Composerにおける _KubernetesPodOperator_ の落とし穴
Cloud Composer上でコンテナを実行する手段が KubernetesPodOperator クラスですが、ここには大きな弱点があります。それは、コンテナがすべてAirflow上のDAGと同じノードで実行されてしまうという点です。つまり、コンテナとDAGがリソースを奪い合うことになります。
一見大した問題ではないように思えるかもしれませんが、実際にはトラブルにつながるケースが少なくありません。たとえば、あるお客様の環境では、他のDAGがメモリを大量に消費していたために、DAG内で動作しているコンテナが例外を発生させ始めたことがありました。
基盤となるGKEクラスタが追加のDAGやタスクをスケジュールできなくなり、Airflowは KubernetesPodOperator タスクを実行しようとするたびにタイムアウト例外をスローするようになりました。その結果、コンテナを含むミッションクリティカルなDAGが実行できない状態になったのです。もしこれが年末の給与計算や賞与計算を担うDAGだったとしたら、間違いなく深刻な事態を招いていたでしょう。
そこで本題の解決策に入っていきますが、その前にGKEの仕組みについて簡単に触れておきます。GKEに精通している方は、次の2つのセクションを読み飛ばして解決策に進んでいただいて構いません。
ノードプールという概念
GKEやマネージドKubernetes環境に馴染みのない方のために説明すると、ノードはノードプールと呼ばれる単位でグループ化されます。ポッドやworkloadsがスケジュールされると、対応するノードプール内の1つ以上のノード上で実行されます。1つのクラスタが複数のノードプールを持つことも珍しくありません。
Cloud Composerインスタンスを作成すると、設定したサイズと台数のノードを含む単一のノードプールを持つGKEクラスタが構築されます。このノードプールは既定で、すべてのDAGおよび関連タスクに加え、Cloud Composerインスタンスが作成・オーケストレーションするすべてのサービス(バックエンドのMySQLデータベースを除く)を実行します。
このノードプールはノード数とインスタンスサイズがあらかじめ決められているため、利用できるリソースには限りがあります。オートスケーリング機能は用意されていますが、本記事の執筆時点ではノードのサイズを変更することはできません。そのため、追加されるのは同じサイズのインスタンスのみです。DAG内のタスクが1ノードの上限を超えるメモリを必要とすると、先ほど紹介したような例外が発生する可能性が高くなります。
では、どう解決すればよいのでしょうか。答えは、コンテナを含むタスク専用のノードプールを別途用意することです。Kubernetesに詳しい方であれば、ここでアフィニティの概念が頭に浮かぶはずです。まさにそれがこの問題への解決策であり、本記事執筆時点ではコンテナを実行するタスクに限ってこの方法が使える理由でもあります。
スケジューリングとアフィニティの仕組み
スケジューリング
前述のとおり、Cloud ComposerはGKEクラスタ上で動作し、すべてのDAG、タスク、サービスは単一のノードプール上で稼働します。DAGが実行されると、Airflow内のスケジューラと呼ばれるサービスが、タスクの実行順序を定めた実行計画を作成します。
DAGの実行が始まると、スケジューラは各タスクをAirflow内のワーカーと呼ばれるサービスで実行できるよう準備します。ワーカーがタスクを実行できる状態になると、基盤のKubernetesサービスにタスクの実行を指示します。この過程でKubernetesは多くの処理を行い、タスクを実行可能なリソースが空いているかを判定します。さらに、ノードプール内のどのノードでタスクを実行するかも決定します。
既定では、Cloud Composerが作成したノードプール内のうち、システムが最適と判断したノード上でタスクが実行されます。Airflowインスタンスの規模によっては、多数のDAGとその中で動く大量のタスクが、同じノードプール上で同時にスケジュールされることになります。その結果、ノードプールの限られたリソースを巡って競合が発生します。
アフィニティ
解決策のひとつとして、特定のタスクをノードプール内の専用ノードでだけ実行し、そのノードでは他のものを動かさない、というアプローチが考えられます。これを実現する仕組みがアフィニティ(affinity)であり、その逆がアンチアフィニティ(anti-affinity)です。
アフィニティは、ノードプール内の特定のノード、もしくはすべてのノードにラベルを付与することで機能します。DAG内のタスク定義を作成する際にnodeSelectorと呼ばれる構成要素を使うと、基盤のKubernetesクラスタに対して「一致するラベルを持つノード上でのみそのタスクを実行する」よう指示できます。
アンチアフィニティはその逆で、特定のラベルに一致するノードでは「このタスクを実行しない」と指定します。これにより、特定のタスクを特定のノードに割り当て、それ以外のノードでは実行しないといったworkloadsの配分が可能になります。
内部的な動作にご興味のある方は、Kubernetesの具体的な仕様をこちらからご確認いただけます。
KubernetesPodOperatorとノードプールを組み合わせる
前述の課題を解決するために、KubernetesPodOperator、これらのタスク専用に新規作成するノードプール、そしてKubernetesアフィニティを組み合わせます。これにより、コンテナは独立した「サンドボックス」内で実行され、環境作成時に選択した設定にリソースが縛られることはなくなります。
参照するコードはGithubのこちらに置いてあります。
sample_dag.pyファイル内には、次のような構造のDAGが定義されています:
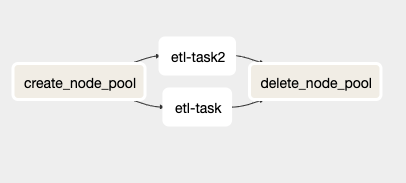
