∘ Enhanced Networking Performance
∘ ENA: che cos'è e perché è importante
∘ Perché conviene usare sempre le versioni più recenti
∘ La vita di un pacchetto di rete, in versione semplificata
∘ Code ENA
∘ Receive Packet Steering (RPS)
Enhanced Networking Performance
Nel cloud computing le prestazioni di rete sono cruciali per la scalabilità e l'efficienza delle applicazioni che richiedono throughput elevato e bassa latenza. Le generazioni moderne di istanze EC2 integrano l'Enhanced Networking con Elastic Network Adapter (ENA) e il driver ENA proprietario di Amazon, garantendo miglioramenti prestazionali significativi rispetto alle macchine virtuali tradizionali. Questo articolo approfondisce le tecniche di networking avanzate e le best practice per ottimizzare le prestazioni di rete sulle istanze EC2 Linux e migliorare quelle delle Sue applicazioni.
ENA: che cos'è e perché è importante
Le generazioni più datate di istanze EC2 sono virtualizzate con Xen e non supportano ENA. Quelle moderne, invece, si appoggiano a KVM e utilizzano i driver ENA proprietari di AWS per il networking.
In Xen esiste il concetto di dom0, ovvero il dominio di gestione attraverso cui passa ogni richiesta di I/O e in cui risiedono i servizi dell'host sottostante.
L'I/O di rete esce dalle macchine virtuali (domU) tramite i driver netfront/netback, mentre l'I/O su disco passa per blockfront/blockback.
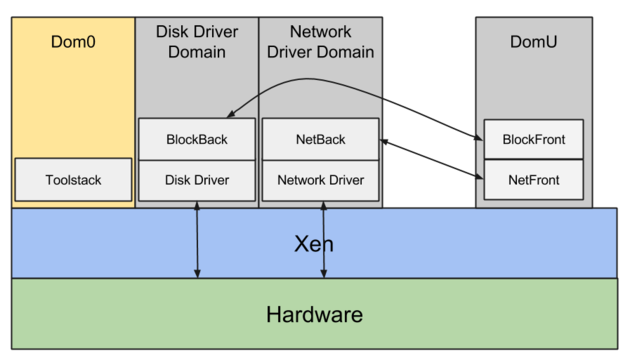
Per ogni richiesta di I/O, la macchina virtuale (domU) deve elaborarla e inoltrarla a dom0 tramite questi driver, che a loro volta si servono dei driver effettivi per inviarla all'hardware fisico.
In sintesi, per ogni richiesta di I/O della macchina virtuale (domU) c'è sempre un intermediario (dom0) tra la VM e l'hardware reale. Il risultato è una performance scarsa e, soprattutto, un jitter rilevante che si traduce in un I/O molto poco prevedibile.
A questo si aggiunge il fatto che dom0 gestisce le richieste di I/O di TUTTE le macchine virtuali presenti sull'host sottostante, che possono essere parecchie: anche centinaia sullo stesso host. Tutto ciò amplifica l'imprevedibilità dell'I/O e introduce un problema serio di noisy neighbours.
Con il driver di rete proprietario di Amazon (ENA) il problema si risolve: le macchine virtuali comunicano direttamente con l'hardware, senza alcun intermediario.
Sulle moderne generazioni di istanze EC2 basate su Nitro non esiste più dom0: AWS ha abbandonato Xen e adottato KVM come hypervisor.
Perché conviene usare sempre le versioni più recenti
Questi miglioramenti sono diventati progressivamente più marcati nelle nuove generazioni di istanze EC2 e questo conferma quanto sia importante scegliere sempre l'ultima generazione di istanze EC2 quando servono prestazioni al massimo livello.
È altrettanto fondamentale verificare che il proprio sistema Linux utilizzi la versione più recente del driver ENA, che include tutte le nuove ottimizzazioni e le correzioni di bug.
