Dans le paysage en pleine évolution de 2026, choisir entre Amazon SageMaker et AWS Bedrock n'est plus une décision simple. Avec le lancement de SageMaker Unified Studio et l'expansion de l'IA agentique de Bedrock, ces deux services sont devenus les piliers d'une stratégie IA moderne.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Le meilleur des deux mondes
Au début des années 2020, les services IA d'AWS étaient nettement cloisonnés. SageMaker faisait office de laboratoire pour les data scientists qui construisaient tout de zéro, tandis que Bedrock jouait le rôle de studio plug-and-play destiné aux développeurs souhaitant exploiter des plateformes d'IA entièrement managées.
En 2026, ces frontières se sont estompées. SageMaker propose désormais des workflows serverless guidés par agents qui rivalisent avec la simplicité de Bedrock, tandis que Bedrock a introduit le Reinforcement Fine-Tuning (RFT) spécialisé et le Provisioned Throughput, offrant un niveau de contrôle autrefois réservé à SageMaker.
Aujourd'hui, le choix repose moins sur les compétences en programmation que sur le cycle de vie produit, le retour sur investissement (ROI) et la souveraineté des données.
1 : Logique de conception
Pour choisir le bon outil, il faut d'abord comprendre le modèle de responsabilité partagée de chaque service.
AWS Bedrock : l'intelligence en tant que service (MaaS)
Bedrock repose sur la philosophie du Model-as-a-Service (MaaS). C'est un modèle prêt à l'emploi. Il prend en charge le travail de fond — gestion des serveurs, pilotes matériels spécialisés — pour que vous n'ayez plus qu'à vous occuper de votre code.
- Le modèle de consommation : vous interagissez avec les modèles via une API standardisée. Que vous appeliez Claude 4 d'Anthropic, Llama 3.5 de Meta ou Nova 2 d'Amazon, la tuyauterie reste identique.
- Scalabilité serverless : Bedrock gère le problème du cold start. Vous ne vous occupez pas de la mise à l'échelle des instances ; AWS s'assure que la puissance de calcul est prête à traiter votre requête, qu'il s'agisse d'une seule ou d'un million.
Amazon SageMaker : l'établi (IaaS/PaaS)
SageMaker fournit un environnement d'infrastructure managée. S'il propose des abstractions de haut niveau, il vous donne en définitive accès à l'ensemble du cycle de vie du machine learning.
- Le modèle d'infrastructure : vous sélectionnez des instances EC2 spécifiques pour l'entraînement et l'inférence, et vous maîtrisez le type d'instances ainsi que l'environnement d'exécution.
- Propriété des poids : dans SageMaker, lorsque vous fine-tunez ou entraînez un modèle, vous êtes propriétaire des artefacts produits (les fichiers .tar.gz dans S3). Vous pouvez les migrer vers un autre service, voire on-premises.
2 : Plongée dans AWS Bedrock (nouvelles fonctionnalités)
En 2026, Bedrock n'est plus un simple wrapper autour des LLM. Le service est devenu une véritable couche d'orchestration pour la GenAI.
2.1 L'évolution agentique : Bedrock AgentCore
La fonctionnalité phare s'appelle Bedrock AgentCore. Elle permet aux développeurs de créer des agents autonomes qui ne se contentent pas de parler : ils agissent.
- Mémoire épisodique : les agents se souviennent désormais des interactions passées d'une session à l'autre, sans que le développeur ait à gérer manuellement un état DynamoDB.
- Streaming bidirectionnel : les agents peuvent désormais mener des conversations vocales naturelles, avec des interruptions humaines et un raisonnement en temps réel. Prenons un exemple : un client appelle une compagnie aérienne pour modifier un vol. Plutôt que de laisser l'IA dérouler un long script juridique, le client peut intervenir : Attendez, c'est trop cher — et le vol du matin ? L'IA s'interrompt en pleine phrase, prend en compte la remarque et se met immédiatement à chercher des options moins onéreuses, sans perdre le fil.
- Contrôles de politique : en langage naturel (que Bedrock convertit en règle), vous pouvez fixer des garde-fous stricts. Par exemple : Ne JAMAIS proposer une remise supérieure à 15 % sans l'approbation d'un superviseur.
2.2 Knowledge Bases et RAG natif
Bedrock a automatisé le pipeline de Retrieval-Augmented Generation (RAG).
- Chunking automatique : les documents sont découpés automatiquement en segments sémantiques optimaux.
- Service vectoriel managé : il gère la génération d'embeddings via des modèles comme Titan Embeddings V2 et les stocke dans un cluster OpenSearch serverless, une base vectorielle S3, Aurora PostgreSQL Serverless ou Neptune Analytics (Graph RAG).
2.3 Reinforcement Fine-Tuning (RFT)
Le RFT permet d'améliorer les modèles à partir de feedback, plutôt qu'à coup de jeux de données labellisés massifs. En pointant Bedrock vers les logs d'invocation de votre application, le service identifie les réponses utiles et s'auto-optimise dans la durée.
3 : Plongée dans Amazon SageMaker (nouvelles fonctionnalités)
SageMaker reste un environnement puissant pour le ML sur mesure, mais il est devenu nettement plus accessible.
3.1 SageMaker HyperPod : pour une meilleure résilience
Pour les organisations qui entraînent des modèles à mille milliards de paramètres, SageMaker HyperPod fait figure de référence.
- Clusters auto-réparateurs : l'entraînement de modèles massifs échoue souvent à cause d'une seule erreur matérielle sur un GPU. HyperPod détecte automatiquement le nœud défaillant, le remplace et reprend l'entraînement au dernier checkpoint en quelques minutes, évitant ainsi des millions de dollars de calcul gaspillé.
3.2 Personnalisation de modèles en serverless
SageMaker s'est inspiré de Bedrock. Vous pouvez désormais réaliser du Supervised Fine-Tuning (SFT) et de la Direct Preference Optimization (DPO) via une interface en langage naturel guidée par agent. C'est une technique très répandue pour aligner les grands modèles de langage (LLM) sur les préférences humaines dans Amazon SageMaker.
3.3 La révolution de l'inférence : Inference Components
SageMaker a réglé le problème du gaspillage de GPU. Avec les Inference Components, vous pouvez héberger des dizaines de modèles différents sur une seule grande instance GPU. À la clé : une consolidation des coûts massive, hors de portée du modèle par token de Bedrock pour les utilisateurs à fort volume.
4 : L'économie à l'échelle (les calculs)
C'est la section la plus critique pour les décideurs. Le service le moins cher dépend entièrement de votre volume et de votre débit.
4.1 Tarification Bedrock : le coût variable
Bedrock applique principalement une tarification basée sur les tokens.
Coût_{Bedrock} = (Tokens_{Entrée} \times Tarif_{In}) + (Tokens_{Sortie} \times Tarif_{Out})
Bedrock a introduit le Prompt Caching, qui change considérablement la donne pour les systèmes RAG. Si vous envoyez le même manuel d'entreprise de 5 000 mots à chaque requête :
- Lecture initiale : tarif plein.
- Lecture en cache : jusqu'à 90 % de réduction.
4.2 Tarification SageMaker : le coût fixe
SageMaker repose sur une tarification à l'instance.
Coût_{SageMaker} = Heures_{Instance} \times Tarif_{Horaire}
4.3 Le point d'équilibre
En règle générale, le point d'équilibre se situe autour de 220 millions de tokens par jour.
- En dessous de 220 M de tokens : Bedrock est presque toujours plus économique, puisque vous ne payez que ce que vous consommez. Si votre application est calme la nuit, vous payez 0 $.
- Au-dessus de 220 M de tokens : SageMaker devient plus attractif. Dès que votre volume est suffisamment élevé (sollicité 80 à 90 % du temps) pour héberger un modèle distillé et quantifié sur SageMaker avec des puces AWS Inferentia3, le tarif forfaitaire du serveur revient moins cher que le coût agrégé par token via une API.
Astuce ROI : avec un trafic élevé et stable, les Savings Plans de SageMaker (engagements d'un an ou de trois ans) peuvent réduire vos coûts jusqu'à 64 %. De son côté, le Provisioned Throughput d'Amazon Bedrock offre des économies significatives pour les workloads d'IA générative à fort volume et constants : vous réservez de la capacité dédiée plutôt que de payer au token à la demande. En vous engageant sur 1 ou 6 mois, vous obtenez généralement entre 30 % et 50 % de réduction par rapport à la tarification on-demand.
5 : Sécurité, souveraineté et conformité
5.1 Isolation VPC
- Bedrock : connexion via des VPC Endpoints (PrivateLink). Vos données ne transitent jamais par l'internet public ; les poids du modèle résident dans la zone de service managée par AWS.
- SageMaker : offre une isolation VPC totale. Vous pouvez déployer des modèles dans un sous-réseau sans aucun accès internet. C'est le choix privilégié des secteurs hautement régulés (défense, santé).
5.2 Propriété et souveraineté des poids
Si votre modèle économique repose sur un modèle d'IA précis, Bedrock présente un risque : vous dépendez du fournisseur (Anthropic, par exemple) pour le maintien de sa disponibilité. Avec SageMaker, vous êtes propriétaire du snapshot du modèle. Si un fournisseur retire une version, votre endpoint SageMaker continue de fonctionner. C'est la souveraineté du modèle.
6 : Exemples sectoriels
Exemple 1 : l'agent Smart Compliance en fintech (choisir Bedrock)
Le problème : une banque a besoin d'un outil qui audite chaque e-mail sortant pour vérifier la conformité réglementaire en temps réel.
- Pourquoi Bedrock ? Le trafic fonctionne par à-coups (élevé à 9 h, nul à 2 h du matin).
- L'architecture : les Guardrails de Bedrock détectent automatiquement les informations personnelles (PII) et les propos toxiques. Les Knowledge Bases de Bedrock hébergent la réglementation bancaire la plus récente.
- L'atout AgentCore : grâce à AgentCore, l'agent peut apprendre des responsables conformité senior de la banque via le Reinforcement Fine-Tuning (RFT). À défaut, un system prompt bien configuré suffit pour qu'un agent accomplisse la tâche demandée.
Exemple 2 : la suite de vision radiologique (choisir SageMaker)
Le problème : un groupe hospitalier doit traiter des millions d'IRM pour repérer d'éventuelles anomalies, avec une architecture de réseau de neurones sur mesure.
- Pourquoi SageMaker ? Il s'agit d'une tâche de vision par ordinateur non générative et de haute précision.
- L'architecture : utilisez SageMaker Ground Truth pour le labelling de données de qualité médicale. Entraînez le modèle sur SageMaker HyperPod pour garantir zéro interruption pendant le cycle d'entraînement de 3 semaines.
- Le déploiement sur des puces Inferentia3 assure une latence inférieure à 100 ms, indispensable pour l'assistance chirurgicale en temps réel.
Exemple 3 : le Smart-Router pour centre de support (l'optimiseur de coûts)
Le problème : une startup fintech traite 1 million de demandes clients par mois. 20 % sont des questions complexes de planification financière, et 80 % de simples requêtes du type Où est mon remboursement ? ou Réinitialisez mon mot de passe.
La solution hybride :
- Phase 1 (Bedrock) : utilisez Amazon Nova 2 Lite comme routeur. Il identifie l'intention de chaque message entrant instantanément et à moindre coût.
- Phase 2 (SageMaker) : pendant que votre conseiller échange avec un client, celui-ci demande : Puis-je augmenter mon plafond de crédit dès maintenant ? Pour répondre, le système doit analyser 5 000 points de données en quelques millisecondes : historique des transactions, probabilités de retard de paiement, volatilité du marché en temps réel.
- Incompatibilité de modèle : Bedrock est pensé pour l'IA générative (LLM). Il ne peut héberger ni exécuter XGBoost, Random Forest ou LightGBM, les modèles standards du marché pour les données tabulaires et les décisions binaires (oui/non).
- Latence : injecter des milliers de lignes de données brutes dans un prompt pour qu'un LLM les analyse est lent et coûteux.
- Structure des données : les LLM raisonnent dans le flou. Pour une décision de crédit, il faut la précision mathématique d'un modèle entraîné spécifiquement sur les données propriétaires de votre entreprise.
La solution SageMaker :
Hébergez un modèle Gradient Boosting spécialisé sur un endpoint SageMaker Inferentia3.
- Bedrock gère la conversation (Je m'en occupe avec plaisir !).
- SageMaker exécute les calculs lourds en arrière-plan et analyse les données tabulaires en moins de 10 ms.
- SageMaker renvoie le résultat Approuvé à Bedrock, qui se charge d'annoncer la nouvelle.
Pourquoi ? Vous évitez de payer des tarifs d'expert (Bedrock) pour répondre à des questions de niveau CP. Le matériel dédié de SageMaker absorbe les gros volumes pour quelques centimes, tandis que Bedrock se réserve à la logique à forte valeur et à la communication claire.
7 : Le cadre de décision : voici un aperçu d'un cadre de décision simple :
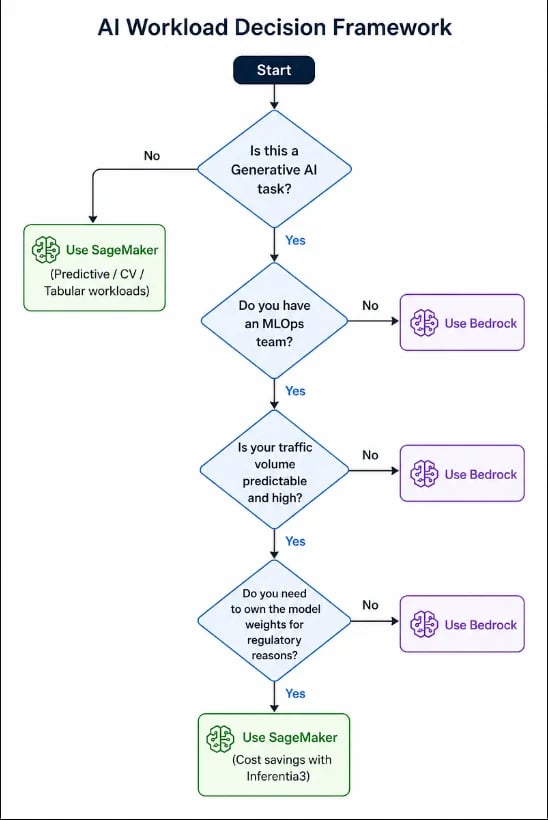
En 2026, le débat SageMaker vs Bedrock a glissé vers SageMaker Unified Studio, où vous pouvez utiliser les deux côte à côte dans un même projet.
Avec le lancement de SageMaker Unified Studio (déployé progressivement à partir de fin 2025), AWS a définitivement clos l'ère des deux onglets. Fini le va-et-vient entre la console SageMaker et la console Bedrock : elles sont désormais réunies dans un seul environnement de développement.
Pourquoi c'est un game changer
- Un espace de travail partagé : vous pouvez créer un unique projet dans Unified Studio regroupant à la fois vos notebooks d'entraînement SageMaker et vos configurations d'agents Bedrock.
- Liquidité des données : Studio s'appuie sur un catalogue de données unifié. Vous pouvez utiliser AWS Glue pour préparer les données, vous en servir pour fine-tuner un modèle dans SageMaker, puis intégrer immédiatement ce modèle dans un Bedrock Flow — sans jamais déplacer les données entre services.
- Accès Bedrock en un clic: dans Unified Studio, une interface web dédiée aux outils Bedrock (Agents, Guardrails et Knowledge Bases) cohabite directement avec vos expérimentations SageMaker.
La stratégie gagnante pour la prochaine décennie n'est pas de choisir un service unique, mais de bâtir une stack IA modulaire : Bedrock pour le cerveau de votre application, SageMaker pour ses compétences spécialisées et son efficacité économique.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
À retenir
La règle des 10 000 $
Démarrez avec Bedrock pour accélérer la mise sur le marché. Dès que votre dépense mensuelle en inférence atteint 10 000 $, la taxe de confort commence à dépasser le coût d'ingénierie. C'est le signal pour migrer vos workloads à fort volume vers SageMaker et capter les économies massives du matériel dédié.
Voici pourquoi cela fonctionne, et où se nichent les nuances :
- Le coût de gestion de l'infrastructure : Bedrock facture une prime à la simplicité. À 10 000 $ de facture, vous payez sans doute une somme conséquente pour la scalabilité serverless.
- Le point de bascule SageMaker : à 10 000 $/mois, le budget couvre le coût d'un SageMaker HyperPod dédié ou d'instances Inferentia3 tournant 24/7. À ce volume, le tarif forfaitaire du serveur revient moins cher que le coût par token de Bedrock.
- Justification d'équipe : une dépense mensuelle de 10 000 $ est généralement le seuil à partir duquel une entreprise peut justifier le salaire d'un ingénieur MLOps dont l'unique mission est d'optimiser l'usage des ressources SageMaker.
Les nuances (quand cela ne s'applique pas)
- Trafic en pics : si vos 10 000 $ proviennent de pics massifs suivis d'heures de silence, Bedrock peut rester plus économique. Les instances dédiées SageMaker coûtent de l'argent même lorsqu'elles ne traitent pas un seul token.
- Besoin de vitesse : si votre équipe est réduite, le gros œuvre que représente le passage à SageMaker risque de vous ralentir.