AI ist längst kein Nebenprojekt mehr. Überall betreiben Teams Large Language Models (LLMs), Trainings-Pipelines und Inferenz-Server auf Kubernetes. Und sobald Ihre workloads eine GPU brauchen, wird es schnell kompliziert.
GPUs und TPUs sind teuer und schwer zu beschaffen. Lange Zeit verwaltete Kubernetes sie über das Device-Plugin-Framework. Dieses Framework entstand zu einer Zeit, in der Kubernetes-workloads vergleichsweise einfach waren und im Wesentlichen nur "eine GPU" anforderten, die das System dann bereitstellte. Moderne AI-workloads sind jedoch deutlich komplexer. Sobald gemischte GPU-Typen, NVLink-Topologien oder spezifische VRAM-Anforderungen ins Spiel kommen, stoßen Device Plugins an ihre Grenzen und erfordern aufwendige manuelle Konfiguration.
Dynamic Resource Allocation (DRA) ist die Antwort von Kubernetes auf diese Schwächen. Statt des alten Modells, in dem Nodes feste Hardware-Mengen meldeten und der Scheduler diese blind beanspruchte, setzt DRA auf ein anforderungsbasiertes Zuweisungsmodell. workloads beschreiben, was sie brauchen, und die Control Plane von DRA findet heraus, wie sich dieser Anspruch im gesamten Cluster erfüllen lässt. Damit wandert das Hardware-Wissen aus den einzelnen Node-Agents in eine zentrale, ausdrucksstarke API.
Auf der KubeCon Europe 2026 hat NVIDIA seinen DRA-GPU-Treiber an die CNCF gespendet, und Google kündigte das Open-Source-Release des DRA-TPU-Treibers an. Das waren keine bloßen Goodwill-Gesten an die Community, sondern ein klares Signal: Die beiden führenden AI-Hardware-Anbieter haben DRA vollständig als Standardschnittstelle für die Hardware-Verwaltung in Kubernetes übernommen. Für Plattform-Teams heißt das: Sie sind nicht länger auf herstellerspezifische Workarounds oder proprietäre Scheduling-Logik angewiesen. Dieselben DRA-Primitive funktionieren zuverlässig – egal ob Sie NVIDIA-GPUs, Google-TPUs oder beides im selben Cluster einsetzen.
Der alte Weg: Device Plugins und ihre Schwachstellen
Wollten Sie vor DRA eine GPU im Pod nutzen, mussten Sie Folgendes in die Pod-Spec aufnehmen:
resources: limits: nvidia.com/gpu: 1Dieser simple Integer-Request brachte drei massive Probleme mit sich:
1. Keine attributbasierte Auswahl und keine native Unterstützung für GPU-Bruchteile
Device Plugins unterstützten nativ nur einfaches Integer-Counting (z. B. "1 GPU") und keinerlei GPU-Bruchteile. Es gibt zwar Workarounds wie NVIDIAs Time-Slicing oder Multi-Instance GPU (MIG), um Hardware-Ressourcen aufzuteilen, doch diese bleiben externe "Hacks", die der Kubernetes-Scheduler nicht wirklich versteht. Auch fehlte die Möglichkeit, Ressourcen anhand bestimmter Attribute anzufordern – etwa "Ich brauche eine mit mindestens 40 GB VRAM" oder "Ich brauche eine bestimmte Architektur". Die Folge: workloads landeten häufig auf zu schwacher oder inkompatibler Hardware.
2. Manueller Orchestrierungsaufwand
Device Plugins liefern dem Kubernetes-Scheduler keinerlei nützliche Hardware-Informationen. Da dem Scheduler das feingranulare Hardware-Wissen fehlte, mussten Administratoren workloads über fest codierte Labels manuell bestimmten Nodes zuweisen. Dieses Vorgehen skaliert in großen Clustern nicht und erfordert ständige manuelle Anpassungen, sobald Hardware hinzugefügt, entfernt oder ausgemustert wird.
3. Statische Provisionierung
Device Plugins setzten voraus, dass Hardware bereits konfiguriert und verfügbar war, bevor eine Aufgabe startete. Es gab weder einen Mechanismus für eine dynamische, "Just-in-time"-Ressourcenzuweisung noch eine Möglichkeit, dass das System Hardware auf Anfrage hin sucht und initialisiert.
Auftritt für Dynamic Resource Allocation (DRA): Der neue Standard für AI-Hardware
Dynamic Resource Allocation (DRA) ist der neue Kubernetes-Standard für die Verwaltung spezialisierter Hardware. Hauptziel von DRA ist es, das Ressourcenmanagement vom Kern-Scheduler von Kubernetes zu entkoppeln. Statt dass Anwender bestimmte Nodes identifizieren oder Hardware manuell taggen, kann der Workload seine Anforderungen über DRA selbst definieren. Das System identifiziert, beansprucht und bereitet anschließend dynamisch die optimale Hardware im gesamten Cluster vor.
