∘ Enhanced Networking Performance
∘ Entendendo o ENA e sua importância
∘ Por que usar sempre as versões mais recentes
∘ A vida (bem simplificada) de um pacote de rede
∘ Receive Packet Steering (RPS)
Enhanced Networking Performance
Em computação em nuvem, a performance de rede é fundamental para a escalabilidade e a eficiência de aplicações que exigem alto throughput e baixa latência. As gerações modernas de instâncias EC2 contam com Enhanced Networking via Elastic Network Adapter (ENA) e o driver ENA proprietário da Amazon, entregando ganhos expressivos de performance em relação às máquinas virtuais tradicionais. Este artigo se aprofunda em técnicas avançadas de rede e boas práticas para otimizar a performance de rede em instâncias EC2 Linux e turbinar suas aplicações.
Entendendo o ENA e sua importância
As gerações mais antigas de instâncias EC2 são virtualizadas em Xen e não suportam o ENA. Já as gerações modernas usam KVM como hypervisor e contam com os drivers ENA proprietários da AWS para a parte de rede.
No Xen existe o conceito de dom0, o domínio de gerenciamento por onde passa toda requisição de I/O e onde rodam os serviços do host subjacente.
O I/O de rede sai das máquinas virtuais (domU) pelos drivers netfront/netback, enquanto o I/O de disco usa o blockfront/blockback.
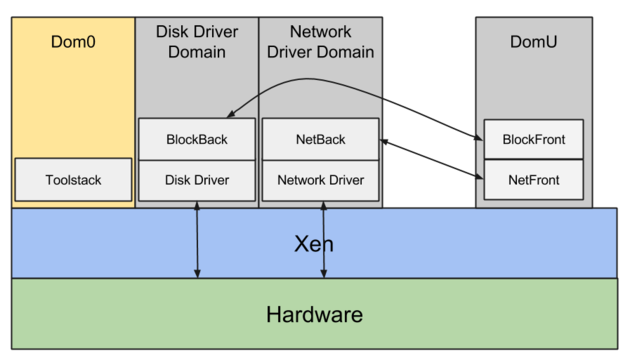
Para cada requisição de I/O, a máquina virtual (domU) precisa processá-la e repassá-la ao dom0 por meio desses drivers, que então usa os drivers de fato para encaminhá-la ao hardware físico.
Resumindo: para cada requisição de I/O da máquina virtual (domU), sempre há um intermediário (dom0) entre a VM e o hardware real, o que resulta em performance ruim e, principalmente, em jitter significativo, entregando uma performance de I/O bem imprevisível.
Além disso, o dom0 participa das requisições de I/O de TODAS as máquinas virtuais daquele host, o que pode ser um número considerável — possivelmente centenas de VMs no mesmo host físico. Isso só aumenta a imprevisibilidade da performance de I/O e cria um problema sério de noisy neighbours.
Com o driver de rede proprietário da Amazon (ENA), esse problema é resolvido: as máquinas virtuais passam a se comunicar diretamente com o hardware, sem precisar de um intermediário.
Nas gerações modernas de instâncias EC2 baseadas em Nitro não existe mais o dom0: a AWS abandonou o Xen de vez e passou a usar o KVM como hypervisor.
Por que usar sempre as versões mais recentes
Esses avanços vêm ficando cada vez mais expressivos a cada nova geração de instâncias EC2, o que reforça a importância de sempre escolher a geração mais recente quando o objetivo é extrair o máximo de performance.
Também é fundamental garantir que seu sistema Linux esteja usando a versão mais recente do driver ENA, que traz todas as novas otimizações de performance e correções de bugs.
