
XGBoost y TensorFlow son frameworks de machine learning muy potentes, pero ¿cómo saber cuál te conviene? ¿O acaso necesitas los dos?
En machine learning no existen los "almuerzos gratis". Asignar algoritmos específicos a problemas específicos suele dar mejores resultados que el enfoque de "talla única". Aun así, con los años la comunidad de data science ha acumulado suficiente experiencia para definir reglas prácticas que ayudan a emparejar ciertos algoritmos con tareas típicas.
En este breve post voy a repasar algunas de esas reglas para ayudarte a decidir entre Gradient Boosting Machines con XGBoost y redes neuronales con TensorFlow.
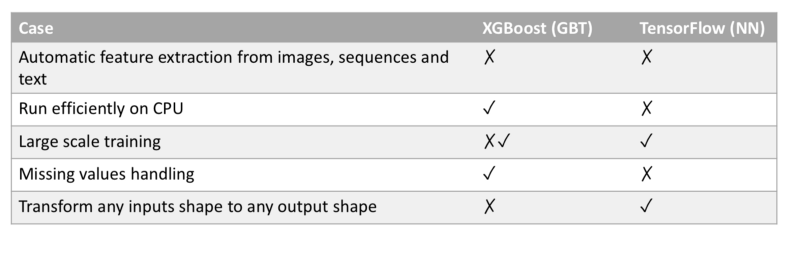 Resumen XGBoost vs TensorFlow
Resumen XGBoost vs TensorFlow
En 2012, Alex Krizhevsky y sus colegas asombraron al mundo con un modelo computacional que no solo aprendía a identificar qué objeto aparece en una imagen a partir de sus características, sino que además se encargaba de la propia extracción de características — una tarea que se consideraba compleja incluso para ingenieros "humanos" con experiencia.
Desde entonces, las redes neuronales profundas han dominado el panorama de la investigación, con cada vez más artículos que proponen conceptos revolucionarios para reconocimiento de imágenes, traducción, videojuegos e incluso autos autónomos. Sin embargo, en el conocido hub de data science Kaggle, los benchmarks de muchas competencias se basan en alguna implementación de Gradient Boosting Machines.
Aunque Cloud Machine Learning Engine ya ofrece ambos frameworks, no siempre queda claro cuál algoritmo conviene explorar primero. Después de resolver muchos problemas de machine learning con los dos métodos, junté algunas ideas sobre cómo elegir entre los distintos enfoques.
Caso 1: ¿Difícil de descomponer en características?
Si algo aprendimos desde 2012 es que las redes neuronales son muy eficientes para trabajar con datos crudos de alta dimensionalidad. Imágenes, video, texto y audio son ejemplos de datos crudos de alta dimensionalidad muy difíciles de preprocesar y representar como características. En estos casos, usar las unidades de extracción de características integradas en las NN (CNNs, LSTMs, capas de Embedding) puede dar resultados extraordinarios en una fracción del tiempo de desarrollo de los enfoques clásicos de ingeniería.
 En lugar de extraer características, deja que la red aprenda la representación. https://www.tensorflow.org/images/audio-image-text.png
En lugar de extraer características, deja que la red aprenda la representación. https://www.tensorflow.org/images/audio-image-text.png
Caso 2: ¿Manejo de valores faltantes?
Si alguna vez intentaste alimentar una red neuronal con datos faltantes, lo más probable es que te encontraras con errores. Esto se debe a que las ecuaciones que se resuelven durante el entrenamiento de la NN suponen un valor válido para cada variable de entrada.
XGBoost, en cambio, tiene su propia forma de lidiar con los datos faltantes. Durante el entrenamiento, XGBoost ejecuta una subtarea de aprender a imputar datos para cada característica. Muchos problemas del mundo real tienen datos faltantes que en sí mismos contienen información valiosa sobre el objetivo. Así que, en cuanto al manejo "gratis" de valores faltantes, XGBoost se lleva la victoria.
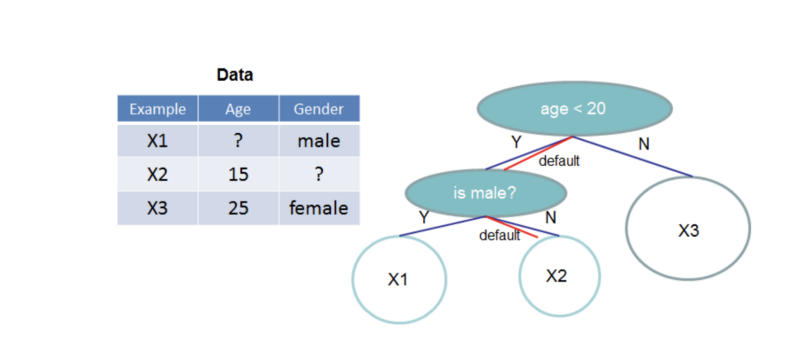 XGBoost: el árbol aprende a manejar valores faltantes. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
XGBoost: el árbol aprende a manejar valores faltantes. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
Caso 3: ¿Qué tan profundos son tus bolsillos?
El entrenamiento de redes neuronales es "vergonzosamente paralelo", lo que las vuelve ideales para entrenamiento paralelo y distribuido. Eso sí, siempre que tu presupuesto alcance para horas de entrenamiento en máquinas costosas con TPUs o GPUs.
Por otro lado, si solo trabajas con hasta varios millones de registros, XGBoost se puede entrenar en una CPU multinúcleo más económica y converger en menos tiempo. Así que, si tienes una cantidad limitada de datos y quieres entrenar un modelo, XGBoost puede salir más a cuenta y lograr resultados similares.
Cloud TPU v2 Pod — resultados sobresalientes al manejar datasets masivos
Caso 4: ¿Cuántos datos tienes?
El caso anterior nos lleva a la pregunta de cuántos datos tienes. Debido a su estructura de datos subyacente, XGBoost tiene limitaciones para paralelizarse, lo que lo deja corto en la cantidad de datos que puede procesar. Una forma de manejar datasets masivos es dividir los datos en shards y aplicar stacking de modelos, multiplicando así el número de parámetros que se usan para ajustar los datos.
Sin embargo, con las redes neuronales suele aplicarse el principio de "cuantos más, mejor". Al trabajar con datasets masivos, las redes neuronales pueden converger con el mismo número de parámetros a un menor error de generalización. Pero para datasets más pequeños, XGBoost suele converger más rápido y con menor error.
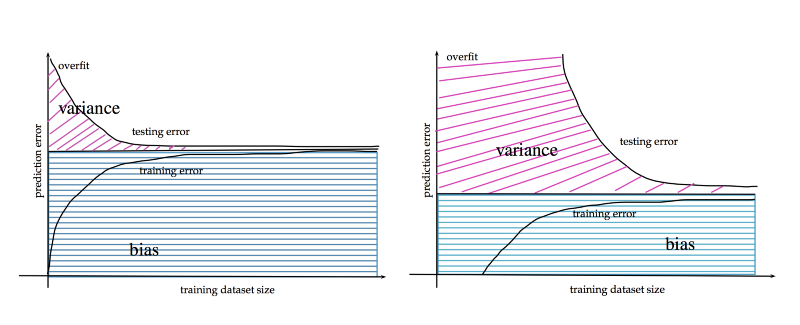 una gran cantidad de datos contribuye a reducir el error de generalización. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
una gran cantidad de datos contribuye a reducir el error de generalización. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
Caso 5: ¿Qué tan complejas son las formas de entrada/salida?
XGBoost tiene más limitaciones que las NN en cuanto a la forma de los datos con los que puede trabajar. Por lo general, recibe arrays de 1-d como entradas de registro y devuelve un único número (regresión) o un vector de probabilidades (clasificación). Por eso resulta más fácil configurar un pipeline de XGBoost. En XGBoost no hay que preocuparse por las formas de los datos: basta con proporcionar un dataframe de pandas con pinta de tabla, definir la columna de etiqueta y listo.
Las redes neuronales, en cambio, están diseñadas para trabajar sobre tensores — una matriz de alta dimensionalidad. La forma de entrada y de salida de las NN puede variar entre números, secuencias (vectores), imágenes e incluso videos. Así que, para problemas clásicos como la predicción de click-through con datos estructurados, ambos funcionan bien en términos de forma de los datos. Pero cuando se trata de construir transformaciones de datos más complejas, ¡las NN pueden ser tu única opción viable!
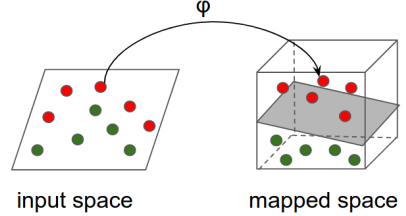 https://www.tensorflow.org/tutorials/representation/kernel_methods
https://www.tensorflow.org/tutorials/representation/kernel_methods
Caso 6: ¿Y si los quiero a los dos?
¿Y si no quieres elegir? En muchos casos, combinar ambos modelos puede dar mejores resultados que cada uno por separado. Ya mencioné el model-stacking en este post. La diferencia matemática entre los modelos provoca una distribución de error distinta sobre los mismos datos. Al hacer stacking se puede lograr una menor tasa de error con la misma cantidad de datos, aunque a costa de complicar la ingeniería del sistema.
Quiero agradecer a Philip Tannor por sus comentarios tan acertados.
¿Quieres más historias? Visita nuestro blog, o sigue a Gad en Twitter.