∘ Enhanced Networking Performance
∘ ENA verstehen – und warum es zählt
∘ Warum stets die neuesten Versionen entscheidend sind
∘ Das stark vereinfachte Leben eines Netzwerkpakets
∘ Receive Packet Steering (RPS)
Enhanced Networking Performance
Im Cloud Computing entscheidet die Netzwerk-Performance maßgeblich darüber, wie skalierbar und effizient Anwendungen laufen, die hohen Durchsatz und niedrige Latenz brauchen. Moderne EC2-Instanzgenerationen bringen Enhanced Networking mit dem Elastic Network Adapter (ENA) und dem proprietären ENA-Treiber von Amazon mit – ein deutlicher Performance-Sprung gegenüber klassischen virtuellen Maschinen. Dieser Artikel zeigt fortgeschrittene Netzwerktechniken und Best Practices, mit denen Sie die Netzwerk-Performance auf EC2-Linux-Instanzen optimieren und Ihre Anwendungen schneller machen.
ENA verstehen – und warum es zählt
Ältere EC2-Instanzgenerationen werden mit Xen virtualisiert und unterstützen kein ENA. Die modernen Generationen setzen dagegen auf KVM und nutzen die proprietären ENA-Treiber von AWS für das Networking.
Bei Xen gibt es das Konzept der dom0 – die Verwaltungsdomäne, durch die jede I/O-Anfrage läuft und in der die Dienste für den darunterliegenden Host angesiedelt sind.
Netzwerk-I/O verlässt die virtuellen Maschinen (domU) über die netfront/netback-Treiber, Disk-I/O nutzt blockfront/blockback.
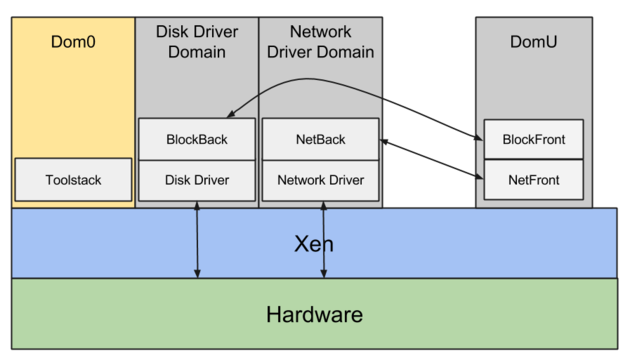
Bei jeder I/O-Anfrage muss die virtuelle Maschine (domU) diese verarbeiten und über diese Treiber an dom0 weitergeben. Diese reicht sie dann über die eigentlichen Treiber an die tatsächliche Hardware durch.
Kurz gesagt: Bei jeder I/O-Anfrage einer virtuellen Maschine (domU) sitzt immer ein Vermittler (dom0) zwischen virtueller Maschine und Hardware. Die Folge: schwache Performance und – noch entscheidender – starker Jitter und damit eine sehr unvorhersehbare I/O-Performance.
Hinzu kommt: dom0 ist an den I/O-Anfragen ALLER virtuellen Maschinen auf demselben Host beteiligt – und das können bis zu mehrere Hundert sein. Das verstärkt die Unvorhersehbarkeit der I/O-Performance zusätzlich und sorgt für ein ausgeprägtes Noisy-Neighbour-Problem.
Mit dem proprietären Netzwerktreiber von Amazon (ENA) ist dieses Problem gelöst: Die virtuellen Maschinen kommunizieren direkt mit der Hardware – ganz ohne Zwischeninstanz.
Auf den modernen, auf Nitro basierenden EC2-Instanzgenerationen existiert keine dom0 mehr; AWS hat sich vollständig von Xen verabschiedet und setzt KVM als Hypervisor ein.
Warum stets die neuesten Versionen entscheidend sind
Diese Verbesserungen sind in jeder neueren EC2-Instanzgeneration spürbar gewachsen – ein klares Argument dafür, für maximale Performance stets die aktuellste EC2-Instanzgeneration zu wählen.
Genauso wichtig: Ihr Linux-System sollte die neueste Version des ENA-Treibers nutzen, denn nur dort sind alle Performance-Optimierungen und Bugfixes enthalten.
