
XGBoost et TensorFlow sont deux frameworks de machine learning très performants, mais comment savoir lequel choisir ? Ou peut-être les deux ?
En machine learning, il n'y a pas de repas gratuit. Associer un algorithme précis à un problème précis donne souvent de meilleurs résultats qu'une approche universelle. Au fil des années, la communauté data science a toutefois acquis suffisamment d'expérience pour dégager des règles empiriques associant certains algorithmes à des tâches typiques.
Dans ce court article, je vais aborder quelques-unes de ces règles afin de vous aider à choisir entre les Gradient Boosting Machines avec XGBoost et les réseaux de neurones avec TensorFlow.
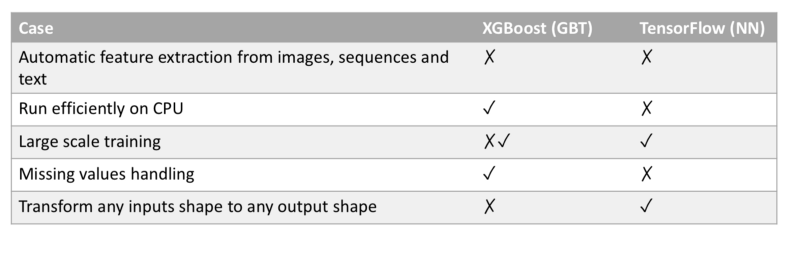 XGBoost vs TensorFlow : récapitulatif
XGBoost vs TensorFlow : récapitulatif
En 2012, Alex Krizhevsky et ses collègues ont stupéfié le monde avec un modèle computationnel capable non seulement d'apprendre à identifier l'objet présent dans une image à partir de caractéristiques, mais aussi de réaliser lui-même l'extraction de ces caractéristiques — une tâche jugée complexe même pour des ingénieurs humains expérimentés.
Depuis, les réseaux de neurones profonds dominent la recherche, avec une multitude d'articles proposant des concepts révolutionnaires pour la reconnaissance d'images, la traduction, les jeux vidéo et même la voiture autonome. Pourtant, sur le très populaire hub data science Kaggle, les benchmarks de nombreuses compétitions reposent sur une implémentation des Gradient Boosting Machines.
Bien que Cloud Machine Learning Engine propose désormais les deux frameworks, il n'est pas toujours évident de savoir quel algorithme explorer en premier. Après avoir résolu de nombreux problèmes de machine learning combinant ces deux méthodes, j'ai rassemblé quelques réflexions pour aider à trancher entre les différentes approches.
Cas n°1 : difficile à décomposer en caractéristiques ?
S'il y a une chose que nous avons retenue de 2012, c'est que les réseaux de neurones sont très efficaces pour traiter des données brutes en haute dimension. Les images, vidéos, textes et fichiers audio sont autant d'exemples de données brutes en haute dimension difficiles à prétraiter et à représenter sous forme de caractéristiques. Dans ce type de cas, les unités d'extraction de caractéristiques intégrées aux NN (CNN, LSTM, couches d'embedding) permettent d'obtenir des résultats phénoménaux en une fraction du temps de développement requis par les approches d'ingénierie classiques.
 Plutôt que d'extraire des caractéristiques, laissez le réseau apprendre la représentation. https://www.tensorflow.org/images/audio-image-text.png
Plutôt que d'extraire des caractéristiques, laissez le réseau apprendre la représentation. https://www.tensorflow.org/images/audio-image-text.png
Cas n°2 : gestion des valeurs manquantes ?
Si vous avez déjà tenté d'alimenter un réseau de neurones avec des données manquantes, vous vous êtes probablement heurté à des erreurs. Les équations résolues durant l'entraînement d'un NN supposent en effet une valeur valide pour chaque variable d'entrée.
XGBoost, lui, dispose de sa propre méthode pour gérer les données manquantes. Pendant l'entraînement, il effectue une sous-tâche d'apprentissage de l'imputation des données pour chaque caractéristique. Or, dans bien des problèmes réels, l'absence d'une donnée est en soi porteuse d'information sur la cible. Pour la gestion gratuite des valeurs manquantes, XGBoost l'emporte donc.
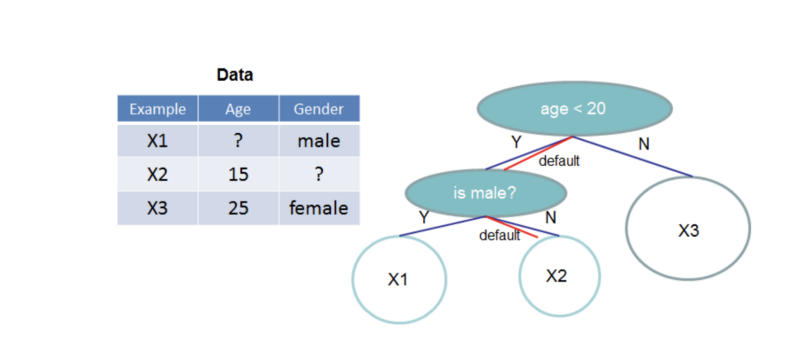 Avec XGBoost, l'arbre apprend à gérer les valeurs manquantes. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
Avec XGBoost, l'arbre apprend à gérer les valeurs manquantes. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
Cas n°3 : quel est votre budget ?
L'entraînement des réseaux de neurones est embarrassingly parallel, ce qui les rend parfaits pour l'entraînement parallèle et distribué. À condition que votre budget puisse couvrir des heures d'entraînement sur des machines coûteuses équipées de TPU ou de GPU.
À l'inverse, si vous travaillez tout au plus avec quelques millions d'enregistrements, XGBoost peut être entraîné sur un CPU multi-cœurs nettement moins coûteux et converger plus rapidement. Avec une quantité de données limitée, XGBoost s'avère donc souvent plus abordable pour des résultats comparables.
Cloud TPU v2 Pod — des résultats remarquables sur des datasets massifs
Cas n°4 : de quel volume de données disposez-vous ?
Le cas précédent nous amène à la question du volume de données disponible. Du fait de sa structure de données sous-jacente, XGBoost se prête mal à la parallélisation, ce qui limite le volume de données qu'il peut traiter. Une façon de gérer des datasets massifs consiste à découper les données en shards et à empiler (stacking) des modèles, multipliant ainsi le nombre de paramètres utilisés pour ajuster les données.
Avec les réseaux de neurones, en revanche, c'est généralement plus on est de fous, plus on rit. Face à des datasets massifs, ils peuvent converger, à nombre de paramètres égal, vers une erreur de généralisation plus faible. Sur des datasets plus petits, XGBoost converge en revanche plus vite et avec une erreur moindre.
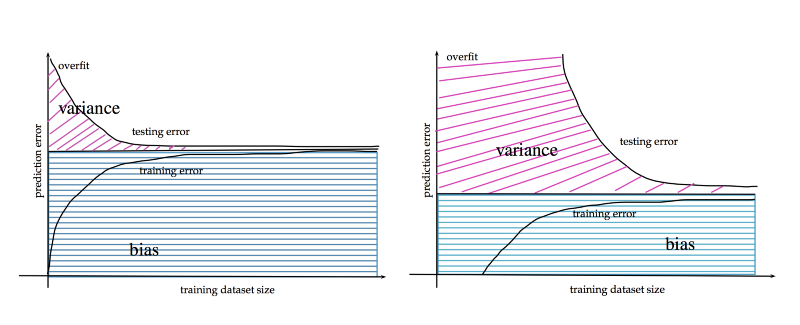 Un volume de données important contribue à réduire l'erreur de généralisation. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
Un volume de données important contribue à réduire l'erreur de généralisation. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
Cas n°5 : quelle complexité pour les formes d'entrée et de sortie ?
XGBoost est plus contraint que les NN sur la forme des données qu'il peut traiter. Il accepte généralement des tableaux 1D en entrée et renvoie un nombre unique (régression) ou un vecteur de probabilités (classification). Configurer un pipeline XGBoost est de ce fait plus simple : pas besoin de se soucier de la forme des données, il suffit de fournir un dataframe pandas qui ressemble à un tableau, de désigner la colonne de label, et le tour est joué.
Les réseaux de neurones, eux, sont conçus pour opérer sur des tenseurs — des matrices en haute dimension. Leurs entrées et sorties peuvent prendre la forme de nombres, de séquences (vecteurs), d'images, voire de vidéos. Pour des problèmes classiques comme la prédiction du taux de clic à partir de données structurées, les deux options conviennent en termes de forme de données. Mais dès qu'il s'agit de construire des transformations plus complexes, les NN restent souvent la seule option viable !
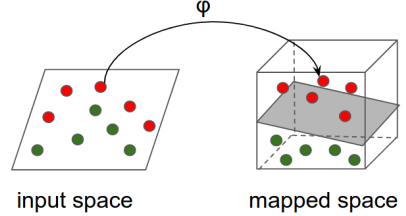 https://www.tensorflow.org/tutorials/representation/kernel_methods
https://www.tensorflow.org/tutorials/representation/kernel_methods
Cas n°6 : et si je voulais les deux ?
Et si vous ne vouliez pas choisir ? Dans bien des cas, la combinaison des deux modèles donne de meilleurs résultats que chacun pris isolément. J'ai déjà évoqué le model-stacking plus haut. La différence mathématique entre les modèles se traduit par une distribution d'erreur différente sur les mêmes données. En les empilant, on peut atteindre un taux d'erreur plus faible à volume de données équivalent, au prix d'une ingénierie système plus complexe.
Je tiens à remercier Philip Tannor pour ses remarques pertinentes.
Envie d'autres articles ? Consultez notre blog, ou suivez Gad sur Twitter.