
XGBoost und TensorFlow sind beides starke Machine-Learning-Frameworks – aber welches brauchen Sie? Oder vielleicht sogar beide?
Im Machine Learning gibt es "no free lunches". Den richtigen Algorithmus zum konkreten Problem zu wählen, schlägt fast immer den "One-fits-all"-Ansatz. Trotzdem hat die Data-Science-Community über die Jahre genug Erfahrung gesammelt, um Faustregeln zu formulieren, welche Algorithmen sich für welche typischen Aufgaben eignen.
In diesem kurzen Beitrag fasse ich einige dieser Regeln zusammen, damit Sie leichter zwischen Gradient Boosting Machines mit XGBoost und Neuronalen Netzen mit TensorFlow entscheiden können.
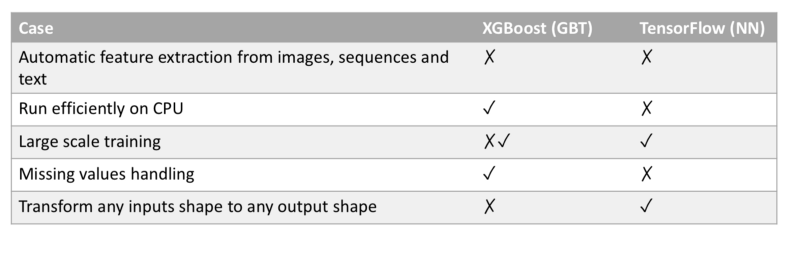 XGBoost vs. TensorFlow im Überblick
XGBoost vs. TensorFlow im Überblick
2012 verblüfften Alex Krizhevsky und seine Kollegen die Welt mit einem Rechenmodell, das nicht nur anhand von Features lernen konnte, welches Objekt in einem Bild zu sehen ist, sondern auch die Feature-Extraktion selbst übernahm – eine Aufgabe, die selbst für erfahrene "menschliche" Engineers als komplex galt.
Seitdem dominieren tiefe neuronale Netze die Forschungslandschaft, mit immer neuen Arbeiten zu revolutionären Konzepten in Bilderkennung, Übersetzung, Computerspielen und sogar autonomem Fahren. Trotzdem basieren auf der populären Data-Science-Plattform Kaggle die Benchmarks vieler Wettbewerbe nach wie vor auf einer Implementierung von Gradient Boosting Machines.
Auch wenn Cloud Machine Learning Engine inzwischen beide Frameworks unterstützt, ist nicht immer klar, mit welchem Algorithmus man starten sollte. Nachdem ich zahlreiche Machine-Learning-Probleme mit beiden Methoden gelöst habe, teile ich hier ein paar Überlegungen, wie sich zwischen den Ansätzen wählen lässt.
Fall 1: Lassen sich Features nur schwer ableiten?
Wenn uns 2012 etwas gelehrt hat, dann das: Neuronale Netze sind extrem effizient im Umgang mit hochdimensionalen Rohdaten. Bilder, Videos, Text und Audio sind allesamt Beispiele für hochdimensionale Rohdaten, die sich nur schwer vorverarbeiten und als Features darstellen lassen. In solchen Fällen liefern die in NNs eingebauten Bausteine zur Feature-Extraktion (CNNs, LSTMs, Embedding-Layer) phänomenale Ergebnisse – und das in einem Bruchteil der Entwicklungszeit klassischer Engineering-Ansätze.
 Statt Features zu extrahieren, lernt das Netz die Repräsentation selbst. https://www.tensorflow.org/images/audio-image-text.png
Statt Features zu extrahieren, lernt das Netz die Repräsentation selbst. https://www.tensorflow.org/images/audio-image-text.png
Fall 2: Umgang mit fehlenden Werten?
Wer schon einmal versucht hat, ein neuronales Netz mit fehlenden Daten zu füttern, kennt die Fehlermeldungen. Der Grund: Die Gleichungen, die während des NN-Trainings gelöst werden, setzen für jede Eingabevariable einen gültigen Wert voraus.
XGBoost geht hier einen eigenen Weg. Während des Trainings lernt XGBoost als Teilaufgabe, für jedes Feature Werte zu imputieren. Viele reale Probleme haben fehlende Werte, die für sich genommen bereits wertvolle Informationen über die Zielgröße enthalten. Beim Umgang mit fehlenden Werten "frei Haus" hat XGBoost also klar die Nase vorn.
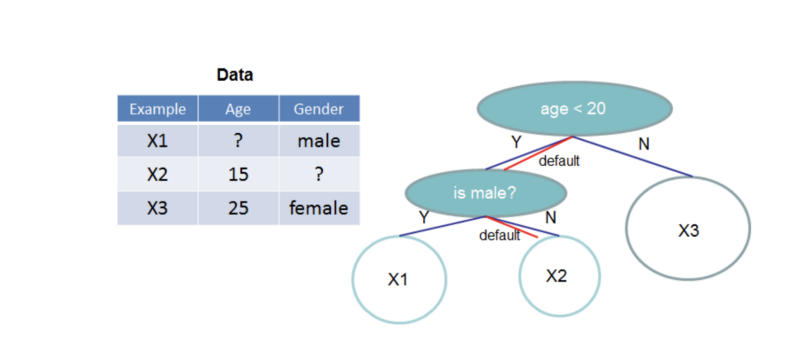 Bei XGBoost lernt der Baum, mit fehlenden Werten umzugehen. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
Bei XGBoost lernt der Baum, mit fehlenden Werten umzugehen. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
Fall 3: Wie tief sitzt das Budget?
Das Training neuronaler Netze ist "embarrassingly parallel" und damit prädestiniert für paralleles und verteiltes Training. Vorausgesetzt, Ihr Budget deckt stundenlanges Training auf teuren Maschinen mit TPUs oder GPUs.
XGBoost dagegen lässt sich bei bis zu einigen Millionen Datensätzen auf einer günstigeren Multi-Core-CPU trainieren und konvergiert dabei in kürzerer Zeit. Wenn Sie also nur über begrenzte Datenmengen verfügen und ein Modell trainieren wollen, ist XGBoost oft die wirtschaftlichere Option mit vergleichbaren Ergebnissen.
Cloud TPU v2 Pod – herausragende Ergebnisse bei riesigen Datensätzen
Fall 4: Wie viele Daten haben Sie?
Damit sind wir bei der Frage, wie viele Daten Ihnen tatsächlich zur Verfügung stehen. Aufgrund seiner zugrunde liegenden Datenstruktur lässt sich XGBoost nur begrenzt parallelisieren – das limitiert die verarbeitbare Datenmenge. Ein Weg, mit sehr großen Datensätzen umzugehen, ist es, die Daten in Shards aufzuteilen und Modelle zu stacken – wodurch sich die Anzahl der Parameter, mit denen die Daten gefittet werden, effektiv vervielfacht.
Bei neuronalen Netzen gilt dagegen meist "je mehr, desto besser". Bei sehr großen Datensätzen können neuronale Netze mit derselben Parameterzahl auf einen niedrigeren Generalisierungsfehler konvergieren. Bei kleineren Datensätzen konvergiert XGBoost dagegen meist schneller und mit geringerem Fehler.
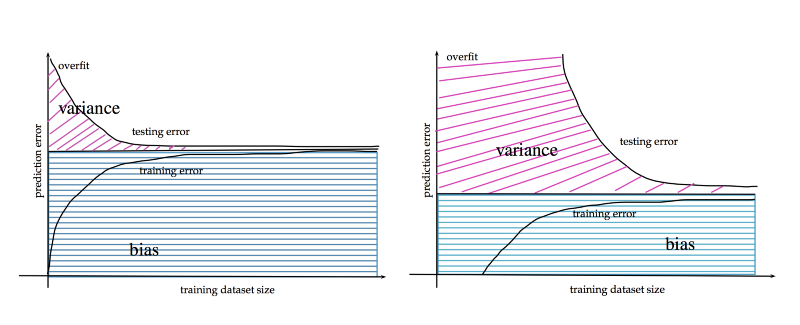 Große Datenmengen führen zu einem niedrigeren Generalisierungsfehler. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
Große Datenmengen führen zu einem niedrigeren Generalisierungsfehler. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
Fall 5: Wie komplex sind die Input-/Output-Strukturen?
XGBoost ist bei der Form der verarbeitbaren Daten stärker eingeschränkt als NNs. Üblicherweise nimmt es 1D-Arrays als Datensätze entgegen und liefert eine einzelne Zahl (Regression) oder einen Wahrscheinlichkeitsvektor (Klassifikation). Dadurch lässt sich eine XGBoost-Pipeline einfacher konfigurieren. In XGBoost müssen Sie sich nicht um Datenformen kümmern – Sie übergeben einfach ein pandas-DataFrame, das wie eine Tabelle aussieht, definieren die Label-Spalte, und schon kann es losgehen.
Neuronale Netze hingegen sind darauf ausgelegt, mit Tensoren – also hochdimensionalen Matrizen – zu arbeiten. Input- und Output-Form eines NN können von Zahlen über Sequenzen (Vektoren) bis hin zu Bildern und sogar Videos reichen. Für klassische Aufgaben wie die Click-Through-Vorhersage auf Basis strukturierter Daten funktionieren beide Ansätze gut – jedenfalls, was die Datenform angeht. Sobald es aber um komplexere Datentransformationen geht, sind NNs oft die einzig sinnvolle Wahl!
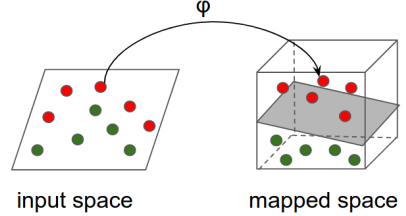 https://www.tensorflow.org/tutorials/representation/kernel_methods
https://www.tensorflow.org/tutorials/representation/kernel_methods
Fall 6: Geht auch beides?
Was, wenn Sie sich gar nicht entscheiden wollen? In vielen Fällen liefert eine Kombination aus beiden Modellen bessere Ergebnisse als jedes Modell für sich allein. Model-Stacking habe ich in diesem Beitrag bereits erwähnt. Die mathematischen Unterschiede zwischen den Modellen führen zu unterschiedlichen Fehlerverteilungen auf denselben Daten. Durch Stacking lässt sich bei gleicher Datenmenge eine niedrigere Fehlerrate erreichen – allerdings um den Preis eines komplexeren System-Engineerings.
Ein herzliches Dankeschön an Philip Tannor für seine wertvollen Anmerkungen.
Lust auf mehr? Schauen Sie in unseren Blog oder folgen Sie Gad auf Twitter.