L'IA n'est plus un projet annexe. Partout, les équipes font tourner de grands modèles de langage (LLM), des pipelines d'entraînement et des serveurs d'inférence sur Kubernetes. Et dès qu'un workload réclame un GPU, les choses se compliquent vite.
Les GPU et TPU sont coûteux et difficiles à obtenir. Pendant longtemps, Kubernetes s'est appuyé sur le framework Device Plugin pour les gérer. Ce framework a vu le jour à une époque où les workloads Kubernetes étaient relativement simples et se contentaient de demander un GPU, que le système fournissait. Les workloads d'IA d'aujourd'hui sont nettement plus complexes. Dès que l'on introduit des types de GPU mixtes, des topologies NVLink ou des exigences spécifiques en VRAM, les Device Plugins s'effondrent et imposent une configuration manuelle considérable.
Dynamic Resource Allocation (DRA) est la réponse de Kubernetes à ces limites. Fini l'ancien modèle où les nœuds annonçaient un nombre fixe de matériels que le scheduler revendiquait à l'aveugle : DRA introduit un modèle d'allocation basé sur des requêtes. Les workloads décrivent ce dont ils ont besoin, et le control plane de DRA se charge d'y répondre à l'échelle du cluster. Ce changement déplace la connaissance du matériel des agents de chaque nœud vers une API centralisée et expressive.
Lors de la KubeCon Europe 2026, NVIDIA a fait don de son pilote DRA pour GPU à la CNCF, et Google a annoncé la publication open source du pilote DRA pour TPU. Loin d'être de simples gestes communautaires, ces annonces montrent que les deux principaux fournisseurs de matériel pour l'IA ont pleinement adopté DRA comme interface standard de gestion du matériel dans Kubernetes. Pour les équipes plateforme, cela veut dire en finir avec les contournements propriétaires et la logique d'ordonnancement spécifique à chaque fournisseur. Les mêmes primitives DRA fonctionnent désormais de façon fiable, que vous utilisiez des GPU NVIDIA, des TPU Google, ou les deux dans un même cluster.
L'ancienne approche : les Device Plugins et leurs limites
Avant DRA, pour qu'un pod utilise un GPU, il fallait ajouter quelque chose comme ceci à sa spec :
resources: limits: nvidia.com/gpu: 1Cette simple requête en nombre entier posait trois problèmes majeurs :
1. Absence de sélection par attributs et de prise en charge native des GPU fractionnés
Les Device Plugins prenaient en charge nativement le comptage entier de base (par exemple 1 GPU) — et aucun GPU fractionné ! Il existe bien des contournements comme le Time-Slicing de NVIDIA ou le Multi-Instance GPU (MIG) pour partager les ressources matérielles, mais ils restent des bricolages externes que le scheduler Kubernetes ne comprend pas vraiment. Impossible également de demander des ressources selon des attributs précis, du type un GPU avec au moins 40 Go de VRAM ou un GPU d'une architecture donnée. Résultat : des workloads souvent affectés à du matériel sous-dimensionné ou incompatible.
2. Surcharge d'orchestration manuelle
Les Device Plugins ne fournissent au scheduler Kubernetes aucune information utile sur le matériel. Faute d'une visibilité matérielle granulaire, les administrateurs étaient contraints d'associer manuellement les workloads à des nœuds spécifiques via des labels codés en dur. Cette approche ne passe pas à l'échelle dans de grands clusters : elle exige des mises à jour manuelles permanentes à chaque ajout, retrait ou mise hors service de matériel.
3. Contraintes de provisionnement statique
Les Device Plugins exigeaient que le matériel soit préconfiguré et disponible avant le démarrage d'une tâche. Aucun mécanisme ne permettait une allocation dynamique just-in-time, ni la recherche et l'initialisation de matériel en réponse à une demande en attente.
Place à Dynamic Resource Allocation (DRA) : le nouveau standard pour le matériel d'IA
Dynamic Resource Allocation (DRA) est le nouveau standard Kubernetes pour gérer le matériel spécialisé. Son objectif principal : découpler la gestion des ressources du scheduler central de Kubernetes. Au lieu d'obliger l'utilisateur à identifier des nœuds précis ou à étiqueter manuellement le matériel, DRA laisse le workload définir ses besoins. Le système identifie alors dynamiquement, revendique et prépare le matériel optimal à l'échelle de tout le cluster.
DRA repose sur trois concepts clés.
1. DeviceClass — abstractions pour les équipes plateforme
Un DeviceClass est un modèle défini par les équipes plateforme ou les administrateurs du cluster. Plutôt que d'exiger des développeurs qu'ils maîtrisent les spécificités matérielles, les administrateurs créent des classes nommées comme high-memory-gpu ou low-latency-fpga. Les développeurs n'ont plus qu'à demander une classe par son nom, et le scheduler se charge du reste.
2. ResourceSlice — ce qui est disponible
Voyez un ResourceSlice comme un inventaire matériel représentant un ou plusieurs devices dans un pool. Les pilotes DRA (comme le pilote GPU de NVIDIA ou le pilote TPU de Google) publient des informations détaillées sur les devices de chaque nœud. Pas seulement ce nœud a 4 GPU, mais des données riches, par exemple :
- Mémoire GPU totale (VRAM)
- Architecture et modèle matériel
- Le complexe racine PCIe ou le nœud NUMA hébergeant le device
- Nombre de cœurs de calcul
C'est là tout le changement : des détails matériels jusqu'ici invisibles deviennent pleinement exploitables par le scheduler.
3. ResourceClaim — ce dont vous avez besoin
Un ResourceClaim décrit les exigences de votre workload. C'est là que DRA prend toute sa puissance. Au lieu de demander 1 GPU, vous pouvez désormais formuler des requêtes telles que :
- Un GPU avec au moins 40 Go de VRAM
- Un GPU et une carte réseau haut débit sur le même nœud NUMA
- Un accélérateur correspondant à la classe
high-memory-gpu
Le scheduler lit cette requête, parcourt l'ensemble des ResourceSlices publiés dans le cluster et trouve automatiquement la meilleure correspondance.
Exemple concret : exécuter vLLM avec DRA
Imaginons un serveur d'inférence pour grand modèle de langage tournant avec vLLM. Il vous faut un GPU avec beaucoup de VRAM, et vous voulez un ordonnancement automatique, sans épingler manuellement les nœuds. Avec DRA, votre configuration peut ressembler à ceci :
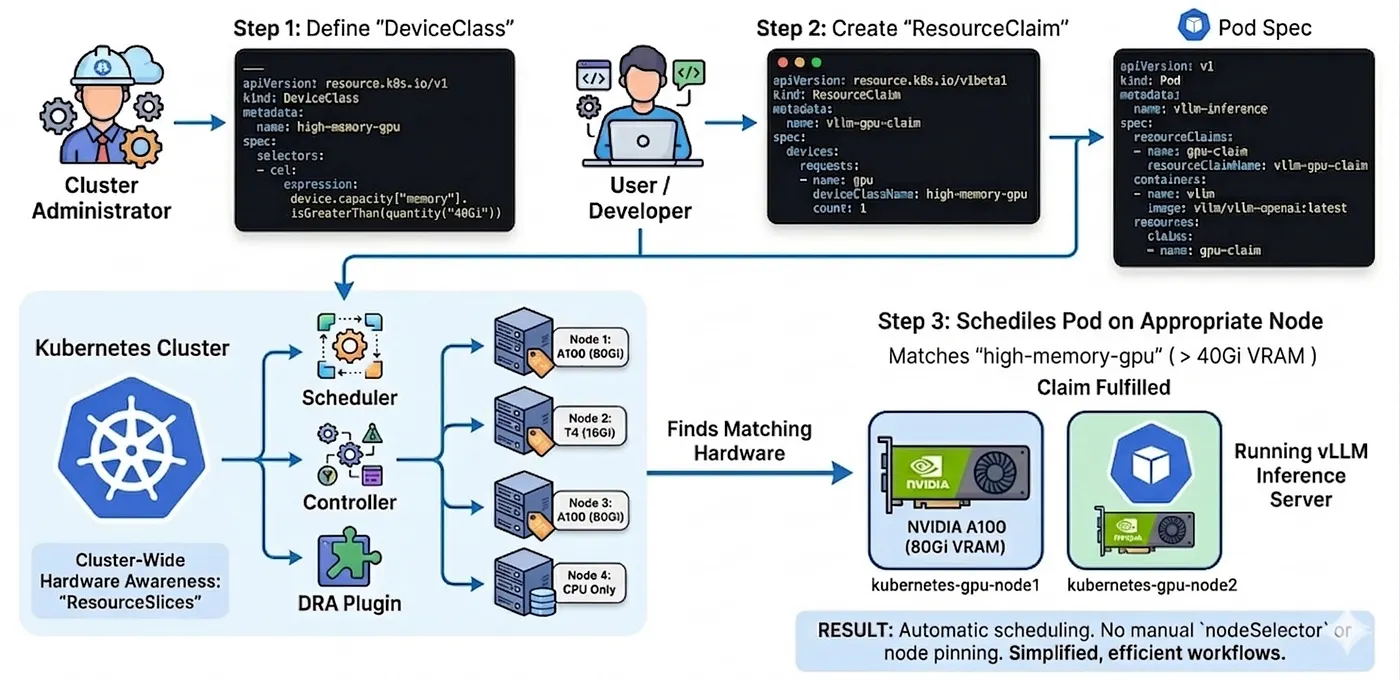
Étape 1 : l'administrateur du cluster crée une DeviceClass
Cette classe filtre tous les GPU dotés de plus de 40 Go de mémoire à l'aide d'un filtre Common Expression Language (CEL).
---apiVersion: resource.k8s.io/v1kind: DeviceClassmetadata: name: high-memory-gpuspec: selectors: - cel: expression: device.capacity["memory"].isGreaterThan(quantity("40Gi"))Étape 2 : créez un ResourceClaim dans votre spec de pod
L'utilisateur demande un device issu de cette classe précise.
