∘ ENAキュー
∘ Receive Packet Steering (RPS)
∘ メモリの制約
拡張ネットワーキング性能
クラウドコンピューティングにおいて、ネットワーク性能は高スループットと低レイテンシを必要とするアプリケーションの拡張性と効率性を左右する重要な要素です。最新世代のEC2インスタンスタイプは、Elastic Network Adapter(ENA)による拡張ネットワーキングと、Amazon独自のENAドライバを備え、従来の仮想マシンと比べて大幅に性能を向上させています。本記事では、EC2 Linuxインスタンスのネットワーク性能を最適化し、アプリケーションのパフォーマンスを引き上げるための高度なテクニックとベストプラクティスを掘り下げて解説します。
ENAとは何か、なぜ重要か
旧世代のEC2インスタンスはXenで仮想化されており、ENAには対応していません。一方、最新世代はKVMで仮想化されており、ネットワーク処理にAWS独自のENAドライバを使用しています。
Xenにはdom0という概念があります。これはすべてのI/Oリクエストが経由する管理ドメインで、基盤ホスト向けのサービスもここで動作します。
ネットワークI/Oはnetfront/netbackドライバを介して仮想マシン(domU)から外へ出ていき、ディスクI/Oはblockfront/blockbackを使います。
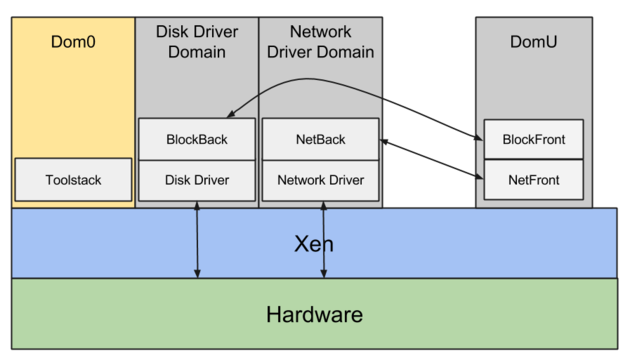
仮想マシン(domU)はI/Oリクエストごとに、これらのドライバを介してdom0に処理を引き渡し、dom0が実際のドライバ経由で物理ハードウェアにリクエストを伝えます。
つまり、仮想マシン(domU)のすべてのI/Oリクエストには、仮想マシンと実際のハードウェアの間に必ず仲介役のdom0が入ることになります。これが性能の低下を招き、さらに大きなジッターを引き起こすため、I/O性能が極めて予測しづらくなります。
加えて、dom0は同一基盤ホスト上のすべての仮想マシンのI/Oリクエストに関与します。1台の基盤ホストには数百台の仮想マシンが乗ることもあり、I/O性能の不安定さに拍車をかけ、いわゆるノイジーネイバー問題という重大な課題を引き起こします。
Amazon独自のネットワークドライバ(ENA)では、仮想マシンが仲介役を介さず直接ハードウェアと通信できるようにすることで、この問題を解消しています。
Nitro上に構築された最新世代のEC2インスタンスでは、すでにdom0は存在しません。AWSはXenから完全に脱却し、ハイパーバイザーとしてKVMを採用しています。
最新バージョンを使うべき理由
こうした改善は、新しい世代のEC2インスタンスほど顕著です。最大限の性能を引き出したいなら、常に最新世代のEC2インスタンスを選ぶことがいかに重要かを物語っています。
同様に欠かせないのが、新しい性能最適化やバグ修正を漏れなく取り込んだ最新バージョンのENAドライバをLinux環境で使用することです。
ネットワークパケットの一生(簡略版)
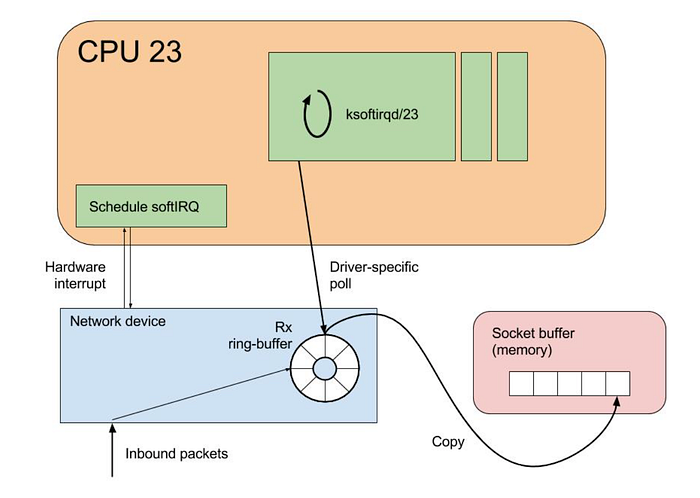
ごく簡単に説明すると、インターネットからLinuxシステムに届くネットワークパケットの一生は、ネットワークインターフェースカードへの到着から始まります。ここでデータの到着を知らせる割り込みがCPUに対して発行されます。
CPUは現在の処理を中断して割り込みを処理します。具体的には、受信したパケットを処理する割り込みハンドラルーチンを実行します。
その後、カーネルのネットワークスタックが処理を引き継ぎ、パケットを処理します。ここではIP処理、TCP/UDP処理など、複数のレイヤー処理が行われます。カーネルはパケットの整合性をチェックし、システム上の宛先を判定して、ルーティングを行います。
パケットがシステム内のアプリケーション宛てであれば、ソケットバッファに移されます。ソケットバッファはコンピュータ上でデータを送受信するためのエンドポイントで、RAM上に確保されています。
本記事では、ネットワークパケットの一生のうち2つのステップに焦点を当てます。ハードウェアからの新しいデータの到着を知らせる割り込み処理と、Linuxスタック内でネットワークパケットの処理を担うENAキューです。
割り込み処理においてLinuxは、ネットワークパケット処理を効率化するためにSoftIRQやNAPIといった仕組みを利用しています。
ネットワークパケットが届くたびにCPUの処理を即座に中断するのではなく、ソフトウェア割り込み(SoftIRQs)を用いることで、システムは処理を遅延実行できるようになり、カーネルはより緊急性の高い処理を優先しつつネットワーク処理を後回しにできます。
NAPIは、高負荷時にネットワーク性能を向上させるために設計されたインターフェースです。ネットワークトラフィックが一定の閾値に達すると、パケット処理を割り込み駆動モデルからポーリングモデルへ切り替え、過剰な割り込みによるオーバーヘッドを軽減します。
ENAキュー
簡単に言えば、ENAキューはインターネットトラフィックを管理する一連のベルトコンベアのようなもので、システムへ出入りするネットワークパケットを処理します。このベルトコンベアは2種類に分類されます。
送信キュー(Tx)は、システムがインターネットへ送信したいデータを置く場所です。受信キュー(Rx)はインターネットから届いたデータを受け取り、バッファに格納して処理する場所です。
これらのキューにはそれぞれsubmission(送信指示)セクションとcompletion(完了)セクションがあります。データはまずsubmissionセクションに置かれ、送信(Tx)または受信準備(Rx)のいずれかが行われます。completionセクションでは、データの送受信が成功したかどうかが確認されます。
こうしたENAキューの全体像を踏まえると、ここがボトルネックとなりネットワーク性能を阻害しうることが容易に想像できます。EC2インスタンスは、インスタンスタイプのサイズに応じて複数のENAキュー(ENIあたり最大32個)を持つことができます。このマルチキュー対応により、ネットワークトラフィックを複数のCPUコアに分散できるため、ボトルネックが軽減され、低レイテンシかつ高スループットでデータ処理効率を全体的に高められます。
ethtoolを使えば、AmazonのENAドライバが提供するメトリクスを監視でき、これらのキューでシステムがどのようにトラフィック負荷を処理しているかをより詳しく把握できます。
重要なメトリクスのひとつが、これらのキューにおけるstops(停止)の回数です。これは、処理可能な速度を超えるペースでパケットがTxリングに投入された結果として発生し、ドロップを引き起こします。
[root@aws rossetv]# ethtool -S eth0|grep stop
queue_0_tx_queue_stop: 0
queue_1_tx_queue_stop: 0
ENAキューでstopsが頻発している場合、通常は次のいずれかによるスロットリングが発生していることを示します。インスタンスのネットワーク制限を超過したことによるAWS側のスロットリングか、入ってくるパケットを処理するのに十分な処理能力やバッファが不足しているリソース不足(starvation)です。
切り分けをさらに進めるには、以下のコマンドでexceeded系のメトリクスを確認し、スロットリングが発生していないかをチェックします。
[root@aws rossetv]# ethtool -S eth0|grep stop
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
これらのカウンタのいずれかが0以外の値を示している場合は、以前執筆したTroubleshooting AWS network throttlingを参照してください(リンクを掲載しています)。
AWS側でのスロットリングが発生していないと確認できた場合は、システムがネットワーク処理に必要なリソース不足に陥っている可能性が高いと考えられます。
CPU Starvation
ENAキューの話をさらに掘り下げます。ENAキューはネットワークパケットを処理しますが、その前段階としてカーネルによるIRQ処理があります。これは、ネットワークカードからの割り込みを受けて、新しいデータが到着したことをCPUに伝える処理です。CPUは現在のタスクを中断して割り込みを処理し、その後、データはネットワークパケットとしてENAで扱われます。
インスタンスのvCPUが過負荷になっていたり、利用が偏っていたりすると、ネットワークトラフィックの処理に遅延が生じます。その結果、Rx側ではパケットドロップ、Tx側では完了タイムアウトが発生し、性能の低下とレイテンシの大きな変動を招きます。
高く安定したネットワーク性能を実現するには、ネットワークトラフィック(ENAキュー)を担当するvCPUが利用可能で、この処理に十分な実行時間が確保されていることが不可欠です。