La vita di un pacchetto di rete, in versione semplificata
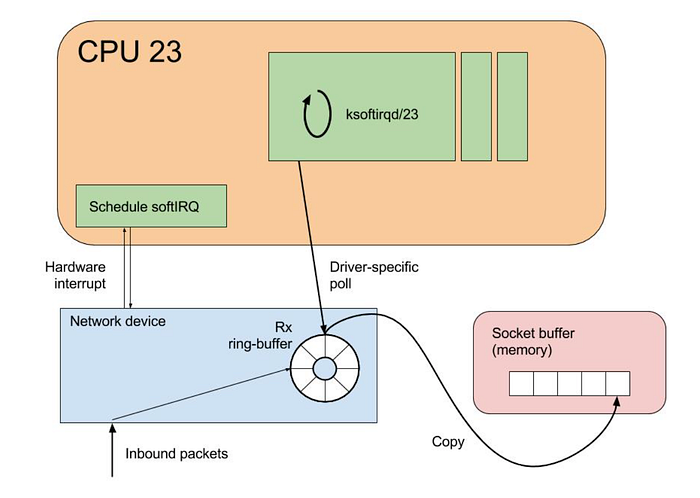
Semplificando al massimo, la vita di un pacchetto di rete che da Internet arriva a un sistema Linux inizia con il suo ingresso nella scheda di rete, la quale genera un interrupt per segnalare alla CPU l'arrivo di nuovi dati.
La CPU sospende quindi l'attività in corso e si occupa dell'interrupt. Questa fase prevede l'esecuzione di una routine di gestione dell'interrupt che elabora il pacchetto in arrivo.
A quel punto subentra lo stack di rete del kernel, che prende in carico il pacchetto. Si attivano vari livelli, come la gestione di IP, TCP/UDP e altri ancora. Il kernel verifica l'integrità del pacchetto, ne stabilisce la destinazione sul sistema e si occupa del routing.
Se il pacchetto è destinato a un'applicazione in esecuzione sul sistema, viene spostato in un buffer di socket, ovvero gli endpoint per l'invio e la ricezione dei dati su un computer, che risiedono nella memoria RAM.
Ai fini di questo articolo ci concentreremo su due fasi specifiche della vita di un pacchetto di rete: la gestione degli interrupt, che segnala l'arrivo di nuovi dati dall'hardware, e le code ENA, che si occupano dell'elaborazione dei pacchetti all'interno dello stack Linux.
Per la gestione degli interrupt, Linux si avvale di meccanismi come SoftIRQ e NAPI, che permettono di elaborare in modo efficiente i pacchetti di rete.
Anziché interrompere subito ciò che la CPU sta facendo a ogni arrivo di un pacchetto, gli interrupt software (SoftIRQ) consentono al sistema un'esecuzione differita: il kernel può rimandare l'elaborazione a favore di attività più urgenti.
NAPI è invece un'interfaccia pensata per migliorare le prestazioni di rete sotto carichi elevati. Quando il traffico raggiunge una determinata soglia, il modello di elaborazione dei pacchetti passa da quello basato sugli interrupt a uno di polling, riducendo l'overhead provocato da interrupt eccessivi.
Code ENA
Detto in modo semplice, una coda ENA funziona come una serie di nastri trasportatori che aiutano a gestire il traffico Internet, smistando i pacchetti di rete in entrata e in uscita dal sistema. Questi nastri trasportatori sono di due tipi:
le code di trasmissione (Tx), dove il sistema inserisce i dati da inviare verso Internet, e le code di ricezione (Rx), dove vengono accolti i dati in arrivo da Internet, che vengono poi posti in un buffer per l'elaborazione.
Ognuna di queste code dispone di una sezione di submission e di una di completion. Inizialmente i dati vengono collocati nella sezione di submission, sia per essere inviati (Tx) sia per prepararsi a ricevere dati in arrivo (Rx). La sezione di completion conferma poi se i dati sono stati inviati o ricevuti correttamente.
Con questa visione delle code ENA è facile capire come possano trasformarsi in un collo di bottiglia e penalizzare le prestazioni di rete. Le istanze EC2 possono disporre di più code ENA (fino a un massimo di 32 per ENI), in funzione delle dimensioni del tipo di istanza. Il supporto multi-coda permette di distribuire il traffico di rete su più core CPU, riducendo i colli di bottiglia e migliorando l'efficienza complessiva nella gestione dei dati, con latenze più basse e throughput più elevato.
Con ethtool, possiamo monitorare le metriche fornite dal driver ENA di Amazon e capire più nel dettaglio come il sistema gestisce il carico di traffico in queste code.
Tra le metriche più rilevanti c'è il numero di stops in queste code: indica che i pacchetti sono stati inviati ai ring Tx più velocemente di quanto fosse possibile elaborarli, causando di conseguenza un drop.
[root@aws rossetv]# ethtool -S eth0|grep stop
queue_0_tx_queue_stop: 0
queue_1_tx_queue_stop: 0
Quando si osserva un numero significativo di stops nelle code ENA, in genere si tratta di throttling riconducibile al throttling AWS, dovuto al superamento dei limiti di rete dell'istanza, oppure alla resource starvation, ossia alla mancanza di potenza di elaborazione o di buffer sufficienti per gestire i pacchetti in arrivo.
Per circoscrivere ulteriormente la causa, possiamo verificare il throttling esaminando le metriche exceeded con il comando seguente.
[root@aws rossetv]# ethtool -S eth0|grep stop
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Se uno di questi contatori riporta un valore diverso da zero, La rimando a un mio articolo precedente sul Troubleshooting AWS network throttling, che linko qui.
Una volta confermato che dal lato AWS non c'è alcun throttling, è probabile che il sistema stia subendo una resource starvation lato networking.
CPU Starvation
Approfondendo il discorso sulle code ENA, queste si occupano di elaborare i pacchetti di rete. Prima di arrivare a quel punto interviene la gestione degli IRQ da parte del kernel, che si occupa degli interrupt provenienti dalla scheda di rete e segnala alla CPU l'arrivo di nuovi dati. La CPU sospende quindi l'attività in corso per gestire l'interrupt e, più avanti, questi dati saranno trattati da ENA come pacchetto di rete.
Se le vCPU di un'istanza sono sovraccariche o utilizzate in modo non uniforme, possono insorgere ritardi nell'elaborazione del traffico di rete, con packet drop sul lato Rx e completion timeout sul lato Tx: il risultato sono prestazioni scarse e una latenza con forti oscillazioni.
Per ottenere prestazioni di rete elevate e stabili è essenziale assicurarsi che le vCPU incaricate di gestire il traffico di rete (le code ENA) siano disponibili e dispongano di tempo di elaborazione sufficiente per questo compito.
La maggior parte dell'elaborazione di rete avviene nel routing NAPI, eseguito in contesto softirq. I core CPU coinvolti nell'elaborazione NAPI possono essere identificati con il seguente comando:
[root@aws rossetv]# egrep 'CPU|eth0' /proc/interrupts
CPU0 CPU1
28: 4531 1535 PCI-MSI 81921-edge eth0-Tx-Rx-0
29: 460 4311 PCI-MSI 81922-edge eth0-Tx-Rx-1
[root@aws rossetv]#
In alcuni casi può capitare di notare che i thread ksoftirqd consumano quasi il 100% di un core CPU. Questi thread gestiscono gli interrupt prima che il traffico raggiunga le code ENA.
Le possibili cause di CPU starvation nell'elaborazione di rete sono diverse: può semplicemente trattarsi di un sistema sovraccarico per via di altre attività CPU-intensive, individuabili con utility come htop o con perf per capire dove i core spendono la maggior parte del tempo.
A volte l'utilizzo elevato della CPU ha una natura sporadica e si manifesta con brevi picchi di utilizzo elevato della CPU. In questi casi è possibile aumentare la dimensione del ring Rx per compensare l'indisponibilità temporanea della CPU.
Per impostazione predefinita la dimensione del ring Rx di ENA è di 1K elementi, ma può essere portata dinamicamente fino a 16K elementi tramite ethtool. Per aumentare la dimensione del ring Rx su eth0 a 4096, ad esempio, può usare il comando seguente.
sudo ethtool -G eth0 rx 4096
Se i core CPU dedicati all'elaborazione di rete sono costantemente sovraccarichi e si avvicinano al 100% di utilizzo mentre quello complessivo della CPU non è altrettanto elevato, si tratta probabilmente di una distribuzione del carico non uniforme tra le vCPU disponibili.
Il problema si risolve riassegnando le altre attività in esecuzione sulle vCPU sovraccariche ad altre vCPU meno cariche e non coinvolte nell'elaborazione di rete, utilizzando le utility Linux taskset oppure numactl.
È anche possibile deviare gli interrupt di rete dalle vCPU già sature, impostando IRQBALANCE_BANNED_CPUS nel file /etc/sysconfig/irqbalance con la maschera CPU che indica quali CPU escludere, e poi riavviando il servizio irqbalance.
Con questo approccio si garantisce che i core CPU che gestiscono le code ENA non siano impegnati anche nella gestione degli IRQ di rete.
Se nella Sua istanza EC2 ci sono più core CPU rispetto al numero di code ENA, può anche abilitare il receive packet steering (RPS) per scaricare parte dell'elaborazione del traffico Rx su altre vCPU. È tuttavia consigliabile mantenere i core vCPU dell'RPS sullo stesso nodo NUMA delle vCPU che elaborano gli IRQ ENA. Inoltre, eviti di assegnare le vCPU RPS ai core gemelli (sibling) delle vCPU IRQ quando l'hyperthreading è abilitato.
Gli approcci appena descritti consentono un controllo molto preciso su quali core CPU si occupino dei diversi aspetti dell'elaborazione di rete su Linux, per spremere il massimo dalle prestazioni.
Receive Packet Steering (RPS)
Il receive packet steering (RPS) è un metodo per indirizzare i pacchetti di rete a CPU specifiche per l'elaborazione. Si può adottare per evitare che la coda hardware di una singola scheda di rete diventi un collo di bottiglia per il traffico di rete.
L'RPS si configura per ogni dispositivo di rete e per ciascuna coda di ricezione, in particolare nel file /sys/class/net/eth0/queues/rx-0/rps_cpus, dove eth0 è il dispositivo di rete e rx-0 indica la relativa coda di ricezione.
Per impostazione predefinita il file rps_cpus è impostato su 0, il che disabilita di fatto l'RPS: lo stesso core CPU che gestisce l'interrupt di rete elabora anche il pacchetto. Per attivare l'RPS, può configurare il file rps_cpus indicando le CPU che dovranno elaborare i pacchetti del dispositivo di rete e della coda di ricezione specificati.
La configurazione nei file rps_cpus si basa su bitmap di CPU separate da virgole. Per abilitare una CPU alla gestione degli interrupt di una coda di ricezione su un'interfaccia, occorre impostare a 1 i valori corrispondenti nella bitmap.
Può individuare quali CPU sono associate a quali nodi NUMA con il comando lscpu, come mostrato di seguito:
[root@aws rossetv]# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Riprendendo l'esempio precedente, abilitiamo l'RPS per i core da 48 a 63. Questo sistema ha 64 core e ogni carattere esadecimale nella bitmask rappresenta 4 bit: serviranno quindi 16 caratteri esadecimali per rappresentare 64 bit. Per abilitare gli ultimi 16 core (48–63) all'RPS, dobbiamo impostare a 1 gli ultimi 16 bit e a 0 tutti gli altri. La rappresentazione esadecimale di 1111 1111 1111 1111 (16 bit per i core 48-63) è FFFF.
Dato che lavoriamo con una rappresentazione a 64 bit e dobbiamo abilitare i 16 bit più alti, la bitmask sarà 0000,00000000,00000000,0000FFFF.
Per applicare questa impostazione su più code di ricezione, può utilizzare i comandi seguenti per ciclare sulle code Rx da rx-0 a rx-15 dell'interfaccia eth0, configurandole per usare solo i core da 48 a 63:
sudo bash -c 'for i in $(seq 0 15); do echo "0000,00000000,00000000,0000FFFF" > /sys/class/net/eth0/queues/rx-$i/rps_cpus; done'
Questa modifica però non sopravvive a un riavvio. Per renderla persistente, dopo i test possiamo creare un semplice script ed eseguirlo all'avvio con i comandi seguenti.
sudo su
echo 'for i in `seq 0 15`; do echo $(printf "0000,00000000,00000000,0000FFFF") | sudo tee /sys/class/net/eth0/queues/rx-$i/rps_cpus; done' > /sbin/rps_core
chmod +x /sbin/rps_core
echo "/sbin/rps_core" >> /etc/rc.local
chmod +x /etc/rc.local
Attenzione: se il servizio irqbalance è attivo, l'elaborazione degli IRQ può migrare verso vCPU diverse, riducendo l'efficacia dell'RPS. Disabilitare irqbalance non è consigliabile, ma può specificare quali core CPU escludere dall'elaborazione degli IRQ impostando la variabile IRQBALANCE_BANNED_CPUS in /etc/sysconfig/irqbalance.
La maschera CPU si calcola allo stesso modo descritto in precedenza: in questo caso specifico imposteremo IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF e riavvieremo irqlbalance con i comandi seguenti.
sudo su
echo "IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF" >> /etc/sysconfig/irqbalance
sudo systemctl restart irqbalance
Interrupt Moderation
Throughput di rete elevato e bassa latenza sono due obiettivi chiave negli ambienti cloud ad alte prestazioni. Dal punto di vista di un controller Ethernet, però, esiste un trade-off tra latenza e throughput.
Per ottenere una latenza più bassa, il controller riduce in genere al minimo l'intervallo tra gli interrupt, in modo da accelerare l'elaborazione dei pacchetti piccoli; il prezzo da pagare è un maggiore utilizzo della CPU e un throughput inferiore.
Per migliorare invece il throughput e contenere l'overhead causato da interrupt frequenti, sono preferibili intervalli di interrupt più ampi. Trovare l'intervallo di interrupt giusto è quindi fondamentale per il miglior bilanciamento delle prestazioni.
L'interrupt moderation è una funzionalità del driver supportata dai tipi di istanza basati su Nitro che utilizzano ENA: consente all'utente di gestire la frequenza degli interrupt verso la CPU durante la trasmissione e la ricezione dei pacchetti.
Senza alcuna interrupt moderation, il sistema genera un interrupt per ogni pacchetto trasmesso e ricevuto. Questo può ridurre al minimo la latenza per ogni singolo pacchetto, ma comporta un maggiore consumo di CPU per l'overhead di gestione degli interrupt e può ridurre sensibilmente il throughput.
Quando l'interrupt moderation è abilitata, ogni interrupt gestisce più pacchetti: l'efficienza complessiva nell'elaborazione degli interrupt aumenta e l'utilizzo della CPU diminuisce, in cambio di una latenza più alta, perché la CPU attende più pacchetti prima di gestirli.
Nelle istanze EC2 che usano il driver ENA, per Tx il ritardo statico degli interrupt è impostato per default su 64 µsec.
Per quanto riguarda la frequenza di moderation Rx, l'impostazione varia a seconda del tipo di istanza. In alcuni tipi la moderation Rx è disabilitata di default, in altri è invece abilitata in modalità adattiva.
Si può verificare con ethtool tramite il comando seguente.
[root@aws rossetv]# ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: n/a
stats-block-usecs: n/a
sample-interval: n/a
pkt-rate-low: n/a
pkt-rate-high: n/a
rx-usecs: 0
rx-frames: n/a
rx-usecs-irq: n/a
rx-frames-irq: n/atx-usecs: 64
tx-frames: n/a
tx-usecs-irq: n/a
tx-frames-irq: n/arx-usecs-low: n/a
rx-frame-low: n/a
tx-usecs-low: n/a
tx-frame-low: n/arx-usecs-high: n/a
rx-frame-high: n/a
tx-usecs-high: n/a
tx-frame-high: n/aCQE mode RX: n/a TX: n/a[root@aws rossetv]#
Nell'esempio sopra l'interrupt moderation per Rx è disabilitata.
In presenza di una frequenza di interrupt elevata è consigliabile attivare la moderation Rx adattiva, che regola dinamicamente la frequenza degli interrupt in base alla dimensione dei pacchetti e al throughput medio. Lo si può fare con il comando seguente.
sudo ethtool -C eth0 adaptive-rx on
Vincoli di memoria
Abbiamo affrontato in modo approfondito la CPU starvation nell'elaborazione di rete, ma anche la memoria può rappresentare un vincolo significativo: se i buffer si esauriscono, il sistema inizia a scartare pacchetti.
Si assicuri che la memoria del kernel riservata sia sufficiente a sostenere un'elevata frequenza di allocazioni di buffer per i pacchetti. La si imposta agendo sul parametro vm.min_free_kbytes in /etc/sysctl.conf.
Come regola generale, conviene impostare questo valore intorno al 3% della memoria di sistema disponibile. Si può fare con i comandi seguenti, indicando il valore in kbytes.
echo "vm.min_free_kbytes = 1048576" >> /etc/sysctl.conf
sudo sysctl -p
Per le applicazioni che fanno un uso intensivo di UDP è opportuno aumentare anche i buffer specifici per UDP: di default, infatti, Linux pone limiti molto stringenti sulle prestazioni del protocollo UDP, riducendo la quantità di traffico UDP che può essere bufferizzata sul socket di ricezione.
I comandi seguenti, ad esempio, impostano i buffer UDP a 128 MB (in kbytes).
sudo su
echo "net.core.rmem_max=134217728" >> /etc/sysctl.conf
echo "net.core.rmem_default=134217728" >> /etc/sysctl.conf
sysctl -p
Parliamone insieme!
In sintesi, raggiungere un throughput elevato con bassa latenza significa superare tre sfide chiave: AWS Throttling, CPU Starvation e Memory Starvation.
Affrontandole, può portare le prestazioni di rete al massimo throughput e alla minima latenza.
Nelle sezioni precedenti abbiamo analizzato diversi modi per gestire questi vincoli in scenari diversi. Le strategie illustrate si applicano in genere a molti contesti, ma ogni ambiente ha le proprie peculiarità.
Detto questo, perché non avviare un confronto? Contatti DoiT per fissare un incontro sull'ottimizzazione di rete e su altri argomenti con i nostri Cloud Architect.
stop
Should be word exceeded.
Reply
this is pure gold !!!
Reply