A vida (bem simplificada) de um pacote de rede
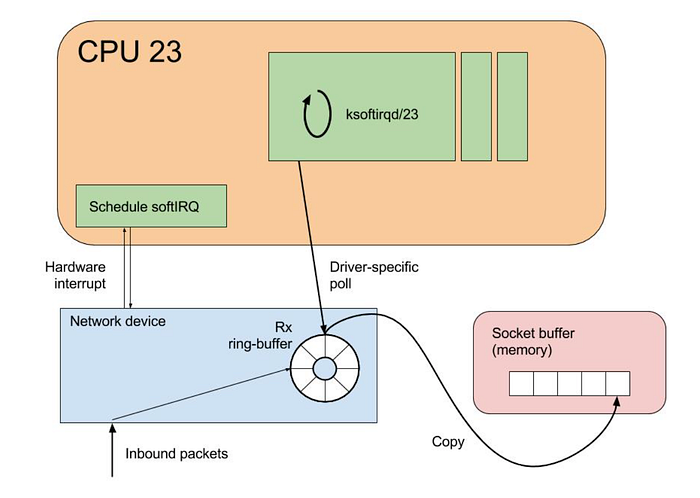
Simplificando bastante, a vida de um pacote de rede vindo da internet para um sistema Linux começa na chegada à placa de rede, que então gera uma interrupção para sinalizar à CPU que dados chegaram.
A CPU pausa o que estava fazendo e trata a interrupção. Isso envolve executar uma rotina de tratamento de interrupção, que processa o pacote recebido.
Em seguida, a pilha de rede do kernel assume e processa o pacote. Isso inclui várias camadas, como tratamento de IP, tratamento de TCP/UDP e por aí vai. O kernel verifica a integridade do pacote, determina seu destino no sistema e cuida do roteamento.
Se o pacote for destinado a uma aplicação rodando no sistema, ele é movido para um socket buffer. Esses são os endpoints de envio e recebimento de dados de um computador, alocados na memória RAM.
Para os fins deste artigo, vamos focar em duas etapas distintas da vida de um pacote de rede: o tratamento de interrupção, que sinaliza a chegada de novos dados do hardware, e as filas do ENA, que cuidam do processamento dos pacotes de rede dentro da pilha Linux.
Para o tratamento de interrupções, o Linux usa mecanismos como SoftIRQs e NAPI para processar pacotes de rede com eficiência.
Em vez de parar imediatamente o que a CPU está fazendo toda vez que um pacote de rede chega, com as interrupções de software (SoftIRQs) o sistema consegue adiar a execução, permitindo que o kernel posterge o processamento em favor de algo mais urgente.
O NAPI é uma interface projetada para melhorar a performance de rede sob alta carga. Ele troca o modelo de processamento de pacotes orientado a interrupções por um modelo de polling quando o tráfego de rede atinge certo limiar, reduzindo o overhead causado por interrupções excessivas.
Filas do ENA
Em termos simples, uma fila do ENA é como um conjunto de esteiras que ajuda a gerenciar o tráfego de internet, lidando com a entrada e a saída de pacotes de rede no sistema. Essas esteiras se organizam em dois tipos:
Filas de transmissão (Tx), onde o sistema coloca os dados que quer enviar para a internet; e filas de recepção (Rx), onde os dados vindos da internet são recebidos e, em seguida, colocados em um buffer para serem processados.
Cada uma dessas filas tem uma seção de submission e uma seção de completion. Inicialmente, os dados são colocados na seção de submission, seja para serem enviados (Tx) ou para preparar o recebimento de dados (Rx). A seção de completion confirma se os dados foram enviados ou recebidos com sucesso.
Com essa visão das filas do ENA, fica fácil ver como elas podem virar um gargalo e prejudicar a performance de rede. Instâncias EC2 podem ter várias filas do ENA (até 32 por ENI), dependendo do tamanho do tipo da instância. Esse suporte a múltiplas filas permite distribuir o tráfego de rede entre vários núcleos de CPU, reduzindo gargalos e melhorando a eficiência geral no manuseio dos dados, com latências menores e throughput maior.
Com o ethtool, dá para monitorar métricas fornecidas pelo driver ENA da Amazon e entender melhor como o sistema está lidando com a carga de tráfego nessas filas.
Uma das métricas importantes disponíveis é o número de stops nessas filas. Eles indicam que pacotes foram submetidos aos rings Tx mais rápido do que conseguiam ser processados, causando descarte.
[root@aws rossetv]# ethtool -S eth0|grep stop
queue_0_tx_queue_stop: 0
queue_1_tx_queue_stop: 0
Quando há um número significativo de stops nas filas do ENA, isso geralmente indica throttling — seja por throttling da AWS, por ultrapassagem dos limites de rede da instância, seja por resource starvation, quando não há poder de processamento ou buffers suficientes para dar conta dos pacotes que chegam.
Para refinar a análise, dá para verificar throttling olhando as métricas exceeded, com o comando abaixo.
[root@aws rossetv]# ethtool -S eth0|grep stop
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Se houver algum valor diferente de zero em qualquer um desses contadores, dê uma olhada em um artigo anterior meu sobre Troubleshooting AWS network throttling, que estou linkando aqui.
Confirmado que não houve throttling pelo lado da AWS, é provável que seu sistema esteja enfrentando resource starvation no nível de rede.
CPU Starvation
Aprofundando nas filas do ENA: elas processam os pacotes de rede. Antes desse ponto, há também o tratamento de IRQ pelo kernel, que cuida das interrupções vindas da placa de rede sinalizando à CPU que novos dados chegaram. A CPU então interrompe a tarefa atual para tratar a interrupção e, mais adiante, esses dados serão tratados pelo ENA como pacote de rede.
Se as vCPUs de uma instância estiverem sobrecarregadas ou utilizadas de forma desigual, podem ocorrer atrasos no processamento do tráfego de rede, levando a descarte de pacotes no lado Rx e a timeouts de completion no lado Tx, o que resulta em performance baixa e latência altamente variável.
Para alcançar performance de rede alta e estável, é essencial garantir que as vCPUs responsáveis por tratar o tráfego de rede (as filas do ENA) estejam disponíveis e tenham tempo de processamento suficiente para essa tarefa.
A maior parte do processamento de rede acontece no roteamento NAPI, executando em contexto softirq. Os núcleos de CPU envolvidos no processamento NAPI podem ser identificados executando o comando a seguir:
[root@aws rossetv]# egrep 'CPU|eth0' /proc/interrupts
CPU0 CPU1
28: 4531 1535 PCI-MSI 81921-edge eth0-Tx-Rx-0
29: 460 4311 PCI-MSI 81922-edge eth0-Tx-Rx-1
[root@aws rossetv]#
Em alguns casos, você também pode ver as threads ksoftirqd consumindo praticamente 100% do núcleo da CPU. Essas threads são responsáveis por tratar essas interrupções antes que o tráfego chegue às filas do ENA.
Há várias causas possíveis para CPU starvation no processamento de rede: pode ser simplesmente que o sistema esteja sobrecarregado com outras tarefas intensivas em CPU, o que dá para detectar com utilitários como o htop, ou usando o perf para descobrir onde os núcleos passam a maior parte do tempo.
Às vezes, a alta utilização de CPU tem natureza intermitente, gerando picos curtos de uso elevado. Nesses casos, dá para aumentar o tamanho do ring Rx para compensar a indisponibilidade temporária de CPU.
Por padrão, o tamanho do ring Rx do ENA é de 1K entradas, mas pode ser aumentado dinamicamente até 16K usando o ethtool. Para aumentar o tamanho do ring Rx em eth0 para 4096, por exemplo, basta o comando abaixo.
sudo ethtool -G eth0 rx 4096
Se os núcleos de CPU responsáveis pelo processamento de rede estiverem constantemente sobrecarregados e perto de 100% de uso, enquanto o uso geral da CPU não está tão alto, isso pode indicar distribuição desigual de carga entre as vCPUs disponíveis.
Para corrigir, basta reatribuir outras tarefas que rodam nas vCPUs sobrecarregadas para vCPUs menos carregadas que não participem do processamento de rede, usando os utilitários Linux taskset ou numactl.
Também é possível desviar interrupções de rede de vCPUs já sobrecarregadas definindo IRQBALANCE_BANNED_CPUS em /etc/sysconfig/irqbalance, com a máscara de CPU indicando os núcleos que você quer excluir, e depois reiniciando o serviço irqbalance.
Com essa abordagem, você garante que os núcleos de CPU que cuidam das filas do ENA não fiquem ocupados também tratando IRQs de rede.
Se houver mais núcleos de CPU na sua instância EC2 do que filas do ENA, dá para habilitar também o receive packet steering (RPS) e distribuir parte do processamento de tráfego Rx para outras vCPUs. No entanto, é recomendável manter os núcleos de vCPU do RPS no mesmo nó NUMA dos nós de vCPU que processam IRQs do ENA. E também evite ter vCPU de RPS em núcleos sibling de vCPUs de IRQ quando o hyperthreading estiver habilitado.
As abordagens indicadas acima permitem um controle bastante refinado sobre quais núcleos de CPU tratam quais aspectos do processamento de rede no Linux, garantindo o máximo absoluto de performance.
Receive Packet Steering (RPS)
Receive packet steering (RPS) é um método para direcionar pacotes de rede a CPUs específicas para processamento. Ele pode ser usado para evitar que a fila de hardware de uma única placa de rede vire um gargalo no tráfego.
O RPS é configurado para cada dispositivo de rede e fila de recepção, especificamente no arquivo /sys/class/net/eth0/queues/rx-0/rps_cpus, em que eth0 é o dispositivo de rede e rx-0 indica a fila de recepção apropriada.
Por padrão, o arquivo rps_cpus está definido como 0, o que efetivamente desativa o RPS — ou seja, o mesmo núcleo de CPU que trata a interrupção de rede também processa o pacote. Para ativar o RPS, configure o arquivo rps_cpus apropriado com as CPUs que devem processar os pacotes do dispositivo de rede e da fila de recepção especificados.
A configuração nos arquivos rps_cpus usa bitmaps de CPU separados por vírgula. Para permitir que uma CPU gerencie interrupções de uma fila de recepção em uma interface, é preciso definir como 1 os valores correspondentes no bitmap.
Você pode identificar quais CPUs estão associadas a quais nós NUMA com o comando lscpu, conforme abaixo:
[root@aws rossetv]# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Usando o exemplo acima, vamos habilitar o RPS para os núcleos 48 a 63. Esse sistema tem 64 núcleos, e cada caractere hexadecimal na máscara representa 4 bits, então precisaremos de 16 caracteres hexadecimais para representar 64 bits. Para habilitar os últimos 16 núcleos (48–63) para RPS, precisamos dos últimos 16 bits definidos como 1 e todos os demais como 0. A representação hexadecimal de 1111 1111 1111 1111 (16 bits para os núcleos 48-63) é FFFF.
Como estamos trabalhando com uma representação de 64 bits e precisamos habilitar os 16 bits mais altos, a máscara fica 0000,00000000,00000000,0000FFFF.
Para aplicar essa configuração em várias filas de recepção, dá para usar os comandos a seguir e iterar pelas filas Rx rx-0 até rx-15 da interface eth0, configurando-as para usar apenas os núcleos 48 a 63:
sudo bash -c 'for i in $(seq 0 15); do echo "0000,00000000,00000000,0000FFFF" > /sys/class/net/eth0/queues/rx-$i/rps_cpus; done'
Essa alteração não persiste após o reboot. Para torná-la persistente, depois dos testes podemos escrever um script simples e adicioná-lo para rodar no boot, com os comandos abaixo.
sudo su
echo 'for i in `seq 0 15`; do echo $(printf "0000,00000000,00000000,0000FFFF") | sudo tee /sys/class/net/eth0/queues/rx-$i/rps_cpus; done' > /sbin/rps_core
chmod +x /sbin/rps_core
echo "/sbin/rps_core" >> /etc/rc.local
chmod +x /etc/rc.local
Atenção: se o serviço irqbalance estiver ativo, o processamento de IRQ pode migrar para outras vCPUs, reduzindo a eficácia do RPS. Embora não seja aconselhável desabilitar o irqbalance, dá para especificar quais núcleos de CPU excluir do processamento de IRQ definindo a variável IRQBALANCE_BANNED_CPUS em /etc/sysconfig/irqbalance.
A máscara de CPU é calculada da mesma forma que acima, então neste exemplo específico definiríamos IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF e reiniciaríamos o irqlbalance com os comandos abaixo.
sudo su
echo "IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF" >> /etc/sysconfig/irqbalance
sudo systemctl restart irqbalance
Interrupt Moderation
Alto throughput de rede e baixa latência são objetivos centrais em ambientes de nuvem de alta performance. Mas existe um trade-off entre latência e throughput do ponto de vista do controlador Ethernet.
Para alcançar menor latência, o controlador costuma reduzir ao máximo o intervalo entre interrupções para acelerar o processamento de pacotes pequenos, ao custo de maior uso de CPU e menor throughput.
Por outro lado, para melhorar o throughput e minimizar o overhead causado por interrupções frequentes, intervalos maiores entre interrupções são desejáveis. Por isso, escolher um intervalo de interrupção adequado é fundamental para encontrar o melhor equilíbrio de performance.
Interrupt moderation é um recurso do driver suportado pelos tipos de instância baseados em Nitro que usam ENA, permitindo ao usuário gerenciar a taxa de interrupções enviadas à CPU durante a transmissão e a recepção de pacotes.
Sem nenhuma interrupt moderation, o sistema dispara uma interrupção para cada pacote transmitido e recebido. Embora isso minimize a latência de cada pacote, recursos extras de CPU são gastos com o overhead de processamento de interrupção, o que pode reduzir bastante o throughput.
Quando a interrupt moderation está habilitada, vários pacotes são tratados a cada interrupção, melhorando a eficiência geral do processamento de interrupções e reduzindo a utilização de CPU — em troca de uma latência maior, já que a CPU espera por múltiplos pacotes antes de processá-los.
Em instâncias EC2 que usam o driver ENA, para Tx o atraso estático de interrupção é de 64 µsec por padrão.
Já a taxa de moderação Rx pode variar conforme o tipo da instância. Em alguns tipos, a moderação Rx vem desabilitada por padrão; em outros, vem habilitada em modo adaptativo.
Para verificar isso, use o ethtool com o comando abaixo.
[root@aws rossetv]# ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: n/a
stats-block-usecs: n/a
sample-interval: n/a
pkt-rate-low: n/a
pkt-rate-high: n/a
rx-usecs: 0
rx-frames: n/a
rx-usecs-irq: n/a
rx-frames-irq: n/atx-usecs: 64
tx-frames: n/a
tx-usecs-irq: n/a
tx-frames-irq: n/arx-usecs-low: n/a
rx-frame-low: n/a
tx-usecs-low: n/a
tx-frame-low: n/arx-usecs-high: n/a
rx-frame-high: n/a
tx-usecs-high: n/a
tx-frame-high: n/aCQE mode RX: n/a TX: n/a[root@aws rossetv]#
No exemplo acima, a interrupt moderation para Rx está desabilitada.
Se você tem uma alta taxa de interrupções, é recomendável habilitar a moderação Rx adaptativa, que ajusta dinamicamente a taxa de interrupção com base no tamanho do pacote e no throughput médio. Isso pode ser feito com o comando abaixo.
sudo ethtool -C eth0 adaptive-rx on
Restrições de memória
Falamos bastante sobre CPU starvation no processamento de rede, mas a memória também pode ser uma restrição importante: se os buffers se esgotarem, o sistema começa a descartar pacotes.
É preciso garantir que a memória reservada do kernel seja suficiente para sustentar uma alta taxa de alocação de buffers de pacote. Isso pode ser ajustado pelo parâmetro vm.min_free_kbytes em /etc/sysctl.conf.
Como regra geral, defina esse valor em torno de 3% da memória disponível no sistema. Você consegue configurar isso com os comandos abaixo, definindo o valor em kbytes.
echo "vm.min_free_kbytes = 1048576" >> /etc/sysctl.conf
sudo sysctl -p
Para aplicações que usam UDP intensamente, os buffers específicos de UDP também devem ser aumentados, já que, por padrão, o Linux impõe limites bem restritivos à performance do protocolo UDP, restringindo o tamanho do tráfego UDP que pode ser bufferizado no socket de recepção.
Os comandos abaixo definem os buffers UDP em 128MB (em kbytes), por exemplo.
sudo su
echo "net.core.rmem_max=134217728" >> /etc/sysctl.conf
echo "net.core.rmem_default=134217728" >> /etc/sysctl.conf
sysctl -p
Vamos conversar!
Resumindo, atingir alto throughput com baixa latência envolve superar três desafios principais: AWS Throttling, CPU Starvation e Memory Starvation.
Ao atacar essas questões, você consegue elevar a performance de rede para alcançar o máximo de throughput e a mínima latência.
Nas seções anteriores, exploramos várias formas de lidar com essas restrições em diferentes cenários. Embora as estratégias mencionadas se apliquem, em geral, a muitos contextos, cada ambiente tem suas particularidades.
Pensando nisso, que tal trocarmos uma ideia? Fale com a DoiT para agendar um bate-papo sobre otimização de rede e outros temas com nossos Cloud Architects.
stop
Should be word exceeded.
Reply
this is pure gold !!!
Reply