AIはもはや片手間で取り組むものではありません。世界中のチームが大規模言語モデル (LLM)、トレーニングパイプライン、推論サーバーをKubernetes上で動かしています。そして、workloadがGPUを必要とした瞬間、話は一気に複雑になります。
GPUやTPUは高価で入手も難しく、Kubernetesは長らくこれらの管理に Device Pluginフレームワーク を使ってきました。このフレームワークが開発されたのは、Kubernetesのworkloadが比較的シンプルだった時代です。求められるのはせいぜい「GPUを1基」程度で、システムはそれを供給すれば事足りていました。ところが、現代のAI workloadsははるかに複雑です。GPUの種類が混在したり、NVLinkのトポロジーや特定のVRAM要件が絡んだりすると、Device Pluginsはたちまち破綻し、膨大な手作業の設定を強いられます。
Dynamic Resource Allocation (DRA) は、こうした課題に対するKubernetesからの答えです。ノードが固定的なハードウェア数を公示し、スケジューラがそれをただ確保していく従来のモデルに代わり、DRAはリクエストベースの割り当てモデルを導入します。workloadは「何が必要か」を記述し、DRAのコントロールプレーンがクラスタ全体でその要求をどう満たすかを判断します。これにより、ハードウェアの把握は個々のノードエージェントから、表現力に富んだ中央集約APIへと移されます。
KubeCon Europe 2026では、NVIDIAが DRA GPUドライバ をCNCFに寄贈し、Googleは DRA TPUドライバ のオープンソース公開を発表しました。これは単なるコミュニティへの善意の表明にとどまりません。AIハードウェアの二大ベンダーが、Kubernetesにおけるハードウェア管理の標準インターフェースとしてDRAを正式採用したことを示しています。プラットフォームチームにとっては、ベンダー固有の回避策や独自のスケジューリングロジックに頼る必要がなくなることを意味します。同じDRAプリミティブが、NVIDIAのGPUでも、GoogleのTPUでも、あるいは両者が同じクラスタ内に混在していても、安定して動作するようになりました。
旧来の方式:Device Pluginsが抱えていた問題
DRA以前は、PodにGPUを使わせたい場合、Pod specに次のような記述を加えていました。
resources: limits: nvidia.com/gpu: 1このシンプルな整数リクエストには、3つの大きな問題がありました。
1. 属性ベースの選択とネイティブな分割サポートの欠如
Device Pluginsがネイティブにサポートしていたのは、基本的な整数カウント(例:「GPU 1基」)だけで、GPUの分割利用には対応していませんでした。ハードウェアリソースを分割する手段として NVIDIAのTime-Slicing や Multi-Instance GPU (MIG) といった回避策はありますが、これらはKubernetesスケジューラが本質的には理解していない、外部の「ハック」にすぎません。さらに、「VRAMが40GB以上のものが欲しい」「特定アーキテクチャのものが欲しい」といった、属性に基づくリソース要求もできませんでした。その結果、workloadが性能不足や非互換のハードウェアに割り当てられてしまうことが頻繁に起きていました。
2. 手動オーケストレーションの負担
Device Pluginsは、ハードウェアに関する有用な情報をKubernetesスケジューラにほとんど提供しません。スケジューラがハードウェアをきめ細かく把握できないため、管理者はハードコードしたラベルを使い、workloadを特定のノードに手動でマッピングするしかありませんでした。このやり方は大規模クラスタではスケールせず、ハードウェアを追加・削除・廃止するたびに手作業での更新が発生します。
