
XGBoost e TensorFlow são frameworks de machine learning poderosíssimos, mas como saber qual você precisa? Ou será que precisa dos dois?
Em machine learning, não existe "almoço grátis". Casar algoritmos específicos com problemas específicos costuma render mais do que a abordagem "tamanho único". Ainda assim, com os anos, a comunidade de data science acumulou experiência o suficiente para criar regras de bolso que ajudam a combinar determinados algoritmos com tarefas típicas.
Neste post curto, vou tentar abordar algumas dessas regras para te ajudar a decidir entre Gradient Boosting Machines com XGBoost e Redes Neurais com TensorFlow.
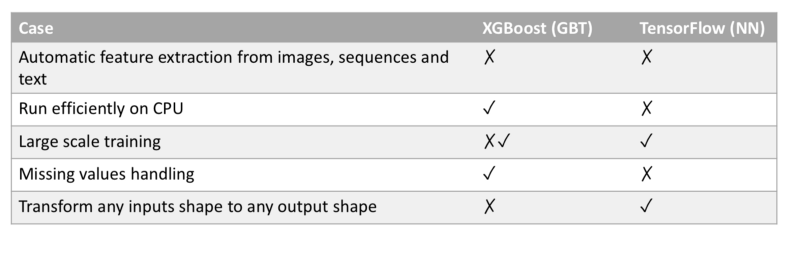 Resumo XGBoost vs TensorFlow
Resumo XGBoost vs TensorFlow
Em 2012, Alex Krizhevsky e seus colegas surpreenderam o mundo com um modelo computacional capaz não só de aprender qual objeto está presente em uma imagem com base em features, como também de fazer a própria extração das features — uma tarefa considerada complexa até para engenheiros "humanos" experientes.
Desde então, as redes neurais profundas dominam o cenário de pesquisa, com inúmeros artigos propondo conceitos revolucionários para reconhecimento de imagens, tradução, jogos de computador e até carros autônomos. Mesmo assim, no popular hub de data science Kaggle, os benchmarks de muitas competições se baseiam em alguma implementação de Gradient Boosting Machines.
Embora o Cloud Machine Learning Engine já ofereça os dois frameworks, nem sempre é óbvio qual algoritmo explorar primeiro. Depois de resolver vários problemas de machine learning usando os dois métodos, juntei algumas reflexões sobre como escolher entre as diferentes abordagens.
Caso 1: Difícil de decompor em features?
Se 2012 nos ensinou alguma coisa, foi que redes neurais são muito eficientes para lidar com dados brutos de alta dimensionalidade. Imagem, vídeo, texto e áudio são exemplos de dados brutos de alta dimensionalidade muito difíceis de pré-processar e representar como features. Nesses casos, usar as unidades de extração de features embutidas nas NNs (CNNs, LSTMs, camadas de Embedding) pode entregar resultados fenomenais em uma fração do tempo de desenvolvimento das abordagens clássicas de engenharia.
 Em vez de extrair features, deixe a rede aprender a representação. https://www.tensorflow.org/images/audio-image-text.png
Em vez de extrair features, deixe a rede aprender a representação. https://www.tensorflow.org/images/audio-image-text.png
Caso 2: Lidando com valores ausentes?
Se você já tentou alimentar uma rede neural com dados faltando, provavelmente acabou tomando erros. Isso acontece porque as equações resolvidas durante o treinamento da NN pressupõem um valor válido para cada variável de entrada.
Já o XGBoost tem sua própria forma de lidar com dados ausentes. Durante o treinamento, ele executa uma subtarefa de aprender a imputar dados para cada feature. Muitos problemas do mundo real têm dados ausentes que, por si só, carregam informações valiosas sobre o alvo. Então, no quesito tratamento "de graça" de valores ausentes, o XGBoost vence.
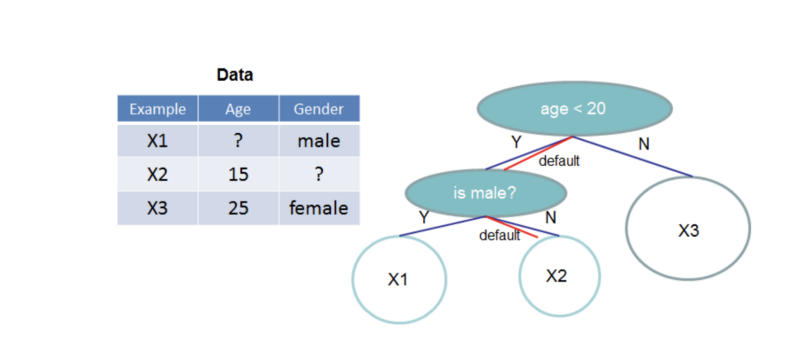 XGBoost: a árvore aprende a lidar com valores ausentes. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
XGBoost: a árvore aprende a lidar com valores ausentes. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
Caso 3: Qual o tamanho do seu bolso?
O treinamento de redes neurais é "embaraçosamente paralelo", o que as torna ótimas para treinamento paralelo e distribuído. Isso, claro, se o seu orçamento aguentar horas de treinamento em máquinas caras com TPUs ou GPUs.
Por outro lado, se você usa apenas alguns milhões de registros no máximo, o XGBoost pode ser treinado em uma CPU multi-core mais barata e convergir em menos tempo. Ou seja, se você tem uma quantidade limitada de dados e quer treinar um modelo, o XGBoost pode sair mais em conta e entregar resultados parecidos.
Cloud TPU v2 Pod — resultados excepcionais no tratamento de datasets massivos
Caso 4: Quantos dados você tem?
O caso anterior nos leva à pergunta sobre quantos dados você tem. Por causa da sua estrutura de dados subjacente, o XGBoost tem limites nas formas em que pode ser paralelizado, o que restringe o volume de dados que ele consegue processar. Uma forma de lidar com datasets massivos é dividir os dados em shards e empilhar (stacking) modelos — multiplicando, na prática, o número de parâmetros usados para ajustar os dados.
Já com redes neurais, geralmente vale o lema "quanto mais, melhor". Ao lidar com datasets massivos, as redes neurais conseguem convergir com o mesmo número de parâmetros para um erro de generalização menor. Mas, para datasets menores, o XGBoost costuma convergir mais rápido e com menor erro.
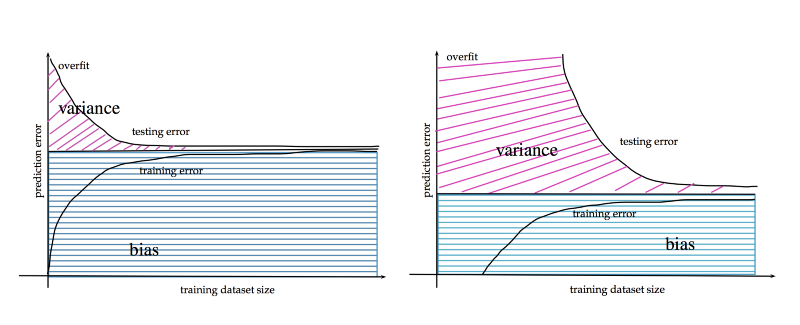 grandes volumes de dados contribuem para um menor erro de generalização. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
grandes volumes de dados contribuem para um menor erro de generalização. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
Caso 5: Qual a complexidade dos formatos de entrada/saída?
O XGBoost tem mais limitações que as NNs quanto ao formato dos dados com os quais consegue trabalhar. Ele normalmente aceita arrays unidimensionais como entrada de cada registro e devolve um único número (regressão) ou um vetor de probabilidades (classificação). Por isso, é mais fácil configurar um pipeline com XGBoost. No XGBoost, você não precisa se preocupar com formatos de dados — basta fornecer um dataframe do pandas que pareça uma tabela, definir a coluna de label e pronto.
Já as redes neurais foram projetadas para operar com tensores — matrizes de alta dimensionalidade. O formato de entrada e saída de uma NN pode variar entre números, sequências (vetores), imagens e até vídeos. Então, para problemas clássicos como predição de cliques com base em dados estruturados, os dois funcionam bem em termos de formato dos dados. Mas, na hora de construir transformações de dados mais complexas, as NNs podem ser sua única opção viável!
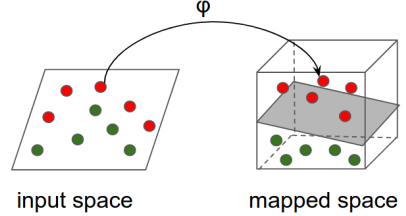 https://www.tensorflow.org/tutorials/representation/kernel_methods
https://www.tensorflow.org/tutorials/representation/kernel_methods
Caso 6: Posso ficar com os dois?
E se você não quiser escolher? Em muitos casos, a combinação dos dois modelos pode entregar resultados melhores do que cada modelo separadamente. Já mencionei stacking de modelos neste post. A diferença matemática entre os modelos gera uma distribuição de erro diferente sobre os mesmos dados. Ao empilhar os modelos, dá para obter uma taxa de erro menor usando a mesma quantidade de dados — só que ao custo de tornar a engenharia do sistema mais complexa.
Gostaria de agradecer ao Philip Tannor pelos comentários perspicazes.
Quer mais histórias? Confira nosso blog ou siga o Gad no Twitter.