Nel panorama in rapida evoluzione del 2026, scegliere tra Amazon SageMaker e AWS Bedrock non è più una decisione scontata. Con il lancio di SageMaker Unified Studio e l'espansione dell'Agentic AI di Bedrock, i due servizi sono diventati le fondamenta di ogni strategia AI moderna.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Il meglio di entrambi i mondi
All'inizio degli anni 2020 i servizi AI di AWS erano nettamente distinti. SageMaker era il "laboratorio" in cui i data scientist costruivano da zero, mentre Bedrock era lo "studio Plug-and-Play" che permetteva agli sviluppatori di usare piattaforme AI completamente gestite.
Nel 2026 questi confini si sono fatti sfumati. SageMaker offre oggi workflow serverless guidati da agenti che reggono il confronto con la semplicità di Bedrock, mentre Bedrock ha introdotto Reinforcement Fine-Tuning (RFT) specializzato e Provisioned Throughput, garantendo livelli di controllo un tempo esclusivi di SageMaker.
Oggi la scelta dipende meno dalle competenze di programmazione e più dal ciclo di vita del prodotto, dal ritorno sull'investimento (ROI) e dalla sovranità dei dati.
1: Logica di progettazione
Per scegliere lo strumento giusto occorre prima capire il "modello di responsabilità condivisa" di ciascun servizio.
AWS Bedrock: l'intelligenza come utility (MaaS)
Bedrock nasce dalla filosofia Model-as-a-Service (MaaS). È un modello pronto all'uso: si fa carico del lavoro più oneroso, come la gestione dei server e dei driver hardware specializzati. A Lei resta da gestire solo il codice.
- Il modello di consumo: interagisce con i modelli tramite un'API standardizzata. Che richiami Claude 4 di Anthropic, Llama 3.5 di Meta o Nova 2 di Amazon, l'infrastruttura sottostante non cambia.
- Scalabilità serverless: Bedrock risolve il problema del cold start. Non deve gestire la scalabilità delle istanze: AWS garantisce che la potenza di calcolo sia pronta a rispondere, che invii una richiesta o un milione.
Amazon SageMaker: il banco di lavoro (IaaS/PaaS)
SageMaker mette a disposizione un ambiente di infrastruttura gestita. Pur offrendo astrazioni di alto livello, dà comunque accesso all'intero ciclo di vita del machine learning.
- Il modello infrastrutturale: seleziona istanze EC2 specifiche per training e inference. Decide il tipo di istanze da utilizzare e l'ambiente di esecuzione.
- Proprietà dei pesi: in SageMaker, quando esegue il fine-tuning o l'addestramento di un modello, gli artefatti risultanti (i file .tar.gz su S3) sono di sua proprietà. Può spostarli su un altro servizio o persino on-premises.
2: Approfondimento su AWS Bedrock (nuove funzionalità)
Nel 2026 Bedrock non è più un semplice wrapper per LLM. Si è evoluto in un vero e proprio livello di orchestrazione per la GenAI.
2.1 L'evoluzione agentica: Bedrock AgentCore
La funzionalità di punta è Bedrock AgentCore, che permette agli sviluppatori di creare agenti autonomi che non si limitano a parlare, ma agiscono.
- Memoria episodica: ora gli agenti ricordano le interazioni precedenti tra una sessione e l'altra, senza che lo sviluppatore debba gestire manualmente uno stato su DynamoDB.
- Streaming bidirezionale: gli agenti possono ora sostenere conversazioni vocali naturali, con interruzioni simili a quelle umane e ragionamento in tempo reale. Un esempio: immagini un cliente che chiama una compagnia aerea per riprenotare un volo. Invece di lasciare che l'AI completi un lungo copione legale, il cliente può dire: "Aspetti, è troppo caro — e il volo del mattino?". L'AI si interrompe a metà frase, raccoglie la richiesta e si mette subito a cercare opzioni più economiche, senza perdere un colpo.
- Controlli di policy: usando il linguaggio naturale (che Bedrock converte in una policy), può fissare limiti invalicabili. Per esempio: "Non offrire MAI uno sconto superiore al 15% senza l'approvazione di un supervisore."
2.2 Knowledge Bases e RAG nativo
Bedrock ha automatizzato la pipeline di Retrieval-Augmented Generation (RAG).
- Chunking automatico: suddivide automaticamente i documenti in segmenti semantici ottimali.
- Servizio gestito per i vettori: si occupa della generazione degli embedding usando modelli come Titan Embeddings V2 e li archivia in un cluster OpenSearch serverless, in un database vettoriale S3, in Aurora PostgreSQL Serverless e in Neptune Analytics (Graph RAG).
2.3 Reinforcement Fine-Tuning (RFT)
L'RFT consente di migliorare i modelli sfruttando il feedback, anziché enormi dataset etichettati. Indicando a Bedrock i log di invocazione della propria applicazione, il sistema impara quali risposte sono state utili e si auto-ottimizza nel tempo.
3: Approfondimento su Amazon SageMaker (nuove funzionalità)
SageMaker resta un ambiente potente per il ML su misura, ma è diventato molto più accessibile.
3.1 SageMaker HyperPod: per una maggiore resilienza
Per le organizzazioni che addestrano modelli da migliaia di miliardi di parametri, SageMaker HyperPod è lo standard di riferimento.
- Cluster auto-riparanti: l'addestramento di modelli di grandi dimensioni spesso si interrompe per un singolo guasto hardware di una GPU. HyperPod rileva automaticamente il nodo difettoso, lo sostituisce e riprende l'addestramento dall'ultimo checkpoint nel giro di pochi minuti, risparmiando milioni in capacità di calcolo sprecata.
3.2 Personalizzazione serverless dei modelli
SageMaker ha preso ispirazione dal playbook di Bedrock. Ora può eseguire il Supervised Fine-Tuning (SFT) e la Direct Preference Optimization (DPO) tramite un'interfaccia in linguaggio naturale guidata da agenti. È una tecnica diffusa per allineare i Large Language Model (LLM) alle preferenze umane su Amazon SageMaker.
3.3 La rivoluzione dell'inference: Inference Components
SageMaker ha risolto il problema dello spreco di GPU. Con gli Inference Components può ospitare decine di modelli diversi su un'unica istanza GPU di grandi dimensioni, ottenendo un consolidamento dei costi che il modello a token di Bedrock non riesce a eguagliare per gli utenti ad alto volume.
4: L'economia di scala (i numeri)
È la sezione più importante per chi deve decidere. Il servizio più economico dipende interamente dal suo volume e dal suo throughput.
4.1 I prezzi di Bedrock: il costo variabile
Bedrock adotta principalmente una tariffazione a token.
Cost_{Bedrock} = (Tokens_{Input} \times Rate_{In}) + (Tokens_{Output} \times Rate_{Out})
Bedrock ha introdotto il Prompt Caching, che cambia in modo radicale i conti per i sistemi RAG. Se invia lo stesso "Manuale Aziendale" di 5.000 parole con ogni query:
- Prima lettura: prezzo pieno.
- Lettura dalla cache: sconto fino al 90%.
4.2 I prezzi di SageMaker: il costo fisso
SageMaker adotta una tariffazione basata sulle istanze.
Cost_{SageMaker} = Hours_{Instance} \times Rate_{Hourly}
4.3 Il punto di pareggio
Come regola generale, il punto di pareggio standard si colloca intorno ai 220 milioni di token al giorno.
- Sotto i 220M di token: Bedrock è quasi sempre più conveniente perché paga solo per ciò che usa. Se la sua applicazione è ferma di notte, paga 0 $.
- Sopra i 220M di token: SageMaker diventa più interessante. Quando il volume è sufficientemente alto (con utilizzo all'80–90% del tempo) da giustificare l'hosting su SageMaker di un modello distillato e quantizzato sui chip AWS Inferentia3, la tariffa fissa del server risulta più conveniente del costo aggregato per token su un'API.
Suggerimento ROI: con traffico elevato e costante, i Savings Plans di SageMaker (commitments di 1 o 3 anni) possono ridurre i costi fino al 64%. Allo stesso modo, il Provisioned Throughput di Amazon Bedrock offre risparmi significativi per workloads di AI generativa ad alto volume e costanti. Può riservare capacità dedicata invece di pagare i prezzi dei token on-demand. Con commitments di 1 o 6 mesi può ottenere riduzioni di costo che vanno tipicamente dal 30% al 50% rispetto ai prezzi on-demand.
5: Sicurezza, sovranità e conformità
5.1 Isolamento VPC
- Bedrock: si connette tramite VPC Endpoint (PrivateLink). I suoi dati non transitano mai sulla rete internet pubblica; i pesi del modello risiedono nella zona di servizio gestita da AWS.
- SageMaker: offre un isolamento VPC totale. Può distribuire i modelli in una subnet senza alcun accesso a internet. È la scelta preferita nei settori altamente regolamentati (difesa, sanità).
5.2 Proprietà e sovranità dei pesi
Se il suo modello di business dipende da un modello specifico, Bedrock rappresenta un rischio: usandolo, dipende dal fatto che il fornitore (per esempio Anthropic) continui a renderlo disponibile. In SageMaker lo snapshot del modello è di sua proprietà. Se un fornitore ritira una versione, il suo endpoint SageMaker continua a funzionare. È la Model Sovereignty.
6: Esempi di settore
Esempio 1: l'agente Fintech "Smart Compliance" (usare Bedrock)
Il problema: una banca ha bisogno di uno strumento che verifichi in tempo reale ogni email in uscita ai fini della conformità normativa.
- Perché Bedrock? Il traffico è discontinuo (elevato alle 9 del mattino, nullo alle 2 di notte).
- L'architettura: i Guardrails di Bedrock analizzano automaticamente PII e linguaggio tossico. Le Bedrock Knowledge Bases contengono le normative bancarie più recenti.
- Il vantaggio di AgentCore: tramite AgentCore l'agente può "imparare" dai responsabili senior della compliance della banca grazie al Reinforcement Fine-Tuning (RFT). In alternativa, con un system prompt ben configurato l'agente è in grado di svolgere il compito assegnato.
Esempio 2: la suite di radiologia per la visione (usare SageMaker)
Il problema: un gruppo ospedaliero deve elaborare milioni di scansioni MRI per segnalare potenziali anomalie utilizzando un'architettura di rete neurale su misura.
- Perché SageMaker? Si tratta di un'attività di computer vision non generativa e ad alta precisione.
- L'architettura: usare SageMaker Ground Truth per l'etichettatura dei dati di livello medicale. Addestrare il modello su SageMaker HyperPod per azzerare il downtime durante il ciclo di addestramento di 3 settimane.
- Il deployment sui chip Inferentia3 garantisce una latenza inferiore a 100 ms, fondamentale per l'assistenza chirurgica in tempo reale.
Esempio 3: lo Smart-Router per il centro di supporto (l'ottimizzatore dei costi)
Il problema: una startup fintech gestisce 1 milione di richieste clienti al mese. Il 20% sono domande complesse di pianificazione finanziaria, ma l'80% sono richieste banali come "Dov'è il mio rimborso?" o "Reimpostare la password".
La soluzione ibrida:
- Fase 1 (Bedrock): usare Amazon Nova 2 Lite come router. Identifica l'intento di ogni messaggio in arrivo in modo istantaneo ed economico.
- Fase 2 (SageMaker): mentre il suo agente di supporto sta chattando con un cliente, quest'ultimo chiede: "Posso aumentare il mio limite di credito adesso?". Per rispondere, il sistema deve analizzare 5.000 punti dati in millisecondi: cronologia delle transazioni, probabilità di pagamenti in ritardo e volatilità del mercato in tempo reale.
- Incompatibilità del modello: Bedrock è pensato per l'AI generativa (LLM). Non può ospitare né eseguire XGBoost, Random Forest o LightGBM, i modelli standard del settore per dati tabulari e decisioni binarie (sì/no).
- Latenza: inviare migliaia di righe di dati grezzi in un prompt perché un LLM le elabori è lento e costoso.
- Struttura dei dati: gli LLM ragionano in modo approssimativo. Per una decisione creditizia serve la precisione matematica di un modello addestrato proprio sui dati proprietari della sua azienda.
La soluzione SageMaker:
Ospitare un Gradient Boosting Model specializzato su un endpoint Inferentia3 di SageMaker.
- Bedrock gestisce la conversazione ("Sarò felice di verificarlo per Lei!").
- SageMaker esegue i calcoli pesanti in background, analizzando i dati tabulari in meno di 10 ms.
- SageMaker restituisce l'esito "Approvato" a Bedrock, che comunica la notizia.
Perché? Si evita di pagare prezzi da specialista (Bedrock) per rispondere a domande elementari. L'hardware dedicato di SageMaker gestisce il lavoro ripetitivo ad alto volume per pochi centesimi, mentre Bedrock resta riservato alla logica ad alto valore e alla comunicazione chiara.
7: Il framework decisionale: ecco una panoramica di un semplice framework decisionale:
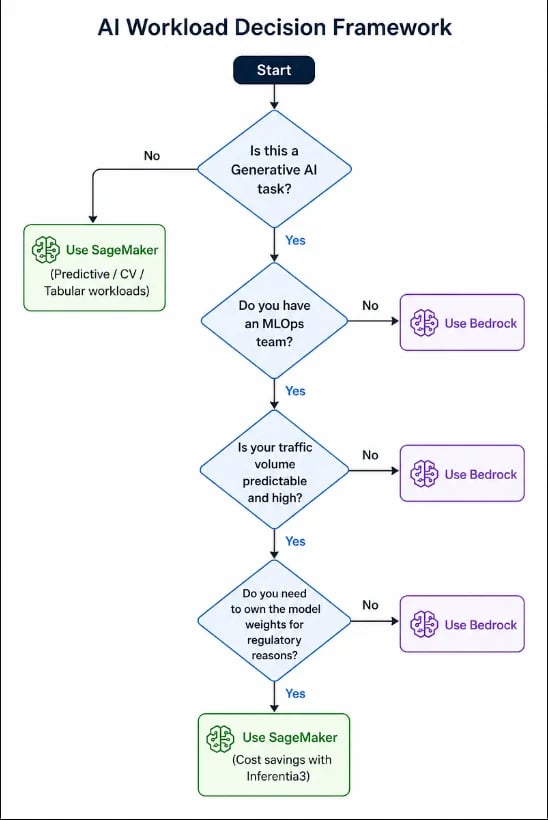
Nel 2026 il dibattito SageMaker vs Bedrock si è spostato verso SageMaker Unified Studio, dove può usare entrambi fianco a fianco nello stesso progetto.
Con il lancio di SageMaker Unified Studio (il cui rollout è iniziato a fine 2025), AWS ha di fatto chiuso l'era delle "due schede". Non deve più passare da una console SageMaker a una console Bedrock: ora sono integrate in un unico ambiente di sviluppo.
Perché è un "Game Changer":
- Lo spazio di lavoro condiviso: può creare un unico progetto in Unified Studio che contenga sia i notebook di training di SageMaker sia le configurazioni degli agenti Bedrock.
- Liquidità dei dati: lo Studio si basa su un catalogo dati unificato. Può usare AWS Glue per preparare i dati, sfruttarli per il fine-tuning di un modello in SageMaker e poi importare subito quel modello in un Bedrock Flow, senza mai spostare i dati tra servizi diversi.
- Accesso a Bedrock con un clic: all'interno dell'interfaccia di Unified Studio trova un'area web dedicata agli strumenti Bedrock (Agents, Guardrails e Knowledge Bases), affiancata ai suoi esperimenti SageMaker.
La strategia vincente per il prossimo decennio non è scegliere un solo servizio, ma costruire uno stack AI modulare: Bedrock come cervello dell'applicazione e SageMaker per le competenze specialistiche e l'efficienza economica.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Considerazione finale:
La regola dei 10.000 $:
Inizi con Bedrock per accelerare il time-to-market. Quando la spesa mensile per l'inference raggiunge i 10.000 $, la "tassa di comodità" inizia a pesare più del "costo ingegneristico". È il segnale per spostare i workloads ad alto volume su SageMaker e cogliere gli enormi risparmi dell'hardware dedicato.
Ecco perché funziona e dove sta la sfumatura:
- Il costo di gestione dell'infrastruttura: Bedrock fa pagare un sovrapprezzo per la comodità. Quando la fattura tocca i 10.000 $, sta probabilmente versando una cifra rilevante solo per la scalabilità serverless.
- Il punto di svolta SageMaker: a 10.000 $ al mese il budget basta a coprire il costo di un SageMaker HyperPod dedicato o di istanze Inferentia3 attive 24/7. A questo volume, il costo fisso del server risulta inferiore al costo per token di Bedrock.
- Giustificazione del team: una spesa mensile di 10.000 $ è di norma la soglia oltre la quale un'azienda può giustificare lo stipendio di un ingegnere MLOps dedicato esclusivamente all'ottimizzazione dell'uso delle risorse SageMaker.
La sfumatura (quando potrebbe non valere):
- Traffico a picchi: se i suoi 10.000 $ di spesa derivano da picchi massicci seguiti da ore di silenzio, Bedrock può restare la scelta più conveniente. Le istanze dedicate di SageMaker costano anche quando non elaborano un solo token.
- Necessità di velocità: se il suo team è ridotto, il "lavoro pesante" della migrazione a SageMaker rischia di rallentarla.