apiVersion: resource.k8s.io/v1kind: ResourceClaimmetadata: name: vllm-gpu-claimspec: devices: requests: - name: gpu deviceClassName: high-memory-gpu count: 1Étape 3 : référencez la claim dans votre pod
Enfin, le Pod se contente de pointer vers la claim. Aucun nodeSelector, aucune règle d'affinité complexe à définir.
apiVersion: v1kind: Podmetadata: name: vllm-inferencespec: resourceClaims: - name: gpu-claim resourceClaimName: vllm-gpu-claim containers: - name: vllm image: vllm/vllm-openai:latest resources: claims: - name: gpu-claimC'est tout. Vous avez décrit votre besoin. Kubernetes — désormais doté d'une visibilité complète sur le matériel de chaque nœud via les ResourceSlices — trouve un nœud adapté et y planifie votre pod. Pas de nodeSelector. Pas de chasse via kubectl get nodes.
La valeur stratégique de DRA
DRA garantit des performances optimales en supprimant les erreurs de configuration manuelle et les goulets d'étranglement matériels.
- Pour les développeurs : finie la chasse aux nœuds. Décrivez les exigences matérielles de votre code, et laissez Kubernetes gérer la découverte et le rattachement.
- Pour les équipes plateforme : créez des paliers de matériel via les DeviceClasses et exposez-les, sans donner à tout le monde un accès brut aux labels de nœud ni aux specs matérielles.
- Pour les opérations : l'utilisation des ressources progresse. Mieux informé, le scheduler prend de meilleures décisions de placement, ce qui réduit la fragmentation, diminue le nombre de GPU inactifs et améliore le ROI sur un matériel coûteux.
- Pour l'IA à grande échelle : DRA est déjà la fondation du programme Kubernetes AI Conformance. Ce n'est plus une fonctionnalité optionnelle : c'est devenu le standard du secteur.
En conclusion
Kubernetes a évolué : de simple hôte de serveurs web et de microservices, il est devenu la plateforme de prédilection pour certains des workloads d'IA les plus exigeants. Cette progression enthousiasmante s'accompagne toutefois de nouveaux défis d'infrastructure, en particulier pour gérer du matériel spécialisé comme les GPU, les TPU et les équipements réseau haut débit.
Le framework Device Plugin a rempli son rôle, mais il a été pensé pour une époque plus simple. DRA est taillé pour notre environnement actuel : des clusters au matériel hétérogène et coûteux, des workloads aux besoins précis et complexes, et des équipes qui doivent avancer vite sans devenir expertes en topologie matérielle.
Pour aller plus loin, voici les meilleurs points de départ :