∘ Por qué conviene usar las versiones más recientes
∘ El recorrido simplificado de un paquete de red
∘ Receive Packet Steering (RPS)
∘ Moderación de interrupciones
Rendimiento de red mejorado
En el cómputo en la nube, el rendimiento de la red resulta clave para la escalabilidad y la eficiencia de las aplicaciones que exigen alto throughput y baja latencia. Las generaciones modernas de instancias EC2 incorporan Enhanced Networking con el Elastic Network Adapter (ENA) y el driver propietario de Amazon, lo que entrega mejoras de rendimiento significativas frente a las máquinas virtuales tradicionales. En este artículo se profundiza en técnicas avanzadas de networking y buenas prácticas para optimizar el rendimiento de red en instancias EC2 Linux y potenciar el desempeño de tus aplicaciones.
ENA y por qué importa
Las generaciones más antiguas de instancias EC2 se virtualizan con Xen y no soportan ENA. Las generaciones modernas, en cambio, se virtualizan con KVM y utilizan los drivers propietarios de AWS (ENA) para la red.
En Xen existe el concepto de dom0, que es el dominio de gestión por el que pasa cada solicitud de I/O y donde residen los servicios del host subyacente.
El I/O de red sale de las máquinas virtuales (domU) a través de los drivers netfront/netback, mientras que el I/O de disco utiliza los drivers blockfront/blockback.
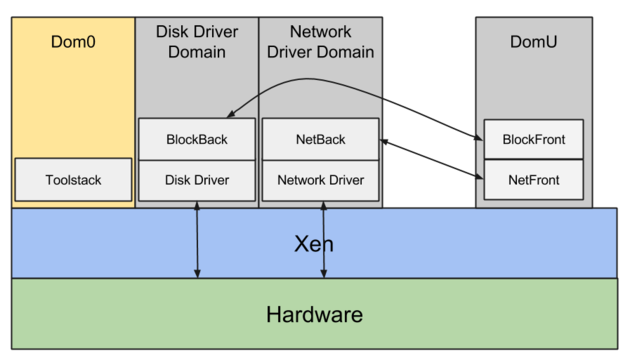
Por cada solicitud de I/O, la máquina virtual (domU) debe procesarla y enviarla a dom0 mediante estos drivers, los cuales luego usan los drivers reales para entregarla al hardware físico.
En resumen, por cada solicitud de I/O de la máquina virtual (domU) siempre hay un intermediario (dom0) entre la máquina virtual y el hardware real, lo que se traduce en un rendimiento pobre y, sobre todo, en un jitter significativo, dando como resultado un rendimiento de I/O muy impredecible.
Además, dom0 participa en las solicitudes de I/O de TODAS las máquinas virtuales que corren en ese host subyacente, las cuales pueden ser muchas, posiblemente cientos en el mismo host. Esto solo agrava la imprevisibilidad del rendimiento de I/O e introduce un problema serio de "vecinos ruidosos".
Con el driver de red propietario de Amazon (ENA), este problema se resuelve permitiendo que las máquinas virtuales se comuniquen directamente con el hardware, sin necesidad de un intermediario.
En las generaciones modernas de instancias EC2 construidas sobre Nitro ya no existe dom0: AWS abandonó Xen por completo y empezó a usar KVM como hipervisor.
Por qué conviene usar las versiones más recientes
Estas mejoras se han vuelto cada vez más significativas en las generaciones más nuevas de instancias EC2, lo que refuerza la importancia de elegir siempre la última generación de instancias EC2 cuando se requiere el máximo rendimiento.
Es igual de importante asegurarte de que tu sistema Linux use la versión más reciente del driver ENA, que incluye todas las nuevas optimizaciones de rendimiento y correcciones de errores.
El recorrido simplificado de un paquete de red
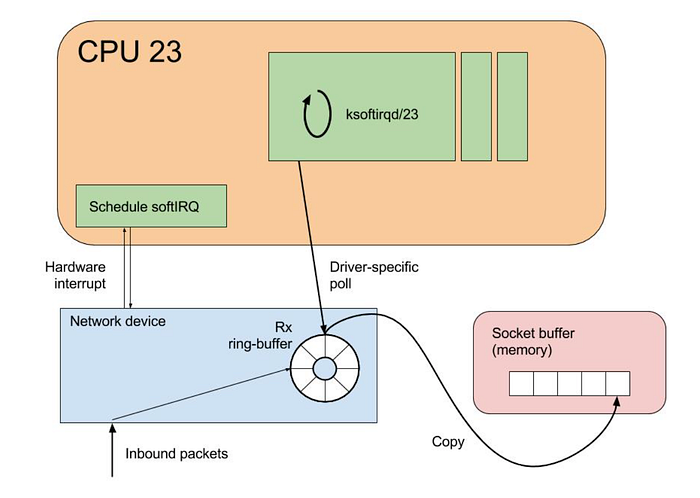
De forma muy simplificada, el recorrido de un paquete de red que llega desde internet a un sistema Linux comienza con su llegada a la tarjeta de red, que luego genera una interrupción para avisarle a la CPU que llegaron datos.
La CPU pausa lo que estaba haciendo y atiende la interrupción. Esto implica ejecutar una rutina de manejo de interrupción que procesa el paquete entrante.
A continuación, el stack de red del kernel toma el control y procesa el paquete. Esto incluye varias capas, como el manejo de IP, el manejo de TCP/UDP y otras. El kernel verifica la integridad del paquete, determina su destino dentro del sistema y se encarga del enrutamiento.
Si el paquete está destinado a una aplicación que corre en el sistema, se mueve a un buffer de socket. Estos son los puntos finales para enviar y recibir datos en un equipo y residen en la memoria RAM.
Para los fines de este artículo, nos enfocaremos en dos pasos distintos del recorrido de un paquete de red: el manejo de interrupciones, que señala la llegada de datos nuevos desde el hardware, y las colas de ENA, que se encargan de procesar los paquetes de red dentro del stack de Linux.
Para el manejo de interrupciones, Linux utiliza mecanismos como SoftIRQs y NAPI para procesar paquetes de red de forma eficiente.
En lugar de detener de inmediato lo que la CPU está haciendo cada vez que llega un paquete de red, mediante interrupciones por software (SoftIRQs) el sistema puede aplicar una ejecución diferida que permite al kernel postergar el procesamiento en favor de algo más urgente.
NAPI es una interfaz diseñada para mejorar el rendimiento de la red bajo carga alta. Cambia la forma en que se procesan los paquetes, pasando de un modelo basado en interrupciones a uno de polling cuando el tráfico de red alcanza cierto umbral, reduciendo así la sobrecarga que generan las interrupciones excesivas.
Colas de ENA
En términos sencillos, una cola de ENA funciona como un conjunto de cintas transportadoras que ayuda a gestionar el tráfico de internet, manejando los paquetes de red que entran y salen del sistema. Estas cintas transportadoras se organizan en dos tipos:
las colas de transmisión (Tx), donde el sistema coloca los datos que quiere enviar a internet; y las colas de recepción (Rx), donde se reciben los datos entrantes desde internet, que luego se colocan en un buffer para procesar la información recibida.
Cada una de estas colas tiene una sección de submission y una sección de completion. Inicialmente, los datos se colocan en la sección de submission, ya sea para enviarse (Tx) o para prepararse a recibir datos entrantes (Rx). La sección de completion confirma si los datos se enviaron o recibieron correctamente.
Con esta imagen de las colas de ENA, es fácil ver cómo pueden convertirse en un cuello de botella y afectar el rendimiento de la red. Las instancias EC2 pueden tener varias colas de ENA (hasta un máximo de 32 por ENI) según el tamaño del tipo de instancia. Este soporte multi-cola permite distribuir el tráfico de red entre varios núcleos de CPU, reduciendo cuellos de botella y mejorando la eficiencia general en el manejo de datos, con menores latencias y mayor throughput.
Con ethtool, podemos monitorear las métricas que provee el driver ENA de Amazon y entender mejor cómo el sistema está manejando la carga de tráfico en estas colas.
Una de las métricas relevantes disponibles es la cantidad de stops en estas colas. Esto significa que se enviaron paquetes a los anillos Tx más rápido de lo que podían procesarse, provocando un drop.
[root@aws rossetv]# ethtool -S eth0|grep stop
queue_0_tx_queue_stop: 0
queue_1_tx_queue_stop: 0
Cuando hay una cantidad significativa de stops en las colas de ENA, suele indicar throttling, ya sea por throttling de AWS, debido a haber excedido los límites de red de la instancia, o por inanición de recursos, cuando no hay suficiente capacidad de procesamiento o buffers disponibles para manejar los paquetes entrantes.