ネットワーク処理の大部分は、softirqコンテキストで動作するNAPIルーティングで行われます。NAPI処理に関与するCPUコアは、以下のコマンドで特定できます。
[root@aws rossetv]# egrep 'CPU|eth0' /proc/interrupts
CPU0 CPU1
28: 4531 1535 PCI-MSI 81921-edge eth0-Tx-Rx-0
29: 460 4311 PCI-MSI 81922-edge eth0-Tx-Rx-1
[root@aws rossetv]#
場合によっては、ksoftirqdスレッドがCPUコアをほぼ100%消費している様子が見られることもあります。これらのスレッドは、トラフィックがENAキューに到達する前の割り込み処理を担っています。
ネットワーク処理におけるCPU不足の原因はいくつか考えられます。単純にシステムが他のCPU負荷の高いタスクで過負荷になっているだけというケースもあり、これはhtopなどのユーティリティで検出できます。あるいはperfを使ってコアがどこで時間を費やしているかを調べることもできます。
CPU使用率がスパイク状の傾向を示し、短時間のCPU使用率ピークとして現れる場合もあります。こうしたケースでは、一時的なCPU不足を補うためにRxリングのサイズを増やすという手があります。
デフォルトでは、ENAのRxリングサイズは1Kエントリですが、ethtoolで動的に最大16Kエントリまで拡張できます。たとえばeth0のRxリングサイズを4096に増やすには、以下のコマンドを使います。
sudo ethtool -G eth0 rx 4096
ネットワーク処理を担当するCPUコアが常に過負荷で100%近くまで張り付いている一方、全体のCPU使用率はそれほど高くない場合、利用可能なvCPU間で負荷分散が偏っている可能性があります。
これは、過負荷のvCPU上で実行されている他のタスクを、ネットワーク処理に関与していない負荷の低い別のvCPUに、Linuxのtasksetまたはnumactlユーティリティを使って割り当て直すことで解消できます。
また、すでに過負荷となっているvCPUからネットワーク割り込みを逃がすこともできます。システムの/etc/sysconfig/irqbalanceにあるIRQBALANCE_BANNED_CPUSに、除外したいCPUを示すCPUマスクを設定し、irqbalanceサービスを再起動してください。
このアプローチにより、ENAキューを処理するCPUコアがネットワークIRQの処理で塞がってしまう事態を防げます。
EC2インスタンスのCPUコア数がENAキューの数より多い場合は、Receive Packet Steering(RPS)を有効にして、Rxトラフィック処理の一部を他のvCPUにオフロードすることもできます。ただし、RPSのvCPUコアは、ENA IRQを処理するvCPUと同じNUMAノードに配置することが推奨されます。また、ハイパースレッディングが有効な場合は、RPSのvCPUをIRQ処理用vCPUの兄弟コアに配置しないようにしてください。
これらのアプローチを組み合わせれば、Linuxのネットワーク処理のどの部分をどのCPUコアが担うかをきめ細かく制御でき、性能を最大限まで引き出せます。
Receive Packet Steering (RPS)
Receive Packet Steering(RPS)は、ネットワークパケットの処理を特定のCPUに振り分ける仕組みです。これにより、単一のネットワークインターフェースカードのハードウェアキューがネットワークトラフィックのボトルネックになるのを防げます。
RPSはネットワークデバイスおよび受信キューごとに設定します。具体的には/sys/class/net/eth0/queues/rx-0/rps_cpusファイルで設定します。eth0はネットワークデバイス、rx-0は対象の受信キューを示します。
デフォルトではrps_cpusファイルは0に設定されており、RPSは事実上無効化されています。つまり、ネットワーク割り込みを処理したCPUコアと同じコアがパケット処理も行う状態です。RPSを有効にするには、対象のrps_cpusファイルに、指定したネットワークデバイスと受信キューからのパケットを処理させたいCPUを設定します。
rps_cpusファイルの設定はカンマ区切りのCPUビットマップで指定します。あるCPUにインターフェース上の受信キューの割り込みを処理させるには、ビットマップ中の該当ビットを1に設定します。
どのCPUがどのNUMAノードに属しているかは、以下のようにlscpuコマンドで確認できます。
[root@aws rossetv]# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
上の例で、コア48〜63に対してRPSを有効にしてみましょう。このシステムは64コアあり、ビットマスクの16進数1文字は4ビットを表すため、64ビットを表現するには16進数16文字が必要です。最後の16コア(48〜63)でRPSを有効にするには、最後の16ビットを1に、それ以外をすべて0に設定します。1111 1111 1111 1111(コア48〜63のための16ビット)を16進数で表すとFFFFになります。
64ビット表現を扱い、最上位の16ビットを有効にする必要があるため、ビットマスクは0000,00000000,00000000,0000FFFFとなります。
この設定を複数の受信キューに適用するには、以下のコマンドを使い、eth0インターフェース上のrx-0からrx-15のRxキューをループ処理して、コア48〜63のみを使うように設定します。
sudo bash -c 'for i in $(seq 0 15); do echo "0000,00000000,00000000,0000FFFF" > /sys/class/net/eth0/queues/rx-$i/rps_cpus; done'
ただし、この変更は再起動後には保持されません。永続化するには、テスト後に簡単なスクリプトを作成し、以下のコマンドで起動時に実行されるよう登録します。
sudo su
echo 'for i in `seq 0 15`; do echo $(printf "0000,00000000,00000000,0000FFFF") | sudo tee /sys/class/net/eth0/queues/rx-$i/rps_cpus; done' > /sbin/rps_core
chmod +x /sbin/rps_core
echo "/sbin/rps_core" >> /etc/rc.local
chmod +x /etc/rc.local
なお、irqbalanceサービスが有効な場合、IRQ処理が別のvCPUに移行する可能性があり、RPSの効果が薄れることがあります。irqbalanceを無効化することは推奨されませんが、/etc/sysconfig/irqbalanceのIRQBALANCE_BANNED_CPUS変数を設定することで、IRQ処理から除外するCPUコアを指定できます。
CPUマスクの計算方法は前述と同じです。この具体例ではIRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFFと設定し、以下のコマンドでirqlbalanceを再起動します。
sudo su
echo "IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF" >> /etc/sysconfig/irqbalance
sudo systemctl restart irqbalance
割り込みモデレーション
高いネットワークスループットと低レイテンシは、高性能なクラウド環境における主要な目標です。しかし、Ethernetコントローラの観点から見ると、レイテンシとスループットはトレードオフの関係にあります。
レイテンシを下げるには、コントローラは通常、割り込みの間隔を短くして小さなパケットの処理を高速化します。その代償として、CPU使用率が上がり、スループットは低下します。
一方、スループットを向上させ、頻繁な割り込みによるオーバーヘッドを抑えるには、より長い割り込み間隔が望ましくなります。したがって、性能のベストバランスを得るためには、適切な割り込み間隔を選ぶことが極めて重要です。
割り込みモデレーションは、ENAを使用するNitro搭載インスタンスタイプでサポートされているドライバ機能で、パケットの送受信時にCPUへの割り込み発生率をユーザーが制御できるようにするものです。
割り込みモデレーションを行わない場合、システムは送受信されるパケットごとに割り込みを発生させます。これによって個々のパケットのレイテンシは最小化できますが、割り込み処理のオーバーヘッドのために余分なCPUリソースが消費され、スループットを大きく低下させる可能性があります。
割り込みモデレーションを有効にすると、1回の割り込みで複数のパケットが処理されるため、全体の割り込み処理効率が高まり、CPU使用率が下がります。その代わりに、CPUは複数のパケットがそろうのを待ってから処理するため、レイテンシは高くなります。
ENAドライバを使用するEC2インスタンスでは、Txの静的な割り込み遅延がデフォルトで64 µsecに設定されています。
Rxのモデレーションレートは、インスタンスタイプによって設定が異なる場合があります。Rxモデレーションがデフォルトで無効化されているインスタンスタイプもあれば、アダプティブモードで有効化されているものもあります。
これは以下のコマンドでethtoolを使って確認できます。
[root@aws rossetv]# ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: n/a
stats-block-usecs: n/a
sample-interval: n/a
pkt-rate-low: n/a
pkt-rate-high: n/a
rx-usecs: 0
rx-frames: n/a
rx-usecs-irq: n/a
rx-frames-irq: n/atx-usecs: 64
tx-frames: n/a
tx-usecs-irq: n/a
tx-frames-irq: n/arx-usecs-low: n/a
rx-frame-low: n/a
tx-usecs-low: n/a
tx-frame-low: n/arx-usecs-high: n/a
rx-frame-high: n/a
tx-usecs-high: n/a
tx-frame-high: n/aCQE mode RX: n/a TX: n/a[root@aws rossetv]#
上記の例では、Rxの割り込みモデレーションが無効になっています。
割り込み発生率が高い場合は、パケットサイズと平均スループットに応じて割り込み発生率を動的に調整するアダプティブRxモデレーションを有効化することをお勧めします。これは以下のコマンドで実行できます。
sudo ethtool -C eth0 adaptive-rx on
メモリの制約
ここまでネットワーク処理におけるCPU不足を中心に取り上げてきましたが、メモリも見過ごせない制約となります。バッファが枯渇すれば、パケットがドロップされ始めるからです。
パケットバッファの高頻度な確保に耐えられるだけのカーネル予約メモリが確保されているか、確認しておく必要があります。これは/etc/sysctl.confのvm.min_free_kbytesパラメータを調整することで設定できます。
目安として、この値はシステム全体メモリの約3%に設定するとよいでしょう。値はkbytes単位で、以下のコマンドで設定できます。
echo "vm.min_free_kbytes = 1048576" >> /etc/sysctl.conf
sudo sysctl -p
UDPを多用するアプリケーションの場合は、UDP固有のバッファも増やしておくべきです。Linuxはデフォルトで、受信ソケットでバッファできるUDPトラフィックのサイズを制限することにより、UDPプロトコルの性能に非常に厳しい制限をかけているためです。
たとえば、以下のコマンドではUDPバッファを128MB(kbytes換算)に設定します。
sudo su
echo "net.core.rmem_max=134217728" >> /etc/sysctl.conf
echo "net.core.rmem_default=134217728" >> /etc/sysctl.conf
sysctl -p
お気軽にご相談ください!
まとめると、低レイテンシと高スループットを両立させるには、3つの主要な課題を克服する必要があります。AWSによるスロットリング、CPU Starvation、そしてMemory Starvationです。
これらに対処することで、ネットワーク性能を引き上げ、最大スループットと最小レイテンシを実現できます。
本記事では、さまざまな条件下でこれらの制約に対処する方法を見てきました。紹介した戦略は多くの環境に広く適用できますが、それぞれの環境には固有の事情があります。
そこで、ぜひ一度ご相談ください。 DoiTまでお問い合わせいただければ、ネットワーク最適化をはじめとするさまざまなテーマについて、当社のCloud Architectとディスカッションの場を設けます。
stop
Should be word exceeded.
返信
this is pure gold !!!
返信