Der Knackpunkt beim _KubernetesPodOperator_ in Composer
Die Klasse KubernetesPodOperator ist das Mittel der Wahl, um Container auf Cloud Composer auszuführen – sie hat allerdings einen entscheidenden Haken: Sie führt sämtliche Container auf denselben Nodes aus, auf denen auch die DAGs in Airflow laufen. Damit konkurriert sie unmittelbar mit ihnen um Ressourcen.
Was zunächst harmlos klingt, kann in der Praxis zu ernsthaften Problemen führen. Bei einem unserer Kunden traten beispielsweise Exceptions beim Ausführen von Containern innerhalb eines DAGs auf, weil andere DAGs zu viel Arbeitsspeicher belegten.
Der zugrunde liegende GKE-Cluster konnte keine weiteren DAGs und Tasks mehr einplanen, sodass Airflow bei jedem Versuch, einen KubernetesPodOperator-Task auszuführen, eine Timeout-Exception warf. Dadurch ließ sich ein geschäftskritischer DAG mit einem Container nicht mehr starten. Wäre es ein DAG zur Berechnung von Gehältern oder Jahresend-Boni gewesen, hätte das gravierende Folgen gehabt.
Damit kommen wir zur Lösung – zunächst aber ein paar kurze Erläuterungen zur Funktionsweise von GKE. Wer sich damit bereits auskennt, kann die nächsten beiden Abschnitte überspringen und direkt zur Lösung springen.
Stichwort Node Pools
Für alle, die mit GKE oder Managed-Kubernetes-Umgebungen nicht vertraut sind: Nodes werden dort zu sogenannten Node Pools zusammengefasst. Wenn Pods und workloads eingeplant werden, laufen sie auf einem oder mehreren Nodes innerhalb des zugehörigen Node Pools. Ein Cluster kann mehrere Node Pools enthalten – und tut dies häufig auch.
Beim Anlegen einer Cloud-Composer-Instanz wird ein GKE-Cluster mit einem einzigen Node Pool erstellt, der die konfigurierte Größe und Anzahl an Nodes enthält. Auf diesem Node Pool laufen standardmäßig alle DAGs samt zugehöriger Tasks sowie sämtliche Services, die von der Cloud-Composer-Instanz erstellt und orchestriert werden (mit Ausnahme der dahinterliegenden MySQL-Datenbank).
Da dieser Node Pool eine vorkonfigurierte Anzahl an Nodes und Instanzgrößen enthält, sind die Ressourcen hier sehr begrenzt. Es gibt zwar eine Autoscaling-Funktion, doch zum Zeitpunkt der Veröffentlichung lässt sich die Größe der Nodes nicht ändern. Folglich werden lediglich weitere Instanzen derselben Größe zum Node Pool hinzugefügt. Wenn ein Task innerhalb eines DAGs mehr Speicher benötigt, als ein Node bereitstellen kann, führt das mit hoher Wahrscheinlichkeit zu den oben beschriebenen Exceptions.
Wie also lässt sich das beheben? Indem Sie einen eigenen Node Pool anlegen, der ausschließlich für Tasks mit Containern reserviert ist. Wer mit Kubernetes vertraut ist, denkt jetzt vermutlich an das Thema Affinity. Genau das ist die Lösung – und der Grund, warum sich dies derzeit nur für Tasks mit Containern umsetzen lässt.
Wie Scheduling und Affinity funktionieren
Scheduling
Wie bereits erwähnt, läuft Cloud Composer auf einem GKE-Cluster, wobei alle DAGs, Tasks und Services auf einem einzigen Node Pool ausgeführt werden. Bei der Ausführung eines DAGs erstellt ein Service innerhalb von Airflow – der Scheduler – einen Ausführungsplan mit der Reihenfolge, in der die Tasks abgearbeitet werden.
Sobald die Ausführung eines DAGs startet, bereitet der Scheduler jeden Task für die Ausführung durch einen weiteren Airflow-Service vor: den Worker. Ist der Worker bereit, weist er den darunterliegenden Kubernetes-Service an, den Task auszuführen. Dabei prüft Kubernetes ausgiebig, ob ausreichend Ressourcen verfügbar sind. Außerdem entscheidet es, auf welchem Node im Node Pool der Task läuft.
Standardmäßig läuft der Task auf demjenigen Node im von Cloud Composer erstellten Node Pool, den das System für am besten geeignet hält. Je nach Größe der Airflow-Instanz können das etliche DAGs sein, die jeweils zahlreiche Tasks gleichzeitig auf demselben Node Pool einplanen. Das führt zu einem Konkurrenzkampf um die begrenzten Ressourcen im Node Pool.
Affinity
Eine Lösung könnte darin bestehen, bestimmte Tasks ausschließlich auf einem dedizierten Node innerhalb des Node Pools auszuführen – und sonst nichts. Dieses Verfahren nennt sich Affinity, das Gegenstück Anti-Affinity.
Affinity funktioniert über Labels, die einzelnen oder allen Nodes eines Node Pools zugewiesen werden. Bei der Definition eines Tasks innerhalb eines DAGs kommt ein Konstrukt namens nodeSelector zum Einsatz, das den darunterliegenden Kubernetes-Cluster anweist, diesen Task ausschließlich auf einem Node mit passendem Label auszuführen.
Anti-Affinity ist das Gegenteil und besagt sinngemäß: "Diesen Task nicht auf einem Node mit diesem Label ausführen." Damit lassen sich bestimmte Tasks gezielt bestimmten Nodes zuweisen und so eine spezifische Verteilung der workloads erreichen.
Wer wissen möchte, wie das im Detail funktioniert, findet die Kubernetes-Spezifika dazu hier.
KubernetesPodOperator und Node Pools kombinieren
Um das eingangs beschriebene Problem zu lösen, kombinieren wir den KubernetesPodOperator mit einem neuen, dedizierten Node Pool für solche Tasks und setzen Kubernetes-Affinity ein. So laufen Ihre Container in einer separaten "Sandbox", in der die Ressourcen nicht durch die ursprünglich gewählte Konfiguration der Umgebung begrenzt sind.
Den Code, auf den ich mich beziehe, finden Sie auf GitHub hier.
In der Datei sample_dag.py befindet sich ein DAG mit folgender Struktur:
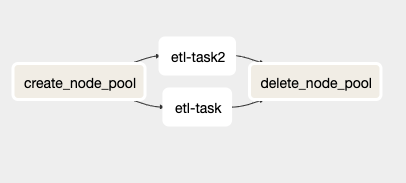
Ansicht der Datei sample_dag.py im Airflow-UI.
Dieser DAG enthält vier verschiedene Tasks, von denen zwei (etl_task und etl_task2) Duplikate sind und vom Endanwender durch eigenen Code ersetzt werden sollen.
Der Task create_node_pool ist ein BashOperator, der einige vorab gesetzte Umgebungsvariablen einliest (mehr dazu in einem späteren Abschnitt), einen neuen GKE-Node-Pool erstellt und dessen Namen in einer Airflow-Variablen ablegt. Der letzte Schritt ist erforderlich, weil der KubernetesPodOperator innerhalb seines affinity-Arguments keine Umgebungsvariablen zulässt.
Die Tasks etl_task und etl_task2 sind Beispiel-Tasks, die ich erstellt habe, um den KubernetesPodOperator in Aktion zu zeigen. Sie starten einen Ubuntu-18.04-Container und schlafen 120 Sekunden, bevor sie sich beenden. Der entscheidende Teil dieser Tasks steckt jedoch im Code: Er zeigt, wie die Affinity für den Operator konfiguriert wird, sodass Ihr GKE-Cluster den Container auf dem neu erstellten Node Pool einplant. Im nächsten Abschnitt gehe ich darauf näher ein.
Der letzte Task, delete_node_pool, ist ein BashOperator, der den erstellten Node Pool nach Abschluss (oder bei einem Fehler) des restlichen DAGs wieder löscht. Wichtig: Dieser Task läuft immer – auch wenn andere Tasks Fehlercodes zurückgeben. So vermeiden Sie, dass ein Node Pool aufgrund eines Fehlers ungewollt weiterläuft und unerwartete Kosten verursacht.
Der KubernetesPodOperator-Code im Detail
Hier ein Auszug aus dem etl_task-Code aus der Python-Datei, bei dem die Kommentare und einige weniger wichtige Zeilen (z. B. die sleep-Befehle) entfernt wurden:
etl_task = kubernetes_pod.KubernetesPodOperator(
task_id='etl-task',
name='etl',
namespace='default',
image='gcr.io/gcp-runtimes/ubuntu_18_0_4',
startup_timeout_seconds=720,
affinity={
'nodeAffinity': {
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{\
'matchExpressions': [{\
'values': [\
Variable.get("node_pool", default_var=node_pool_value)\
]\
}]\
}]
}
}
})
Ich habe den affinity-Objektparameter oben hervorgehoben, denn genau darauf möchte ich mich konzentrieren – er ist sehr Kubernetes-spezifisch.
Der Code weist Kubernetes an, diesen Task beim Scheduling (nicht bei der Ausführung) zwingend auf einem Node mit einem Label einzuplanen, das dem Namen des im create_node_pool-Task erzeugten Node Pools entspricht. Realisiert wird das über einen nodeSelector, der ein Label mit dem Namen des erzeugten Node Pools abgleicht. Wenn GKE einen neuen Node Pool erstellt, weist es jedem Node automatisch ein Label mit dem Namen des Node Pools zu – und genau dagegen prüfen wir im obigen Code.
Beachten Sie, dass der Label-Wert aus der Airflow-Variablen node_pool gelesen wird. Wenn Sie mehrere Instanzen dieses DAGs parallel ausführen, empfehle ich, diesen Variablennamen DAG-spezifisch zu wählen. Beachten Sie außerdem, dass Airflow-bedingt keine Templates oder dynamischen Code-Aufrufe (etwa das Auslesen einer Umgebungsvariablen) im affinity-Parameterobjekt verwendet werden dürfen – andernfalls schlägt das Laden des DAGs fehl.
Konfigurierbare Optionen für den DAG
Da der Code einen Node Pool erstellt, der nicht für jedes Szenario passt, habe ich einige Umgebungsvariablen eingeführt, mit denen sich Optionen rund um den Node Pool anpassen lassen.
Hier die Liste der Umgebungsvariablen und ihrer Funktionen:
NODE_COUNT
Die Anzahl der Nodes, die im neuen Node Pool bereitgestellt werden. Standardwert: 3.
MACHINE_TYPE
Der Instanztyp (die Größe) der virtuellen Maschine, die im neuen Node Pool bereitgestellt wird. Wenn Sie diesen Ansatz für kürzer laufende workloads nutzen und den Node Pool nach Abschluss wieder entfernen, empfehle ich dringend die E2-Maschinentypen: Bei ihnen ist der Sustained-Use-Discount bereits im Preis enthalten, wodurch sie für kurzlebige workloads günstiger sind. Standardwert: e2-standard-8 (8 vCPU und 32 GB RAM).
SCOPES
Enthält die GCP-Scopes, die den Instanzen im Node Pool zugewiesen werden. So würden beispielsweise der Zugriff auf BigQuery und Pub/Sub sowie das Schreiben von Logs folgende Scopes erfordern: bigquery, pubsub, logging-write. Standardwert: default,cloud-platform.
Das war ein sehr einfacher Weg, Container innerhalb eines DAGs auf Cloud Composer auszuführen. Der bequemste ist es nicht – aber wegen der Einschränkungen von Managed Services sind solche Schritte mitunter nötig, bis der Anbieter eine native First-Party-Lösung bereitstellt.
Ich persönlich würde es sehr begrüßen, wenn sich Affinity nicht nur für KubernetesPodOperator-Tasks festlegen ließe – denn manchmal verursachen auch andere Tasks ähnliche Probleme, etwa Python- oder Bash-Operator-Tasks.

Vielen Dank fürs Lesen! Bleiben Sie mit uns in Kontakt – über den DoiT Engineering Blog, den DoiT LinkedIn-Kanal und den DoiT Twitter-Kanal. Karrieremöglichkeiten finden Sie unter https://careers.doit-intl.com.