Para acotar mejor el problema, podemos verificar el throttling revisando las métricas de exceeded con el comando que aparece a continuación.
[root@aws rossetv]# ethtool -S eth0|grep stop
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Si alguno de estos contadores tiene un valor distinto de cero, te recomiendo revisar un artículo previo mío sobre Troubleshooting de throttling de red en AWS, que dejo enlazado aquí.
Cuando se confirma que no hubo throttling por parte de AWS, lo más probable es que tu sistema esté enfrentando inanición de recursos en la red.
Inanición de CPU
Profundizando un poco más sobre las colas de ENA, son ellas las que procesan los paquetes de red. Antes de ese punto también ocurre el manejo de IRQ por parte del kernel, que se encarga de las interrupciones provenientes de la tarjeta de red, indicándole a la CPU que llegaron datos nuevos. La CPU detiene su tarea actual para atender la interrupción y, más adelante, esos datos serán procesados por ENA como un paquete de red.
Si las vCPU de una instancia están sobrecargadas o se utilizan de forma desigual, se pueden producir retrasos en el procesamiento del tráfico de red, generando drops de paquetes en el lado Rx y completion timeouts en el lado Tx, lo que se traduce en bajo rendimiento y una latencia muy variable.
Para conseguir un rendimiento de red alto y estable, es esencial asegurar que las vCPU encargadas de manejar el tráfico de red (las colas de ENA) estén disponibles y reciban suficiente tiempo de procesamiento para esa tarea.
La mayor parte del procesamiento de red ocurre en el enrutamiento NAPI, que se ejecuta en contexto softirq. Los núcleos de CPU involucrados en el procesamiento NAPI se pueden identificar ejecutando el siguiente comando:
[root@aws rossetv]# egrep 'CPU|eth0' /proc/interrupts
CPU0 CPU1
28: 4531 1535 PCI-MSI 81921-edge eth0-Tx-Rx-0
29: 460 4311 PCI-MSI 81922-edge eth0-Tx-Rx-1
[root@aws rossetv]#
En algunos casos también podrías ver que los hilos ksoftirqd consumen casi el 100% del núcleo de CPU. Estos hilos se encargan de manejar dichas interrupciones antes de que el tráfico llegue a las colas de ENA.
Hay varias causas posibles de inanición de CPU en el procesamiento de red: puede que el sistema esté simplemente sobrecargado con otras tareas intensivas de CPU, algo que se detecta con utilidades como htop, o usando perf para determinar dónde pasan la mayor parte del tiempo los núcleos.
A veces, la alta utilización de CPU es de naturaleza puntual y se traduce en picos cortos de uso elevado. En esos casos, puedes aumentar el tamaño del anillo Rx para compensar la indisponibilidad temporal de la CPU.
Por defecto, el tamaño del anillo Rx de ENA es de 1K entradas, pero se puede aumentar dinámicamente hasta 16K entradas con ethtool. Para aumentar el tamaño del anillo Rx en eth0 a 4096, por ejemplo, puedes usar el siguiente comando.
sudo ethtool -G eth0 rx 4096
Si los núcleos de CPU responsables del procesamiento de red están sobrecargados de manera constante y rondan el 100% de utilización, mientras que el uso global de CPU no es tan alto, esto podría indicar una distribución desigual de la carga entre las vCPU disponibles.
Esto se soluciona reasignando otras tareas que corren en las vCPU sobrecargadas a vCPU menos cargadas que no participen en el procesamiento de red, usando las utilidades taskset o numactl de Linux.
También es posible desviar las interrupciones de red de las vCPU ya sobrecargadas, definiendo IRQBALANCE_BANNED_CPUS en /etc/sysconfig/irqbalance de tu sistema, con la máscara de CPU que indica los núcleos que quieres excluir, y reiniciando luego el servicio irqbalance.
Con este enfoque te aseguras de que los núcleos de CPU que manejan las colas de ENA no estén también ocupados gestionando las IRQ de red.
Si tu instancia EC2 tiene más núcleos de CPU que colas de ENA, también puedes habilitar receive packet steering (RPS) para descargar parte del procesamiento de tráfico Rx en otras vCPU. Sin embargo, se recomienda mantener los núcleos vCPU de RPS en el mismo nodo NUMA que las vCPU que procesan las IRQ de ENA. Asimismo, evita ubicar las vCPU de RPS en núcleos hermanos (sibling) de las vCPU de IRQ cuando hyperthreading esté habilitado.
Los enfoques anteriores te dan un control muy fino sobre qué núcleos de CPU manejan cada parte del procesamiento de red en Linux, para asegurar el máximo rendimiento absoluto.
Receive Packet Steering (RPS)
Receive packet steering (RPS) es un método para dirigir paquetes de red hacia CPU específicas para su procesamiento. Sirve para evitar que la cola de hardware de una sola tarjeta de red se convierta en un cuello de botella del tráfico.
RPS se configura para cada dispositivo de red y cada cola de recepción, específicamente en el archivo /sys/class/net/eth0/queues/rx-0/rps_cpus, donde eth0 es el dispositivo de red y rx-0 indica la cola de recepción correspondiente.
Por defecto, el archivo rps_cpus está en 0, lo que efectivamente desactiva RPS, es decir, el mismo núcleo de CPU que maneja la interrupción de red también procesa el paquete. Para habilitar RPS, configura el archivo rps_cpus correspondiente con las CPU que deben procesar los paquetes del dispositivo y la cola de recepción especificados.
La configuración en los archivos rps_cpus usa bitmaps de CPU separados por comas. Para habilitar a una CPU para gestionar interrupciones de una cola de recepción en una interfaz, debes establecer en 1 los valores correspondientes en el bitmap.
Puedes identificar qué CPU están asociadas a qué nodos NUMA con el comando lscpu, como se muestra a continuación:
[root@aws rossetv]# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Con el ejemplo anterior, habilitemos RPS para los núcleos 48 a 63. Este sistema tiene 64 núcleos y cada carácter hexadecimal de la máscara de bits representa 4 bits, así que se necesitan 16 caracteres hexadecimales para representar 64 bits. Para habilitar los últimos 16 núcleos (48–63) con RPS, los últimos 16 bits deben estar en 1 y el resto en 0. La representación hexadecimal de 1111 1111 1111 1111 (16 bits para los núcleos 48-63) es FFFF.
Como estamos trabajando con una representación de 64 bits y necesitamos habilitar los 16 bits más altos, la máscara queda como 0000,00000000,00000000,0000FFFF.
Para aplicar esta configuración a varias colas de recepción, puedes usar los siguientes comandos para iterar entre las colas Rx rx-0 a rx-15 en la interfaz eth0, configurándolas para usar solo los núcleos 48 a 63:
sudo bash -c 'for i in $(seq 0 15); do echo "0000,00000000,00000000,0000FFFF" > /sys/class/net/eth0/queues/rx-$i/rps_cpus; done'
Sin embargo, este cambio no persiste tras un reinicio. Para hacerlo persistente, después de probar podemos escribir un script simple y agregarlo para que se ejecute en el arranque, con los comandos que aparecen a continuación.
sudo su
echo 'for i in `seq 0 15`; do echo $(printf "0000,00000000,00000000,0000FFFF") | sudo tee /sys/class/net/eth0/queues/rx-$i/rps_cpus; done' > /sbin/rps_core
chmod +x /sbin/rps_core
echo "/sbin/rps_core" >> /etc/rc.local
chmod +x /etc/rc.local
Ten en cuenta que, si el servicio irqbalance está activo, el procesamiento de IRQ podría migrar a distintas vCPU, restándole efectividad a RPS. Aunque no se recomienda deshabilitar irqbalance, puedes especificar qué núcleos de CPU excluir del procesamiento de IRQ definiendo la variable IRQBALANCE_BANNED_CPUS en /etc/sysconfig/irqbalance.
La máscara de CPU se calcula igual que antes, así que en este ejemplo concreto definiríamos IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF y reiniciaríamos irqlbalance con los comandos que aparecen a continuación.
sudo su
echo "IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF" >> /etc/sysconfig/irqbalance
sudo systemctl restart irqbalance
Moderación de interrupciones
El alto throughput de red y la baja latencia son objetivos clave en entornos cloud de alto rendimiento. Sin embargo, desde la perspectiva del controlador Ethernet existe un trade-off entre latencia y throughput.
Para conseguir menor latencia, el controlador suele minimizar el intervalo entre interrupciones para acelerar el procesamiento de paquetes pequeños, a costa de un mayor uso de CPU y un menor throughput.
Por otro lado, para mejorar el throughput y reducir la sobrecarga que generan las interrupciones frecuentes, conviene tener intervalos de interrupción más amplios. Por eso, contar con un intervalo de interrupción adecuado resulta crítico para lograr el mejor balance de rendimiento.
La moderación de interrupciones es una característica del driver, soportada por los tipos de instancia con tecnología Nitro que usan ENA, que permite al usuario gestionar la tasa de interrupciones a la CPU durante la transmisión y recepción de paquetes.
Sin moderación de interrupciones, el sistema dispara una interrupción por cada paquete transmitido y recibido. Aunque esto puede minimizar la latencia de cada paquete, se gastan recursos extra de CPU en la sobrecarga de procesamiento de interrupciones, lo que puede reducir el throughput de manera significativa.
Cuando la moderación de interrupciones está habilitada, se manejan varios paquetes por cada interrupción, mejorando la eficiencia general del procesamiento y reduciendo la utilización de CPU, a cambio de una mayor latencia, ya que la CPU espera varios paquetes antes de procesarlos.
En las instancias EC2 que usan el driver ENA, para Tx el delay estático de interrupción está configurado en 64 µsec por defecto.
En cuanto a la tasa de moderación de Rx, la configuración puede variar según el tipo de instancia. En algunos tipos, la moderación de Rx está deshabilitada por defecto, mientras que en otros está habilitada en modo adaptativo.
Esto se puede verificar con ethtool mediante el comando que aparece a continuación.
[root@aws rossetv]# ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: n/a
stats-block-usecs: n/a
sample-interval: n/a
pkt-rate-low: n/a
pkt-rate-high: n/a
rx-usecs: 0
rx-frames: n/a
rx-usecs-irq: n/a
rx-frames-irq: n/atx-usecs: 64
tx-frames: n/a
tx-usecs-irq: n/a
tx-frames-irq: n/arx-usecs-low: n/a
rx-frame-low: n/a
tx-usecs-low: n/a
tx-frame-low: n/arx-usecs-high: n/a
rx-frame-high: n/a
tx-usecs-high: n/a
tx-frame-high: n/aCQE mode RX: n/a TX: n/a[root@aws rossetv]#
En el ejemplo anterior, la moderación de interrupciones para Rx está deshabilitada.
Si tienes una tasa de interrupciones alta, se recomienda habilitar la moderación adaptativa de Rx, que ajusta dinámicamente la tasa de interrupciones según el tamaño del paquete y el throughput promedio. Esto se logra con el comando que aparece a continuación.
sudo ethtool -C eth0 adaptive-rx on
Restricciones de memoria
Si bien profundizamos bastante en la inanición de CPU para el procesamiento de red, la memoria también puede ser una restricción importante: si los buffers se agotan, empezarán a producirse drops de paquetes.
Debes asegurarte de que la memoria de kernel reservada sea suficiente para sostener una alta tasa de asignaciones de buffers de paquetes. Esto se ajusta modificando el parámetro vm.min_free_kbytes en /etc/sysctl.conf.
Como regla general, conviene fijar este valor en alrededor del 3% de la memoria disponible del sistema. Esto se puede definir con los comandos siguientes, ajustando el valor en kbytes.
echo "vm.min_free_kbytes = 1048576" >> /etc/sysctl.conf
sudo sysctl -p
Para aplicaciones que hacen un uso intensivo de UDP, conviene también incrementar los buffers específicos de UDP, ya que por defecto Linux impone límites muy restrictivos al rendimiento del protocolo UDP, limitando el tamaño del tráfico UDP que se permite almacenar en el buffer del socket de recepción.
Los siguientes comandos configurarían los buffers de UDP en 128MB (en kbytes), por ejemplo.
sudo su
echo "net.core.rmem_max=134217728" >> /etc/sysctl.conf
echo "net.core.rmem_default=134217728" >> /etc/sysctl.conf
sysctl -p
¡Conversemos!
En resumen, alcanzar alto throughput con baja latencia implica superar tres desafíos clave: throttling de AWS, inanición de CPU e inanición de memoria.
Al abordar estos puntos, puedes mejorar el rendimiento de la red para lograr el máximo throughput y la mínima latencia.
En las secciones anteriores exploramos varias formas de atacar estas restricciones bajo distintas condiciones. Si bien las estrategias mencionadas suelen aplicar a muchos escenarios, cada entorno tiene sus particularidades.
Con esto en mente, ¿por qué no comenzamos una conversación? Contacta a DoiT para coordinar una charla sobre optimización de redes y otros temas con nuestros Cloud Architects.
stop
Should be word exceeded.
Reply
this is pure gold !!!
Reply