Das stark vereinfachte Leben eines Netzwerkpakets
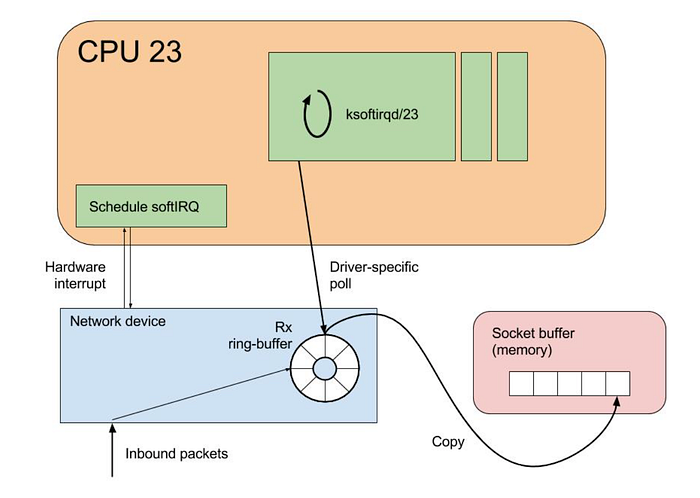
Stark vereinfacht beginnt das Leben eines Netzwerkpakets, das aus dem Internet auf ein Linux-System trifft, mit der Ankunft an der Netzwerkkarte. Diese erzeugt einen Interrupt und signalisiert der CPU damit, dass Daten eingetroffen sind.
Die CPU pausiert daraufhin ihre aktuelle Tätigkeit und behandelt den Interrupt. Dazu wird eine Interrupt-Handler-Routine ausgeführt, die das eingehende Paket verarbeitet.
Anschließend übernimmt der Netzwerk-Stack des Kernels und verarbeitet das Paket weiter. Dazu gehören verschiedene Schichten wie IP-Handling, TCP/UDP-Handling und mehr. Der Kernel prüft die Integrität des Pakets, ermittelt sein Ziel im System und übernimmt das Routing.
Ist das Paket für eine Anwendung im System bestimmt, wird es in einen Socket-Buffer verschoben. Das sind die Endpunkte zum Senden und Empfangen von Daten auf einem Computer, die im RAM liegen.
Für diesen Artikel konzentrieren wir uns auf zwei Schritte im Leben eines Netzwerkpakets: das Interrupt-Handling, das das Eintreffen neuer Daten von der Hardware signalisiert, und die ENA Queues, die die Verarbeitung der Netzwerkpakete innerhalb des Linux-Stacks übernehmen.
Für das Interrupt-Handling setzt Linux auf Mechanismen wie SoftIRQs und NAPI, um die Verarbeitung von Netzwerkpaketen effizient abzuwickeln.
Statt die CPU bei jedem eingehenden Netzwerkpaket sofort zu unterbrechen, ermöglichen Software-Interrupts (SoftIRQs) eine zurückgestellte Ausführung: Der Kernel kann die Verarbeitung zugunsten dringenderer Aufgaben aufschieben.
NAPI ist eine Schnittstelle, die die Netzwerk-Performance unter hoher Last verbessert. Erreicht der Netzwerkverkehr einen bestimmten Schwellenwert, wechselt sie die Paketverarbeitung von einem Interrupt-getriebenen Modell auf ein Polling-Modell und reduziert so den Overhead durch übermäßige Interrupts.
ENA Queues
Vereinfacht gesagt funktioniert eine ENA Queue wie eine Reihe von Förderbändern, die den Internetverkehr managen, indem sie Netzwerkpakete in das System hinein und aus ihm heraus befördern. Diese Förderbänder gibt es in zwei Varianten:
Transmit Queues (Tx), in die das System Daten ablegt, die ins Internet gesendet werden sollen, und Receive Queues (Rx), in denen eingehende Daten aus dem Internet empfangen und zur weiteren Verarbeitung in einen Buffer gelegt werden.
Jede dieser Queues hat einen Submission- und einen Completion-Bereich. Zunächst landen die Daten im Submission-Bereich – entweder zum Versenden (Tx) oder zur Vorbereitung des Empfangs eingehender Daten (Rx). Der Completion-Bereich bestätigt, ob die Daten erfolgreich gesendet oder empfangen wurden.
Mit diesem Bild der ENA Queues vor Augen wird schnell klar, wie schnell sie zum Flaschenhals werden und die Netzwerk-Performance ausbremsen können. EC2-Instanzen können je nach Größe des Instanztyps mehrere ENA Queues besitzen (maximal 32 pro ENI). Diese Multi-Queue-Unterstützung verteilt den Netzwerkverkehr auf mehrere CPU-Kerne, baut Engpässe ab und macht die gesamte Datenverarbeitung effizienter – mit niedrigeren Latenzen und höherem Durchsatz.
Mit ethtool lassen sich die vom ENA-Treiber von Amazon bereitgestellten Metriken auslesen und besser nachvollziehen, wie das System die Verkehrslast in diesen Queues bewältigt.
Eine wichtige Metrik ist die Anzahl der Stops in diesen Queues. Sie bedeutet, dass Pakete schneller in die Tx-Ringe eingestellt wurden, als sie verarbeitet werden konnten – mit der Folge, dass Pakete verworfen wurden.
[root@aws rossetv]# ethtool -S eth0|grep stop
queue_0_tx_queue_stop: 0
queue_1_tx_queue_stop: 0
Tritt in den ENA Queues eine signifikante Anzahl an Stops auf, deutet das typischerweise auf eine Drosselung hin – entweder durch AWS-Throttling wegen Überschreitung der Netzwerklimits der Instanz oder durch Resource Starvation, also nicht ausreichende Rechenleistung oder Buffer für die eingehenden Pakete.
Um das Problem weiter einzugrenzen, prüfen wir mit dem folgenden Befehl die exceeded-Metriken auf Throttling.
[root@aws rossetv]# ethtool -S eth0|grep stop
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Falls einer dieser Zähler einen Wert ungleich null aufweist, lohnt ein Blick in meinen früheren Artikel Troubleshooting AWS network throttling, den ich hier verlinke.
Steht fest, dass kein Throttling auf AWS-Seite stattgefunden hat, leidet Ihr System sehr wahrscheinlich unter Resource Starvation im Networking-Bereich.
CPU Starvation
Noch einmal zurück zu den ENA Queues: Sie verarbeiten die Netzwerkpakete. Davor übernimmt der Kernel das IRQ-Handling, das die Interrupts der Netzwerkkarte verarbeitet und der CPU signalisiert, dass neue Daten eingetroffen sind. Die CPU stoppt dann ihre aktuelle Aufgabe, um den Interrupt zu behandeln; weiter unten in der Verarbeitungskette werden diese Daten von ENA als Netzwerkpaket weiterverarbeitet.
Sind die vCPUs einer Instanz überlastet oder ungleichmäßig ausgelastet, kann das die Verarbeitung des Netzwerkverkehrs verzögern – mit Paketverlusten auf der Rx-Seite und Completion-Timeouts auf der Tx-Seite. Das Resultat: niedrige Performance und stark schwankende Latenzen.
Für eine hohe und stabile Netzwerk-Performance müssen die für den Netzwerkverkehr (die ENA Queues) zuständigen vCPUs verfügbar sein und ausreichend Rechenzeit für diese Aufgabe erhalten.
Der Großteil der Netzwerkverarbeitung läuft im NAPI-Routing im softirq-Kontext ab. Welche CPU-Kerne an der NAPI-Verarbeitung beteiligt sind, lässt sich mit folgendem Befehl ermitteln:
[root@aws rossetv]# egrep 'CPU|eth0' /proc/interrupts
CPU0 CPU1
28: 4531 1535 PCI-MSI 81921-edge eth0-Tx-Rx-0
29: 460 4311 PCI-MSI 81922-edge eth0-Tx-Rx-1
[root@aws rossetv]#
In manchen Fällen werden Sie sehen, dass die ksoftirqd-Threads nahezu 100 % eines CPU-Kerns auslasten. Diese Threads sind dafür zuständig, die Interrupts zu behandeln, bevor der Verkehr die ENA Queues erreicht.
Für CPU Starvation im Netzwerkbereich gibt es mehrere mögliche Ursachen: Vielleicht ist das System schlicht durch andere CPU-intensive Aufgaben überlastet – feststellbar mit Tools wie htop oder perf, um zu ermitteln, wo die Kerne den Großteil ihrer Zeit verbringen.
Manchmal verläuft die hohe CPU-Auslastung in kurzen Spitzen mit hoher CPU-Auslastung. In solchen Fällen können Sie die Größe des Rx-Rings erhöhen, um zeitweilige CPU-Knappheit zu kompensieren.
Standardmäßig hat der ENA Rx-Ring eine Größe von 1K Einträgen, lässt sich per ethtool aber dynamisch auf bis zu 16K Einträge erhöhen. Um die Rx-Ringgröße auf eth0 beispielsweise auf 4096 zu erhöhen, verwenden Sie folgenden Befehl:
sudo ethtool -G eth0 rx 4096
Sind die für die Netzwerkverarbeitung zuständigen CPU-Kerne dauerhaft überlastet und nähern sich 100 % Auslastung, während die Gesamt-CPU-Auslastung moderat bleibt, deutet das auf eine ungleichmäßige Lastverteilung über die verfügbaren vCPUs hin.
Beheben lässt sich das, indem andere Aufgaben auf den überlasteten vCPUs auf weniger ausgelastete vCPUs verlagert werden, die nicht an der Netzwerkverarbeitung beteiligt sind – etwa mit den Linux-Tools taskset oder numactl.
Außerdem lassen sich Netzwerk-Interrupts gezielt von bereits überlasteten vCPUs fernhalten: Setzen Sie dazu in /etc/sysconfig/irqbalance die Variable IRQBALANCE_BANNED_CPUS auf die CPU-Maske der auszuschließenden CPUs und starten Sie anschließend den Dienst irqbalance neu.
So stellen Sie sicher, dass die CPU-Kerne, die die ENA Queues bearbeiten, nicht zugleich mit Netzwerk-IRQs beschäftigt sind.
Hat Ihre EC2-Instanz mehr CPU-Kerne als ENA Queues, können Sie zusätzlich Receive Packet Steering (RPS) aktivieren, um einen Teil der Rx-Verkehrsverarbeitung auf andere vCPUs auszulagern. Empfehlenswert ist, die RPS-vCPU-Kerne auf demselben NUMA-Knoten zu halten wie die vCPUs, die die ENA-IRQs verarbeiten. Vermeiden Sie außerdem, RPS-vCPUs auf Sibling-Cores der IRQ-vCPUs zu legen, wenn Hyperthreading aktiviert ist.
Mit den oben beschriebenen Ansätzen erhalten Sie sehr feinkörnige Kontrolle darüber, welche CPU-Kerne unter Linux welche Aspekte der Netzwerkverarbeitung übernehmen – für absolut maximale Performance.
Receive Packet Steering (RPS)
Receive Packet Steering (RPS) ist eine Methode, um Netzwerkpakete bestimmten CPUs zur Verarbeitung zuzuweisen. Damit lässt sich verhindern, dass die Hardware-Queue einer einzelnen Netzwerkkarte zum Flaschenhals im Netzwerkverkehr wird.
RPS wird pro Netzwerkgerät und Receive Queue konfiguriert, konkret in der Datei /sys/class/net/eth0/queues/rx-0/rps_cpus, wobei eth0 das Netzwerkgerät und rx-0 die jeweilige Receive Queue bezeichnet.
Standardmäßig ist die Datei rps_cpus auf 0 gesetzt, was RPS effektiv deaktiviert – derselbe CPU-Kern, der den Netzwerk-Interrupt behandelt, verarbeitet dann auch das Paket. Um RPS zu aktivieren, konfigurieren Sie die entsprechende rps_cpus-Datei mit den CPUs, die die Pakete des angegebenen Netzwerkgeräts und der jeweiligen Receive Queue verarbeiten sollen.
Die Konfiguration in den rps_cpus-Dateien verwendet kommagetrennte CPU-Bitmaps. Damit eine CPU Interrupts für eine Receive Queue auf einer Schnittstelle übernehmen darf, müssen die entsprechenden Werte in der Bitmap auf 1 stehen.
Welche CPUs zu welchen NUMA-Knoten gehören, ermitteln Sie mit dem Befehl lscpu, wie unten gezeigt:
[root@aws rossetv]# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Im obigen Beispiel aktivieren wir RPS für die Kerne 48 bis 63. Das System hat 64 Kerne, und jedes Hexadezimalzeichen in der Bitmaske repräsentiert 4 Bit – für 64 Bit benötigen wir also 16 Hexadezimalzeichen. Um die letzten 16 Kerne (48–63) für RPS zu aktivieren, müssen die letzten 16 Bit auf 1 und alle anderen auf 0 stehen. Die Hexadezimaldarstellung von 1111 1111 1111 1111 (16 Bit für die Kerne 48-63) ist FFFF.
Da wir mit einer 64-Bit-Darstellung arbeiten und die obersten 16 Bit aktivieren wollen, lautet die Bitmaske 0000,00000000,00000000,0000FFFF.
Um diese Einstellung über mehrere Receive Queues anzuwenden, können Sie mit folgenden Befehlen über die Rx Queues rx-0 bis rx-15 auf der Schnittstelle eth0 iterieren und sie so konfigurieren, dass sie ausschließlich die Kerne 48 bis 63 nutzen:
sudo bash -c 'for i in $(seq 0 15); do echo "0000,00000000,00000000,0000FFFF" > /sys/class/net/eth0/queues/rx-$i/rps_cpus; done'
Diese Änderung überlebt allerdings keinen Reboot. Damit sie persistent bleibt, schreiben wir nach dem Test ein einfaches Skript und führen es per folgender Befehle beim Booten aus.
sudo su
echo 'for i in `seq 0 15`; do echo $(printf "0000,00000000,00000000,0000FFFF") | sudo tee /sys/class/net/eth0/queues/rx-$i/rps_cpus; done' > /sbin/rps_core
chmod +x /sbin/rps_core
echo "/sbin/rps_core" >> /etc/rc.local
chmod +x /etc/rc.local
Bitte beachten Sie: Ist der Dienst irqbalance aktiv, kann die IRQ-Verarbeitung auf andere vCPUs migrieren und die Wirksamkeit von RPS beeinträchtigen. Es ist nicht ratsam, irqbalance zu deaktivieren; Sie können jedoch festlegen, welche CPU-Kerne von der IRQ-Verarbeitung ausgeschlossen werden, indem Sie in /etc/sysconfig/irqbalance die Variable IRQBALANCE_BANNED_CPUS setzen.
Die CPU-Maske wird auf dieselbe Weise berechnet wie oben; in diesem konkreten Beispiel würden wir IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF setzen und irqlbalance mit den folgenden Befehlen neu starten.
sudo su
echo "IRQBALANCE_BANNED_CPUS=0000,00000000,00000000,FFFF" >> /etc/sysconfig/irqbalance
sudo systemctl restart irqbalance
Interrupt Moderation
Hoher Netzwerkdurchsatz und niedrige Latenz sind zentrale Ziele in performancekritischen Cloud-Umgebungen. Aus Sicht eines Ethernet-Controllers besteht zwischen Latenz und Durchsatz allerdings ein Trade-off.
Für niedrigere Latenzen verkürzt der Controller in der Regel das Intervall zwischen Interrupts und beschleunigt so die Verarbeitung kleiner Pakete – um den Preis höherer CPU-Auslastung und niedrigeren Durchsatzes.
Für höheren Durchsatz und weniger Overhead durch häufige Interrupts sind dagegen größere Interrupt-Intervalle wünschenswert. Ein passendes Interrupt-Intervall ist daher entscheidend für die optimale Performance-Balance.
Interrupt Moderation ist ein Treiberfeature, das die Nitro-basierten Instanztypen mit ENA unterstützen. Damit lässt sich die Rate der Interrupts an die CPU bei Paketversand und -empfang steuern.
Ohne Interrupt Moderation löst das System für jedes gesendete und empfangene Paket einen Interrupt aus. Das minimiert zwar die Latenz pro Paket, kostet aber zusätzliche CPU-Ressourcen für den Interrupt-Overhead und kann den Durchsatz erheblich reduzieren.
Ist Interrupt Moderation aktiviert, werden mehrere Pakete pro Interrupt verarbeitet. Die Effizienz der Interrupt-Verarbeitung steigt, die CPU-Auslastung sinkt – im Gegenzug erhöht sich die Latenz, da die CPU vor der Verarbeitung auf mehrere Pakete wartet.
Bei EC2-Instanzen mit dem ENA-Treiber ist die statische Interrupt-Verzögerung für Tx standardmäßig auf 64 µsec gesetzt.
Bei der Rx-Moderationsrate kann die Einstellung je nach Instanztyp variieren. Bei manchen Instanztypen ist die Rx-Moderation standardmäßig deaktiviert, bei anderen im adaptiven Modus aktiviert.
Prüfen lässt sich das mit ethtool über folgenden Befehl.
[root@aws rossetv]# ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: n/a
stats-block-usecs: n/a
sample-interval: n/a
pkt-rate-low: n/a
pkt-rate-high: n/a
rx-usecs: 0
rx-frames: n/a
rx-usecs-irq: n/a
rx-frames-irq: n/atx-usecs: 64
tx-frames: n/a
tx-usecs-irq: n/a
tx-frames-irq: n/arx-usecs-low: n/a
rx-frame-low: n/a
tx-usecs-low: n/a
tx-frame-low: n/arx-usecs-high: n/a
rx-frame-high: n/a
tx-usecs-high: n/a
tx-frame-high: n/aCQE mode RX: n/a TX: n/a[root@aws rossetv]#
Im obigen Beispiel ist die Interrupt Moderation für Rx deaktiviert.
Bei einer hohen Interrupt-Rate empfiehlt es sich, die adaptive Rx-Moderation zu aktivieren. Sie passt die Interrupt-Rate dynamisch an Paketgröße und durchschnittlichen Durchsatz an. Das funktioniert mit folgendem Befehl.
sudo ethtool -C eth0 adaptive-rx on
Speicher-Engpässe
CPU Starvation in der Netzwerkverarbeitung haben wir ausführlich behandelt – aber auch Speicher kann zum Engpass werden: Sind die Buffer erschöpft, beginnt das System, Pakete zu verwerfen.
Stellen Sie sicher, dass der reservierte Kernel-Speicher ausreicht, um eine hohe Rate an Paket-Buffer-Allokationen zu tragen. Einstellen lässt sich das über den Parameter vm.min_free_kbytes in /etc/sysctl.conf.
Als Faustregel gilt: Setzen Sie diesen Wert auf etwa 3 % des verfügbaren Systemspeichers. Das geht mit folgenden Befehlen, der Wert wird in kbytes angegeben.
echo "vm.min_free_kbytes = 1048576" >> /etc/sysctl.conf
sudo sysctl -p
Für Anwendungen, die stark UDP nutzen, sollten zusätzlich die UDP-spezifischen Buffer erhöht werden, denn Linux begrenzt die Performance des UDP-Protokolls standardmäßig sehr restriktiv – konkret durch eine Begrenzung der UDP-Verkehrsmenge, die im Receive-Socket gepuffert werden darf.
Folgende Befehle setzen die UDP-Buffer beispielsweise auf 128 MB (in kbytes).
sudo su
echo "net.core.rmem_max=134217728" >> /etc/sysctl.conf
echo "net.core.rmem_default=134217728" >> /etc/sysctl.conf
sysctl -p
Sprechen wir miteinander!
Zusammengefasst: Hoher Durchsatz bei niedriger Latenz erfordert das Bewältigen dreier zentraler Herausforderungen: AWS Throttling, CPU Starvation und Memory Starvation.
Wenn Sie diese Punkte adressieren, holen Sie aus Ihrer Netzwerk-Performance maximalen Durchsatz bei minimaler Latenz heraus.
In den vorigen Abschnitten haben wir verschiedene Wege beleuchtet, diese Einschränkungen unter unterschiedlichen Bedingungen anzugehen. Auch wenn die genannten Strategien grundsätzlich auf viele Umgebungen anwendbar sind, hat jede Umgebung ihre Eigenheiten.
Warum also nicht einfach miteinander sprechen? Kontaktieren Sie DoiT und tauschen Sie sich mit unseren Cloud Architects über Netzwerkoptimierung und weitere Themen aus.
stop
Should be word exceeded.
Antworten
this is pure gold !!!
Antworten