La IA dejó de ser un proyecto secundario. En todas partes, los equipos están corriendo modelos de lenguaje grandes (LLMs), pipelines de entrenamiento y servidores de inferencia sobre Kubernetes. Y cuando tu workload necesita una GPU, la cosa se complica rápido.
Las GPUs y TPUs son caras y difíciles de conseguir, y durante mucho tiempo Kubernetes usó el framework de Device Plugin para gestionarlas. Ese framework nació en una época en la que los workloads de Kubernetes eran relativamente simples y solo pedían "una GPU", que el sistema entregaba sin más. Pero los workloads de IA actuales son mucho más complejos. En cuanto entran en juego tipos mixtos de GPU, topologías NVLink o requisitos específicos de VRAM, los Device Plugins se quedan cortos y obligan a una configuración manual interminable.
Dynamic Resource Allocation (DRA) es la respuesta de Kubernetes a estas limitaciones. En vez del modelo anterior, donde los nodos publicaban conteos fijos de hardware y el scheduler los reclamaba a ciegas, DRA propone un modelo de asignación basado en solicitudes. Los workloads describen qué necesitan, y el plano de control de DRA se encarga de resolver esa solicitud en todo el cluster. Con este cambio, el conocimiento del hardware se traslada de los agentes de cada nodo a una API centralizada y expresiva.
En KubeCon Europe 2026, NVIDIA donó su driver DRA para GPU a la CNCF, y Google anunció el lanzamiento open source del driver DRA para TPU. No fueron simples gestos de buena voluntad: dejan claro que los dos principales proveedores de hardware para IA adoptaron DRA como la interfaz estándar para gestionar hardware en Kubernetes. Para los equipos de plataforma, esto significa que ya no hace falta depender de soluciones específicas de cada proveedor ni de lógica propietaria de scheduling. Las mismas primitivas de DRA funcionan de manera confiable, ya sea que uses GPUs de NVIDIA, TPUs de Google o ambas en el mismo cluster.
La forma antigua: Device Plugins y sus dolores de cabeza
Antes de DRA, si querías que tu pod usara una GPU, agregabas algo así a la spec del pod:
resources: limits: nvidia.com/gpu: 1Esta simple solicitud entera traía tres dolores de cabeza enormes:
1. Falta de selección por atributos y de soporte nativo para GPUs fraccionarias
De forma nativa, los Device Plugins solo soportaban el conteo entero básico (por ejemplo, "1 GPU") y nada de GPUs fraccionarias. Existen alternativas como el Time-Slicing de NVIDIA o la Multi-Instance GPU (MIG) para repartir los recursos de hardware, pero siguen siendo "hacks" externos que el scheduler de Kubernetes en realidad no entiende. Tampoco había forma de pedir recursos según atributos específicos, como "necesito una con al menos 40 GB de VRAM" o "necesito una de cierta arquitectura". El resultado: workloads asignados a hardware insuficiente o incompatible.
2. Sobrecarga de orquestación manual
Los Device Plugins no le entregan al scheduler de Kubernetes información útil sobre el hardware. Como el scheduler no tenía un conocimiento granular del hardware, los administradores se veían obligados a mapear los workloads a nodos específicos a mano, mediante etiquetas hardcodeadas. Es un enfoque que no escala en clusters grandes, porque exige actualizaciones manuales constantes cada vez que se agrega, retira o da de baja hardware.
3. Restricciones de aprovisionamiento estático
Los Device Plugins requerían que el hardware estuviera preconfigurado y disponible antes de iniciar una tarea. No había ningún mecanismo para una asignación dinámica "just-in-time" de recursos, ni para que el sistema buscara e inicializara hardware en respuesta a una solicitud pendiente.
Llega Dynamic Resource Allocation (DRA): el nuevo estándar para hardware de IA
Dynamic Resource Allocation (DRA) es el nuevo estándar de Kubernetes para gestionar hardware especializado. Su objetivo principal es desacoplar la gestión de recursos del scheduler central de Kubernetes. En lugar de que el usuario identifique nodos específicos o etiquete el hardware a mano, DRA permite que el workload defina sus requisitos. A partir de ahí, el sistema identifica, reclama y prepara dinámicamente el hardware óptimo en todo el cluster.
DRA introduce tres conceptos clave que hacen posible este enfoque.
1. DeviceClass — abstracciones para los equipos de plataforma
DeviceClass es un blueprint que definen los administradores de plataforma o de cluster. En vez de obligar a los desarrolladores a conocer los detalles del hardware, los administradores pueden crear clases con nombre como high-memory-gpu o low-latency-fpga. Los desarrolladores solo piden una clase por su nombre y el scheduler hace el resto.
2. ResourceSlice — qué hay disponible
Piensa en un ResourceSlice como un reporte de inventario de hardware que representa uno o más devices en un pool. Los drivers de DRA (como el de GPU de NVIDIA o el de TPU de Google) publican información detallada sobre los devices de cada nodo. No solo "este nodo tiene 4 GPUs", sino detalles completos como:
- Memoria total de la GPU (VRAM)
- Arquitectura y modelo de hardware
- En qué root complex de PCIe o nodo NUMA reside el device
- Cantidad de núcleos de cómputo
Este es el cambio clave: los detalles del hardware que antes estaban ocultos ahora son totalmente visibles para el scheduler.
3. ResourceClaim — qué necesitas
Un ResourceClaim es la forma de describir los requisitos de tu workload. Aquí es donde DRA muestra todo su potencial. En lugar de pedir "1 GPU", ahora puedes decir cosas como:
- Necesito una GPU con al menos 40 GB de VRAM
- Necesito una GPU y una NIC de alta velocidad que estén en el mismo nodo NUMA
- Necesito un acelerador que coincida con la clase
high-memory-gpu
El scheduler lee este claim, revisa todos los ResourceSlices publicados en el cluster y encuentra automáticamente la mejor coincidencia.
Ejemplo del mundo real: correr vLLM con DRA
Supón que estás corriendo un servidor de inferencia para un modelo de lenguaje grande con vLLM. Necesitas una GPU con bastante VRAM y quieres que el scheduling sea automático, sin tener que fijar nodos a mano. Con DRA, tu configuración podría verse así:
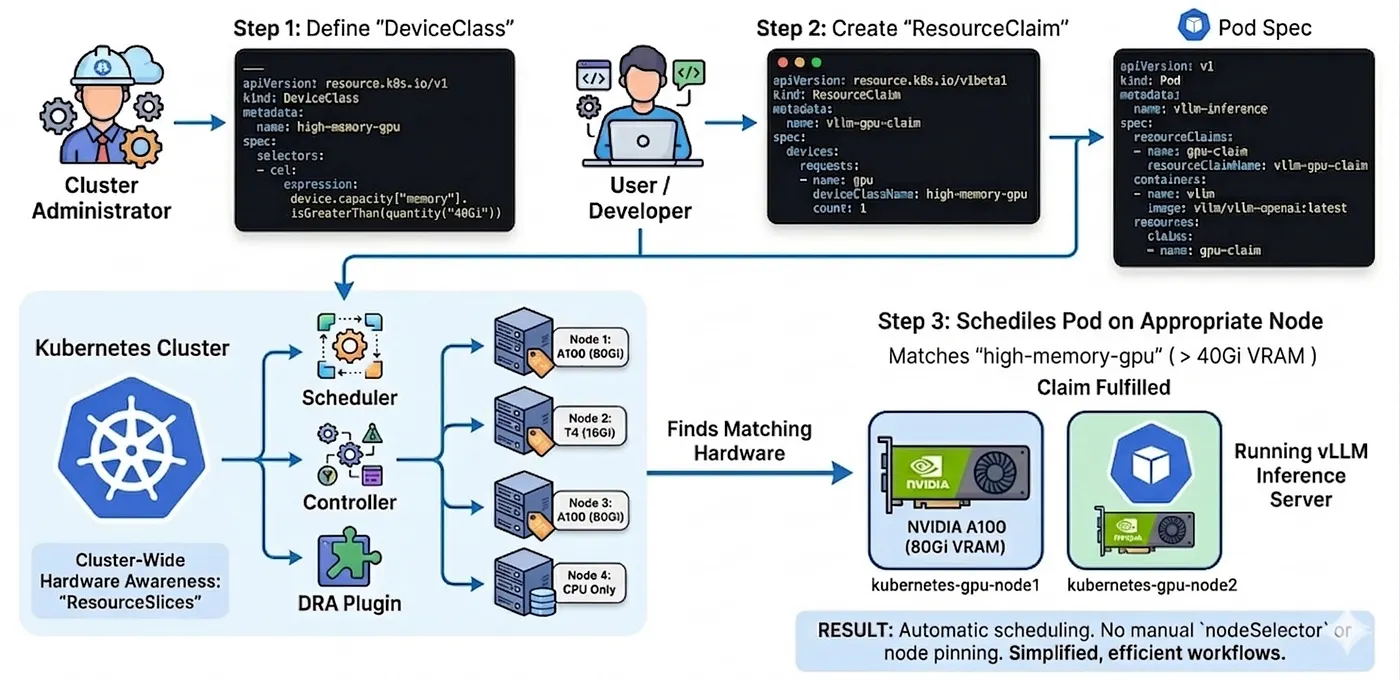
Paso 1: el administrador del cluster crea una DeviceClass
Esta clase filtra cualquier GPU con más de 40 GB de memoria usando un filtro de Common Expression Language (CEL).
---apiVersion: resource.k8s.io/v1kind: DeviceClassmetadata: name: high-memory-gpuspec: selectors: - cel: expression: device.capacity["memory"].isGreaterThan(quantity("40Gi"))Paso 2: creas un ResourceClaim para la spec de tu pod
El usuario solicita un device de esa clase específica.
apiVersion: resource.k8s.io/v1kind: ResourceClaimmetadata: name: vllm-gpu-claimspec: devices: requests: - name: gpu deviceClassName: high-memory-gpu count: 1Paso 3: referencia el claim en tu pod
Por último, el Pod simplemente apunta al claim. No hacen falta nodeSelector ni reglas complejas de afinidad.
apiVersion: v1kind: Podmetadata: name: vllm-inferencespec: resourceClaims: - name: gpu-claim resourceClaimName: vllm-gpu-claim containers: - name: vllm image: vllm/vllm-openai:latest resources: claims: - name: gpu-claimEso es todo. Describiste lo que necesitas. Kubernetes —ahora con visibilidad completa del hardware de cada nodo a través de los ResourceSlices— encuentra un nodo adecuado y agenda tu pod ahí. Sin nodeSelector. Sin rastrear nada con kubectl get nodes.
El valor estratégico de DRA
DRA permite aprovechar todo el rendimiento al eliminar errores de configuración manual y cuellos de botella de hardware.
- Para los desarrolladores: se acabó la "caza manual de nodos". Define los requisitos de hardware que necesita tu código y deja que Kubernetes se encargue del descubrimiento y la conexión.
- Para los equipos de plataforma: puedes crear "tiers" de hardware mediante DeviceClasses y exponerlos, sin tener que dar a todo el mundo acceso directo a las etiquetas de node ni a las specs del hardware.
- Para operaciones: mejora la utilización de recursos. El scheduler cuenta con mejor información, lo que se traduce en mejores decisiones de ubicación, menos fragmentación, menos GPUs ociosas y un mejor ROI sobre hardware costoso.
- Para la IA a escala: DRA ya es la base del Kubernetes AI Conformance program. Dejó de ser una característica opcional: se convirtió en el estándar de la industria.
Para cerrar
Kubernetes pasó de alojar servidores web y microservicios a convertirse en la plataforma preferida para algunos de los workloads de IA más exigentes. Pero este avance también trajo nuevos desafíos de infraestructura, sobre todo en la gestión de hardware especializado como GPUs, TPUs y dispositivos de red de alta velocidad.
El framework de Device Plugin cumplió su función, pero fue diseñado para una época más simple. DRA está pensado para el entorno actual: clusters con hardware diverso y costoso, workloads con necesidades específicas y complejas, y equipos que deben moverse rápido sin tener que volverse expertos en topologías de hardware.
Si quieres profundizar más, estos son los mejores puntos de partida: