A IA deixou de ser um projeto paralelo. Times no mundo todo estão rodando grandes modelos de linguagem (LLMs), pipelines de treinamento e servidores de inferência no Kubernetes. E, na hora em que seu workload precisa de uma GPU, a coisa complica rápido.
GPUs e TPUs são caras e difíceis de conseguir, e por muito tempo o Kubernetes usou o framework de Device Plugin para gerenciá-las. Esse framework foi criado em uma época em que os workloads do Kubernetes eram relativamente simples e basicamente pediam "uma GPU", que o sistema então entregava. Só que os workloads modernos de IA são bem mais complexos. Assim que entram tipos diferentes de GPU, topologias NVLink ou requisitos específicos de VRAM, os Device Plugins desmoronam e exigem uma configuração manual enorme.
Dynamic Resource Allocation (DRA) é a resposta do Kubernetes para essas limitações. No lugar do modelo antigo, em que os nodes anunciavam contagens fixas de hardware e o scheduler as reivindicava às cegas, o DRA traz um modelo de alocação baseado em requisições. Os workloads descrevem o que precisam, e o control plane do DRA descobre como atender a essa requisição em todo o cluster. Essa mudança tira a inteligência sobre o hardware dos agentes individuais de cada node e a centraliza em uma API expressiva.
No KubeCon Europe 2026, a NVIDIA doou seu driver DRA para GPU à CNCF, e o Google anunciou o lançamento open source do driver DRA para TPU. Não foram só gestos de boa vontade com a comunidade: mostram que os dois maiores fabricantes de hardware para IA adotaram o DRA como interface padrão para gerenciar hardware no Kubernetes. Para os times de plataforma, isso significa que você não precisa mais depender de soluções específicas de cada fornecedor nem de lógicas proprietárias de scheduling. As mesmas primitivas do DRA funcionam de forma confiável seja com GPUs NVIDIA, TPUs do Google ou os dois no mesmo cluster.
O jeito antigo: Device Plugins e suas dores
Antes do DRA, para o seu pod usar uma GPU, você adicionava algo assim na spec dele:
resources: limits: nvidia.com/gpu: 1Essa simples requisição inteira gerava três grandes dores:
1. Falta de seleção por atributos e de suporte nativo a frações
Os Device Plugins suportavam nativamente apenas contagens inteiras (ex.: "1 GPU") — e nada de GPUs fracionadas! Existem soluções alternativas, como o Time-Slicing da NVIDIA e a Multi-Instance GPU (MIG), para dividir os recursos de hardware, mas elas continuam sendo "gambiarras" externas que o scheduler do Kubernetes não entende de fato. Também faltava a capacidade de pedir recursos com base em atributos específicos, como "preciso de uma com pelo menos 40 GB de VRAM" ou "preciso de uma de uma arquitetura específica". O resultado, muitas vezes, eram workloads parando em hardware subdimensionado ou incompatível.
2. Sobrecarga de orquestração manual
Os Device Plugins não passam para o scheduler do Kubernetes nenhuma informação útil sobre o hardware. Como o scheduler não tinha visão granular do hardware, os administradores eram obrigados a mapear os workloads para nodes específicos manualmente, usando labels fixas. Essa abordagem não escala em clusters grandes, porque exige atualização manual constante toda vez que o hardware é adicionado, removido ou desativado.
3. Restrições de provisionamento estático
Os Device Plugins exigiam que o hardware estivesse pré-configurado e disponível antes do início da tarefa. Não havia mecanismo para alocação dinâmica e "just-in-time" de recursos, nem para o sistema buscar e inicializar hardware em resposta a uma requisição pendente.
Entra em cena o Dynamic Resource Allocation (DRA): o novo padrão para hardware de IA
O Dynamic Resource Allocation (DRA) é o novo padrão do Kubernetes para gerenciar hardware especializado. O objetivo principal do DRA é desacoplar o gerenciamento de recursos do scheduler central do Kubernetes. Em vez de fazer o usuário identificar nodes específicos ou marcar hardware na mão, o DRA permite que o próprio workload defina seus requisitos. O sistema então identifica, reivindica e prepara dinamicamente o hardware ideal em todo o cluster.
O DRA traz três conceitos-chave que tornam isso possível.
1. DeviceClass — abstrações para times de plataforma
DeviceClass é um modelo definido pelos administradores de plataforma ou de cluster. Em vez de exigir que os desenvolvedores conheçam as especificidades do hardware, os admins criam classes nomeadas como high-memory-gpu ou low-latency-fpga. Os desenvolvedores apenas pedem uma classe pelo nome, e o scheduler cuida do resto.
2. ResourceSlice — o que está disponível
Pense em um ResourceSlice como um relatório de inventário de hardware que representa um ou mais devices em um pool. Os drivers DRA (como o driver de GPU da NVIDIA ou o driver de TPU do Google) publicam informações detalhadas sobre os devices em cada node. Não é só "este node tem 4 GPUs", mas detalhes ricos, como:
- Memória total da GPU (VRAM)
- Arquitetura e modelo do hardware
- Em qual PCIe root complex ou node NUMA o device está
- Número de núcleos de computação
Essa é a virada de chave: detalhes de hardware que antes ficavam ocultos agora estão totalmente visíveis para o scheduler.
3. ResourceClaim — o que você precisa
Um ResourceClaim é a forma como você descreve os requisitos do seu workload. É aqui que o DRA mostra a força. No lugar de pedir "1 GPU", agora você pode dizer coisas como:
- Preciso de uma GPU com pelo menos 40 GB de VRAM
- Preciso de uma GPU e uma NIC de alta velocidade no mesmo node NUMA
- Preciso de um acelerador que se encaixe na classe
high-memory-gpu
O scheduler lê essa claim, olha todos os ResourceSlices publicados no cluster e encontra automaticamente o melhor encaixe.
Exemplo prático: rodando vLLM com DRA
Digamos que você esteja rodando um servidor de inferência de um grande modelo de linguagem com vLLM. Você precisa de uma GPU com bastante VRAM e quer que o scheduling seja automático, sem fixar nodes na mão. Com o DRA, sua configuração pode ficar mais ou menos assim:
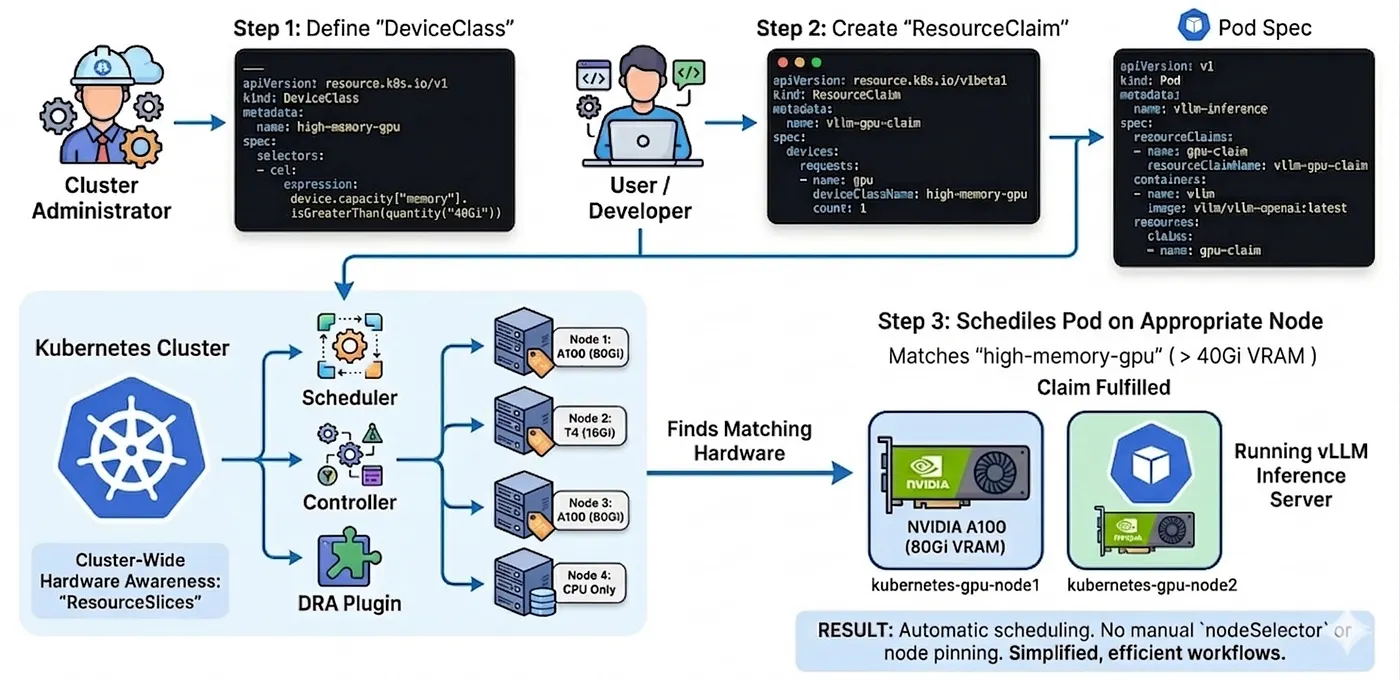
Passo 1: o admin do cluster cria uma DeviceClass
Essa classe filtra qualquer GPU com mais de 40 GB de memória usando um filtro Common Expression Language (CEL).
---apiVersion: resource.k8s.io/v1kind: DeviceClassmetadata: name: high-memory-gpuspec: selectors: - cel: expression: device.capacity["memory"].isGreaterThan(quantity("40Gi"))Passo 2: você cria um ResourceClaim para a spec do seu pod
O usuário pede um device dessa classe específica.
apiVersion: resource.k8s.io/v1kind: ResourceClaimmetadata: name: vllm-gpu-claimspec: devices: requests: - name: gpu deviceClassName: high-memory-gpu count: 1Passo 3: referencie a claim no seu pod
Por fim, o Pod simplesmente aponta para a claim. Sem nodeSelector nem regras complexas de afinidade.
apiVersion: v1kind: Podmetadata: name: vllm-inferencespec: resourceClaims: - name: gpu-claim resourceClaimName: vllm-gpu-claim containers: - name: vllm image: vllm/vllm-openai:latest resources: claims: - name: gpu-claimÉ isso. Você descreveu o que precisa. O Kubernetes — agora com visibilidade total do hardware de cada node via ResourceSlices — encontra um node adequado e agenda seu pod ali. Sem nodeSelector. Sem ficar caçando com kubectl get nodes.
O valor estratégico do DRA
O DRA garante que você extraia o desempenho máximo, eliminando erros de configuração manual e gargalos de hardware.
- Para desenvolvedores: chega de "caçar nodes" na mão. Defina os requisitos de hardware do seu código e deixe o Kubernetes cuidar da descoberta e do attachment.
- Para times de plataforma: dá para criar "tiers" de hardware com DeviceClasses e expô-los, sem precisar dar a todo mundo acesso direto a labels de node e specs de hardware.
- Para operações: a utilização de recursos melhora. Com mais informação, o scheduler toma decisões de alocação melhores, com menos fragmentação, menos GPUs ociosas e ROI maior em hardware caro.
- Para IA em escala: o DRA já virou a base do programa Kubernetes AI Conformance. Não é mais um recurso opcional; virou padrão de mercado.
Para fechar
O Kubernetes deixou de ser apenas um lugar para hospedar servidores web e microsserviços e se tornou a plataforma preferida para alguns dos workloads de IA mais pesados. Mas todo esse progresso empolgante também trouxe novos desafios de infraestrutura, especialmente no gerenciamento de hardware especializado, como GPUs, TPUs e equipamentos de rede de alta velocidade.
O framework de Device Plugin cumpriu seu papel, mas foi pensado para uma época mais simples. O DRA foi feito para o cenário atual: clusters com hardware diverso e caro, workloads com necessidades específicas e complexas e times que precisam se mover rápido sem virar especialistas em topologia de hardware.
Se você quiser se aprofundar, estes são os melhores pontos de partida: