En el vertiginoso panorama de 2026, elegir entre Amazon SageMaker y AWS Bedrock ya no es una decisión tan simple. Con el lanzamiento de SageMaker Unified Studio y la expansión de la IA Agéntica de Bedrock, ambos servicios se volvieron la base de cualquier estrategia moderna de IA.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Lo mejor de ambos mundos
A principios de los 2020, los servicios de IA de AWS estaban bien delimitados. SageMaker era el "laboratorio" donde los científicos de datos construían desde cero, mientras que Bedrock era el "estudio Plug-and-Play" para que los desarrolladores aprovecharan plataformas de IA totalmente gestionadas.
Para 2026, esas fronteras se difuminaron. SageMaker hoy ofrece flujos serverless guiados por agentes que rivalizan con la simplicidad de Bedrock, mientras que Bedrock incorporó Reinforcement Fine-Tuning (RFT) especializado y Provisioned Throughput, con niveles de control antes reservados para SageMaker.
Hoy, la decisión depende menos de tus habilidades de programación y más del ciclo de vida del producto, el retorno de inversión (ROI) y la soberanía de los datos.
1: Lógica de diseño
Para elegir la herramienta correcta, primero hay que entender el "modelo de responsabilidad compartida" de cada servicio.
AWS Bedrock: inteligencia como servicio (MaaS)
Bedrock parte de la filosofía Model-as-a-Service (MaaS). Es un modelo listo para usar. Se encarga del trabajo pesado, como administrar servidores y drivers de hardware especializado. Tú solo te ocupas de tu código.
- El modelo de consumo: interactúas con los modelos vía una API estandarizada. Ya sea que llames a Claude 4 de Anthropic, Llama 3.5 de Meta o Nova 2 de Amazon, la infraestructura subyacente es idéntica.
- Escalado serverless: Bedrock resuelve el problema del cold start. Tú no te ocupas del escalado de instancias; AWS se asegura de que la capacidad de cómputo esté lista para atender tu solicitud, ya sea que envíes una o un millón.
Amazon SageMaker: la mesa de trabajo (IaaS/PaaS)
SageMaker ofrece un entorno de infraestructura gestionada. Aunque incluye abstracciones de alto nivel, en última instancia te da acceso al ciclo de vida del machine learning.
- El modelo de infraestructura: seleccionas instancias EC2 específicas para entrenamiento e inferencia. Tú decides el tipo de instancias y el entorno de ejecución.
- Propiedad de los pesos: en SageMaker, cuando haces fine-tuning o entrenas un modelo, los artefactos resultantes son tuyos (los archivos .tar.gz en S3). Puedes moverlos a otro servicio o incluso on-premises.
2: A fondo con AWS Bedrock (nuevas funciones)
A partir de 2026, Bedrock dejó de ser un simple wrapper para LLMs. Evolucionó hasta convertirse en una capa de orquestación completa para GenAI.
2.1 La evolución agéntica: Bedrock AgentCore
La función estrella es Bedrock AgentCore, que permite a los desarrolladores crear agentes autónomos que no solo conversan, sino que actúan.
- Memoria episódica: ahora los agentes recuerdan interacciones pasadas entre sesiones sin que el desarrollador tenga que gestionar manualmente un estado en DynamoDB.
- Streaming bidireccional: los agentes ya pueden mantener conversaciones de voz naturales, con interrupciones similares a las humanas y razonamiento en tiempo real. Por ejemplo: imagina a un cliente que llama a una aerolínea para reprogramar un vuelo. En lugar de que la IA termine de leer un largo guion legal, el cliente puede decir: "Espera, eso es demasiado caro, ¿qué tal el vuelo de la mañana?". La IA se detiene a mitad de frase, escucha la inquietud y, sin perder el ritmo, empieza a buscar opciones más económicas.
- Controles de política: con lenguaje natural (que Bedrock convierte en política), puedes establecer límites estrictos. Por ejemplo: "NUNCA ofrezcas un descuento superior al 15% sin aprobación del supervisor."
2.2 Knowledge Bases y RAG nativo
Bedrock automatizó el pipeline de Retrieval-Augmented Generation (RAG).
- Chunking automático: divide los documentos en segmentos semánticos óptimos de forma automática.
