El quid del _KubernetesPodOperator_ en Composer
La clase KubernetesPodOperator es el método para ejecutar contenedores en Cloud Composer, pero tiene una falla importante: corre todos los contenedores en los mismos nodos que los DAGs de Airflow. Es decir, compite con ellos por los recursos.
Puede que no suene tan grave, pero hay escenarios que sí pueden traerte problemas. Por ejemplo, uno de nuestros clientes empezó a recibir excepciones al ejecutar contenedores dentro de un DAG porque sus otros DAGs estaban consumiendo demasiada memoria.
El cluster de GKE subyacente no lograba programar DAGs ni tareas adicionales, así que Airflow simplemente comenzó a lanzar una excepción de timeout al intentar ejecutar cualquier tarea de KubernetesPodOperator. Por eso, el DAG de misión crítica que contenía un contenedor no podía correr. Si hubiera sido un DAG encargado de calcular la nómina o los bonos de fin de año, sin duda habría sido un problema grave con implicaciones serias.
Esto nos lleva a la solución de este problema en particular, pero antes vale la pena explicar brevemente cómo funciona GKE. Si ya conoces GKE, puedes saltarte las próximas dos secciones e ir directo a la solución.
Entran en escena los Node Pools
Para quienes no están familiarizados con GKE ni con los entornos de Kubernetes administrados, los nodos se agrupan en lo que se conoce como node pools. Cuando se programan pods y workloads, estos se ejecutan en uno o más nodos del node pool asociado. Un cluster puede tener (y suele tener) varios node pools.
Al crear una instancia de Cloud Composer, esta genera un cluster de GKE con un único node pool que contiene el tamaño y la cantidad de nodos configurados. Por defecto, este node pool ejecuta todos los DAGs y sus tareas asociadas, además de todos los servicios creados y orquestados por la instancia de Cloud Composer (excepto la base de datos MySQL de respaldo).
Como este node pool tiene una cantidad y un tamaño de instancias preconfigurados, los recursos disponibles serán limitados y muy finitos. Cabe mencionar que existe una función de autoescalado, pero al momento de escribir esto, no se puede cambiar el tamaño de los nodos. Por lo tanto, solo se agregarán más instancias del mismo tamaño al node pool. Si tienes una tarea dentro de un DAG que requiere más memoria de la que un nodo permite, lo más probable es que se generen los problemas de excepciones descritos arriba.
Entonces, ¿cómo se soluciona esto? Crea un node pool dedicado a ejecutar las tareas que contienen contenedores. Si conoces Kubernetes, te vendrá a la mente el concepto de affinity. Esa es justamente la solución a este problema y la razón por la cual, al momento de escribir esto, solo podemos aplicarlo a tareas que ejecutan contenedores.
Cómo funcionan el Scheduling y la Affinity
Scheduling
Como se mencionó antes, Cloud Composer corre sobre un cluster de GKE en el que todos los DAGs, tareas y servicios se ejecutan en un único node pool. Cuando se ejecuta un DAG, un servicio dentro de Airflow llamado scheduler arma un plan de ejecución con el orden en que correrán las tareas.
Cuando arranca la ejecución de un DAG, el scheduler prepara cada tarea para que se ejecute en un servicio de Airflow llamado worker. Cuando el worker está listo para correr la tarea, le indica al servicio subyacente de Kubernetes que la ejecute. En ese proceso, Kubernetes hace bastante trabajo: determina si hay recursos disponibles para ejecutar la tarea y decide en qué nodo del node pool se ejecutará.
Por defecto, correrá la tarea en el nodo del node pool creado por Cloud Composer que el sistema considere mejor candidato. Dependiendo del tamaño de la instancia de Airflow, esto puede traducirse en bastantes DAGs, todos con un gran número de tareas, programados al mismo tiempo en el mismo node pool. Esto genera competencia por los recursos finitos disponibles en el node pool.
Affinity
Una solución que podrías considerar es ejecutar ciertas tareas en un nodo dedicado del node pool y nada más en ese nodo. Al proceso para lograrlo se le llama affinity, y a su opuesto, anti-affinity.
La affinity funciona aplicando una etiqueta a nodos específicos —o a todos— dentro de un node pool. Al definir una tarea dentro de un DAG, se utiliza una construcción llamada nodeSelector, que le indica al cluster de Kubernetes subyacente que ejecute esa tarea solo en un nodo con una etiqueta coincidente.
La anti-affinity es lo contrario: indica "no ejecutes esta tarea" en un nodo que coincida con una etiqueta específica. Así es posible programar ciertas tareas en ciertos nodos y no en otros, lo que permite una distribución específica del workload.
Si te da curiosidad cómo funciona esto a fondo, los detalles específicos de Kubernetes los puedes encontrar aquí.
Combinando KubernetesPodOperator y Node Pools
Para resolver el problema mencionado, vamos a combinar el KubernetesPodOperator, un node pool nuevo y dedicado a ejecutar estas tareas, y la affinity de Kubernetes. Esto garantiza que tus contenedores corran en un "sandbox" separado, donde los recursos no estén limitados por lo que seleccionaste al crear el entorno.
El código al que voy a hacer referencia está en GitHub aquí.
Dentro del archivo sample_dag.py hay un DAG con una estructura como esta:
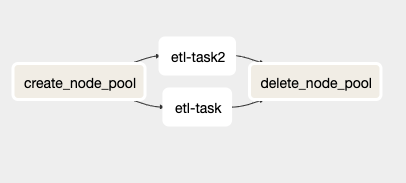
Vista del archivo sample_dag.py desde la UI de Airflow.
Este DAG tiene cuatro tareas distintas; dos de ellas (etl_task y etl_task2) son duplicadas y cualquier usuario final podrá reemplazarlas para ejecutar su propio código.
La tarea create_node_pool es un BashOperator que toma algunas variables de entorno preestablecidas (más sobre esto en una sección posterior), crea un nuevo node pool de GKE y guarda el nombre de ese node pool en una variable de Airflow. Este último paso es necesario porque el KubernetesPodOperator no permite usar variables de entorno dentro de su parámetro de affinity.
Las tareas etl_task y etl_task2 son tareas de muestra que creé para mostrar el KubernetesPodOperator en acción. Levantan un contenedor de Ubuntu 18.04 y duermen 120 segundos antes de apagarse. La parte clave de estas tareas, sin embargo, está en el código: muestra cómo configurar la affinity del operador para que tu cluster de GKE programe el contenedor en el node pool recién creado. Cubriré esto con más detalle en la siguiente sección.
La última tarea, delete_node_pool, es un BashOperator que elimina el node pool creado al completarse (o al fallar) el resto del DAG. Algo a destacar es que esta tarea siempre se ejecuta, incluso si otras tareas devuelven códigos de error. Esto es así para que no termines con un node pool corriendo y acumulando costos inesperados por culpa de un error.
Desglosando el código del KubernetesPodOperator
Aquí va una copia del código de etl_task tomado del archivo Python, con los comentarios y algunas líneas poco relevantes removidas (por ejemplo, los comandos de sleep):
etl_task = kubernetes_pod.KubernetesPodOperator(
task_id='etl-task',
name='etl',
namespace='default',
image='gcr.io/gcp-runtimes/ubuntu_18_0_4',
startup_timeout_seconds=720,
affinity={
'nodeAffinity': {
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{\
'matchExpressions': [{\
'values': [\
Variable.get("node_pool", default_var=node_pool_value)\
]\
}]\
}]
}
}
})
Notarás que resalté arriba el parámetro del objeto affinity, en el que quiero enfocarme aquí porque es muy específico de Kubernetes.
Lo que hace este código es indicarle a Kubernetes que, al programar (no al ejecutar) esta tarea, la asigne obligatoriamente a un nodo cuya etiqueta coincida con el nombre del node pool creado por la tarea create_node_pool. Lo hace mediante un nodeSelector, pidiéndole que haga match con una etiqueta que tenga el nombre del node pool creado. Cuando GKE crea un nuevo node pool, aplica automáticamente una etiqueta con el nombre del node pool a cada nodo, que es justamente con lo que estamos haciendo match en el código de arriba.
Algo a tener en cuenta es que toma el valor de la etiqueta desde la variable de Airflow node_pool. Si ejecutas múltiples instancias de este DAG, te recomiendo cambiar el nombre de esta variable para que sea específica de cada DAG. Eso sí, debido a limitaciones de Airflow, no puedes incluir plantillas ni código dinámico (como tomar una variable de entorno) dentro del objeto del parámetro affinity, o de lo contrario fallará al cargar el DAG.
Elementos configurables del DAG
Como este código crea un node pool que no es talla única para todos, agregué algunas variables de entorno que permiten ajustar opciones relacionadas con el node pool.
Esta es la lista de variables de entorno y sus funciones:
NODE_COUNT
Es el número de nodos que se aprovisionarán dentro del nuevo node pool. El valor por defecto es 3.
MACHINE_TYPE
Es el tipo de instancia (tamaño) de máquina virtual que se aprovisionará dentro del nuevo node pool. Si lo usas para workloads de corta duración y eliminas el node pool al finalizar, te recomiendo mucho usar tipos de máquina E2, ya que estos ya tienen incorporado el sustained-use-discount en el precio y, por lo tanto, resultan más baratos para workloads de vida corta. El valor por defecto es e2-standard-8 (8 vCPU y 32 GB de RAM).
SCOPES
Contiene los scopes de GCP que se asocian a las instancias del node pool. Por ejemplo, permitir el acceso a BigQuery y Pub/Sub, además de poder escribir logs, requeriría los siguientes scopes: bigquery, pubsub, logging-write. El valor por defecto es default,cloud-platform.
Esta fue una forma muy sencilla de ejecutar contenedores dentro de un DAG en Cloud Composer. No es el camino más fácil, pero lamentablemente, debido a las limitaciones que imponen los servicios administrados, a veces hay que dar pasos como estos hasta que el proveedor implemente una solución nativa de primera mano.
A mí, en lo personal, me encantaría ver la posibilidad de especificar affinity para más tareas además del KubernetesPodOperator, porque a veces tareas distintas a las basadas en contenedores también pueden causar estos problemas, en particular las tareas de operadores de Python o Bash.

¡Gracias por leer! Para mantenerte al día, síguenos en el DoiT Engineering Blog, el canal de DoiT en LinkedIn y el canal de DoiT en Twitter. Para explorar oportunidades laborales, visita https://careers.doit-intl.com.