DRA bringt drei zentrale Konzepte mit, die das möglich machen.
1. DeviceClass — Abstraktionen für Plattform-Teams
Eine DeviceClass ist ein Bauplan, den Plattform- oder Cluster-Admins definieren. Statt Entwicklern Hardware-Details aufzubürden, können Admins benannte Klassen wie high-memory-gpu oder low-latency-fpga anlegen. Entwickler fordern einfach eine Klasse über ihren Namen an – den Rest erledigt der Scheduler.
2. ResourceSlice — Was verfügbar ist
Einen ResourceSlice können Sie sich als Hardware-Inventarbericht vorstellen, der ein oder mehrere Devices in einem Pool abbildet. DRA-Treiber (etwa der NVIDIA-GPU-Treiber oder Googles TPU-Treiber) veröffentlichen detaillierte Informationen zu den Geräten auf jedem Node. Nicht nur "dieser Node hat 4 GPUs", sondern reichhaltige Details wie:
- Gesamter GPU-Speicher (VRAM)
- Architektur und Hardware-Modell
- An welchem PCIe-Root-Komplex oder NUMA-Node das Gerät hängt
- Anzahl der Compute-Cores
Das ist der entscheidende Wandel: Hardware-Details, die früher verborgen waren, sind jetzt für den Scheduler vollständig sichtbar.
3. ResourceClaim — Was Sie brauchen
Über einen ResourceClaim beschreiben Sie die Anforderungen Ihrer workloads. Hier zeigt DRA seine Stärke. Statt nach "1 GPU" zu fragen, können Sie jetzt zum Beispiel sagen:
- Ich brauche eine GPU mit mindestens 40 GB VRAM
- Ich brauche eine GPU und eine Hochgeschwindigkeits-NIC am selben NUMA-Node
- Ich brauche einen Beschleuniger, der zur Klasse
high-memory-gpupasst
Der Scheduler liest diesen Claim, prüft alle clusterweit veröffentlichten ResourceSlices und findet automatisch die beste Übereinstimmung.
Praxisbeispiel: vLLM mit DRA betreiben
Nehmen wir an, Sie betreiben einen Inferenz-Server für ein Large Language Model mit vLLM. Sie brauchen eine GPU mit reichlich VRAM, und das Scheduling soll automatisch laufen – ohne manuelles Node-Pinning. Mit DRA könnte Ihr Setup etwa so aussehen:
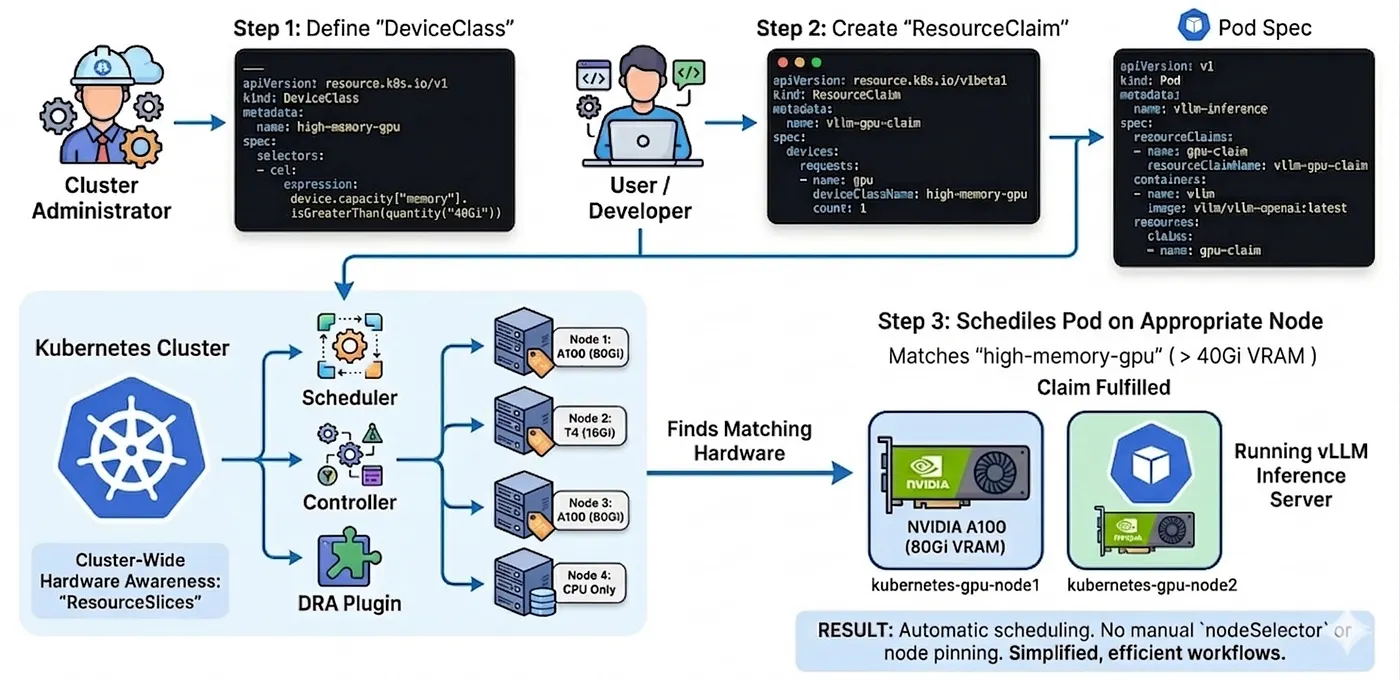
Schritt 1: Der Cluster-Admin legt eine DeviceClass an
Diese Klasse filtert per Common Expression Language (CEL) auf jede GPU mit mehr als 40 GB Speicher.
