L'AI non è più un progetto secondario. Ovunque, i team eseguono large language model (LLM), pipeline di training e server di inferenza su Kubernetes. E quando un workload richiede una GPU, le cose si complicano in fretta.
GPU e TPU sono costose e difficili da reperire e, per molto tempo, Kubernetes le ha gestite tramite il framework Device Plugin. Questo framework è nato in un'epoca in cui i workloads su Kubernetes erano relativamente semplici e si limitavano a chiedere "una GPU", che il sistema provvedeva a fornire. I workloads AI moderni, però, sono molto più complessi. Non appena entrano in gioco tipi di GPU misti, topologie NVLink o requisiti specifici di VRAM, i Device Plugin mostrano tutti i loro limiti e impongono una configurazione manuale capillare.
Dynamic Resource Allocation (DRA) è la risposta di Kubernetes a queste lacune. Al posto del vecchio modello in cui i nodi dichiaravano un numero fisso di componenti hardware e lo scheduler li reclamava alla cieca, DRA introduce un modello di allocazione basato sulle richieste. I workloads descrivono ciò di cui hanno bisogno e il control plane di DRA si occupa di soddisfare quella richiesta nell'intero cluster. Questo cambiamento sposta la conoscenza dell'hardware dai singoli agent dei nodi a un'API centralizzata ed espressiva.
Alla KubeCon Europe 2026, NVIDIA ha donato il proprio driver DRA per GPU alla CNCF e Google ha annunciato il rilascio open source del driver DRA per TPU. Non si è trattato di semplici gesti di buona volontà verso la community: dimostrano che i due principali fornitori di hardware AI hanno adottato pienamente DRA come interfaccia standard per gestire l'hardware su Kubernetes. Per i team di piattaforma significa non dover più dipendere da workaround proprietari o da logiche di scheduling specifiche del singolo vendor. Le stesse primitive DRA funzionano in modo affidabile sia che si utilizzino GPU NVIDIA, TPU Google o entrambe nello stesso cluster.
Il vecchio approccio: i Device Plugin e i loro limiti
Prima di DRA, per far sì che un pod usasse una GPU bastava aggiungere qualcosa di simile alla pod spec:
resources: limits: nvidia.com/gpu: 1Questa semplice richiesta numerica generava tre grossi problemi:
1. Nessuna selezione basata sugli attributi né supporto nativo per le GPU frazionarie
I Device Plugin supportavano nativamente solo il conteggio intero di base (es. "1 GPU"), senza alcuna gestione di GPU frazionarie. Esistono soluzioni come il Time-Slicing di NVIDIA o la Multi-Instance GPU (MIG) per suddividere le risorse hardware, ma restano "hack" esterni che lo scheduler di Kubernetes non comprende davvero. Mancava inoltre la possibilità di richiedere risorse in base ad attributi specifici, come "ne serve una con almeno 40 GB di VRAM" o "ne serve una con una determinata architettura". Il risultato? Workloads spesso assegnati a hardware sottodimensionato o incompatibile.
2. Orchestrazione manuale onerosa
I Device Plugin non forniscono allo scheduler di Kubernetes alcuna informazione utile sull'hardware. Senza una conoscenza granulare delle risorse, gli amministratori erano costretti a mappare manualmente i workloads su nodi specifici tramite label hard-coded. Un approccio non scalabile in cluster di grandi dimensioni, perché impone aggiornamenti manuali costanti ogni volta che si aggiunge, rimuove o dismette dell'hardware.
3. Vincoli di provisioning statico
I Device Plugin richiedevano che l'hardware fosse pre-configurato e disponibile prima dell'avvio di un task. Non esisteva alcun meccanismo di allocazione dinamica "just-in-time" delle risorse, né la possibilità per il sistema di cercare e inizializzare l'hardware in risposta a una richiesta in attesa.
Arriva Dynamic Resource Allocation (DRA): il nuovo standard per l'hardware AI
Dynamic Resource Allocation (DRA) è il nuovo standard Kubernetes per la gestione dell'hardware specializzato. L'obiettivo principale di DRA è disaccoppiare la gestione delle risorse dal core dello scheduler Kubernetes. Anziché chiedere all'utente di individuare nodi specifici o etichettare manualmente l'hardware, DRA permette al workload di esprimere i propri requisiti. È poi il sistema a individuare, riservare e preparare dinamicamente l'hardware ottimale nell'intero cluster.
DRA introduce tre concetti chiave che rendono tutto questo possibile.
1. DeviceClass — Astrazioni per i team di piattaforma
DeviceClass è un blueprint definito dagli amministratori della piattaforma o del cluster. Anziché costringere gli sviluppatori a conoscere le specifiche dell'hardware, gli amministratori possono creare classi con nomi parlanti come high-memory-gpu o low-latency-fpga. Gli sviluppatori richiedono semplicemente una classe per nome e lo scheduler pensa al resto.
2. ResourceSlice — Cosa è disponibile
Un ResourceSlice è una sorta di inventario dell'hardware che rappresenta uno o più device all'interno di un pool. I driver DRA (come quello GPU di NVIDIA o quello TPU di Google) pubblicano informazioni dettagliate sui device presenti su ogni nodo. Non solo "questo nodo ha 4 GPU", ma dettagli ricchi come:
- Memoria GPU totale (VRAM)
- Architettura e modello hardware
- Su quale PCIe root complex o nodo NUMA si trova il device
- Numero di compute core
È proprio questo il cambio di paradigma: i dettagli hardware che prima rimanevano nascosti sono ora pienamente visibili allo scheduler.
3. ResourceClaim — Cosa serve
Un ResourceClaim è il modo in cui si descrivono i requisiti del workload. Ed è qui che DRA tira fuori tutta la sua potenza. Invece di chiedere "1 GPU", oggi si può specificare ad esempio:
- Mi serve una GPU con almeno 40 GB di VRAM
- Mi servono una GPU e una NIC ad alta velocità sullo stesso nodo NUMA
- Mi serve un acceleratore corrispondente alla classe
high-memory-gpu
Lo scheduler legge la claim, esamina tutti i ResourceSlice pubblicati nel cluster e trova automaticamente la corrispondenza migliore.
Un esempio concreto: vLLM con DRA
Ipotizziamo di eseguire un server di inferenza per large language model basato su vLLM. Serve una GPU con molta VRAM e si vuole uno scheduling automatico, senza node pinning manuale. Con DRA, la configurazione potrebbe essere simile a questa:
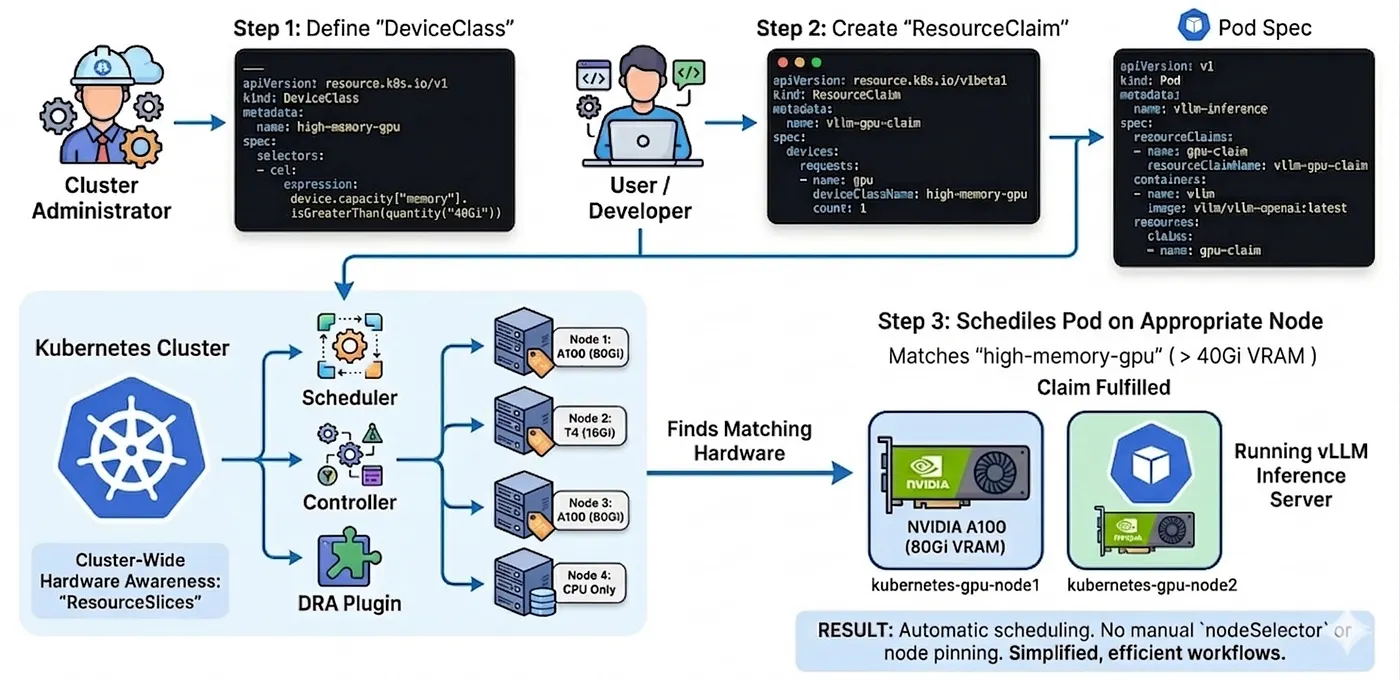
Step 1: l'amministratore del cluster crea una DeviceClass
Questa classe filtra qualsiasi GPU con più di 40 GB di memoria tramite un filtro Common Expression Language (CEL).
---apiVersion: resource.k8s.io/v1kind: DeviceClassmetadata: name: high-memory-gpuspec: selectors: - cel: expression: device.capacity["memory"].isGreaterThan(quantity("40Gi"))Step 2: si crea una ResourceClaim nella pod spec
L'utente richiede un device appartenente a quella classe specifica.
apiVersion: resource.k8s.io/v1kind: ResourceClaimmetadata: name: vllm-gpu-claimspec: devices: requests: - name: gpu deviceClassName: high-memory-gpu count: 1Step 3: si referenzia la claim nel pod
Infine, il Pod si limita a puntare alla claim. Niente nodeSelector, niente regole di affinità complesse.
apiVersion: v1kind: Podmetadata: name: vllm-inferencespec: resourceClaims: - name: gpu-claim resourceClaimName: vllm-gpu-claim containers: - name: vllm image: vllm/vllm-openai:latest resources: claims: - name: gpu-claimTutto qui. Lei descrive ciò che le serve. Kubernetes — ora con piena visibilità sull'hardware di ogni nodo grazie ai ResourceSlice — individua un nodo adatto e vi schedula il pod. Nessun nodeSelector. Nessuna caccia tra i kubectl get nodes.
Il valore strategico di DRA
DRA permette di sfruttare appieno le prestazioni dell'hardware, eliminando errori di configurazione manuale e colli di bottiglia.
- Per gli sviluppatori: basta con la "caccia ai nodi" manuale. Si definiscono i requisiti hardware del proprio codice e Kubernetes si occupa di scoperta e allocazione.
- Per i team di piattaforma: si possono creare "tier" hardware tramite le DeviceClass ed esporli, senza dover dare a tutti accesso diretto alle label dei nodi e alle specifiche hardware.
- Per le operations: l'utilizzo delle risorse migliora. Con informazioni più ricche a disposizione, lo scheduler prende decisioni di placement più accurate, riduce la frammentazione, lascia meno GPU inattive e massimizza il ROI sull'hardware costoso.
- Per l'AI su larga scala: DRA è già la base del programma Kubernetes AI Conformance. Non è più una funzionalità opzionale: è ormai lo standard del settore.
In conclusione
Kubernetes è passato dal semplice hosting di web server e microservizi a piattaforma di riferimento per alcuni dei workloads AI più intensivi. Un'evoluzione entusiasmante che ha però portato con sé nuove sfide infrastrutturali, soprattutto nella gestione di hardware specializzato come GPU, TPU e dispositivi di rete ad alta velocità.
Il framework Device Plugin ha svolto il suo compito, ma era pensato per un'epoca più semplice. DRA è progettato per il contesto di oggi: cluster con hardware eterogeneo e costoso, workloads con esigenze specifiche e complesse, team che devono muoversi rapidamente senza diventare esperti di topologia hardware.
Per approfondire, ecco i punti di partenza migliori: