Quali servizi conviene utilizzare per il data warehousing e l'analytics su GCP / AWS?

Per rispondere a questa domanda non basta confrontare le funzionalità dei singoli servizi: occorre analizzare a fondo i modelli di pricing, spesso tutt'altro che lineari, dei sistemi DWH e dei numerosi servizi cloud da cui dipendono.
Se il confronto delle funzionalità tra le diverse offerte è relativamente immediato, paragonare i prezzi è molto più complesso, per due ragioni principali:
- I DWH si appoggiano a diversi servizi cloud per preparare e caricare i dati. Ciascuno di questi servizi ha un costo tutt'altro che trascurabile, che si somma a quello del DWH vero e proprio.
- Per valutare il costo del solo DWH bisogna tenere conto sia del volume di dati archiviati, sia delle modalità e della frequenza con cui tali dati verranno interrogati. Tipologie di query e frequenze di esecuzione diverse generano costi molto differenti a seconda del DWH scelto e del modello di pricing adottato.
Per rispondere in modo più puntuale a questa domanda, ricorrente tra i clienti cloud che vogliono operare in modo cost-efficient su larga scala, proponiamo di seguito un confronto dettagliato dei costi end-to-end delle opzioni di data warehousing su GCP e AWS. Esamineremo nello specifico il costo di:
- Recuperare dataset di grandi dimensioni, dell'ordine di diversi TB, utilizzati in applicazioni reali di genomica
- Eseguire trasformazioni dei dati per agevolarne il caricamento in un data warehouse
- Eseguire 17 query complesse che producono risultati realmente utili
(invece di limitarsi, ad esempio, a semplici query benchmark arbitrarie)
Sebbene il fulcro di questo articolo sia il costo complessivo delle operazioni di data warehousing, proporrò anche alcuni confronti funzionali per arricchire la discussione e offrire una guida a 360° alla scelta del data warehouse.
Per chi volesse riprodurre i calcoli di costo qui presentati, è possibile consultare il repository Git associato all'articolo, pensato per rendere la replica dei benchmark il più semplice e automatizzata possibile.
Per qualsiasi dubbio sulle modalità di calcolo dei costi durante la lettura, può fare riferimento all'Appendice per ulteriori dettagli.
Detto questo, entriamo nel vivo!
Senza troppi giri di parole, vorrei anticipare subito le raccomandazioni sulla scelta del data warehouse emerse dai miei benchmark.
Se l'attenzione è rivolta esclusivamente all'efficienza dei costi, senza considerare le funzionalità a valore aggiunto, raccomando i seguenti servizi, dal più economico al più costoso:
- AWS Athena con AWS Glue Data Catalog (il più economico)
- AWS EMR con AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (il più costoso)
Se invece le funzionalità a valore aggiunto pesano nella scelta, raccomando i prodotti secondo il seguente ordine, che bilancia funzionalità e costo:
- GCP BigQuery (l'opzione DWH che offre il maggior valore)
- AWS Athena con AWS Glue Data Catalog
- AWS EMR con AWS Glue Data Catalog
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (l'opzione DWH che offre il minor valore)
Continui a leggere per approfondire le motivazioni alla base di queste raccomandazioni.
Parte 1: Acquisizione e trasformazione dei dati
Per simulare al meglio operazioni realistiche su scala TB, lavorerò con dati del genoma umano: un dominio intrinsecamente multi-TB, che spesso pone sfide peculiari nel raggiungere analisi cost-efficient.
Eviterò i tecnicismi della genomica per mantenere il contenuto accessibile. Per i lettori interessati ai workloads scientifici scalabili, il repository Git di questo blog propone esempi dettagliati e riproducibili per implementare workloads di genomica in modo cost-efficient.
Lavorerò nello specifico con i due dataset seguenti, che, per un pubblico non esperto di genomica, possono essere riassunti così:
- gnomAD genomes v4.0: gnomAD è ampiamente utilizzato nella ricerca genomica perché contiene dati sulla frequenza nella popolazione delle mutazioni rilevate nel sequenziamento dell'intero genoma di 807.162 individui. Tra i diversi utilizzi, le frequenze nella popolazione consentono di individuare mutazioni rare che, proprio in virtù della loro rarità, hanno maggiore probabilità di avere rilevanza clinica.
- Esempio: una mutazione con una frequenza del 25% è presente nel 25% della popolazione umana complessiva. Una mutazione così comune ha probabilità nettamente inferiori di avere un impatto clinico su un individuo rispetto, ad esempio, a una mutazione rara (resa tale dalla pressione evolutiva contraria) presente solo nello 0,01% della popolazione umana.
- In formato flat file, gnomAD v4.0, una volta bgzippato, occupa circa 830 GB.
- dbNSFP v4.6: un altro grande dataset utilizzato nella ricerca sul genoma umano. dbNSFP raccoglie - in un unico file - decine di previsioni di impatto funzionale e annotazioni per tutte le mutazioni del genoma umano, unificando i dati provenienti da diverse decine di database. L'ampiezza e la profondità dei dati di dbNSFP aiutano i clinici a valutare l'impatto clinico delle mutazioni.
- In formato flat file, dbNSFP non compresso occupa circa 250 GB.
Sia gnomAD sia dbNSFP sono risorse fondamentali nella medicina di precisione.
gnomAD è ospitato sia su bucket S3 sia su GCS, mentre dbNSFP è ospitato su S3, quindi recuperare questi dataset all'interno degli account cloud è semplice. Tuttavia, entrambi i dataset sono archiviati in formati flat file pensati per ricercatori che li esplorano con strumenti bioinformatici di stampo accademico, scarsamente scalabili. gnomAD, in particolare, è archiviato in un formato flat file bioinformatico specializzato (VCF bgzippato) che non è né ideale per analytics su larga scala né uno standard accettato dai DWH.
Il primo passo del nostro percorso di analisi dei costi DWH consiste quindi nel recuperare gnomAD e dbNSFP per poi trasformare i loro enormi flat file in un formato compatibile con i data warehouse: Parquet.
Tra gli strumenti più cost-efficient per manipolare grandi flat file figura Apache Spark. Anzi, Spark è uno degli strumenti più cost-efficient per fare analytics su qualsiasi dataset di grandi dimensioni, in particolare quando si lavora con file Parquet come input. Spark non solo è spesso un componente chiave nelle data pipeline su larga scala, ma può addirittura essere utilizzato come DWH per eseguire analytics su file Parquet archiviati in un bucket.
Detto questo, esaminiamo prima il costo di una fase di preparazione dati basata su Spark.
Il grafico seguente illustra i costi per convertire le due fonti dati da flat file a Parquet, unirle e scrivere il file risultante in Parquet, predisporre un metastore Hive per gestire i metadati Parquet e archiviare tutti i file Parquet in un bucket:
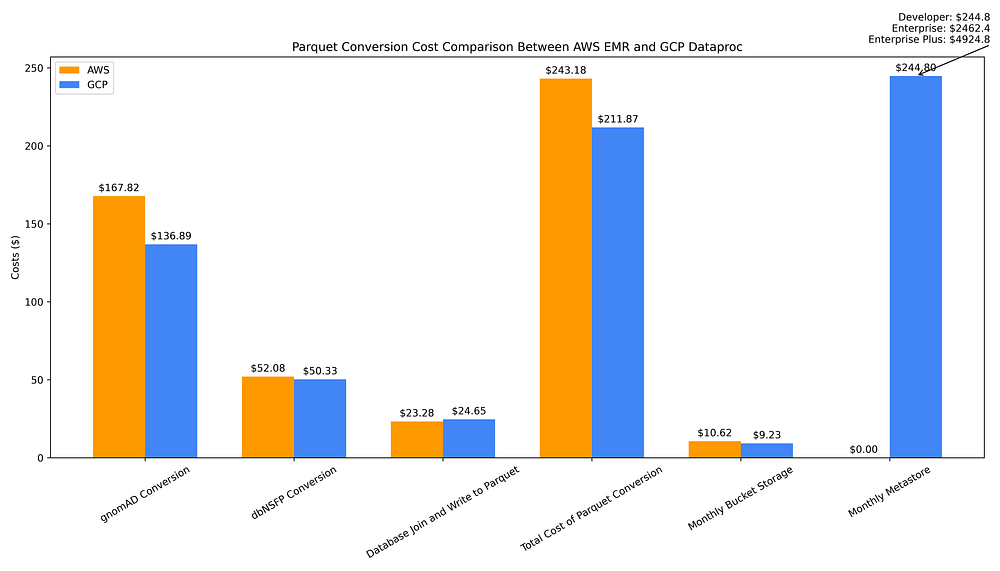
Confronto dei costi di data warehousing GCP vs AWS per la conversione flat file → Parquet, lo storage Parquet e la creazione del metastore Hive
Il costo totale una tantum della conversione dei flat file di entrambi i database in Parquet e della loro unione in un unico file Parquet è complessivamente leggermente inferiore con GCP Dataproc (211,87 $) rispetto ad AWS EMR (243,18 $). Ciò è dovuto al sovrapprezzo EMR applicato alle macchine Graviton di settima generazione, all'avanguardia, come le istanze Spot r7g.16xlarge.
Il costo di archiviazione dei file Parquet in output in bucket regionali è comparabile tra i due cloud: archiviare i dati Parquet su un bucket GCS (9,23 $) anziché su S3 (10,62 $) consente di risparmiare appena 1,39 $ al mese.
I costi operativi a lungo termine legati all'utilizzo di questi file Parquet sono però sensibilmente più elevati su GCP, poiché il suo servizio di metadata store completamente gestito ha un costo orario, mentre su AWS è di fatto gratuito grazie a Glue Data Catalog, almeno fino a quando non si raggiungono utilizzi su larga scala.
Con Glue Data Catalog occorre superare 1 milione di oggetti archiviati prima di iniziare a pagare la cifra simbolica di 1 $ ogni 100.000 oggetti archiviati al mese oltre il free tier di 1 milione di oggetti. Anche le richieste a Data Catalog sono gratuite fino a 1 milione; superata tale soglia, vengono addebitati appena 1 $ per milione di richieste oltre 1 milione al mese.
A fronte del metastore di AWS, dal costo nullo o trascurabile, si pone il costo mensile di 245 $ di Dataproc Metastore. Tale costo Dataproc presuppone l'utilizzo del tier Developer, che presenta "scalabilità limitata e nessuna fault tolerance". Per analytics su larga scala è necessario il tier Enterprise, scalabile e fault-tolerant, con un costo mensile di 2.462 $. Esiste inoltre un tier Enterprise Plus, scarsamente documentato, che raddoppia questo costo mensile portandolo a 4.924 $ (da una conversazione con un PM di GCP è emerso che il "Plus" indica una configurazione High Availability).
In sintesi, sebbene i costi una tantum di conversione dei dati e creazione dei metadati siano leggermente più alti su AWS e quelli di archiviazione a lungo termine siano grosso modo equivalenti, sul fronte dell'utilizzo dei file Parquet come data warehouse AWS ha la meglio grazie al costo trascurabile del metastore Parquet. Un metastore Hive è essenziale sia per migliorare l'efficienza dei costi delle query sui file Parquet, sia per renderli più semplici e comodi da consultare — ad esempio, consentendo di interrogarli tramite nomi di "tabella" anziché interrogare direttamente il filepath — quindi lo considero un componente indispensabile per un data warehouse basato su Parquet.
Parte 2: Il costo di 17 query analitiche complesse
Abbiamo confrontato il costo di trasformare terabyte di flat file in formato Parquet e di ospitare un metadata store per quei file allo scopo di accelerare i tempi di esecuzione delle query. Esaminiamo ora il costo di eseguire query su questi dataset utilizzando diversi servizi cloud di data warehouse.
Un riepilogo delle 17 query che verranno eseguite su ciascun DWH è disponibile in Appendice, per dare un'idea della complessità delle query in esame. Per chi ha competenze in genomica, ulteriori spiegazioni dettagliate sono fornite tramite i commenti nei file di codice.
Opzione 1: cluster Spark effimeri come data warehouse
Partiamo dall'ipotesi che il nostro data warehouse sia composto da cluster Spark effimeri che interrogano file Parquet archiviati in un bucket:
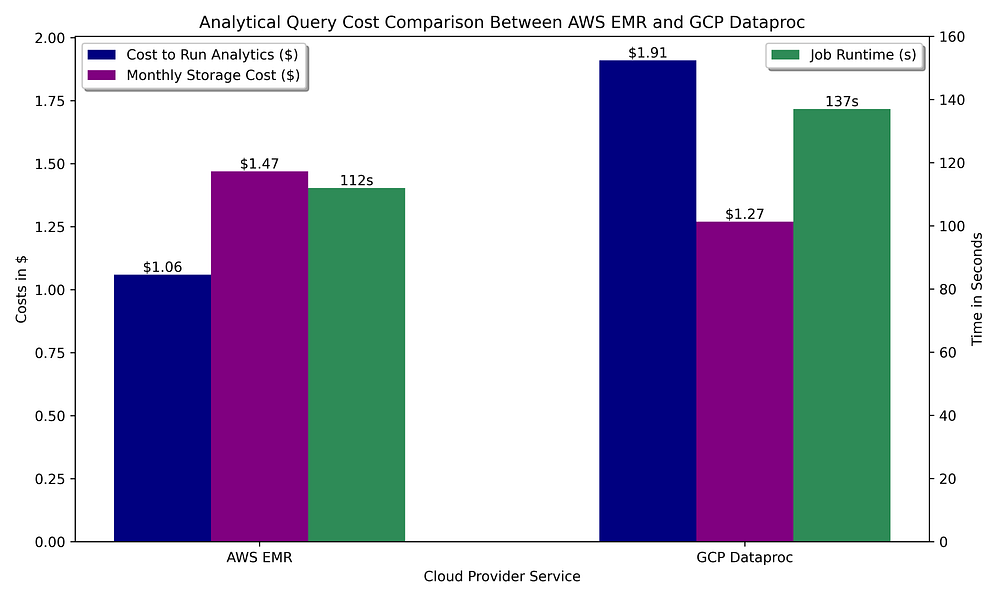
Confronto dei costi di data warehousing GCP vs AWS per l'esecuzione di query OLAP con Apache Spark e archiviazione Parquet del dataset interrogato
Come nella fase di preparazione dei dati basata su Spark, eseguire analytics sulle offerte Spark gestite ha un costo simile in entrambi i cloud. In questo caso AWS ha un vantaggio su GCP grazie alla configurazione di auto-terminazione in idle di EMR, che consente di scendere fino a 60 secondi di inattività prima di terminare il cluster, mentre la corrispondente configurazione di Dataproc può scendere solo fino a 5 minuti. Considerato che queste query non richiedono molto tempo per essere completate, il tempo minimo di idle che porta alla terminazione del cluster gioca a sfavore di GCP.
Le funzionalità di Spark sono identiche su entrambi i cloud, quindi non c'è un reale vantaggio funzionale per uno o per l'altro. Tra l'esecuzione più rapida ed economica di EMR su cluster di breve durata e il metastore gratuito, contrapposti all'elevato costo di hosting di un metastore Hive su GCP, gli analytics basati su Spark pendono nettamente a favore di AWS.
Opzione 2: offerte DWH serverless
E se volessimo sostituire Spark come DWH con un servizio di data warehouse completamente gestito e serverless di un cloud provider — in cui le query si eseguono con il solo SQL — per evitare di scrivere codice Spark?
Di seguito riportiamo il confronto dei costi del data warehousing AWS con Athena e Redshift Serverless rispetto a GCP BigQuery on-demand. Per questi DWH vengono utilizzate le stesse 17 query OLAP impiegate nello Step 2 Opzione 1. È proprio in questo confronto che la convenienza economica delle diverse opzioni DWH emerge con chiarezza:
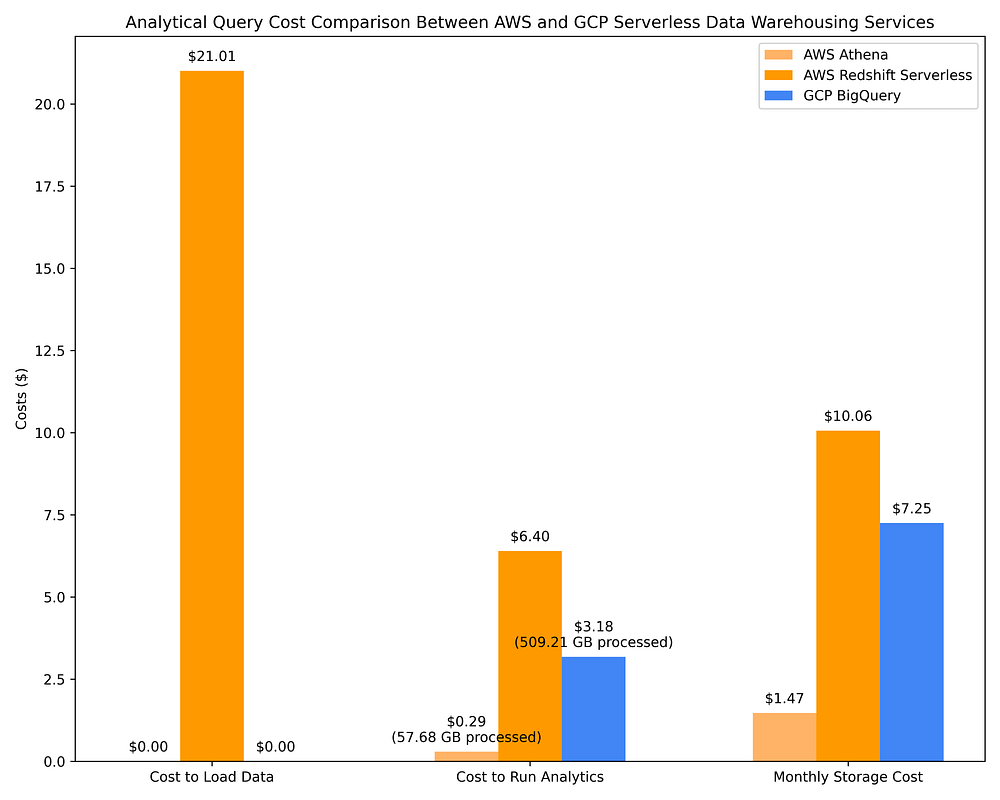
Confronto dei costi di data warehousing GCP vs AWS per l'esecuzione di query OLAP con servizi DWH serverless e archiviazione del dataset interrogato
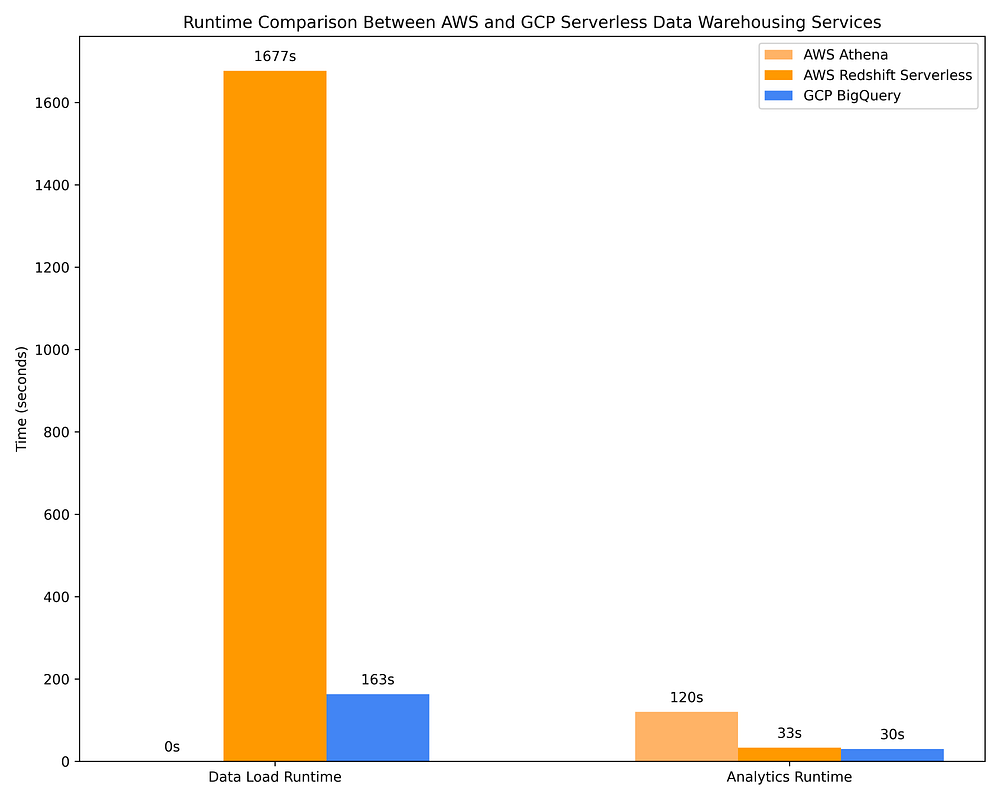
Confronto dei tempi di esecuzione del data warehousing GCP vs AWS per il caricamento dei dati e l'esecuzione di query OLAP su servizi DWH serverless
