Il punto critico di _KubernetesPodOperator_ su Composer
La classe KubernetesPodOperator è il metodo per eseguire container su Cloud Composer, ma ha un grosso difetto: esegue tutti i container sugli stessi nodi su cui girano i DAG di Airflow. Significa che competono con essi per le risorse.
Detta così può sembrare poca cosa, ma esistono scenari in grado di crearle qualche grattacapo. Uno dei nostri clienti, ad esempio, ha iniziato a ricevere eccezioni nell'esecuzione dei container all'interno di un DAG perché gli altri DAG saturavano la memoria.
Il cluster GKE sottostante non riusciva più a pianificare DAG e task aggiuntivi, e Airflow ha iniziato a generare eccezioni di timeout a ogni tentativo di esecuzione di un task KubernetesPodOperator. Risultato: il loro DAG mission-critical che conteneva un container non riusciva ad andare in esecuzione. Se fosse stato un DAG dedicato al calcolo delle buste paga o dei bonus di fine anno, le conseguenze sarebbero state davvero gravi.
Veniamo dunque alla soluzione, ma non prima di qualche breve premessa sul funzionamento di GKE. Se conosce già GKE, può tranquillamente saltare le prossime due sezioni e andare direttamente alla soluzione.
Entrano in gioco i Node Pool
Per chi non ha familiarità con GKE o con gli ambienti Kubernetes gestiti: i nodi vengono raggruppati in insiemi chiamati node pool. Quando vengono pianificati pod e workloads, questi vengono eseguiti su uno o più nodi del node pool associato. Un cluster può avere, e di norma ha, più node pool.
Quando si crea un'istanza di Cloud Composer, viene generato un cluster GKE con un singolo node pool, con la dimensione e il numero di nodi configurati. Per impostazione predefinita, questo node pool esegue tutti i DAG e i relativi task, oltre a tutti i servizi creati e orchestrati dall'istanza Cloud Composer (eccezion fatta per il database MySQL di backend).
Poiché il node pool ha una quantità di nodi e una dimensione delle istanze pre-configurate, le risorse disponibili sono limitate e ben definite. Esiste una funzionalità di autoscaling, ma al momento in cui scriviamo non consente di modificare la dimensione dei nodi: si limita ad aggiungere altre istanze della stessa dimensione al node pool. Se all'interno di un DAG c'è un task che richiede più memoria di quanta ne possa offrire un singolo nodo, è molto probabile incappare nelle eccezioni descritte sopra.
Come si risolve, allora? Creando un node pool dedicato all'esecuzione dei task che contengono container. Chi conosce Kubernetes penserà subito al concetto di affinity: è proprio questa la soluzione, ed è anche il motivo per cui, al momento, possiamo applicarla solo ai task che eseguono container.
Come funzionano scheduling e affinity
Scheduling
Come accennato, Cloud Composer gira su un cluster GKE in cui tutti i DAG, i task e i servizi vengono eseguiti su un unico node pool. Quando un DAG viene avviato, un servizio interno ad Airflow chiamato scheduler crea un piano che stabilisce l'ordine di esecuzione dei task.
All'avvio del DAG, lo scheduler prepara ciascun task per l'esecuzione da parte di un altro servizio Airflow, il worker. Quando il worker è pronto a eseguire il task, comunica al servizio Kubernetes sottostante di mandarlo in esecuzione. In questo passaggio Kubernetes svolge numerose elaborazioni, verificando se ci sono risorse disponibili e decidendo su quale nodo del node pool eseguire il task.
Per impostazione predefinita, il task verrà eseguito sul nodo del node pool creato da Cloud Composer che il sistema considera il candidato migliore. A seconda della dimensione dell'istanza Airflow, ciò può tradursi in parecchi DAG, ciascuno con un gran numero di task, pianificati contemporaneamente sullo stesso node pool. Si crea così una certa competizione per le risorse limitate disponibili.
Affinity
Una possibile soluzione consiste nell'eseguire determinati task su un nodo dedicato del node pool, e nient'altro su quel nodo. Il meccanismo che lo permette si chiama affinity, e il suo opposto anti-affinity.
L'affinity funziona applicando un'etichetta a nodi specifici, o a tutti i nodi, di un node pool. Quando si definisce un task all'interno di un DAG, si utilizza un costrutto chiamato nodeSelector, che indica al cluster Kubernetes sottostante di eseguire quel task soltanto su un nodo con un'etichetta corrispondente.
L'anti-affinity è esattamente il contrario: dice "non eseguire questo task" sui nodi che corrispondono a una specifica etichetta. In questo modo è possibile pianificare determinati task su determinati nodi e non su altri, ottenendo una distribuzione mirata dei workloads.
Se è curioso di vedere come funziona dietro le quinte, trova i dettagli specifici di Kubernetes qui.
Combinare KubernetesPodOperator e Node Pool
Per risolvere il problema descritto sopra combineremo il KubernetesPodOperator, un nuovo node pool dedicato all'esecuzione di questi task e l'affinity di Kubernetes. In questo modo i container vengono eseguiti in una "sandbox" separata, dove le risorse non sono vincolate a quanto definito al momento della creazione dell'ambiente.
Il codice a cui farò riferimento si trova su Github qui.
All'interno del file sample_dag.py si trova un DAG con la seguente struttura:
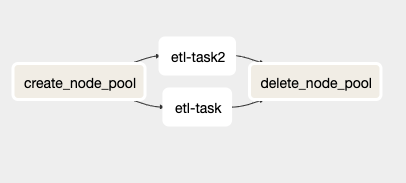
Vista del file sample_dag.py dall'interfaccia di Airflow.
Il DAG contiene quattro task diversi, due dei quali (etl_task ed etl_task2) sono duplicati e dovranno essere sostituiti dall'utente finale con il proprio codice.
Il task create_node_pool è un BashOperator che recupera alcune variabili d'ambiente preimpostate (ne parleremo più avanti), crea un nuovo node pool GKE e ne salva il nome in una variabile Airflow. Quest'ultimo passaggio è necessario perché il KubernetesPodOperator non consente l'uso di variabili d'ambiente all'interno del suo argomento affinity.
I task etl_task ed etl_task2 sono task di esempio che ho creato per mostrare il KubernetesPodOperator in azione: avviano un container Ubuntu 18.04 e restano in sleep per 120 secondi prima di terminare. La parte interessante, però, è nel codice: mostra come configurare l'affinity per l'operator in modo da indicare al cluster GKE di pianificare il container sul node pool appena creato. Approfondirò questo aspetto nella prossima sezione.
L'ultimo task, delete_node_pool, è un BashOperator che elimina il node pool creato al completamento (o in caso di errore) del resto del DAG. Da notare: questo task viene sempre eseguito, anche quando gli altri task restituiscono codici di errore, così da evitare che un node pool resti attivo accumulando costi imprevisti.
Analisi del codice KubernetesPodOperator
Ecco una copia del codice di etl_task tratta dal file Python qui sotto, da cui ho rimosso i commenti e qualche riga poco rilevante (come i comandi sleep):
etl_task = kubernetes_pod.KubernetesPodOperator(
task_id='etl-task',
name='etl',
namespace='default',
image='gcr.io/gcp-runtimes/ubuntu_18_0_4',
startup_timeout_seconds=720,
affinity={
'nodeAffinity': {
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{\
'matchExpressions': [{\
'values': [\
Variable.get("node_pool", default_var=node_pool_value)\
]\
}]\
}]
}
}
})
Avrà notato che ho evidenziato il parametro dell'oggetto affinity: è proprio su questo che voglio concentrarmi, perché è molto specifico di Kubernetes.
Cosa fa questo codice? Dice a Kubernetes che, in fase di pianificazione (non di esecuzione) del task, deve obbligatoriamente assegnarlo a un nodo con un'etichetta corrispondente al nome del node pool creato dal task create_node_pool. Lo fa tramite un nodeSelector, istruendolo a cercare un'etichetta che riporti il nome del node pool appena creato. Quando GKE crea un nuovo node pool, applica automaticamente a ciascun nodo un'etichetta con il nome del node pool stesso: ed è proprio questo il valore con cui il codice qui sopra cerca la corrispondenza.
Una cosa da tenere a mente: il valore dell'etichetta viene letto dalla variabile Airflow node_pool. Se prevede di eseguire più istanze di questo DAG, le consiglio di rinominare la variabile rendendola specifica per ciascun DAG. Attenzione però: a causa delle limitazioni di Airflow non è possibile inserire template o codice dinamico (come il recupero di una variabile d'ambiente) all'interno dell'oggetto del parametro affinity, altrimenti il caricamento del DAG fallirà.
Elementi configurabili del DAG
Poiché il codice crea un node pool che non è una soluzione universale valida per tutti, ho introdotto alcune variabili d'ambiente che permettono di modificare le opzioni del node pool.
Ecco l'elenco delle variabili d'ambiente e delle relative funzioni:
NODE_COUNT
È il numero di nodi che verranno provisionati nel nuovo node pool. Il valore predefinito è 3.
MACHINE_TYPE
È il tipo di istanza (dimensione) della macchina virtuale che verrà provisionata nel nuovo node pool. Se la sta usando per workloads di breve durata e rimuove il node pool al termine, le consiglio vivamente le macchine di tipo E2: hanno già il sustained-use-discount incluso nel prezzo e risultano quindi più convenienti per workloads di breve durata. Il valore predefinito è e2-standard-8 (8 vCPU e 32 GB di RAM).
SCOPES
Contiene gli scope GCP associati alle istanze del node pool. Ad esempio, per consentire l'accesso a BigQuery e Pub/Sub oltre alla scrittura dei log, gli scope sarebbero: bigquery, pubsub, logging-write. Il valore predefinito è default,cloud-platform.
Questo è un modo molto semplice per eseguire container all'interno di un DAG su Cloud Composer. Non è la strada più immediata ma, a causa delle limitazioni imposte dai servizi gestiti, a volte è necessario procedere così finché il provider non rilascerà una soluzione nativa di prima parte.
Personalmente mi piacerebbe poter specificare l'affinity non solo per i task KubernetesPodOperator: anche task diversi da quelli basati su container possono infatti generare gli stessi problemi, in particolare i task di tipo Python o Bash operator.

Grazie per la lettura! Per restare in contatto, ci segua sul DoiT Engineering Blog, sul canale LinkedIn di DoiT e sul canale Twitter di DoiT. Per scoprire le opportunità di carriera, visiti https://careers.doit-intl.com.