3. 静的プロビジョニングの制約
Device Pluginsは、タスク開始前にハードウェアが事前構成され、利用可能になっていることを前提としていました。動的な「ジャストインタイム」のリソース割り当てや、保留中のリクエストに応じてシステムがハードウェアを探索・初期化する仕組みは存在しませんでした。
Dynamic Resource Allocation (DRA) の登場:AIハードウェア管理の新標準
Dynamic Resource Allocation (DRA) は、特殊ハードウェアを管理するためのKubernetesの新標準です。DRAの主な狙いは、リソース管理をKubernetesのコアスケジューラから切り離すことにあります。ユーザーが特定のノードを指定したり、ハードウェアに手動でタグ付けしたりするのではなく、DRAではworkload自身が要件を宣言します。すると、システムがクラスタ全体から最適なハードウェアを動的に特定し、確保し、準備します。
DRAでは、これを支える3つの重要な概念が導入されています。
1. DeviceClass — プラットフォームチームのための抽象化
DeviceClass は、プラットフォーム管理者やクラスタ管理者が定義する設計図です。開発者にハードウェアの細部を覚えてもらう代わりに、管理者が high-memory-gpu や low-latency-fpga といった名前付きクラスを作成できます。開発者はクラス名を指定して要求するだけで、あとはスケジューラに任せられます。
2. ResourceSlice — 何が利用できるか
ResourceSlice は、プール内の1つ以上の デバイス を表す、ハードウェアのインベントリレポートのようなものと考えてください。DRAドライバ(NVIDIAのGPUドライバやGoogleのTPUドライバなど)は、各ノード上のデバイスについて詳細な情報を公開します。「このノードにGPUが4基ある」だけでなく、次のような豊富な情報です。
- GPUの総メモリ (VRAM)
- アーキテクチャとハードウェアモデル
- デバイスが属するPCIeルートコンプレックスやNUMAノード
- コンピュートコア数
これが決定的な変化です。これまで隠れていたハードウェアの詳細が、スケジューラから完全に見えるようになりました。
3. ResourceClaim — 何が必要か
ResourceClaim は、workloadの要件を記述する仕組みです。ここでDRAの真価が発揮されます。「GPU 1基」と要求するだけでなく、次のような表現が可能になります。
- VRAMが40GB以上のGPUが欲しい
- 同じNUMAノード上にあるGPUと高速NICが欲しい
high-memory-gpuクラスに合致するアクセラレータが欲しい
スケジューラはこのクレームを読み取り、クラスタ全体で公開されているすべての ResourceSlices を参照して、最適な組み合わせを自動的に見つけ出します。
実例:DRAでvLLMを動かす
たとえば、vLLMを使った大規模言語モデルの推論サーバーを動かしている場面を考えてみましょう。VRAMの大きなGPUが必要で、スケジューリングは自動化したい、ノードへの手動ピン留めはしたくない。DRAを使うと、構成は次のような形になります。
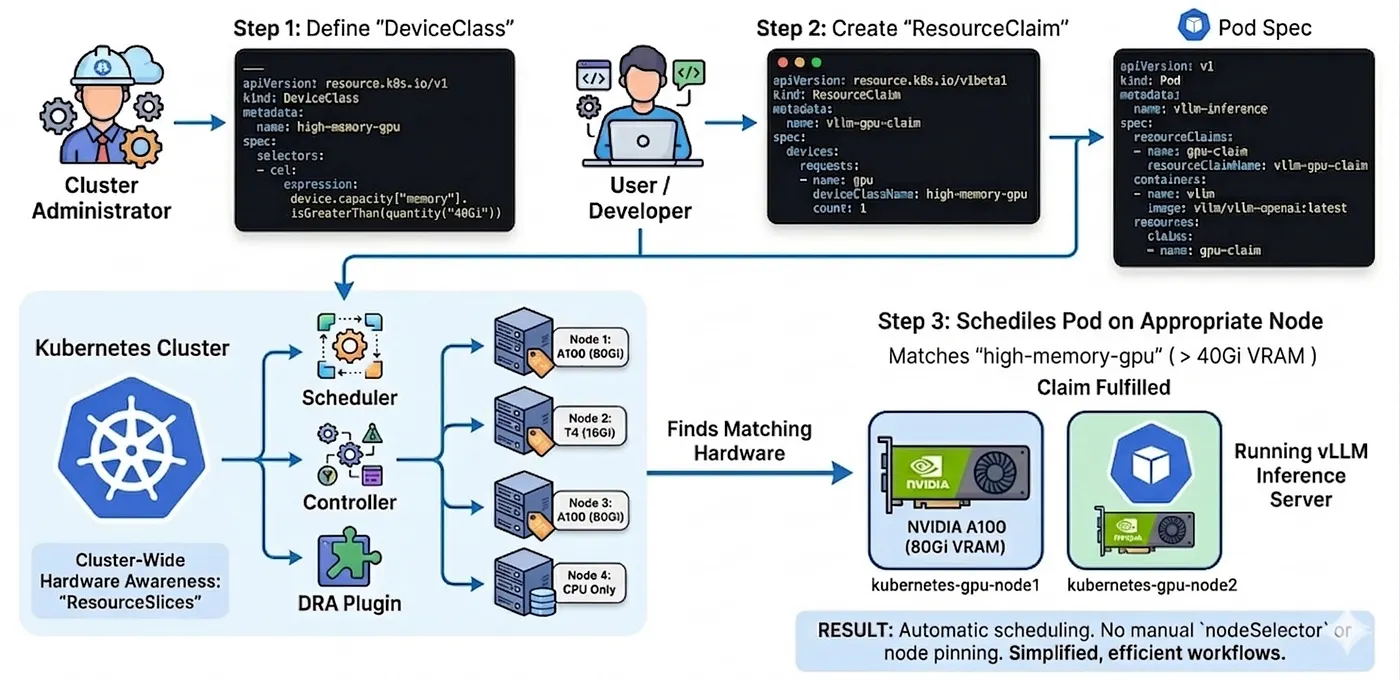
ステップ1:クラスタ管理者がDeviceClassを作成する
このクラスでは、Common Expression Language (CEL) フィルタを使い、メモリが40GB超のGPUのみを対象にします。
---apiVersion: resource.k8s.io/v1kind: DeviceClassmetadata: name: high-memory-gpuspec: selectors: - cel: expression: device.capacity["memory"].isGreaterThan(quantity("40Gi"))ステップ2:Pod spec用のResourceClaimを作成する
ユーザーは、そのクラスからデバイスを1つ要求します。
apiVersion: resource.k8s.io/v1kind: ResourceClaimmetadata: name: vllm-gpu-claimspec: devices: requests: - name: gpu deviceClassName: high-memory-gpu count: 1ステップ3:Podからクレームを参照する
最後に、Pod側ではクレームを参照するだけです。nodeSelector も複雑なアフィニティルールもいりません。
apiVersion: v1kind: Podmetadata: name: vllm-inferencespec: resourceClaims: - name: gpu-claim resourceClaimName: vllm-gpu-claim containers: - name: vllm image: vllm/vllm-openai:latest resources: claims: - name: gpu-claimこれで完了です。必要なものを記述すれば、ResourceSlices を通じて各ノードのハードウェアを余すところなく把握したKubernetesが、適切なノードを見つけてPodをスケジューリングしてくれます。nodeSelector も、kubectl get nodes で目視で探す作業も不要です。
DRAがもたらす戦略的価値
DRAは、手動設定によるミスやハードウェアのボトルネックを取り除き、本来のパフォーマンスを引き出します。
- 開発者にとって: 手作業の「ノード探し」から解放されます。コードに必要なハードウェア要件を宣言するだけで、検出も割り当てもKubernetesに任せられます。
- プラットフォームチームにとって: DeviceClassesを使ってハードウェアの「ティア」を作り、それを公開できます。全員に ノード ラベルやハードウェア仕様への直接アクセスを与える必要はありません。
- 運用チームにとって: リソース利用率が向上します。スケジューラがより充実した情報を持てるため、配置判断が的確になり、断片化の低減、アイドルGPUの削減、そして高価なハードウェアのROI向上につながります。
- 大規模AIにとって: DRAはすでに Kubernetes AI Conformanceプログラム の基盤になっています。もはや任意機能ではなく、業界標準です。
まとめ
Kubernetesは、Webサーバーやマイクロサービスをホストするだけの存在から、もっとも負荷の高いAI workloadsを支える有力プラットフォームへと進化してきました。一方で、この目覚ましい進化は、特にGPU、TPU、高速ネットワーク機器といった特殊ハードウェアの管理面で、新たなインフラ課題ももたらしています。
Device Pluginフレームワークは役目を果たしましたが、設計されたのはもっと単純な時代でした。DRAは今の環境、すなわち多様で高価なハードウェアを抱えるクラスタ、複雑で固有のニーズを持つworkloads、そしてハードウェアトポロジーの専門家になっている暇はなく素早く動かなければならないチームのために設計されています。
さらに深く知りたい方には、まず次のリソースをおすすめします。