Redshift e BigQuery calcolano i metadati di colonna per l'ottimizzazione delle query nel momento in cui i dati vengono inseriti in una tabella. Tali metadati ottimizzano le query consentendo, ad esempio, filtri pushdown predicati che riducono la quantità di dati da scansionare per eseguire una query. Questo, di conseguenza, riduce il costo delle query addebitate in base ai TB di dati scansionati, sia direttamente (BigQuery) sia indirettamente (Redshift, tramite il numero di RPU necessari per eseguirle).
I file Parquet contengono già metadati e, calcolando e archiviando metadati aggiuntivi su tali file in un metastore Hive tramite Spark, le query OLAP che li interrogano sfruttano metadati di colonna molto simili per l'ottimizzazione.
Sia che si utilizzi un DWH serverless sia che si usino cluster Spark per interrogare file Parquet, si sfruttano metadati di colonna pre-calcolati che permettono di completare query molto complesse su TB di dati tipicamente in pochi secondi, scansionando solo pochi GB o MB grazie ai metadati disponibili. Ecco perché, ad esempio, eseguire 17 query complesse su diversi TB di dati può costare poco più di un quarto di dollaro dopo aver scansionato appena 57,68 GB, come si vede nei costi di AWS Athena sopra riportati.
I confronti dei costi mostrati sopra, così come quelli dell'Opzione 2 della Parte 1, rivelano che interrogare file Parquet abbinati a un metastore Hive tramite AWS Athena, AWS EMR e GCP Dataproc è molto più cost-effective rispetto all'utilizzo di servizi cloud-native di data warehouse. Un risultato piuttosto interessante, considerando che tutti questi sistemi si basano sullo stesso principio: l'ottimizzazione del query plan tramite i metadati di colonna di un file system colonnare.
