Le nœud du problème avec _KubernetesPodOperator_ sur Composer
La classe KubernetesPodOperator est la méthode pour exécuter des conteneurs sur Cloud Composer, mais elle présente un défaut majeur : elle exécute tous les conteneurs sur les mêmes nœuds que les DAGs tournant sur Airflow. Autrement dit, elle entre en concurrence avec eux pour les ressources.
Cela peut sembler anodin, mais certains scénarios peuvent vite devenir problématiques. L'un de nos clients, par exemple, a commencé à voir des exceptions remonter lors de l'exécution de conteneurs au sein d'un DAG, parce que ses autres DAGs consommaient trop de mémoire.
Le cluster GKE sous-jacent ne parvenait plus à planifier les DAGs et tâches supplémentaires : Airflow se contentait de renvoyer une exception de timeout dès qu'on lançait une tâche KubernetesPodOperator. Conséquence directe : leur DAG critique contenant un conteneur ne pouvait plus s'exécuter. S'il s'était agi d'un DAG calculant la paie ou les primes de fin d'année, les conséquences auraient été lourdes.
Cela nous amène à la solution de ce problème précis, mais d'abord quelques explications rapides sur le fonctionnement de GKE. Si vous connaissez déjà GKE, sautez les deux sections suivantes pour aller directement à la solution.
Place aux Node Pools
Pour celles et ceux qui ne connaissent pas GKE ni les environnements Kubernetes managés : les nœuds y sont regroupés au sein d'ensembles appelés node pools. Lorsque des pods et des workloads sont planifiés, ils s'exécutent sur un ou plusieurs nœuds du node pool associé. Un cluster peut tout à fait, et c'est même fréquent, contenir plusieurs node pools.
À la création d'une instance Cloud Composer, un cluster GKE est généré avec un seul node pool, dont la taille et le nombre de nœuds correspondent à la configuration choisie. Par défaut, ce node pool exécute tous les DAGs et leurs tâches associées, ainsi que l'ensemble des services créés et orchestrés par l'instance Cloud Composer (à l'exception de la base de données MySQL sous-jacente).
Comme ce node pool repose sur une quantité préconfigurée de nœuds et des tailles d'instances figées, les ressources disponibles y sont par nature limitées. Une fonctionnalité d'autoscaling existe, mais à l'heure où nous écrivons ces lignes, il est impossible de modifier la taille des nœuds. L'autoscaling se contentera donc d'ajouter des instances de la même taille à votre node pool. Si une tâche d'un DAG demande plus de mémoire qu'un nœud ne peut en fournir, vous tomberez très probablement sur les exceptions décrites plus haut.
Comment résoudre cela ? En créant un node pool dédié à l'exécution des tâches qui contiennent des conteneurs. Si vous connaissez Kubernetes, la notion d'affinité vous viendra immédiatement à l'esprit. C'est précisément la solution, et c'est aussi pourquoi, à l'heure actuelle, on ne peut l'appliquer qu'aux tâches qui exécutent des conteneurs.
Fonctionnement de la planification et de l'affinité
Planification
Comme indiqué plus haut, Cloud Composer s'exécute au-dessus d'un cluster GKE, l'ensemble des DAGs, tâches et services tournant sur un seul node pool. Au lancement d'un DAG, un service interne d'Airflow appelé scheduler établit un plan d'exécution définissant l'ordre dans lequel les tâches seront exécutées.
Lorsque l'exécution d'un DAG démarre, le scheduler prépare chaque tâche pour qu'elle soit prise en charge par un autre service interne d'Airflow, le worker. Quand le worker est prêt, il demande au service Kubernetes sous-jacent d'exécuter la tâche. Au cours de cette opération, Kubernetes effectue de nombreux traitements pour déterminer si les ressources nécessaires sont disponibles et choisit le nœud du node pool sur lequel exécuter la tâche.
Par défaut, la tâche s'exécute sur le nœud du node pool créé par Cloud Composer que le système juge le plus adapté. Selon la taille de l'instance Airflow, cela peut représenter un nombre conséquent de DAGs comportant chacun de nombreuses tâches, planifiés simultanément sur le même node pool. D'où une concurrence évidente pour les ressources finies du node pool.
Affinité
Une solution envisageable consiste à exécuter certaines tâches sur un nœud dédié du node pool, et rien d'autre sur ce nœud. Le mécanisme qui permet cela s'appelle l'affinité ; son inverse, l'anti-affinité.
L'affinité fonctionne en appliquant un label à certains nœuds — voire à tous — d'un node pool. Lors de la définition d'une tâche dans un DAG, on utilise une construction appelée nodeSelector qui indique au cluster Kubernetes sous-jacent d'exécuter cette tâche uniquement sur un nœud portant un label correspondant.
L'anti-affinité fait l'inverse : elle indique de ne pas exécuter cette tâche sur un nœud correspondant à un label donné. On peut ainsi planifier certaines tâches sur certains nœuds et pas sur d'autres, et obtenir une répartition fine des workloads.
Si vous voulez voir comment cela fonctionne dans le détail, la documentation Kubernetes correspondante est disponible ici.
Combiner KubernetesPodOperator et Node Pools
Pour résoudre le problème évoqué plus haut, nous allons combiner le KubernetesPodOperator, un nouveau node pool dédié à ces tâches et l'affinité Kubernetes. Vos conteneurs s'exécuteront ainsi dans un bac à sable distinct, où les ressources ne sont pas limitées par les choix faits à la création de l'environnement.
Le code que je vais référencer est disponible sur Github ici.
Le fichier sample_dag.py contient un DAG dont la structure ressemble à ceci :
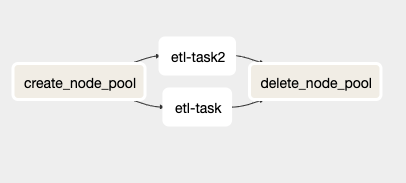
Vue du fichier sample_dag.py depuis l'UI Airflow.
Ce DAG comporte quatre tâches distinctes, dont deux ( etl_task et etl_task2) sont identiques et destinées à être remplacées par chaque utilisateur final pour exécuter son propre code.
La tâche create_node_pool est un BashOperator qui récupère un certain nombre de variables d'environnement préconfigurées (nous y reviendrons plus loin), crée un nouveau node pool GKE et stocke son nom dans une variable Airflow. Cette dernière étape est indispensable, car le KubernetesPodOperator n'autorise pas l'utilisation de variables d'environnement dans son argument d'affinité.
Les tâches etl_task et etl_task2 sont des exemples créés pour montrer le KubernetesPodOperator en action. Elles démarrent un conteneur Ubuntu 18.04, attendent 120 secondes puis s'arrêtent. L'essentiel se trouve toutefois dans le code : il montre comment configurer l'affinité de l'opérateur pour que votre cluster GKE planifie le conteneur sur le node pool fraîchement créé. Je détaille ce point dans la section suivante.
La dernière tâche, delete_node_pool, est un BashOperator qui supprime le node pool créé une fois le reste du DAG terminé (ou en erreur). À noter : cette tâche s'exécute systématiquement, même si d'autres tâches renvoient des codes d'erreur, afin d'éviter qu'un node pool ne reste actif et n'engendre des coûts imprévus.
Décryptage du code KubernetesPodOperator
Voici une copie du code etl_task issu du fichier python ci-dessous, dont les commentaires et quelques lignes peu importantes (les commandes sleep, par exemple) ont été retirés :
etl_task = kubernetes_pod.KubernetesPodOperator(
task_id='etl-task',
name='etl',
namespace='default',
image='gcr.io/gcp-runtimes/ubuntu_18_0_4',
startup_timeout_seconds=720,
affinity={
'nodeAffinity': {
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{\
'matchExpressions': [{\
'values': [\
Variable.get("node_pool", default_var=node_pool_value)\
]\
}]\
}]
}
}
})
Vous remarquerez que j'ai mis en gras le paramètre de l'objet affinity ci-dessus : c'est sur lui que je veux me concentrer, car il est très spécifique à Kubernetes.
Concrètement, ce code indique à Kubernetes, au moment de la planification (et non de l'exécution) de la tâche, d'exiger qu'elle soit planifiée sur un nœud portant un label correspondant au nom du node pool créé par la tâche create_node_pool. Il s'appuie sur un nodeSelector pour faire correspondre un label avec le nom du node pool créé. Lorsque GKE crée un nouveau node pool, il applique automatiquement un label portant son nom sur chacun de ses nœuds — c'est précisément ce label que nous ciblons dans le code ci-dessus.
Un point à retenir : le code récupère la valeur du label depuis la variable Airflow node_pool. Si vous lancez plusieurs instances de ce DAG, je vous recommande de donner à cette variable un nom propre à chaque DAG. Attention toutefois : du fait des limitations d'Airflow, vous ne pouvez insérer ni template ni code dynamique (comme la récupération d'une variable d'environnement) dans l'objet du paramètre affinity, sous peine de voir le DAG échouer au chargement.
Éléments configurables du DAG
Ce code crée un node pool qui ne convient pas à tous les usages : j'ai donc introduit quelques variables d'environnement permettant d'ajuster les options liées au node pool.
Voici la liste de ces variables d'environnement et leur rôle :
NODE_COUNT
Nombre de nœuds qui seront provisionnés dans le nouveau node pool. Valeur par défaut : 3.
MACHINE_TYPE
Type d'instance (taille) de la machine virtuelle provisionnée dans le nouveau node pool. Si vous l'utilisez pour des workloads de courte durée et que vous supprimez le node pool à la fin, je recommande vivement les types de machines E2 : la remise pour utilisation soutenue (sustained-use discount) y est déjà intégrée au prix, ce qui les rend plus économiques pour des workloads éphémères. Valeur par défaut : e2-standard-8 (8 vCPU et 32 Go de RAM).
SCOPES
Cette variable regroupe les scopes GCP attachés aux instances du node pool. Par exemple, autoriser l'accès à BigQuery et à Pub/Sub ainsi que l'écriture des logs correspondrait aux scopes suivants : bigquery, pubsub, logging-write. Valeur par défaut : default,cloud-platform.
Voilà une manière très simple d'exécuter des conteneurs au sein d'un DAG sur Cloud Composer. Ce n'est pas le chemin le plus direct, mais en raison des limitations imposées par les services managés, il faut parfois passer par ce type d'étapes en attendant qu'une solution native soit proposée par le fournisseur.
Personnellement, j'aimerais beaucoup pouvoir spécifier l'affinité au-delà des seules tâches KubernetesPodOperator, car d'autres types de tâches — notamment les opérateurs python ou bash — peuvent eux aussi provoquer ce genre de problèmes.

Merci de votre lecture ! Pour rester en contact, suivez-nous sur le DoiT Engineering Blog , le DoiT Linkedin Channel et le DoiT Twitter Channel . Pour découvrir nos opportunités de carrière, rendez-vous sur https://careers.doit-intl.com .