∘ Performances réseau optimisées
∘ Comprendre ENA et son importance
∘ Pourquoi privilégier les versions les plus récentes
∘ Le parcours simplifié d'un paquet réseau
∘ Receive Packet Steering (RPS)
∘ Modération des interruptions
Performances réseau optimisées
Dans le cloud computing, les performances réseau conditionnent la scalabilité et l'efficacité des applications qui exigent un haut débit et une faible latence. Les générations récentes d'instances EC2 intègrent l'Enhanced Networking via l'Elastic Network Adapter (ENA) ainsi que le pilote ENA propriétaire d'Amazon, ce qui leur procure des gains de performance notables face aux machines virtuelles classiques. Cet article passe en revue des techniques avancées et les bonnes pratiques pour optimiser les performances réseau sur les instances EC2 Linux et, par extension, celles de vos applications.
Comprendre ENA et son importance
Les anciennes générations d'instances EC2 sont virtualisées sous Xen et ne prennent pas en charge ENA. Les générations modernes, à l'inverse, reposent sur KVM et s'appuient sur les pilotes ENA propriétaires d'AWS pour le réseau.
Avec Xen, on retrouve la notion de dom0, le domaine de gestion par lequel transitent toutes les requêtes d'E/S et qui héberge les services de l'hôte sous-jacent.
Les E/S réseau sortent des machines virtuelles (domU) via les pilotes netfront/netback, tandis que les E/S disque empruntent blockfront/blockback.
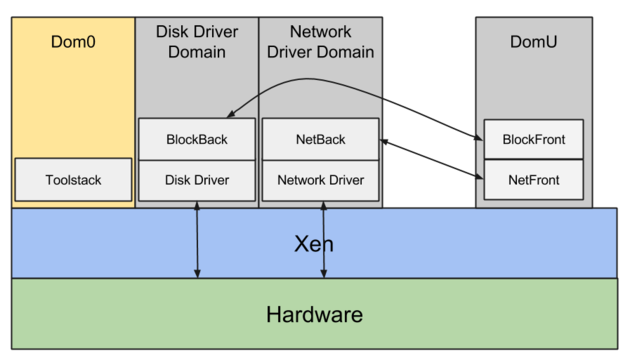
Pour chaque requête d'E/S, la machine virtuelle (domU) doit la traiter et la transmettre à dom0 via ces pilotes, qui s'appuie ensuite sur les pilotes réels pour la transmettre au matériel physique.
En résumé, chaque requête d'E/S de la machine virtuelle (domU) passe systématiquement par un intermédiaire (dom0) entre la VM et le matériel réel. Résultat : des performances dégradées et, surtout, un jitter important, qui rend les performances d'E/S très imprévisibles.
De plus, dom0 intervient dans les requêtes d'E/S de TOUTES les machines virtuelles de l'hôte sous-jacent — un volume potentiellement considérable, qui peut atteindre plusieurs centaines de VM sur un même hôte. De quoi accentuer encore l'imprévisibilité des performances d'E/S et générer un sérieux problème de voisins bruyants.
Le pilote réseau propriétaire d'Amazon (ENA) résout ce problème en permettant aux machines virtuelles de communiquer directement avec le matériel, sans intermédiaire.
Sur les générations modernes d'instances EC2 bâties sur Nitro, dom0 a disparu : AWS a abandonné Xen au profit de KVM comme hyperviseur.
Pourquoi privilégier les versions les plus récentes
Ces améliorations s'amplifient au fil des générations d'instances EC2, ce qui rend indispensable le choix de la dernière génération d'instances EC2 dès lors que la performance maximale est recherchée.
Il est tout aussi essentiel de vérifier que votre système Linux utilise la toute dernière version du pilote ENA, qui regroupe l'ensemble des optimisations de performance et des correctifs récents.
Le parcours simplifié d'un paquet réseau
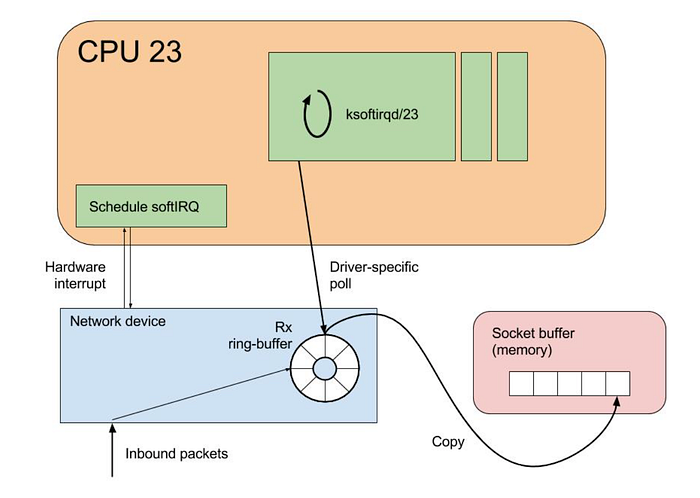
De manière très simplifiée, le parcours d'un paquet réseau venu d'Internet vers un système Linux débute à son arrivée sur la carte réseau, qui génère alors une interruption pour signaler au CPU que des données sont disponibles.
Le CPU suspend alors sa tâche en cours pour traiter l'interruption, en exécutant une routine de gestion d'interruption qui prend en charge le paquet entrant.
La pile réseau du noyau prend ensuite le relais et traite le paquet. Cela englobe différentes couches : gestion IP, gestion TCP/UDP, etc. Le noyau vérifie l'intégrité du paquet, détermine sa destination sur le système et assure le routage.
Si le paquet est destiné à une application qui s'exécute sur le système, il est déplacé vers un buffer de socket. Ces buffers sont les points d'extrémité d'envoi et de réception de données sur une machine et résident en mémoire RAM.
Pour cet article, nous nous concentrerons sur deux étapes du parcours d'un paquet réseau : la gestion des interruptions, qui signale l'arrivée de nouvelles données depuis le matériel, et les files ENA, qui prennent en charge le traitement des paquets réseau au sein de la pile Linux.
Pour la gestion des interruptions, Linux fait appel à des mécanismes tels que SoftIRQs et NAPI afin de traiter efficacement les paquets réseau.
Plutôt que d'interrompre immédiatement le CPU à chaque arrivée de paquet réseau, les interruptions logicielles (SoftIRQs) autorisent une exécution différée : le noyau peut reporter le traitement au profit d'une tâche plus urgente.
NAPI est une interface conçue pour améliorer les performances réseau en charge élevée. Elle bascule le traitement des paquets d'un modèle piloté par interruptions à un modèle de polling lorsque le trafic réseau atteint un certain seuil, ce qui réduit la surcharge liée à des interruptions trop fréquentes.
Files d'attente ENA
Pour le dire simplement, une file d'attente ENA fonctionne comme un ensemble de tapis roulants qui aide à gérer le trafic Internet en orchestrant les paquets réseau entrants et sortants du système. Ces tapis roulants se déclinent en deux types :
Les files de transmission (Tx), où le système place les données qu'il souhaite envoyer vers Internet, et les files de réception (Rx), où les données entrantes sont reçues puis placées dans un buffer pour traitement.
Chaque file dispose d'une section de soumission et d'une section de complétion. Les données sont d'abord placées dans la section de soumission, soit pour être envoyées (Tx), soit pour préparer la réception de données entrantes (Rx). La section de complétion confirme ensuite si les données ont bien été envoyées ou reçues.
Avec cette représentation des files ENA, on comprend aisément qu'elles peuvent devenir un goulot d'étranglement et nuire aux performances réseau. Les instances EC2 peuvent disposer de plusieurs files ENA (jusqu'à 32 par ENI) selon la taille du type d'instance. Cette prise en charge multi-files permet de répartir le trafic réseau sur plusieurs cœurs CPU, ce qui réduit les goulots d'étranglement et améliore l'efficacité globale du traitement des données, avec une latence plus faible et un débit plus élevé.
Avec ethtool, nous pouvons surveiller les métriques exposées par le pilote ENA d'Amazon et mieux comprendre comment le système absorbe la charge de trafic dans ces files.
Une métrique clé est le nombre de stops dans ces files. Ces stops indiquent que des paquets ont été soumis aux anneaux Tx plus rapidement qu'ils ne pouvaient être traités, ce qui se traduit par des pertes.
[root@aws rossetv]# ethtool -S eth0|grep stop
queue_0_tx_queue_stop: 0
queue_1_tx_queue_stop: 0
Un nombre significatif de stops dans les files ENA traduit généralement un throttling : soit du throttling AWS, lié au dépassement des limites réseau de l'instance, soit une saturation des ressources, faute de puissance de traitement ou de buffers suffisants pour absorber les paquets entrants.
Pour affiner le diagnostic, on peut vérifier le throttling en consultant les métriques exceeded, avec la commande ci-dessous.
[root@aws rossetv]# ethtool -S eth0|grep stop
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Si l'un de ces compteurs affiche une valeur non nulle, reportez-vous à mon précédent article sur le Troubleshooting du throttling réseau AWS, dont voici le lien.
Une fois confirmé qu'aucun throttling ne provient d'AWS, votre système est très probablement confronté à une saturation des ressources réseau.
Saturation CPU
Pour aller plus loin sur les files ENA : ce sont elles qui traitent les paquets réseau. En amont, le noyau gère les IRQ provenant de la carte réseau, qui signalent au CPU l'arrivée de nouvelles données. Le CPU interrompt alors sa tâche en cours pour prendre en charge l'interruption, et plus loin dans la chaîne, ces données seront traitées par ENA en tant que paquet réseau.
Si les vCPU d'une instance sont surchargés ou utilisés de manière inégale, le traitement du trafic réseau peut prendre du retard, provoquant des pertes de paquets côté Rx et des timeouts de complétion côté Tx. Conséquence : des performances dégradées et une latence élevée, très variable.
Pour atteindre des performances réseau élevées et stables, il est essentiel de s'assurer que les vCPU chargés du trafic réseau (les files ENA) sont disponibles et bénéficient d'un temps de traitement suffisant.
L'essentiel du traitement réseau s'effectue dans le routage NAPI, exécuté en contexte softirq. Les cœurs CPU impliqués dans le traitement NAPI peuvent être identifiés avec la commande suivante :
[root@aws rossetv]# egrep 'CPU|eth0' /proc/interrupts
CPU0 CPU1
28: 4531 1535 PCI-MSI 81921-edge eth0-Tx-Rx-0
29: 460 4311 PCI-MSI 81922-edge eth0-Tx-Rx-1
[root@aws rossetv]#
Dans certains cas, vous constaterez aussi que les threads ksoftirqd consomment près de 100 % d'un cœur CPU. Ce sont ces threads qui prennent en charge les interruptions avant que le trafic n'atteigne les files ENA.
Plusieurs causes peuvent expliquer une saturation CPU dans le traitement réseau : le système est peut-être tout simplement surchargé par d'autres tâches gourmandes en CPU, ce que l'on détecte avec des utilitaires comme htop, ou avec perf pour repérer où les cœurs passent le plus de temps.
Parfois, l'utilisation CPU élevée est sporadique, sous forme de brefs pics d'utilisation CPU. Dans ce cas, vous pouvez augmenter la taille de l'anneau Rx pour compenser une indisponibilité temporaire du CPU.
Par défaut, l'anneau Rx ENA contient 1K entrées, mais sa taille peut être portée dynamiquement jusqu'à 16K entrées avec ethtool. Pour passer la taille de l'anneau Rx sur eth0 à 4096, par exemple, utilisez la commande ci-dessous.
sudo ethtool -G eth0 rx 4096
Si les cœurs CPU dédiés au traitement réseau sont constamment surchargés et frôlent les 100 % d'utilisation alors que l'utilisation CPU globale reste modérée, cela peut signaler une répartition de charge inégale entre les vCPU disponibles.
Pour y remédier, on peut réaffecter les autres tâches qui s'exécutent sur les vCPU surchargés vers des vCPU moins sollicités et qui ne participent pas au traitement réseau, à l'aide des utilitaires Linux taskset ou numactl.
Il est également possible de détourner les interruptions réseau des vCPU déjà surchargés en définissant IRQBALANCE_BANNED_CPUS dans /etc/sysconfig/irqbalance, avec le masque CPU correspondant aux CPU à exclure, puis en redémarrant le service irqbalance.
Vous garantissez ainsi que les cœurs CPU qui pilotent les files ENA ne sont pas en parallèle mobilisés par le traitement des IRQ réseau.
Si votre instance EC2 dispose de plus de cœurs CPU que de files ENA, vous pouvez aussi activer le receive packet steering (RPS) pour décharger une partie du traitement du trafic Rx sur d'autres vCPU. Il est toutefois conseillé de conserver les vCPU RPS sur le même nœud NUMA que les vCPU traitant les IRQ ENA. Évitez également de placer les vCPU RPS sur les cœurs frères des vCPU IRQ lorsque l'hyperthreading est activé.
Ces approches offrent un contrôle très fin sur les cœurs CPU qui prennent en charge chaque aspect du traitement réseau sous Linux, afin d'atteindre des performances absolument maximales.
Receive Packet Steering (RPS)
Le receive packet steering (RPS) est une méthode qui consiste à orienter les paquets réseau vers des CPU spécifiques pour traitement. On peut y recourir pour empêcher la file matérielle d'une seule carte réseau de devenir un goulot d'étranglement.
Le RPS se configure pour chaque périphérique réseau et chaque file de réception, plus précisément dans le fichier /sys/class/net/eth0/queues/rx-0/rps_cpus, où eth0 désigne le périphérique réseau et rx-0 la file de réception concernée.
Par défaut, le fichier rps_cpus est à 0, ce qui désactive le RPS : le même cœur CPU qui gère l'interruption réseau traite également le paquet. Pour activer le RPS, configurez le fichier rps_cpus approprié avec les CPU qui doivent traiter les paquets du périphérique réseau et de la file de réception spécifiés.
La configuration des fichiers rps_cpus utilise des bitmaps de CPU séparés par des virgules. Pour qu'un CPU prenne en charge les interruptions d'une file de réception sur une interface, il faut placer les bits correspondants à 1 dans le bitmap.
La commande lscpu permet d'identifier quels CPU sont rattachés à quels nœuds NUMA, comme illustré ci-dessous :
[root@aws rossetv]# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Avec l'exemple ci-dessus, activons le RPS pour les cœurs 48 à 63. Ce système compte 64 cœurs et chaque caractère hexadécimal du masque représente 4 bits : il nous faut donc 16 caractères hexadécimaux pour représenter 64 bits. Pour activer les 16 derniers cœurs (48–63) au RPS, on positionne les 16 derniers bits à 1 et tous les autres bits à 0. La représentation hexadécimale de 1111 1111 1111 1111 (16 bits pour les cœurs 48-63) est FFFF.
Comme nous travaillons sur une représentation 64 bits et que nous devons activer les 16 bits de poids fort, le masque sera 0000,00000000,00000000,0000FFFF.
Pour appliquer ce paramètre à plusieurs files de réception, les commandes suivantes parcourent les files Rx rx-0 à rx-15 de l'interface eth0 et les configurent pour n'utiliser que les cœurs 48 à 63 :
sudo bash -c 'for i in $(seq 0 15); do echo "0000,00000000,00000000,0000FFFF" > /sys/class/net/eth0/queues/rx-$i/rps_cpus; done'
Cette modification ne survivra toutefois pas à un redémarrage. Pour la rendre persistante, après les tests, écrivez un script simple et programmez-le au démarrage avec les commandes ci-dessous.
sudo su
echo 'for i in `seq 0 15`; do echo $(printf "0000,00000000,00000000,0000FFFF") | sudo tee /sys/class/net/eth0/queues/rx-$i/rps_cpus; done' > /sbin/rps_core
chmod +x /sbin/rps_core
echo "/sbin/rps_core" >> /etc/rc.local
chmod +x /etc/rc.local
À noter : si le service irqbalance est actif, le traitement des IRQ peut migrer vers d'autres vCPU, ce qui peut réduire l'efficacité du RPS. Désactiver irqbalance n'est pas recommandé, mais vous pouvez préciser les cœurs CPU à exclure du traitement des IRQ via la variable IRQBALANCE_BANNED_CPUS dans /etc/sysconfig/irqbalance.
Le masque CPU se calcule de la même manière que ci-dessus ; dans cet exemple précis, on définirait IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF et on redémarrerait irqlbalance avec les commandes ci-dessous.
sudo su
echo "IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF" >> /etc/sysconfig/irqbalance
sudo systemctl restart irqbalance
Modération des interruptions
Un débit réseau élevé et une faible latence sont des objectifs clés des environnements cloud à hautes performances. Pourtant, du point de vue d'un contrôleur Ethernet, latence et débit relèvent d'un compromis.
Pour réduire la latence, le contrôleur réduit habituellement l'intervalle entre les interruptions afin d'accélérer le traitement des petits paquets, au prix d'une utilisation CPU plus élevée et d'un débit moindre.
À l'inverse, pour améliorer le débit et limiter la surcharge induite par des interruptions trop fréquentes, on privilégie des intervalles d'interruption plus longs. Choisir un intervalle adapté est donc déterminant pour atteindre le meilleur équilibre de performance.
La modération des interruptions est une fonctionnalité du pilote, prise en charge par les types d'instances Nitro utilisant ENA, qui permet de piloter la fréquence des interruptions envoyées au CPU lors de la transmission et de la réception de paquets.
Sans modération, le système déclenche une interruption pour chaque paquet émis et reçu. Cela permet certes de minimiser la latence par paquet, mais des ressources CPU supplémentaires sont consommées par la surcharge de traitement des interruptions, ce qui peut réduire considérablement le débit.
Lorsque la modération des interruptions est activée, plusieurs paquets sont traités à chaque interruption, ce qui améliore l'efficacité globale du traitement et réduit l'utilisation CPU, en contrepartie d'une latence plus élevée puisque le CPU attend plusieurs paquets avant de les traiter.
Sur les instances EC2 utilisant le pilote ENA, le délai d'interruption statique pour Tx est fixé à 64 µsec par défaut.
Quant au taux de modération Rx, son réglage varie selon le type d'instance. Sur certains types, la modération Rx est désactivée par défaut ; sur d'autres, elle est activée en mode adaptatif.
Vous pouvez le vérifier avec ethtool via la commande ci-dessous.
[root@aws rossetv]# ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: n/a
stats-block-usecs: n/a
sample-interval: n/a
pkt-rate-low: n/a
pkt-rate-high: n/a
rx-usecs: 0
rx-frames: n/a
rx-usecs-irq: n/a
rx-frames-irq: n/atx-usecs: 64
tx-frames: n/a
tx-usecs-irq: n/a
tx-frames-irq: n/arx-usecs-low: n/a
rx-frame-low: n/a
tx-usecs-low: n/a
tx-frame-low: n/arx-usecs-high: n/a
rx-frame-high: n/a
tx-usecs-high: n/a
tx-frame-high: n/aCQE mode RX: n/a TX: n/a[root@aws rossetv]#
Dans l'exemple ci-dessus, la modération des interruptions pour Rx est désactivée.
Si votre taux d'interruption est élevé, il est recommandé d'activer la modération Rx adaptative, qui ajuste dynamiquement le taux d'interruption en fonction de la taille des paquets et du débit moyen. La commande ci-dessous y suffit.
sudo ethtool -C eth0 adaptive-rx on
Contraintes mémoire
Si nous avons largement traité la saturation CPU pour le traitement réseau, la mémoire peut elle aussi représenter une contrainte forte : une fois les buffers épuisés, le système commence à perdre des paquets.
Vérifiez que la mémoire noyau réservée est suffisante pour soutenir un taux élevé d'allocations de buffers de paquets. Le réglage se fait via le paramètre vm.min_free_kbytes dans /etc/sysctl.conf.
En règle générale, fixez cette valeur autour de 3 % de la mémoire système disponible. Cela peut se configurer avec les commandes ci-dessous, en exprimant la valeur en kbytes.
echo "vm.min_free_kbytes = 1048576" >> /etc/sysctl.conf
sudo sysctl -p
Pour les applications qui sollicitent intensivement UDP, les buffers spécifiques à UDP doivent eux aussi être augmentés : par défaut, Linux impose des limites très strictes aux performances du protocole UDP en plafonnant la taille du trafic UDP autorisé à se mettre en buffer sur le socket de réception.
Les commandes ci-dessous portent par exemple les buffers UDP à 128 Mo (en kbytes).
sudo su
echo "net.core.rmem_max=134217728" >> /etc/sysctl.conf
echo "net.core.rmem_default=134217728" >> /etc/sysctl.conf
sysctl -p
Discutons-en !
En résumé, atteindre un haut débit avec une faible latence suppose de relever trois défis majeurs : le throttling AWS, la saturation CPU et la saturation mémoire.
En vous attaquant à ces points, vous pouvez tirer le meilleur des performances réseau pour atteindre un débit maximal et une latence minimale.
Dans les sections précédentes, nous avons exploré différentes pistes pour traiter ces contraintes selon les conditions. Si les stratégies évoquées s'appliquent largement à de nombreux contextes, chaque environnement a ses spécificités.
Dans cet esprit, et si nous en discutions ? Contactez DoiT pour organiser un échange sur l'optimisation réseau et d'autres sujets avec nos Cloud Architects.
stop
Should be word exceeded.
Répondre
this is pure gold !!!
Répondre