O ponto crítico do _KubernetesPodOperator_ no Composer
A classe KubernetesPodOperator é o método para rodar containers no Cloud Composer, mas tem uma falha grave: ela executa todos os containers nos mesmos nodes em que rodam as DAGs do Airflow. Ou seja, os containers disputam recursos com elas.
Isso pode parecer pouco preocupante, mas há cenários em que vira um problema. Por exemplo, um dos nossos clientes começou a receber exceções ao rodar containers dentro de uma DAG porque suas outras DAGs estavam consumindo memória demais.
O cluster GKE por trás não conseguia agendar DAGs e tarefas adicionais, e o Airflow simplesmente passou a lançar uma exceção de timeout sempre que tentava executar qualquer tarefa do tipo KubernetesPodOperator. Por causa disso, a DAG mission-critical que continha um container deixou de rodar. Se fosse uma DAG responsável por calcular folha de pagamento ou bônus de fim de ano, com certeza teria sido um baita problema, com sérias implicações.
Isso nos leva à solução para esse caso específico, mas antes vale uma explicação rápida sobre como o GKE funciona. Se você já manja de GKE, pode pular as duas próximas seções e ir direto para a solução.
Conheça os Node Pools
Para quem não tem familiaridade com GKE ou ambientes Kubernetes gerenciados: os nodes são agrupados em conjuntos chamados node pools. Quando pods e workloads são agendados, eles rodam em um ou mais nodes do node pool associado. Um cluster pode ter — e quase sempre tem — vários node pools.
Quando uma instância do Cloud Composer é criada, ela provisiona um cluster GKE com um único node pool, com o tamanho e a quantidade de nodes configurados. Por padrão, esse node pool roda todas as DAGs e suas tarefas, além de todos os serviços criados e orquestrados pela instância do Cloud Composer (com exceção do banco MySQL de apoio).
Como esse node pool tem uma quantidade pré-configurada de nodes e tamanhos de instância, os recursos por ali são limitados e bem finitos. Vale lembrar que existe um recurso de autoscaling disponível, mas, no momento em que escrevo, não dá para alterar o tamanho dos nodes. Resultado: o autoscaler só adiciona mais instâncias do mesmo tamanho ao node pool. Se você tem uma tarefa dentro de uma DAG que precisa de mais memória do que um node permite, é bem provável que isso leve às exceções descritas acima.
Então, como resolver? Criando um node pool dedicado a rodar tarefas que contêm containers. Se você conhece Kubernetes, a ideia de affinity já deve ter vindo à cabeça. É exatamente essa a solução — e é por isso que, no momento em que escrevo, só conseguimos aplicar isso em tarefas que executam containers.
Como funcionam Scheduling e Affinity
Scheduling
Como mencionei acima, o Cloud Composer roda em cima de um cluster GKE, com todas as DAGs, tarefas e serviços executando em um único node pool. Quando uma DAG é executada, um serviço do Airflow chamado scheduler monta um plano com a ordem em que as tarefas serão executadas.
Quando a execução de uma DAG começa, o scheduler prepara cada tarefa para rodar em um serviço do Airflow chamado worker. Quando o worker está pronto, ele instrui o serviço Kubernetes por baixo a executar a tarefa. Nesse processo, o Kubernetes faz bastante trabalho: avalia se há recursos disponíveis para executar a tarefa e decide em qual node do node pool ela vai rodar.
Por padrão, ele executa essa tarefa em qualquer node do node pool criado pelo Cloud Composer que o sistema considere o melhor candidato. Dependendo do tamanho da instância do Airflow, isso pode envolver várias DAGs, todas com um monte de tarefas sendo agendadas ao mesmo tempo no mesmo node pool. Isso gera certa concorrência pelos recursos finitos disponíveis ali.
Affinity
Uma solução possível é rodar determinadas tarefas em um node dedicado dentro do node pool, e nada mais nesse node. O processo que viabiliza isso se chama affinity, e o oposto, anti-affinity.
O affinity funciona aplicando uma label a nodes específicos (ou a todos) de um node pool. Ao definir uma tarefa dentro de uma DAG, usa-se uma construção chamada nodeSelector, que orienta o cluster Kubernetes por trás a rodar aquela tarefa apenas em um node que tenha uma label correspondente.
O anti-affinity é o contrário: diz "não rode esta tarefa" em um node que tenha uma label específica. Isso permite agendar certas tarefas em determinados nodes e não em outros, possibilitando uma distribuição específica do workload.
Se você tiver curiosidade sobre como isso funciona por baixo dos panos, os detalhes específicos do Kubernetes estão aqui.
Combinando KubernetesPodOperator e Node Pools
Para resolver o problema mencionado, vamos combinar o KubernetesPodOperator, um node pool novo e dedicado para rodar essas tarefas, e o affinity do Kubernetes. Isso garante que seus containers rodem em um "sandbox" separado, em que os recursos não ficam restritos ao que você selecionou na criação do ambiente.
O código que vou usar como referência está no GitHub aqui.
Dentro do arquivo sample_dag.py existe uma DAG com a seguinte estrutura:
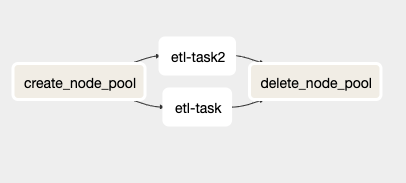
Visualização do arquivo sample_dag.py na UI do Airflow.
Nesta DAG há quatro tarefas distintas, sendo duas delas (etl_task e etl_task2) duplicadas — elas devem ser substituídas pelo usuário final pelo seu próprio código.
A tarefa create_node_pool é um BashOperator que carrega algumas variáveis de ambiente pré-definidas (mais detalhes em uma seção adiante), cria um novo node pool no GKE e armazena o nome desse node pool em uma variável do Airflow. Esse último passo é necessário porque o KubernetesPodOperator não permite usar variáveis de ambiente dentro do seu argumento de affinity.
As tarefas etl_task e etl_task2 são tarefas de exemplo que criei para mostrar o KubernetesPodOperator em ação. Elas sobem um container Ubuntu 18.04 e ficam em sleep por 120 segundos antes de serem encerradas. A parte essencial dessas tarefas, no entanto, está no código: ele mostra como configurar o affinity do operator, instruindo o cluster GKE a agendar o container no node pool recém-criado. Vou detalhar isso na próxima seção.
A última tarefa, delete_node_pool, é um BashOperator que apaga o node pool criado quando o restante da DAG termina (ou falha). Vale notar que essa tarefa sempre é executada, mesmo que outras tarefas retornem códigos de erro — assim você não corre o risco de deixar um node pool rodando e acumulando custos inesperados por causa de algum erro.
Detalhando o código do KubernetesPodOperator
Aqui vai uma cópia do código de etl_task do arquivo Python, com os comentários e algumas linhas pouco relevantes (como os comandos de sleep) removidos:
etl_task = kubernetes_pod.KubernetesPodOperator(
task_id='etl-task',
name='etl',
namespace='default',
image='gcr.io/gcp-runtimes/ubuntu_18_0_4',
startup_timeout_seconds=720,
affinity={
'nodeAffinity': {
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{\
'matchExpressions': [{\
'values': [\
Variable.get("node_pool", default_var=node_pool_value)\
]\
}]\
}]
}
}
})
Você vai notar que destaquei o parâmetro do objeto affinity acima — é nele que quero focar aqui, porque é bem específico do Kubernetes.
O que esse código faz é dizer ao Kubernetes que, no momento de agendar (e não de executar) essa tarefa, ela precisa ser agendada em um node cuja label corresponda ao nome do node pool criado pela tarefa create_node_pool. Ele usa um nodeSelector e instrui o sistema a casar com uma label que tenha o nome do node pool criado. Quando o GKE cria um novo node pool, ele automaticamente aplica em cada node uma label com o nome desse node pool — e é com isso que estamos fazendo o match no código acima.
Vale observar que o valor da label é obtido a partir da variável do Airflow node_pool. Se você roda várias instâncias dessa DAG, recomendo trocar o nome dessa variável por algo específico de cada DAG. Apenas fique atento que, devido a limitações do Airflow, não é possível inserir templates ou código dinâmico (como puxar uma variável de ambiente) dentro do objeto do parâmetro affinity — caso contrário, a DAG não vai conseguir ser carregada.
Itens configuráveis da DAG
Como esse código cria um node pool que não serve do mesmo jeito para todo mundo, introduzi algumas variáveis de ambiente no código para permitir alterar opções relacionadas ao node pool.
Aqui vai a lista de variáveis de ambiente e suas funções:
NODE_COUNT
É a quantidade de nodes que será provisionada no novo node pool. O valor padrão é 3.
MACHINE_TYPE
É o tipo (tamanho) da instância de máquina virtual que será provisionada no novo node pool. Se você está usando isso para workloads de execução mais curta e remove o node pool ao final, recomendo fortemente os tipos de máquina E2, já que eles já incluem o sustained-use discount no preço — o que os torna mais baratos para workloads de curta duração. O valor padrão é e2-standard-8 (8 vCPUs e 32 GB de RAM).
SCOPES
Contém os scopes do GCP atribuídos às instâncias do node pool. Por exemplo, liberar acesso ao BigQuery e ao Pub/Sub, além de gravar logs, exigiria os seguintes scopes: bigquery, pubsub, logging-write. O valor padrão é default,cloud-platform.
Essa foi uma forma bem simples de rodar containers dentro de uma DAG no Cloud Composer. Não é o caminho mais fácil, mas, infelizmente, devido às limitações impostas pelos serviços gerenciados, às vezes é preciso seguir esses passos até que o provedor implemente uma solução nativa para fazer isso de forma integrada.
Particularmente, eu adoraria poder especificar affinity para mais do que apenas tarefas do KubernetesPodOperator, porque, em alguns casos, tarefas que não envolvem containers — como as de Python ou Bash operator — também causam esse tipo de problema.

Obrigado pela leitura! Para continuar por dentro, siga a gente no DoiT Engineering Blog , no canal do DoiT no LinkedIn e no canal do DoiT no Twitter . Para conhecer oportunidades de carreira, acesse https://careers.doit-intl.com .