Vistas materializadas (Enterprise)
La eficiencia de costos de la escalabilidad serverless de Redshift es similarmente limitada y también requiere un cluster de tarifa fija para resolverlo.
Los modelos de Precios basados en recursos pueden ser complejos (en particular para BigQuery Editions [1] [2] [3]) y difíciles —si no imposibles— de estimar con verdadera precisión sin ejecutar todos los workloads en una implementación basada en recursos durante unos días y, a partir de eso, proyectar los costos mensuales/anuales. Hay particularidades, como el autoescalador de slots defectuoso de BigQuery Editions (solo escala en incrementos de 100 slots y factura un mínimo de 1 minuto para una cantidad de slots dada, sin importar si las consultas están usando esos slots autoescalados), así como la variable desconocida de cuántos slots requerirán colectivamente todas tus consultas, que no se pueden tener en cuenta sin ejecutar todos los workloads en una prueba completa que simule producción sobre el modelo de tarifa fija.
Más allá de los detalles de Precios, he observado en muchos clientes de DoiT que los modelos de Precios de tarifa fija suelen costar más que el modelo on-demand. A menos que planees ejecutar consultas OLAP 24/7/365, y solo si esas consultas solicitan consistentemente la misma cantidad de recursos de cómputo a lo largo del tiempo, es poco probable que la tarifa fija te ahorre mucho —si es que algo— en comparación con los Precios on-demand.
Con base en lo anterior, si te enfocas únicamente en la eficiencia de costos sin considerar funcionalidades de valor agregado, recomendaría los siguientes servicios, ordenados de mayor a menor probabilidad de ser los más económicos:
- AWS Athena con AWS Glue Data Catalog (el más económico)
- AWS EMR con AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (el más costoso)
Sin embargo, no daría por cerrada la conversación aquí. Es importante sopesar con cuidado el costo de los sistemas DWH serverless frente a las funcionalidades que habilitan.
Recomendación: si se pondera el costo frente a la funcionalidad
Consultar archivos Parquet con código Spark o SQL de Athena puede ser muy eficiente en costos, pero este enfoque tiene limitaciones. Te perderás las ventajas de riqueza de funciones que aportan servicios como BigQuery.
A continuación, algunas de las ventajas clave que, en mi opinión, hacen que BigQuery valga el costo extra en muchos casos:
- Accesibilidad. La UI de BQ es preciosa, fácil de usar y fácil de aprender. Los data scientists —que pueden ser menos propensos a aprender Apache Spark y otros sistemas complejos— apreciarán contar con una UI agradable y basada en SQL para almacenar y consultar datos.
- Recuperación a un punto en el tiempo. PIT viene incorporado en BQ, con time travel de hasta 7 días por defecto. En cambio, aunque podrías activar el versionado del bucket para permitir restaurar archivos Parquet eliminados accidentalmente, esto no es tan cómodo como restaurar una tabla con un solo comando SQL. Proyectos de data lakehouse como Apache Iceberg y Delta Lake pueden habilitar la recuperación PIT basada en SQL sobre archivos Parquet, pero en pruebas breves que he hecho, los lakehouses aumentan el tiempo de ejecución de consultas al menos 2 a 3 veces. Al depender de un data lakehouse, pierdes las ventajas de alto rendimiento y bajo costo que ofrece consultar datos Parquet únicamente con Apache Spark.
- Integraciones nativas con IAM. La dependencia de BQ del IAM de GCP hace posible —y sorprendentemente fácil— compartir datos y controlar el acceso a esos datos con un nivel muy granular. Es sencillo compartir datasets y tablas con otros usuarios de GCP. Incluso puedes limitar la capacidad de los usuarios para ver columnas y filas específicas. Compartir y el control de acceso granular no es algo que vayas a obtener con un sistema de archivos respaldado por Parquet.
- Integraciones nativas con servicios de streaming en tiempo real. Si la ingesta de datos en tiempo real es clave, BigQuery se integra de forma nativa con PubSub y Dataflow. Estos servicios permiten que las consultas accedan a datos en streaming en tiempo real con apenas unos segundos de latencia como máximo. BigQuery se distingue de todos los demás sistemas DWH en este aspecto; incluso la ingesta de datos en tiempo real de Snowflake puede tardar varios minutos en estar disponible. Hacer que los datos estén disponibles para consulta casi en tiempo real, hasta donde sé, no es posible con un sistema de archivos respaldado por Parquet.
- Integraciones nativas con… casi todo. Hay un aspecto de UI/UX en BigQuery que no se debe subestimar. Con BQ on-demand, puedes ver el costo estimado de una consulta antes incluso de ejecutarla. Supongamos que el costo de una consulta te parece bien y la ejecutas. Con un solo clic, puedes exportar los resultados de esa consulta a Looker Studio, donde se construye automáticamente una visualización con base en lo que el algoritmo impulsado por ML de Looker Studio cree que querrás visualizar de los resultados de tu consulta. Es igual de fácil mover los resultados de la consulta a Vertex AI de GCP para machine learning, construir/desplegar un modelo ML directamente dentro de BigQuery a través de BQ ML SQL, exportar los resultados a Google Drive, etcétera. BigQuery no es solo un data warehouse. BigQuery es parte de un ecosistema de servicios construido aparentemente alrededor de BigQuery por completo.
A diferencia de BigQuery, lamentablemente Redshift ofrece más dolores de cabeza que beneficios. Lo pondría en último lugar en términos de eficiencia de costos y riqueza de funciones. Se comporta más como Postgres que como un data warehouse y, por eso, usarlo bien exige familiarizarse a fondo con el ajuste fino del rendimiento de tablas, así como con la creación de usuarios/grupos y los permisos dentro de Redshift, debido a que sus controles IAM permanecen separados de AWS IAM.
Si bien técnicamente es posible autenticarse en Redshift con AWS IAM, esto se logra mediante Trusted Identity Propagation (SSO) —lo que significa que aún hay que configurar una interfaz entre dos sistemas IAM separados— y las políticas personalizadas de AWS IAM que deben construirse y emparejarse con la configuración de SSO para otorgarle a un usuario de AWS acceso a la instancia de Redshift solo permiten otorgar permisos amplios. Si necesitas limitar el alcance de lo que una entidad de AWS IAM puede hacer más allá de acciones de alto nivel (por ejemplo, más allá de habilitar la creación, modificación o eliminación de un cluster, o de algo más granular que, digamos, otorgar acceso completo o acceso completo de solo lectura a una instancia), entonces tienes que crear un rol usando el sistema IAM de la instancia de Redshift al que se le asigna un alcance acotado a nivel de tabla, luego actualizar la política del usuario de AWS IAM para que la autenticación a través de SSO asuma el rol IAM del nuevo cluster… al final del día, es una configuración drásticamente más complicada en comparación con las alternativas disponibles.
En contraste, en BigQuery, por ejemplo, puedes limitar el acceso de un usuario de GCP a un dataset, una tabla, o incluso filas o columnas específicas dentro de una tabla con solo hacer clic en la entidad relevante en la UI de BigQuery y otorgarle dichos permisos de alcance reducido directamente al usuario de GCP IAM. Redshift exige consultar media docena de páginas de documentación para asegurarte de configurar correctamente permisos granulares a nivel de tabla —permisos que no se pueden auditar únicamente viendo las políticas otorgadas en AWS IAM, debido a la dependencia de políticas granulares que existen solo dentro de los roles IAM de Redshift. Dentro de BigQuery, en cambio, puedes configurar permisos granulares jugando un rato con la UI, y como BQ depende únicamente de GCP IAM para la autenticación, determinar quién tiene acceso a qué tablas, o incluso quién está autorizado a ver columnas o filas sensibles específicas dentro de las tablas, es relativamente sencillo de auditar.
Las integraciones de Redshift con otros servicios son igual de torpes. Conectarlo con SageMaker para realizar entrenamientos de ML, o conectarlo con Quicksight para visualizar los resultados de las consultas, técnicamente se pueden hacer, pero requieren pasos de integración más engorrosos en comparación con la configuración cero, lista para usar, que ofrece BigQuery con sus servicios equivalentes Vertex AI (ML) y Looker (BI).
Considerando el costo excepcionalmente alto asociado con Redshift, ya sea que uses su versión serverless o de capacidad aprovisionada… personalmente no le veo ningún beneficio a usarlo. Hay varias mejores opciones, incluso dentro de la propia AWS (AWS Athena y AWS EMR emparejados con AWS Glue Data Catalog).
Si quieres equilibrar la funcionalidad de valor agregado con el costo total, recomiendo data warehouses según el siguiente orden:
- GCP BigQuery (aporta el mayor valor entre las opciones de DWH)
- AWS Athena con AWS Glue Data Catalog
- AWS EMR con AWS Glue Data Catalog
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (aporta el menor valor entre las opciones de DWH)
Apéndice
Se aprovecharon las capacidades de Reporting de DoiT Navigator para simplificar y acelerar la determinación del costo total de cada Parte. Esta plataforma unifica el gasto en todos los proveedores cloud y permite crear fácilmente reportes con criterios complejos de agrupación y filtrado. Por ejemplo, un desglose del gasto cloud por día, proveedor, servicio y SKU se obtiene en segundos con relativa facilidad; este tipo de reporte se utilizó con frecuencia para reunir sin esfuerzo los datos de gasto reportados en este artículo.
Los detalles de cálculo de costos y las explicaciones sobre la complejidad de las consultas se encuentran en el código que acompaña a este blog: Appendix.md
¿Aún tienes preguntas sobre cómo aplicar las recomendaciones que te he dado para lograr el éxito en data warehousing en GCP o AWS dentro de tu organización?
Contáctanos en DoiT International. Conformados exclusivamente por talento senior de Engineering, nos especializamos en brindar consultoría avanzada en arquitectura cloud y asesoría en debugging.