Ciononostante, le offerte DWH serverless non sono altrettanto efficaci nell'ottimizzare le query in base ai metadati di colonna. BigQuery, ad esempio, scansiona circa 10 volte più dati rispetto ad AWS Athena quando interroga file Parquet tramite AWS Glue Data Catalog, addebitando di conseguenza circa 10 volte di più. I costi delle query di BigQuery sono inoltre più del doppio rispetto all'esecuzione delle stesse query su cluster Spark effimeri con istanze Spot/preemptible su AWS EMR / GCP Dataproc. BigQuery può completare le proprie query circa 4 volte più velocemente di AWS Athena, AWS EMR e GCP Dataproc, ma a un costo circa 10 volte superiore. A seconda del caso d'uso, questo costo aggiuntivo può valerne o non valerne la pena.
AWS Redshift è un servizio nato come a capacità provisioned, a cui è stata aggiunta una versione quasi-serverless solo molto più tardi (l'offerta "serverless" richiede comunque una pianificazione della capacità sotto forma di configurazione di scaling delle Redshift Processing Unit, o RPU). Date le sue origini, Redshift Serverless rimane la più costosa tra le opzioni DWH on-demand, in larga parte perché il suo pricing "serverless" continua a basarsi sulle risorse provisioned anziché sui TB di dati scansionati. Considerando inoltre che Redshift si comporta più come Postgres che come un data warehouse cloud-native, che manca di integrazioni native con AWS IAM (il che ostacola la condivisione dei dati e i permessi a livello granulare di tabella/colonna/riga) e che impiega circa 9 volte più tempo di BigQuery per caricare i dati nelle tabelle, con un costo non trascurabile… personalmente non posso raccomandare Redshift. È vantaggioso solo se i suoi data engineer hanno una grande familiarità con Postgres e solo se, per qualsiasi motivo, non possono utilizzare alcun'altra opzione di data warehouse.
Quale data warehouse scegliere?
Raccomandazione: se il costo è l'unico criterio
Se il costo è l'unico fattore da considerare e se il suo caso d'uso è compatibile con i file Parquet come backend (ovvero, se i dataset interrogati non dipendono da streaming di dati in tempo reale), raccomando di archiviare i file Parquet in un bucket e interrogarli con un query engine serverless come AWS Athena o un servizio di cluster effimeri come AWS EMR o GCP Dataproc. Le offerte di data warehouse serverless come BigQuery e Redshift offrono comodità, un miglior supporto per i casi d'uso di streaming in tempo reale e molte altre funzionalità a valore aggiunto che illustrerò a breve, ma tutto questo ha un costo significativo.
Vale la pena ricordare che, a una scala operativa sufficientemente grande, BigQuery e Redshift incontrano limitazioni tecniche che impongono il passaggio da un modello di pricing on-demand a uno basato sulle risorse slot/CPU. Questo passaggio costerà con ogni probabilità più dell'equivalente on-demand.
BigQuery on-demand fattura per TB scansionato, ma è limitato a soli 2.000 slot (~2.000 core e ~2 TB di memoria) per l'utilizzo complessivo su tutte le query. Inoltre, non è possibile utilizzare alcune funzionalità chiave di BigQuery, come le query BigQuery ML, con BQ on-demand o nemmeno con BQ Editions Standard. Se prevede di aver bisogno di una qualsiasi delle seguenti funzionalità, dovrà passare a uno dei tre tier di pricing basato sulle risorse di BigQuery Editions:
- Più di 2.000 core / 2 TB di memoria (Standard)
- Esecuzione di training e predizioni ML all'interno di BQ tramite SQL (Enterprise)
- Controlli di accesso a livello di riga e colonna (Enterprise)
- Viste materializzate (Enterprise)
L'efficienza dei costi della scalabilità di Redshift serverless è altrettanto limitata e richiede anch'essa un cluster a tariffa fissa per essere superata.
I modelli di pricing basati sulle risorse possono essere complessi (in particolare per BigQuery Editions [1] [2] [3]) e rendono difficile, se non impossibile, arrivare a una stima dei costi davvero accurata senza eseguire tutti i workloads su un deployment basato sulle risorse per qualche giorno e, da lì, prevedere i costi mensili/annuali. Esistono peculiarità — come l'autoscaler di slot di BigQuery Editions, imperfetto (scala solo a incrementi di 100 slot e fattura per un minimo di 1 minuto per una determinata quantità di slot, indipendentemente dal fatto che le query stiano effettivamente utilizzando tali slot autoscalati) — oltre alla variabile imprevedibile di quanti slot saranno complessivamente necessari a tutte le sue query, fattori che non possono essere stimati senza eseguire tutti i workloads in un test che simuli pienamente la produzione sul modello a tariffa fissa.
Indipendentemente dai dettagli di pricing, ho riscontrato presso molti clienti DoiT che i modelli di pricing a tariffa fissa risultano generalmente più costosi del modello on-demand. A meno di prevedere l'esecuzione di query OLAP 24/7/365, e solo se tali query richiedono costantemente la stessa quantità di risorse di calcolo nel tempo, è improbabile che la tariffa fissa porti a risparmi significativi rispetto al pricing on-demand.
Alla luce di quanto sopra, se l'attenzione è esclusivamente sull'efficienza dei costi, senza considerare le funzionalità a valore aggiunto, raccomando i seguenti servizi, dal più economico al più costoso:
- AWS Athena con AWS Glue Data Catalog (il più economico)
- AWS EMR con AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (il più costoso)
La discussione, però, non si chiude qui. È importante valutare con attenzione il costo dei sistemi DWH serverless rispetto alle funzionalità che abilitano.
Raccomandazione: se il costo viene bilanciato con le funzionalità
Interrogare i file Parquet con codice Spark o con SQL su Athena può essere molto cost-effective, ma questo approccio ha dei limiti. Si rinuncia ai vantaggi della ricchezza funzionale che servizi come BigQuery offrono.
Ecco alcuni dei principali vantaggi che, a mio parere, rendono BigQuery degno del costo aggiuntivo in molti casi:
- Accessibilità. La UI di BQ è gradevole, semplice da usare e da imparare. I data scientist — che potrebbero essere meno propensi a imparare Apache Spark e altri sistemi complessi — apprezzeranno avere a disposizione una UI gradevole e basata su SQL per archiviare e interrogare i dati.
- Point-in-time recovery. Il PIT è integrato in BQ, con time travel fino a 7 giorni impostato come default. Per contro, sebbene si possa attivare il versioning dei bucket per consentire il ripristino di file Parquet eliminati per errore, non è altrettanto comodo quanto ripristinare una tabella con un singolo comando SQL. Progetti di data lakehouse come Apache Iceberg e Delta Lake possono abilitare il ripristino PIT basato su SQL su file Parquet, ma nei brevi test che ho eseguito le lakehouse aumentano il runtime delle query di almeno 2-3 volte. Affidandosi a una data lakehouse si rinuncia ai vantaggi prestazionali e di costo legati all'utilizzo del solo Apache Spark per interrogare i dati Parquet.
- Integrazioni IAM native. La dipendenza di BQ da GCP IAM rende possibile, e sorprendentemente semplice, condividere i dati e controllarne l'accesso a un livello molto granulare. Condividere dataset e tabelle con altri utenti GCP è immediato. Si può persino limitare la possibilità degli utenti di visualizzare specifiche colonne e righe. La condivisione e il controllo degli accessi granulare non sono qualcosa che si ottiene con un file system basato su Parquet.
- Integrazioni native con servizi di streaming in tempo reale. Se l'ingestione di dati in tempo reale è cruciale, BigQuery si integra nativamente con PubSub e Dataflow. Questi servizi consentono alle query di colpire dati in streaming in tempo reale con al massimo qualche secondo di latenza. Da questo punto di vista BigQuery si distingue da tutti gli altri sistemi DWH; persino l'ingestione di dati in tempo reale di Snowflake può richiedere diversi minuti prima che i dati diventino disponibili. Rendere i dati interrogabili in near real time, per quanto ne so, non è possibile con un file system basato su Parquet.
- Integrazioni native con… praticamente tutto. C'è un aspetto UI/UX di BigQuery che non andrebbe sottovalutato. Con BQ on-demand è possibile vedere il costo stimato di una query prima ancora di eseguirla. Supponiamo che il costo della query le vada bene e la lanci. Con un solo clic può esportarne i risultati in Looker Studio, dove viene generata automaticamente una visualizzazione basata su ciò che l'algoritmo ML di Looker Studio ritiene che lei voglia visualizzare a partire dai risultati. È altrettanto semplice spostare i risultati delle query su Vertex AI di GCP per il machine learning, oppure costruire e distribuire un modello ML direttamente all'interno di BigQuery tramite BQ ML SQL, o ancora esportare i risultati su Google Drive, e così via. BigQuery non è solo un data warehouse: è parte di un ecosistema di servizi costruito apparentemente del tutto attorno a BigQuery.
A differenza di BigQuery, Redshift offre purtroppo più grattacapi che benefici. Lo collocherei all'ultimo posto in termini di efficienza dei costi e ricchezza funzionale. Si comporta più come Postgres che come un data warehouse e, di conseguenza, per usarlo bene è necessario diventare profondamente esperti nell'ottimizzazione delle prestazioni delle tabelle, oltre che nella creazione di utenti/gruppi e nella gestione dei permessi all'interno di Redshift, dato che i suoi controlli IAM rimangono separati da AWS IAM.
Pur essendo tecnicamente possibile autenticarsi su Redshift con AWS IAM, ciò avviene tramite la Trusted Identity Propagation (SSO) — il che significa che bisogna comunque predisporre un'interfaccia tra due sistemi IAM separati — e le policy AWS IAM personalizzate da costruire e abbinare alla configurazione SSO per concedere a un utente AWS l'accesso all'istanza Redshift sono in grado di concedere solo permessi generici. Se si vuole limitare lo scope di ciò che un'entità AWS IAM può fare oltre le azioni di alto livello (ad es. oltre la creazione, modifica o eliminazione di un cluster, o in modo più granulare rispetto, ad esempio, alla concessione dell'accesso completo o di sola lettura completa a un'istanza), bisogna creare un ruolo utilizzando il sistema IAM dell'istanza Redshift a cui assegnare uno scope ristretto a livello di tabella, quindi aggiornare la policy dell'utente AWS IAM in modo che l'autenticazione tramite SSO assuma il ruolo IAM di tale nuovo cluster… alla fine, è una configurazione enormemente più complicata rispetto alle alternative disponibili.
In BigQuery, invece, è possibile limitare l'accesso di un utente GCP a un dataset, a una tabella o persino a specifiche righe o colonne all'interno di una tabella semplicemente cliccando sull'entità desiderata nella UI di BigQuery e concedendo direttamente all'utente GCP IAM tali permessi a scope ristretto. Redshift richiede di consultare una mezza dozzina di pagine di documentazione per assicurarsi di configurare correttamente i permessi granulari a livello di tabella — permessi che non possono essere auditati esclusivamente visualizzando le policy concesse in AWS IAM, a causa della dipendenza da policy granulari che esistono solo all'interno dei ruoli IAM di Redshift. In BigQuery, invece, è possibile configurare permessi granulari armeggiando brevemente con la UI e, dato che BQ si affida esclusivamente a GCP IAM per l'autenticazione, determinare chi ha accesso a quali tabelle, o persino chi è autorizzato a visualizzare colonne o righe specifiche e sensibili all'interno delle tabelle, è relativamente semplice da auditare.
Le integrazioni di Redshift con altri servizi sono altrettanto macchinose. Connetterlo a SageMaker per eseguire training ML, o a Quicksight per visualizzare i risultati delle query, è certo possibile, ma richiede passaggi di integrazione decisamente più onerosi rispetto alla configurazione zero-setup, pronta all'uso, che BigQuery offre per i servizi analoghi Vertex AI (ML) e Looker (BI).
Considerando l'altissimo costo associato a Redshift, sia nella versione serverless sia in quella a capacità provisioned… personalmente non vedo alcun beneficio nell'utilizzarlo. Esistono diverse opzioni migliori, anche all'interno di AWS stessa (AWS Athena e AWS EMR abbinati ad AWS Glue Data Catalog).
Se desidera bilanciare le funzionalità a valore aggiunto con il costo totale, raccomando i data warehouse secondo il seguente ordine:
- GCP BigQuery (l'opzione DWH che offre il maggior valore)
- AWS Athena con AWS Glue Data Catalog
- AWS EMR con AWS Glue Data Catalog
- GCP Dataproc con GCP Dataproc Metastore
- AWS Redshift (l'opzione DWH che offre il minor valore)
Appendice
Le funzionalità di Reporting di DoiT Navigator sono state utilizzate per semplificare e velocizzare il calcolo dei costi totali di ciascuna parte. Questa piattaforma unifica la spesa di tutti i cloud provider e consente di creare con facilità report con criteri di raggruppamento e filtraggio complessi. Ad esempio, è possibile ottenere in pochi secondi un breakdown della spesa cloud per giorno, cloud provider, servizio e SKU; questo tipo di report è stato spesso impiegato per raccogliere senza sforzo i dati di spesa riportati nell'articolo.
I dettagli sul calcolo dei costi e le spiegazioni sulla complessità delle query sono disponibili nel codice base abbinato al blog: Appendix.md
Ha ancora dubbi su come applicare le raccomandazioni qui presentate per ottenere il successo del data warehousing GCP o AWS all'interno della sua organizzazione?
Ci contatti su DoiT International. Composti esclusivamente da senior engineering talent, siamo specializzati nel fornire consulenza cloud avanzata su progettazione architetturale e debugging.