---apiVersion: resource.k8s.io/v1kind: DeviceClassmetadata: name: high-memory-gpuspec: selectors: - cel: expression: device.capacity["memory"].isGreaterThan(quantity("40Gi"))Schritt 2: Sie erstellen einen ResourceClaim für Ihre Pod-Spec
Der Anwender fordert ein Gerät aus dieser konkreten Klasse an.
apiVersion: resource.k8s.io/v1kind: ResourceClaimmetadata: name: vllm-gpu-claimspec: devices: requests: - name: gpu deviceClassName: high-memory-gpu count: 1Schritt 3: Den Claim im Pod referenzieren
Zum Schluss verweist der Pod einfach auf den Claim. Kein nodeSelector, keine komplexen Affinity-Regeln nötig.
apiVersion: v1kind: Podmetadata: name: vllm-inferencespec: resourceClaims: - name: gpu-claim resourceClaimName: vllm-gpu-claim containers: - name: vllm image: vllm/vllm-openai:latest resources: claims: - name: gpu-claimDas war's. Sie haben beschrieben, was Sie brauchen. Kubernetes – jetzt mit voller Sicht auf die Hardware jedes Nodes über ResourceSlices – findet einen passenden Node und scheduled Ihren Pod dorthin. Kein nodeSelector. Kein Suchen mit kubectl get nodes.
Der strategische Mehrwert von DRA
DRA stellt sicher, dass Sie die volle Performance herausholen, weil manuelle Konfigurationsfehler und Hardware-Engpässe wegfallen.
- Für Entwickler: Schluss mit dem manuellen Node-Hunting. Definieren Sie die Hardware-Anforderungen Ihres Codes und überlassen Sie Kubernetes die Auswahl und Anbindung.
- Für Plattform-Teams: Mit DeviceClasses lassen sich Hardware-"Tiers" anlegen und gezielt bereitstellen, ohne allen direkten Zugriff auf Node-Labels und Hardware-Spezifikationen geben zu müssen.
- Für den Betrieb: Die Ressourcennutzung verbessert sich. Der Scheduler verfügt über bessere Informationen – das bedeutet bessere Platzierungsentscheidungen, weniger Fragmentierung, weniger ungenutzte GPUs und einen besseren ROI für teure Hardware.
- Für AI im großen Maßstab: DRA ist bereits die Grundlage des Kubernetes AI Conformance Program. Es ist kein optionales Feature mehr, sondern hat sich zum Industriestandard entwickelt.
Fazit
Kubernetes hat sich vom reinen Host für Webserver und Microservices zur bevorzugten Plattform für einige der anspruchsvollsten AI-workloads entwickelt. Dieser spannende Fortschritt bringt jedoch auch neue Infrastruktur-Herausforderungen mit sich – vor allem beim Management spezialisierter Hardware wie GPUs, TPUs und Hochgeschwindigkeits-Netzwerkgeräten.
Das Device-Plugin-Framework hat seinen Zweck erfüllt, war aber für eine einfachere Zeit gedacht. DRA ist auf das heutige Umfeld zugeschnitten: Cluster mit vielfältiger, teurer Hardware, workloads mit spezifischen und komplexen Anforderungen und Teams, die schnell vorankommen müssen, ohne zu Experten für Hardware-Topologie zu werden.
Wenn Sie tiefer einsteigen möchten, hier die besten Anlaufstellen: