
XGBoost も TensorFlow も強力な機械学習フレームワーク。自分のプロジェクトにはどちらが向いているのか、あるいは両方を組み合わせるべきか、判断のポイントを解説します。
機械学習の世界に「ノーフリーランチ定理」という考え方があります。万能のアプローチに頼るよりも、問題ごとに最適なアルゴリズムを選んだほうがよい結果につながることが多い、というものです。とはいえデータサイエンスの現場では長年の経験が積み重なり、「この種のタスクにはこのアルゴリズム」という経験則が共有されるようになってきました。
本記事では、XGBoost による勾配ブースティングマシンと、TensorFlow によるニューラルネットワークのどちらを選ぶべきかを判断する際に役立つ経験則を、コンパクトに整理してご紹介します。
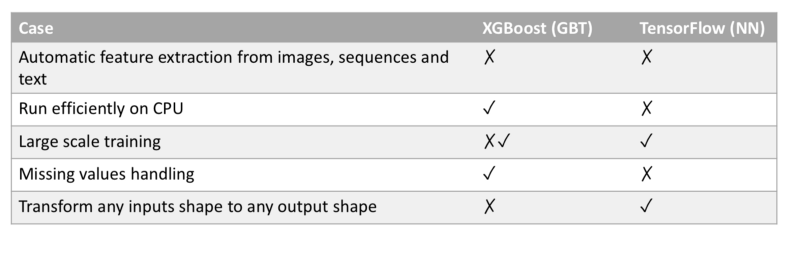 XGBoost と TensorFlow の比較サマリー
XGBoost と TensorFlow の比較サマリー
2012 年、Alex Krizhevsky 氏らは世界に衝撃を与えました。特徴量に基づいて画像内の物体を識別するだけでなく、特徴抽出そのものまで自ら行う計算モデルを示したのです。当時、特徴抽出は熟練した「人間の」エンジニアにとっても難題と考えられていました。
以来、ディープニューラルネットワークは研究の主役となり、画像認識、機械翻訳、ゲームプレイ、さらには自動運転に至るまで、画期的なコンセプトを提示する論文が次々と発表されてきました。一方、人気のデータサイエンス・コミュニティ Kaggle では、多くのコンペティションのベンチマークが勾配ブースティングマシンの実装をベースにしています。
Cloud Machine Learning Engine では現在どちらのフレームワークも利用可能ですが、まずどちらから試すべきかは必ずしも自明ではありません。両方を使った機械学習プロジェクトを数多く経験してきた立場から、選び方のヒントをまとめてみました。
ケース 1:特徴量への分解が難しい
2012 年以降の歩みが教えてくれたのは、ニューラルネットワークが高次元の生データを扱うのに極めて長けているということです。画像、動画、テキスト、音声はいずれも、前処理して特徴量に落とし込むのが非常に難しい高次元データの典型例です。こうした場面では、ニューラルネットワークに組み込まれた特徴抽出ユニット(CNN、LSTM、Embedding 層など)を使うことで、従来のエンジニアリング手法のごく一部の開発時間で目覚ましい結果を得られます。
 特徴量を抽出するのではなく、ネットワーク自身に表現を学ばせる。https://www.tensorflow.org/images/audio-image-text.png
特徴量を抽出するのではなく、ネットワーク自身に表現を学ばせる。https://www.tensorflow.org/images/audio-image-text.png
ケース 2:欠損値をどう扱うか
欠損値を含むデータをニューラルネットワークに流し込もうとして、エラーで止まった経験はないでしょうか。これは学習中に解かれる方程式が、すべての入力変数に有効な値があることを前提としているためです。
これに対して XGBoost は、欠損データを扱う独自の仕組みを備えています。学習の過程で、各特徴量について欠損値の補完方法そのものを学習するサブタスクが実行されるのです。実世界の問題では、欠損していること自体が予測対象に関する有益な情報を含んでいるケースも少なくありません。欠損値処理を「タダで」済ませたいなら、軍配は XGBoost に上がります。
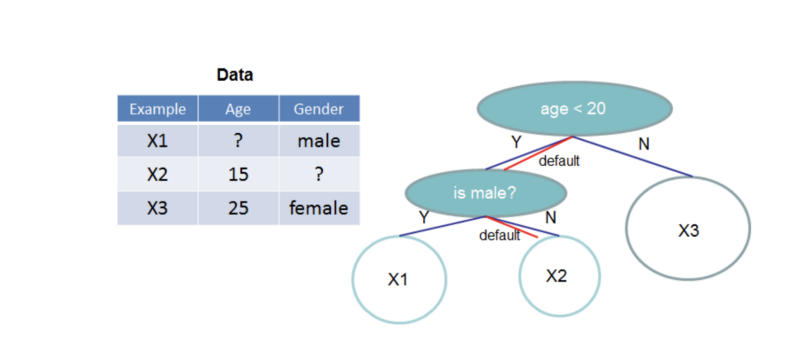 XGBoost では、ツリーが欠損値の扱い方を学習する。arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
XGBoost では、ツリーが欠損値の扱い方を学習する。arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
ケース 3:予算はどのくらい?
ニューラルネットワークの学習は「embarrassingly parallel(きわめて並列化しやすい)」と呼ばれる性質を持ち、並列・分散学習に最適です。ただし、TPU や GPU を積んだ高価なマシンで何時間も回せるだけの予算があれば、の話です。
一方、扱うレコードが数百万件程度までに収まるなら、XGBoost はより安価なマルチコア CPU で学習でき、収束までの時間も短く済みます。データ量が限られていてモデルを手早く学習させたいなら、XGBoost のほうがコストを抑えながら同等の結果を出せる可能性があります。
Cloud TPU v2 Pod — 大規模データセットの処理で圧倒的なパフォーマンスを発揮
ケース 4:データはどれだけあるか
前のケースから自然につながる問いが、「データはどのくらいあるのか」です。XGBoost はその内部データ構造に起因して並列化の余地が限られており、処理できるデータ量にも上限があります。大規模データセットへの対処法のひとつは、データをシャードに分割してモデルをスタッキングすることで、データへのフィッティングに使えるパラメータ数を実質的に増やすことです。
一方、ニューラルネットワークでは「多ければ多いほど良い」がおおむね通用します。大規模データセットを扱う場合、同じパラメータ数でも汎化誤差をより低く抑えるかたちで収束させることができます。逆に小規模なデータセットでは、XGBoost のほうが速く、しかも小さい誤差で収束する傾向があります。
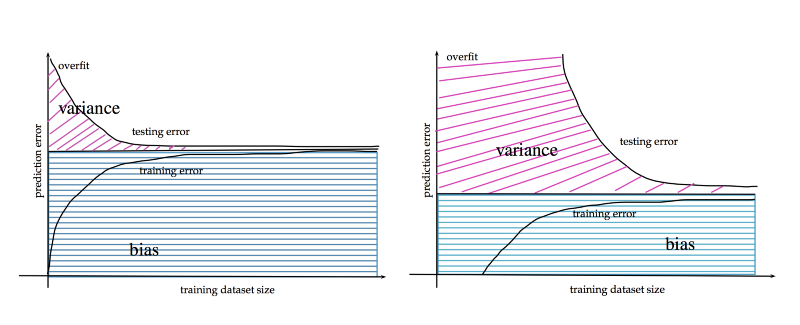 大量のデータは汎化誤差の低減に寄与する。http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
大量のデータは汎化誤差の低減に寄与する。http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
ケース 5:入出力の形状はどれだけ複雑?
XGBoost は、扱えるデータの形状についてニューラルネットワークよりも制約が多めです。_通常_はレコード入力として 1 次元配列を受け取り、出力は単一の数値(回帰)か確率ベクトル(分類)です。そのぶんパイプラインの構築は容易で、データの形状に頭を悩ませる必要もありません。表形式の pandas DataFrame を用意し、ラベル列を指定すれば、それで準備完了です。
これに対しニューラルネットワークは、テンソル(高次元の行列)を扱うように設計されています。入出力の形状は、数値、シーケンス(ベクトル)、画像、さらには動画まで自在に変えられます。構造化データに基づくクリックスルー予測のような古典的なタスクであれば、データの形状という観点ではどちらでも問題なく対応できます。しかし、より複雑なデータ変換を組み立てたい場合は、ニューラルネットワーク以外に選択肢がないこともあります。
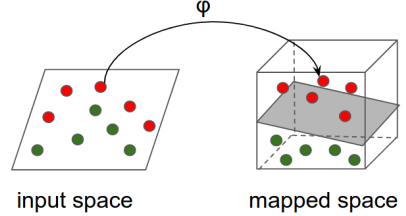 https://www.tensorflow.org/tutorials/representation/kernel_methods
https://www.tensorflow.org/tutorials/representation/kernel_methods
ケース 6:両方使ってはダメ?
そもそも一つに絞りたくない、というケースもあるでしょう。実際、両方のモデルを組み合わせたほうが、それぞれ単独よりも良い結果になることは少なくありません。本記事でも先にモデルスタッキングに触れました。モデルごとの数学的な違いにより、同じデータでも誤差の分布は変わります。スタッキングすれば、同じデータ量のままでより低い誤差率を実現できます。ただし、その代償としてシステムのエンジニアリングは複雑になります。
鋭い指摘をくださった Philip Tannor 氏に感謝します。
他の記事もぜひ。ブログを覗いてみるか、Twitter で Gad をフォローしてください。