
XGBoost e TensorFlow sono due framework di machine learning molto potenti: come capire quale fa al caso suo? O forse servono entrambi?
Nel machine learning non esistono "pasti gratis". Abbinare algoritmi specifici a problemi specifici dà spesso risultati migliori rispetto all'approccio "unico per tutti". Negli anni, però, la community della data science ha accumulato esperienza a sufficienza per definire alcune regole pratiche su come associare determinati algoritmi alle tipologie di problemi più ricorrenti.
In questo breve articolo proverò a illustrare alcune di queste regole, per aiutarla a scegliere tra le Gradient Boosting Machines con XGBoost e le reti neurali con TensorFlow.
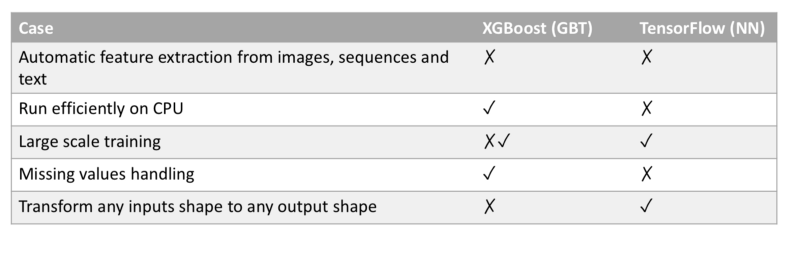 XGBoost vs TensorFlow: il confronto in sintesi
XGBoost vs TensorFlow: il confronto in sintesi
Nel 2012 Alex Krizhevsky e i suoi colleghi sbalordirono il mondo con un modello computazionale capace non solo di imparare a riconoscere quale oggetto fosse presente in un'immagine sulla base delle feature, ma anche di eseguire autonomamente l'estrazione delle feature stesse: un compito ritenuto complesso anche per ingegneri "umani" esperti.
Da allora, le reti neurali profonde hanno dominato il panorama della ricerca, con una valanga di articoli che propongono concetti rivoluzionari per il riconoscimento delle immagini, la traduzione, i videogiochi e perfino le auto a guida autonoma. Eppure, sul popolarissimo hub di data science Kaggle, i benchmark di molte competizioni si basano su qualche implementazione delle Gradient Boosting Machines.
Anche se Cloud Machine Learning Engine oggi offre entrambi i framework, non è sempre chiaro da quale algoritmo convenga partire. Dopo aver affrontato numerosi problemi di machine learning con entrambi i metodi, ho messo insieme alcune riflessioni su come orientarsi tra i due approcci.
Caso 1: difficile scomporre il problema in feature?
Se c'è una lezione che abbiamo imparato dal 2012, è che le reti neurali sono estremamente efficaci nel gestire dati grezzi ad alta dimensionalità. Immagini, video, testo e audio sono tutti esempi di dati grezzi ad alta dimensionalità, molto difficili da preprocessare e rappresentare come feature. In questi casi, sfruttare le unità di estrazione delle feature integrate nelle NN (CNN, LSTM, layer di embedding) consente di ottenere risultati straordinari in una frazione del tempo richiesto dagli approcci ingegneristici tradizionali.
 Anziché estrarre le feature, lasci che sia la rete a imparare la rappresentazione. https://www.tensorflow.org/images/audio-image-text.png
Anziché estrarre le feature, lasci che sia la rete a imparare la rappresentazione. https://www.tensorflow.org/images/audio-image-text.png
Caso 2: gestione dei valori mancanti?
Se ha mai provato a passare a una rete neurale dei dati con valori mancanti, con tutta probabilità si è ritrovato pieno di errori. Le equazioni risolte durante il training di una NN, infatti, presuppongono un valore valido per ogni variabile di input.
XGBoost, al contrario, ha un proprio modo di gestire i dati mancanti. Durante il training esegue un sotto-task in cui impara a imputare i dati per ciascuna feature. Molti problemi reali presentano dati mancanti che, di per sé, contengono informazioni preziose sul target. Quindi, sulla gestione "gratuita" dei valori mancanti, XGBoost ha la meglio.
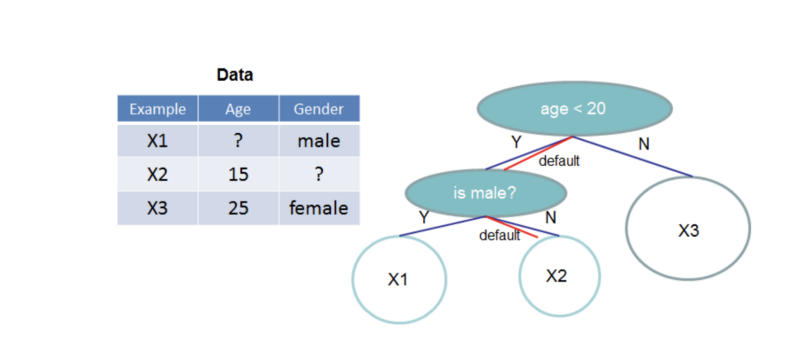 In XGBoost l'albero impara da solo a gestire i valori mancanti. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
In XGBoost l'albero impara da solo a gestire i valori mancanti. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016
Caso 3: quanto è capiente il suo budget?
Il training delle reti neurali è "embarrassingly parallel": una caratteristica che lo rende perfetto per il calcolo parallelo e distribuito. Sempre che il budget regga ore di training su macchine costose dotate di TPU o GPU.
D'altro canto, se utilizza al massimo qualche milione di record, XGBoost può essere addestrato su una CPU multi-core meno costosa e arrivare a convergenza in meno tempo. Quindi, se ha a disposizione una quantità limitata di dati e vuole addestrare un modello, XGBoost può rivelarsi più conveniente e produrre risultati comparabili.
Cloud TPU v2 Pod: risultati eccezionali nella gestione di dataset di grandi dimensioni
Caso 4: di quanti dati dispone?
Il punto precedente ci porta alla domanda: di quanti dati dispone? Per via della sua struttura dati interna, XGBoost ha dei limiti nelle modalità di parallelizzazione, e questo ne riduce la capacità di elaborare grandi volumi. Un modo per gestire dataset enormi è suddividere i dati in shard e ricorrere allo stacking dei modelli, moltiplicando di fatto il numero di parametri impiegati per il fitting.
Con le reti neurali, invece, di solito vale il principio "più ce n'è, meglio è". Quando si lavora con dataset enormi, le reti neurali, a parità di parametri, riescono a convergere a un errore di generalizzazione più basso. Sui dataset più piccoli, però, XGBoost in genere converge più rapidamente e con un errore inferiore.
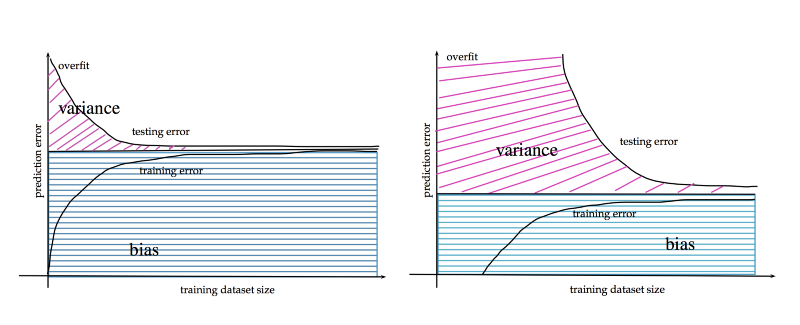 una grande quantità di dati contribuisce a ridurre l'errore di generalizzazione. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
una grande quantità di dati contribuisce a ridurre l'errore di generalizzazione. http://www.stats.ox.ac.uk/~sejdinov/teaching/sdmml15/materials/HT15_lecture12-nup.pdf
Caso 5: quanto sono complesse le shape di input/output?
XGBoost ha più limitazioni delle NN sulla forma dei dati con cui può lavorare. Di solito accetta in input array monodimensionali e restituisce un singolo numero (regressione) o un vettore di probabilità (classificazione). Per questo motivo, configurare una pipeline XGBoost è più semplice. Con XGBoost non occorre preoccuparsi delle shape dei dati: basta fornire un dataframe pandas simile a una tabella, impostare la colonna delle label e si è pronti a partire.
Le reti neurali, invece, sono progettate per lavorare sui tensori, matrici ad alta dimensionalità. La shape di input e output di una NN può spaziare tra numeri, sequenze (vettori), immagini e perfino video. Per problemi classici come la previsione del click-through basata su dati strutturati, quindi, entrambi possono funzionare bene, almeno in termini di shape dei dati. Ma quando si tratta di costruire trasformazioni più complesse, le NN possono essere l'unica scelta praticabile!
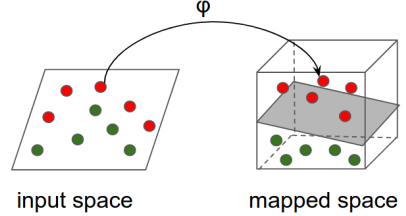 https://www.tensorflow.org/tutorials/representation/kernel_methods
https://www.tensorflow.org/tutorials/representation/kernel_methods
Caso 6: posso usarli entrambi, per favore?
E se non volesse scegliere? In molti casi, la combinazione dei due modelli può dare risultati migliori rispetto a ciascuno preso singolarmente. Ho già accennato in questo articolo allo stacking dei modelli. La differenza matematica tra i due si traduce in una distribuzione dell'errore diversa sugli stessi dati. Facendo stacking si può ottenere un tasso d'errore più basso a parità di dati, al prezzo però di una maggiore complessità ingegneristica del sistema.
Vorrei ringraziare Philip Tannor per i suoi preziosi commenti.
Vuole leggere altri articoli? Visiti il nostro blog oppure segua Gad su Twitter.