- Servicio gestionado de vectores: se encarga de la generación de embeddings usando modelos como Titan Embeddings V2 y los almacena en un cluster serverless de OpenSearch, base de datos S3 Vector, Aurora PostgreSQL Serverless y Neptune Analytics (Graph RAG).
2.3 Reinforcement Fine-Tuning (RFT)
RFT permite mejorar los modelos a partir de feedback en lugar de enormes datasets etiquetados. Al apuntar Bedrock a los logs de invocación de tu aplicación, aprende qué respuestas resultaron útiles y se autooptimiza con el tiempo.
3: A fondo con Amazon SageMaker (nuevas funciones)
SageMaker sigue siendo un entorno potente para ML personalizado, pero se volvió mucho más amigable.
3.1 SageMaker HyperPod: mayor resiliencia
Para las organizaciones que entrenan modelos de billones de parámetros, SageMaker HyperPod es el estándar de oro.
- Clusters autorreparables: el entrenamiento de modelos masivos suele fallar por un único error de hardware en una GPU. HyperPod detecta automáticamente el nodo defectuoso, lo reemplaza y reanuda el entrenamiento desde el último checkpoint en cuestión de minutos, ahorrando millones en cómputo perdido.
3.2 Personalización de modelos serverless
SageMaker tomó prestado del manual de Bedrock. Ya puedes ejecutar Supervised Fine-Tuning (SFT) y Direct Preference Optimization (DPO) a través de una interfaz de lenguaje natural guiada por agentes. Es una técnica muy usada para alinear los Large Language Models (LLMs) con las preferencias humanas en Amazon SageMaker.
3.3 La revolución de la inferencia: Inference Components
SageMaker resolvió el problema del desperdicio de GPU. Con Inference Components, puedes hospedar decenas de modelos distintos en una sola instancia GPU grande. Esto permite una consolidación masiva de costos que el modelo por token de Bedrock no puede igualar en escenarios de alto volumen.
4: La economía a escala (la fórmula)
Esta es la sección más crítica para quienes toman decisiones. El servicio más barato depende por completo de tu volumen y throughput.
4.1 Precios de Bedrock: el costo variable
Bedrock se basa principalmente en precios por token.
Cost_{Bedrock} = (Tokens_{Input} \times Rate_{In}) + (Tokens_{Output} \times Rate_{Out})
Bedrock introdujo Prompt Caching, que cambia notablemente la fórmula para los sistemas RAG. Si envías el mismo "Manual de la Empresa" de 5,000 palabras en cada consulta:
- Lectura inicial: precio completo.
- Lectura cacheada: hasta un 90% de descuento.
4.2 Precios de SageMaker: el costo fijo
SageMaker usa precios basados en instancias.
Cost_{SageMaker} = Hours_{Instance} \times Rate_{Hourly}
4.3 El punto de equilibrio
Como regla general, el punto de equilibrio estándar se alcanza en torno a los 220 millones de tokens al día.
- Por debajo de 220M tokens: Bedrock casi siempre es más barato porque solo pagas por lo que usas. Si tu app está tranquila por la noche, pagas $0.
- Por encima de 220M tokens: SageMaker se vuelve más atractivo. Cuando tu volumen es lo suficientemente alto (ocupado entre el 80 y el 90% del tiempo), conviene hospedar un modelo destilado y cuantizado en SageMaker con chips AWS Inferentia3. A ese nivel, la tarifa plana del servidor sale más barata que el costo agregado por token de una API.
Tip de ROI: si tu tráfico es alto y constante, los Savings Plans de SageMaker (commitments de 1 o 3 años) pueden reducir tus costos hasta en un 64%. De forma similar, Provisioned Throughput de Amazon Bedrock ofrece ahorros importantes para workloads de IA generativa consistentes y de alto volumen. Puedes reservar capacidad dedicada en lugar de pagar tokens bajo demanda. Al comprometerte por plazos de 1 o 6 meses, se logran reducciones de costos que suelen ir del 30% al 50% frente a los precios on-demand.
5: Seguridad, soberanía y cumplimiento
5.1 Aislamiento de VPC
- Bedrock: se conecta vía VPC Endpoints (PrivateLink). Tus datos nunca atraviesan internet pública; los pesos del modelo residen en la zona del servicio gestionado por AWS.
- SageMaker: ofrece aislamiento total de VPC. Puedes desplegar modelos en una subred sin acceso a internet. Es la opción preferida para sectores altamente regulados (defensa, salud).
5.2 Propiedad y soberanía de los pesos
Si tu modelo de negocio depende de un modelo en particular, Bedrock implica un riesgo. Al usar Bedrock, dependes de que el proveedor del modelo (por ejemplo, Anthropic) lo mantenga disponible. En SageMaker, el snapshot del modelo es tuyo. Si un proveedor retira una versión, tu endpoint de SageMaker sigue funcionando. Eso es soberanía del modelo.
6: Ejemplos de la industria
Ejemplo 1: el agente Fintech de "Smart Compliance" (usa Bedrock)
El problema: un banco necesita una herramienta que audite cada correo saliente en tiempo real para verificar el cumplimiento regulatorio.
- ¿Por qué Bedrock? el tráfico es por ráfagas (alto a las 9 AM, cero a las 2 AM).
- La arquitectura: los Guardrails de Bedrock escanean automáticamente en busca de PII y lenguaje tóxico. Las Knowledge Bases de Bedrock contienen las regulaciones bancarias más recientes.
- Ventaja de AgentCore: con AgentCore, el agente puede "aprender" de los oficiales senior de cumplimiento del banco mediante Reinforcement Fine-Tuning (RFT). O bien, con un system prompt bien configurado, un agente puede ejecutar la tarea encomendada.
Ejemplo 2: la Radiology Vision Suite (usa SageMaker)
El problema: un grupo hospitalario necesita procesar millones de resonancias magnéticas para detectar posibles anomalías con una arquitectura de red neuronal personalizada.
- ¿Por qué SageMaker? es una tarea de visión por computadora no generativa y de alta precisión.
- La arquitectura: usa SageMaker Ground Truth para etiquetado de datos de grado médico. Entrena el modelo en SageMaker HyperPod para garantizar cero downtime durante el ciclo de entrenamiento de 3 semanas.
- Desplegar en chips Inferentia3 asegura una latencia inferior a 100 ms, algo crítico para asistencia quirúrgica en tiempo real.
Ejemplo 3: el Smart-Router para un Support Center (el optimizador de costos)
El problema: una startup fintech atiende 1 millón de consultas de clientes al mes. El 20% son preguntas complejas de planificación financiera, pero el 80% son solicitudes simples como "¿Dónde está mi reembolso?" o "Resetea mi contraseña".
La solución híbrida:
- Fase 1 (Bedrock): usa Amazon Nova 2 Lite como router. Identifica la intención de cada mensaje entrante de forma instantánea y económica.
- Fase 2 (SageMaker): mientras tu agente de soporte conversa con un cliente, este pregunta: "¿Puedo aumentar mi límite de crédito ahora mismo?". Para responder, el sistema debe analizar 5,000 puntos de datos en milisegundos: historial de transacciones, probabilidades de pagos atrasados y volatilidad del mercado en tiempo real.
- Incompatibilidad de modelos: Bedrock está pensado para IA generativa (LLMs). No puede hospedar ni ejecutar XGBoost, Random Forest o LightGBM, los modelos estándar de la industria para datos tabulares y decisiones binarias (Sí/No).
- Latencia: meter miles de filas de datos crudos en un prompt para que un LLM razone resulta lento y costoso.
- Estructura de datos: los LLMs son pensadores difusos. Para una decisión de crédito necesitas la precisión matemática de un modelo entrenado específicamente con los datos propietarios de tu empresa.
La solución con SageMaker:
Hospedas un modelo especializado de Gradient Boosting en un endpoint de SageMaker con Inferentia3.
- Bedrock lleva la conversación ("¡Con gusto lo reviso por ti!").
- SageMaker hace los cálculos pesados en segundo plano y analiza los datos tabulares en menos de 10 ms.
- SageMaker devuelve el resultado "Aprobado" a Bedrock para que comunique la noticia.
¿Por qué? Evitas pagar precios de nivel maestro (Bedrock) para responder preguntas de nivel escolar. El hardware dedicado de SageMaker absorbe el trabajo bruto de alto volumen por centavos, mientras que Bedrock queda reservado para la lógica de alto valor y la comunicación clara.
7: El marco de decisión: esta es una visión general de un marco de decisión sencillo:
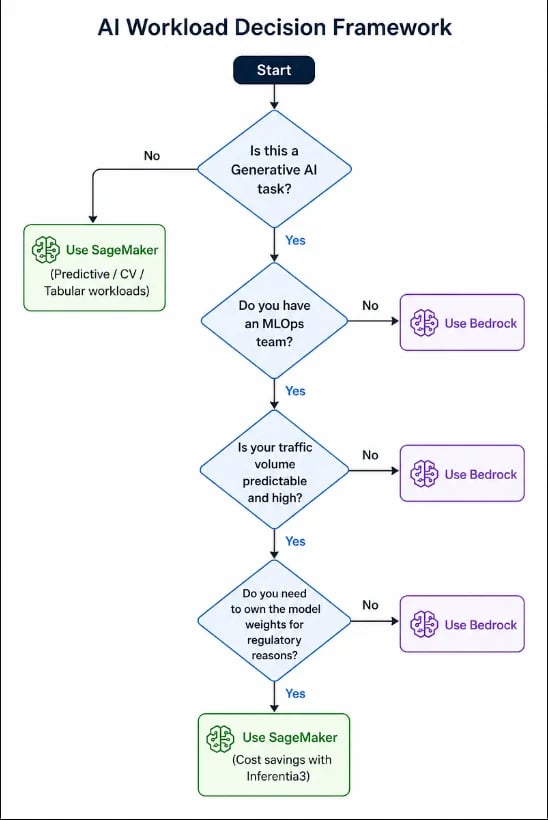
Para 2026, el debate SageMaker vs. Bedrock se desplazó hacia SageMaker Unified Studio, donde puedes usar ambos en paralelo dentro del mismo proyecto.
Con el lanzamiento de SageMaker Unified Studio (que comenzó a desplegarse a finales de 2025), AWS le puso fin a la era de las "dos pestañas". Ya no tienes que saltar entre la consola de SageMaker y la de Bedrock; ahora viven en un mismo entorno de desarrollo.
Por qué esto es un "Game Changer":
- Espacio de trabajo compartido: puedes crear un único proyecto en Unified Studio que contenga tanto tus notebooks de entrenamiento de SageMaker como las configuraciones de tus Bedrock Agents.
- Liquidez de datos: el Studio usa un catálogo de datos unificado. Puedes usar AWS Glue para preparar datos, hacer fine-tuning de un modelo en SageMaker y, en seguida, llevar ese modelo a un Bedrock Flow, todo sin mover tus datos entre servicios distintos.
- Acceso a Bedrock con un clic: dentro de la interfaz de Unified Studio hay una interfaz web dedicada para las herramientas de Bedrock (Agents, Guardrails y Knowledge Bases) que convive junto a tus experimentos de SageMaker.
La estrategia ganadora para la próxima década no consiste en elegir un solo servicio, sino en construir un stack de IA modular: usa Bedrock como el cerebro de tu aplicación y SageMaker para sus habilidades especializadas y su eficiencia económica.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Conclusión final:
La regla de los $10k:
Arranca con Bedrock para salir rápido al mercado. Cuando tu gasto mensual en inferencia llegue a $10,000, el "impuesto de la conveniencia" empieza a pesar más que el "costo de ingeniería". Esa es la señal para mover los workloads de alto volumen a SageMaker y capturar los enormes ahorros del hardware dedicado.
Este es el desglose de por qué funciona y dónde están los matices:
- El costo de gestionar la infraestructura: Bedrock cobra un premium por la conveniencia. Cuando tu factura llega a $10k, probablemente estás pagando un monto importante por el escalado serverless.
- El cruce con SageMaker: a $10k/mes hay presupuesto suficiente para cubrir el costo de un SageMaker HyperPod dedicado o de instancias Inferentia3 funcionando 24/7. A ese volumen, la tarifa plana del servidor sale más barata que el costo por token de Bedrock.
- Justificación del equipo: un gasto mensual de $10k suele ser el punto en el que un negocio puede justificar el sueldo de un ingeniero MLOps cuya única misión sea optimizar el uso de los recursos de SageMaker.
El matiz (cuándo podría no aplicar):
- Tráfico con picos: si esos $10k vienen de ráfagas masivas seguidas de horas de silencio, Bedrock podría seguir siendo más barato. Las instancias dedicadas de SageMaker cuestan dinero incluso cuando no procesan un solo token.
- Necesidad de velocidad: si tu equipo es pequeño, el "trabajo pesado" de migrar a SageMaker podría frenarte.