sample_dag.pyファイルをAirflow UIで表示した様子。
このDAGには4つのタスクがあり、そのうち2つ(etl_task と etl_task2)は同一内容で、エンドユーザーが独自のコードに差し替えて使うためのプレースホルダーです。
create_node_pool タスクはBashOperatorで、事前に設定された環境変数(詳細は後述)を読み込み、新しいGKEノードプールを作成し、そのノードプール名をAirflow変数に保存します。最後の手順が必要な理由は、KubernetesPodOperator ではアフィニティ引数の中で環境変数を使えないためです。
etl_task と etl_task2 は KubernetesPodOperator の動作を示すために用意したサンプルタスクです。Ubuntu 18.04のコンテナを起動し、120秒スリープしてから終了します。重要なのはコードの中身です。オペレーターのアフィニティを設定し、新しく作成したノードプール上でコンテナをスケジュールするようGKEクラスタに指示する方法を示しています。詳細は次のセクションで解説します。
最後の delete_node_pool タスクもBashOperatorで、DAGの残りのタスクが完了(またはエラー終了)した時点で、作成済みのノードプールを削除します。注目すべき点は、他のタスクがエラーコードを返した場合でも、このタスクは必ず実行されることです。これにより、エラーをきっかけにノードプールが起動したままとなり、想定外のコストが発生するのを防ぎます。
KubernetesPodOperatorのコードを読み解く
以下は、上述のPythonファイルから etl_task のコードを抜粋し、コメントや本筋に関係のない数行(sleepコマンドなど)を省いたものです:
etl_task = kubernetes_pod.KubernetesPodOperator(
task_id='etl-task',
name='etl',
namespace='default',
image='gcr.io/gcp-runtimes/ubuntu_18_0_4',
startup_timeout_seconds=720,
affinity={
'nodeAffinity': {
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{\
'matchExpressions': [{\
'values': [\
Variable.get("node_pool", default_var=node_pool_value)\
]\
}]\
}]
}
}
})
上のコードでaffinityオブジェクトのパラメータを強調しているのは、ここがKubernetes固有の部分であり、特に注目してほしいポイントだからです。
このコードがKubernetesに伝えているのは、「このタスクをスケジュールする際に(実行時ではなくスケジュール時に)、create_node_pool タスクで作成したノードプールの名前と一致するラベルを持つノードに必ず割り当てよ」ということです。これはnodeSelectorを用いて、作成したノードプール名と一致するラベルを指定することで実現しています。GKEは新しいノードプールを作成すると、そのノードプール名をラベルとして自動的に各ノードに付与します。上のコードは、このラベルに対してマッチングを行っているのです。
注意点として、ラベルの値はAirflow変数 node_pool から取得しています。このDAGを複数インスタンス並行で動かす場合は、変数名をDAGごとに変えることをおすすめします。ただし、Airflowの制約上、affinityパラメータオブジェクトの中にテンプレートや動的なコード(環境変数の取得など)を入れることはできません。入れてしまうとDAGの読み込みに失敗するのでご注意ください。
DAGで設定可能な項目
このコードで作成するノードプールは万人向けの設定ではないため、ノードプール関連のオプションを調整できるよう、いくつかの環境変数を用意しました。
以下が環境変数とその役割の一覧です:
NODE_COUNT
新しいノードプールにプロビジョニングされるノード数です。既定値は3です。
MACHINE_TYPE
新しいノードプールにプロビジョニングされる仮想マシンのインスタンスタイプ(サイズ)です。短時間で終わるworkloadsで、完了後にノードプールを削除する使い方であれば、E2マシンタイプを強くおすすめします。E2タイプは継続利用割引があらかじめ価格に組み込まれているため、短命なworkloadsではよりコスト効率に優れます。既定値はe2-standard-8(8 vCPU、32GB RAM)です。
SCOPES
ノードプール内のインスタンスに付与されるGCPスコープです。たとえばBigQueryやPub/Subへのアクセスに加えてログ書き込みも許可したい場合は、bigquery、pubsub、logging-writeを指定します。既定値はdefault,cloud-platformです。
以上が、Cloud ComposerのDAG内でコンテナを実行するごくシンプルな方法です。けっして手軽な方法とは言えませんが、マネージドサービスならではの制約があるため、プロバイダーがネイティブな公式ソリューションを提供してくれるまでは、こうした工夫が必要になる場面もあります。
個人的には、KubernetesPodOperator 以外のタスクでもアフィニティを指定できるようになってほしいと願っています。というのも、コンテナベース以外のタスク、特にPythonやBashのオペレータータスクでも同様の問題が起こり得るからです。

お読みいただきありがとうございました! 最新情報は DoiT Engineering Blog 、 DoiT Linkedin Channel 、 DoiT Twitter Channel でぜひフォローしてください。採用情報は https://careers.doit-intl.com からご覧いただけます。