Si vous diffusez des données vers AWS IoT Core, leur stockage et leur visualisation sont des composants critiques en aval, à concevoir bien en amont pour soutenir des analyses à l'échelle du big data.
Dans la continuité de mon précédent article sur l'intégration sécurisée d'une flotte d'appareils IoT à l'échelle de la production dans l'AWS IoT Registry et la diffusion de données vers IoT Core, ce nouvel article présente les différents services serverless AWS à mobiliser pour stocker et manipuler ces données en toute sécurité une fois qu'elles arrivent sur la plateforme AWS.

Vue d'ensemble
Cet article s'articule autour des sections suivantes :
- Stockage des données en streaming
- Visualisation des données en streaming
Contrairement à la première partie, ce qui suit peut être réalisé via la console web AWS : aucune expérience en programmation n'est donc requise.
Les services AWS suivants seront abordés : IoT Core Rules, IoT Analytics, DynamoDB et Quicksight.
Stockage des données en streaming
Vérification de l'intégration IoT
Si vous avez correctement intégré vos appareils dans le registre IoT et lancé la diffusion des données vers IoT Core, un flux régulier de messages doit apparaître sur le dashboard principal AWS IoT :
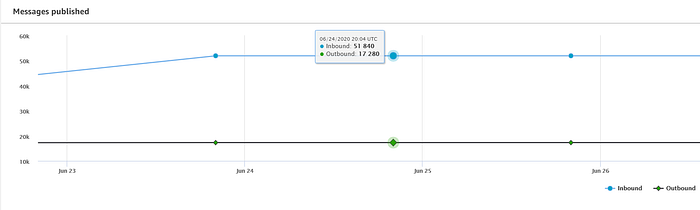
Le script de streaming de température fourni dans la première partie envoie des relevés à IoT Core toutes les 5 secondes. J'ai enregistré trois Raspberry Pi chez moi — un dans la mezzanine à l'étage, un dans le salon au rez-de-chaussée et un dans une chambre au sous-sol — et je m'attends donc à voir les 51 840 messages publiés par jour indiqués ci-dessus (17 280 messages par appareil).
La console web IoT facilite considérablement le transfert de ces messages vers différents services AWS pour traitement et stockage. Quel que soit le service de destination, envoyer des données IoT vers un autre service AWS revient simplement à créer une IoT Rule dans la console web. Voyons comment procéder en configurant une table DynamoDB simple et en y envoyant l'ensemble des données en streaming.
Streaming vers DynamoDB
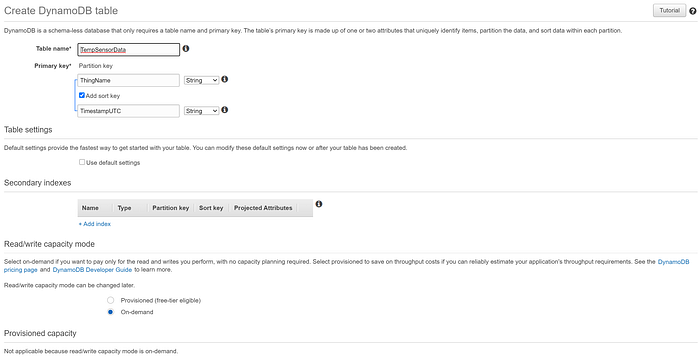
Créez une table DynamoDB nommée TempSensorData, avec une Partition key ThingName et une sort key TimestampUTC, correspondant aux valeurs de clé primaire diffusées vers IoT Core. Configurez la table en capacité On-demand plutôt que provisionnée, afin de réduire les coûts pendant ce petit test. Et c'est tout ! Lorsque nous configurerons une IoT Rule qui transmettra les données à cette table, la règle identifiera les champs hors clé dans nos données et les renseignera automatiquement :
Une fois la table provisionnée, retournez sur la plateforme IoT Core et accédez à Act → Rules, puis créez une nouvelle règle. Nommez-la TemperatureSensorRule, ajoutez une description et définissez la requête de la règle pour sélectionner toutes les valeurs diffusées vers le topic de haut niveau temperature.
Comment créer une règle qui capture toutes les valeurs de température alors que chaque appareil diffuse vers son propre topic unique ? La solution passe par les caractères génériques IoT SQL. Rappelons que chaque appareil diffuse vers un topic défini par trois variables de policy d'appareil qui, ensemble, créent un topic unique :
temperature/${iot:Connection.Thing.Attributes[BuildingName]}/${iot:Connection.Thing.Attributes[Location]}/${iot:Connection.Thing.ThingName}
Voici par exemple les topics vers lesquels publient les trois appareils chez moi :
temperature/house417/loft/sensor_7210b5ba84f64cbbb406e98a1c3b3d32
temperature/house417/living_room/sensor_d51ea63b02bf4cb5b8ac9cf9b464ec3a
temperature/house417/downstairs_bedroom/sensor_b912a3f3c85f4b44ba60720ee43a1a94
Le topic IoT à sélectionner dans votre règle IoT SQL sera temperature/#, le caractère générique # correspondant à un ou plusieurs sous-chemins. La requête IoT SQL à utiliser est donc la suivante :
SELECT * FROM 'temperature/#'
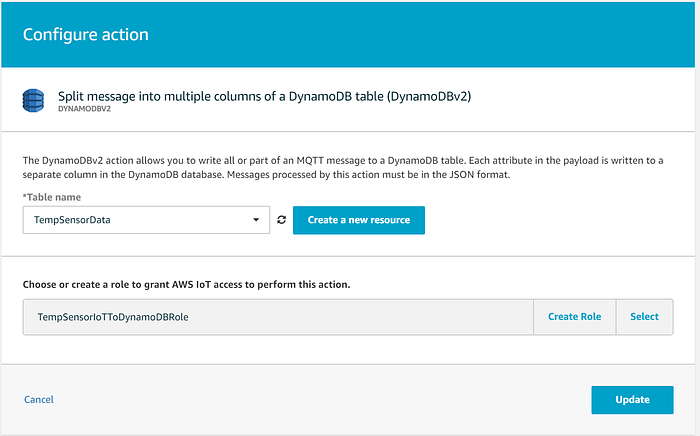
Cliquez ensuite sur Add action et sélectionnez l'option qui envoie les données vers une table DynamoDB. Attention : veillez à choisir l'option DynamoDBv2, car la v1 ne renseigne pas automatiquement les champs hors clé et stocke à la place le message complet dans la table sous forme d'un unique champ JSON sérialisé en chaîne :

Sélectionnez ensuite la table DynamoDB de destination et autorisez l'assistant à créer un rôle accordant à AWS IoT les permissions nécessaires pour y envoyer les données :
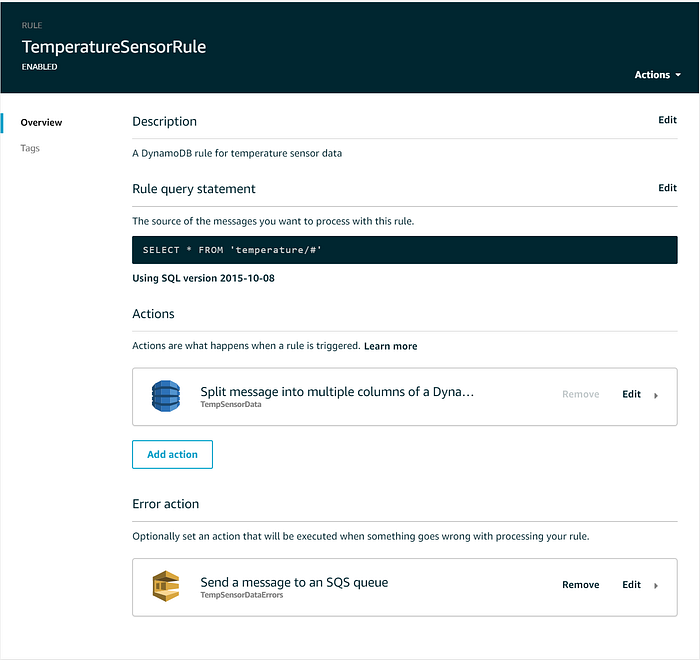
Une fois la règle IoT Core créée, vous pouvez éventuellement ajouter une Error action qui redirige les échecs de livraison de message vers, par exemple, une dead letter queue SQS ou un bucket S3. Une fois finalisée, votre IoT Rule devrait ressembler à ceci :
Au bout de quelques secondes, la table commence à se remplir :
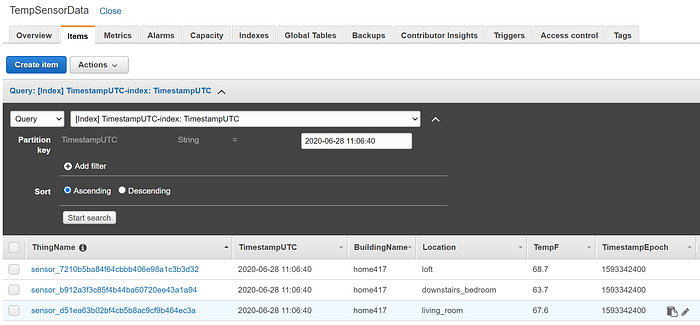
À partir de là, vous pourriez créer des applications d'analyse et de visualisation personnalisées qui s'alimentent depuis DynamoDB. Plus réalistement, en contexte de production (et trop coûteux pour les besoins d'une démo), vous pourriez transférer les données IoT vers un flux Kinesis Firehose plutôt que vers DynamoDB. Ce flux Firehose effectuerait alors des écritures par lots vers un data warehouse comme Redshift et/ou un object store comme S3 ; ces écritures groupées sont essentielles pour éviter que des écritures unitaires issues d'un streaming IoT à l'échelle de la production ne dégradent les performances de Redshift ou n'atteignent les limites de débit en écriture de S3. Redshift, DynamoDB et S3 sont tous d'excellentes sources pour des applications d'analyse à l'échelle du big data.
Vous pourriez par exemple déployer un job Apache Spark sur AWS EMR ou un modèle de machine learning sur AWS Sagemaker, et faire en sorte que l'un de ces services s'alimente depuis DynamoDB, Redshift ou S3.
Cependant, dans cet article, je souhaite me concentrer sur une approche purement serverless du stockage et de la visualisation, sans aucune ligne de code. Dans cette optique, voyons comment, de manière serverless, stocker nos données brutes et nos jeux de données filtrés avec des politiques de cycle de vie via le datastore time-series IoT Analytics, puis utiliser Quicksight pour la visualisation. Comme Quicksight ne peut pas s'alimenter depuis DynamoDB, que Redshift comme source revient un peu cher pour une démo, et qu'IoT Analytics répond facilement à nos besoins de stockage serverless à haut débit et de récupération par QuickSight, nous retiendrons IoT Analytics comme datastore.
Streaming vers IoT Analytics
Accédez au service IoT Analytics et utilisez l'assistant Quick Create pour lancer une création en un clic permettant de diffuser les données dans IoT Analytics depuis notre topic temperature IoT Core. Ce processus créera :
- Un channel destiné à recevoir les données IoT brutes depuis IoT Core, ainsi que la IoT Core Rule qui y transfère les données
- Une pipeline permettant de filtrer et transformer les données du channel, de manière facultative
- Un data store pour les données issues de la pipeline, avec une période de rétention associée
- Un dataset filtré à partir du data store, avec sa propre période de rétention et un calendrier de recréation périodique. Ce dataset filtré servira à Quicksight pour générer ses analyses et ses visualisations.
La configuration de tous ces composants IoT Analytics se résume à remplir les deux champs Quick Start suivants :
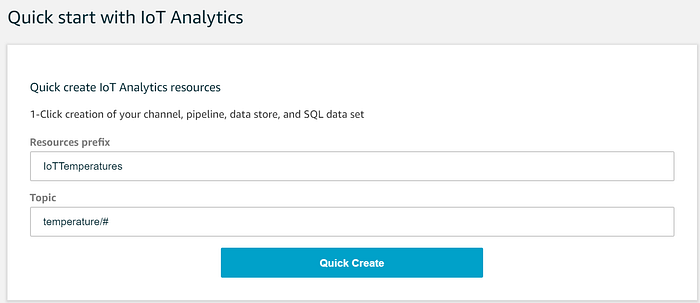
L'assistant créera ensuite les entrées Channel, Pipeline, Data Store et Data Set requises. Le rôle de ces composants IoT Analytics et les actions menées par l'assistant ne sont pas explicites : entrons donc dans le détail.
Un Channel IoT Analytics est le point d'arrivée des données en streaming. Si vous revenez à la liste des IoT Core Rules, vous remarquerez que l'assistant a créé une règle identique à la règle DynamoDB configurée précédemment, à ceci près que l'Action effectuée transfère désormais les données vers le channel que l'assistant vient de créer dans la plateforme IoT Analytics. Notez que pour capturer les livraisons de message en erreur, vous devrez mettre à jour la règle afin de spécifier une destination comme une queue SQS :

Une Pipeline IoT Analytics permet, de manière facultative, d'enrichir, transformer et filtrer les messages selon leurs attributs. La manipulation des données brutes n'étant pas nécessaire pour notre exemple, nous conserverons les paramètres par défaut de la Pipeline.
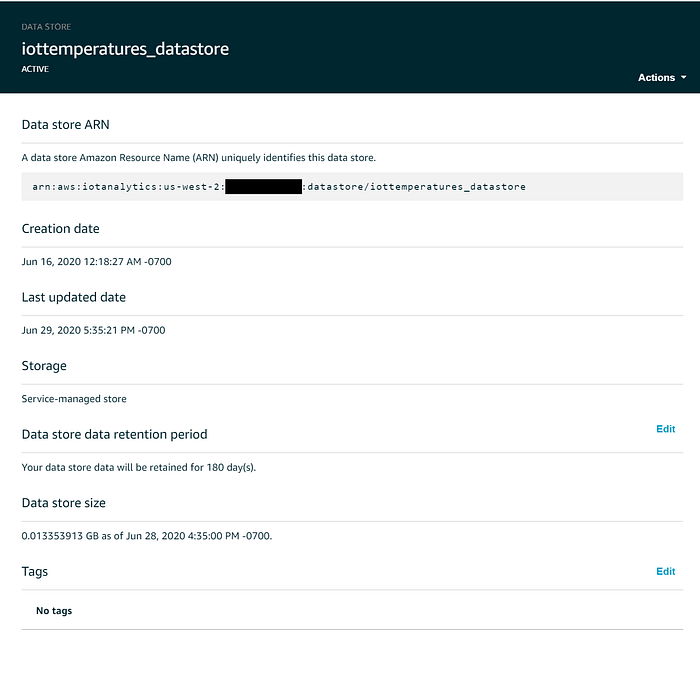
Les Data stores IoT sont l'endroit où sont stockées les données en streaming, soit indéfiniment, soit pendant une durée déterminée. En coulisses, ces données sont stockées dans un bucket S3 géré par AWS : vous bénéficiez donc toujours des 11 9 de durabilité et des 99,99 % de haute disponibilité du service. Si nécessaire, un data store peut être configuré pour enregistrer les données dans un bucket S3 que vous contrôlez, ce qui facilite la récupération et l'utilisation des données IoT par des services qui s'intègrent moins bien à IoT Analytics ; pour cette démo, nous resterons toutefois sur le bucket caché géré par le service.
Par défaut, les données diffusées dans un data store IoT Analytics sont conservées indéfiniment ; ce paramètre peut être modifié dans la console web en cliquant sur Edit à côté de Data store data retention period. Pour maîtriser les coûts d'un déploiement IoT à l'échelle de la production, faites expirer les données du Data Store après une certaine période. J'ai configuré l'expiration de mes valeurs de température au bout de six mois :

Un IoT Data Set est un sous-ensemble d'un IoT Data Store créé en IoT SQL, qui possède sa propre période de rétention et qui peut être recréé à la demande ou selon un calendrier récurrent. Comme les Data Stores, les Data Sets sont stockés sous forme de fichiers CSV dans un bucket géré par le service. Concrètement, les Data Sets vous permettent de créer un jeu de données statique basé sur un filtre personnalisé (par exemple, sélectionner toutes les données de température sur une fenêtre temporelle restreinte mais pertinente), de le générer une seule fois à la demande, puis de le conserver indéfiniment pour les analyses en aval, tout en laissant expirer les messages bruts d'origine du data store selon une période de rétention que votre organisation juge la plus à même d'équilibrer conservation des données brutes et maîtrise des coûts.
Certains services AWS qui s'intègrent à IoT Analytics, comme Quicksight, ne s'alimentent qu'à partir des data sets, tandis que d'autres comme SageMaker peuvent puiser à la fois dans les data stores et les data sets. De manière générale, tous les services devraient pouvoir exploiter les data sets. En raison de la connectivité plus limitée avec les data stores et du coût d'un stockage indéfini de données brutes dans IoT Analytics, en contexte de production, mieux vaut prendre l'habitude de créer des datasets discrets et filtrés, à utiliser dans les analyses ou la génération de modèles de ML, en laissant expirer le data store brut au fil du temps — sauf si votre organisation accepte de payer pour le stockage de l'historique complet des données IoT.
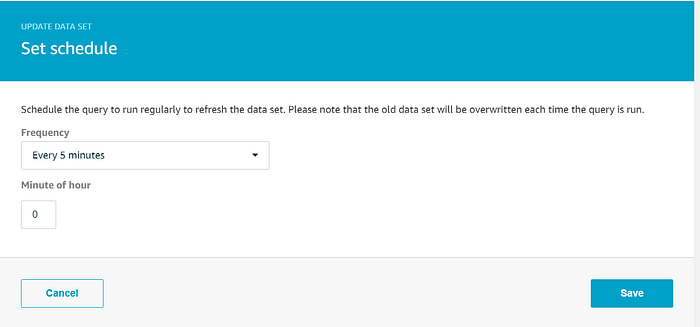
L'assistant aura créé un data set qui sélectionne toutes les données du data store ; deux ajustements restent toutefois à faire. Comme nous prévoyons d'utiliser l'ensemble des données du data store pour notre visualisation Quicksight, nous laisserons la requête SQL telle quelle. En revanche, nous voulons que Quicksight affiche les températures les plus à jour : plutôt que de recréer le data set à la demande, configurons un cron job pour le régénérer toutes les 5 minutes. Cliquez sur Edit à côté de Schedule et définissez la fréquence de recréation souhaitée :
Nous voulons que le data set soit conservé pendant 180 jours, en cohérence avec la période de rétention de notre data store, et nous voulons désactiver la rétention de plusieurs versions :
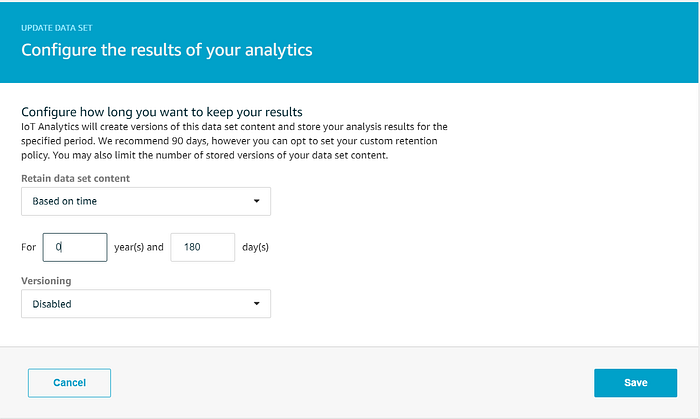
Le data set destiné à Quicksight devrait ressembler à ceci :
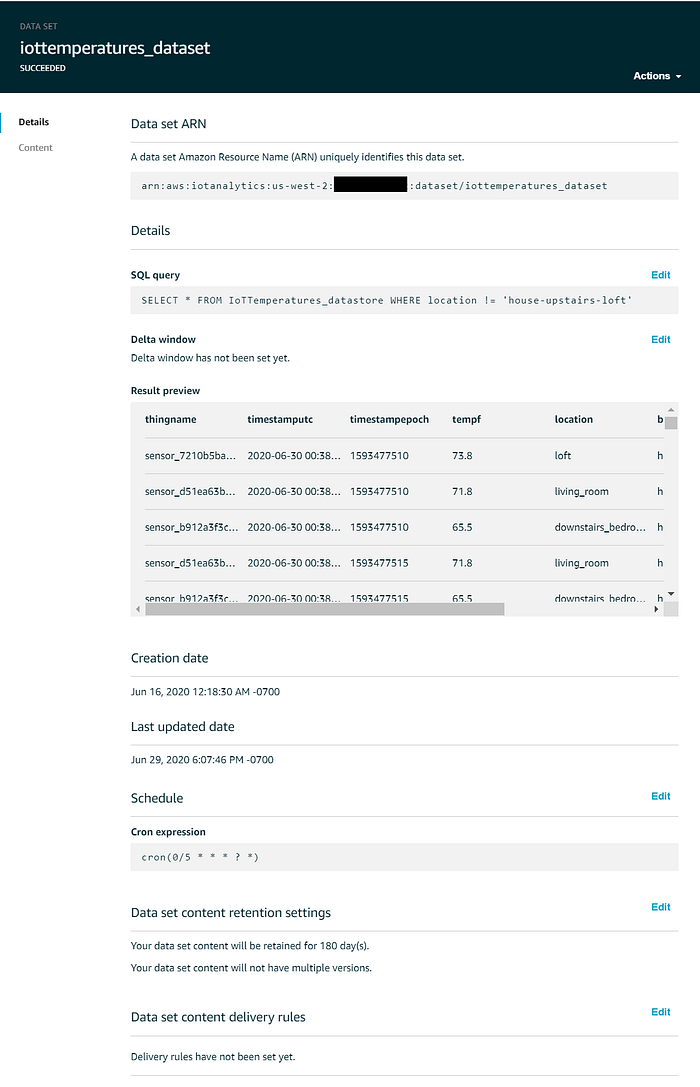
Visualisation des données en streaming
Notre dataset de température étant prêt, place aux capacités de visualisation d'AWS Quicksight. Accédez au service Quicksight et choisissez le type de compte Standard edition pour limiter le coût de votre démo :

Au-delà du jargon marketing, SPICE n'est rien d'autre que le moteur de calcul en mémoire de Quicksight, conçu pour générer rapidement des analyses et des visualisations ad hoc. Avec les données de quelques appareils IoT domestiques, le free tier de 1 Go de SPICE sera largement suffisant pour ce tutoriel.
Une fois votre compte QuickSight créé, vous serez redirigé vers un dashboard listant plusieurs analyses fournies par défaut. Si vous cliquez sur Manage data en haut à droite, vous verrez également les sources de données qui les alimentent. Avant de créer un dashboard d'analyse de température IoT, nous devons configurer notre data set IoT Analytics comme source de données. Cliquez sur New dataset depuis l'écran Manage data et choisissez IoT Analytics dans la liste des sources prises en charge :
Le data store IoT Analytics que nous avons créé s'affichera. Sélectionnez-le et cliquez sur Create data source, puis sur Visualize une fois terminé :
Vous arriverez alors sur un AutoGraph vide :

Comme un graphique en courbes (Line chart) est tout indiqué pour des séries temporelles, sélectionnez cette option dans Visual types. L'espace de travail se transformera et vous pourrez ajouter une dimension sur l'axe x, des valeurs et un regroupement par couleur :

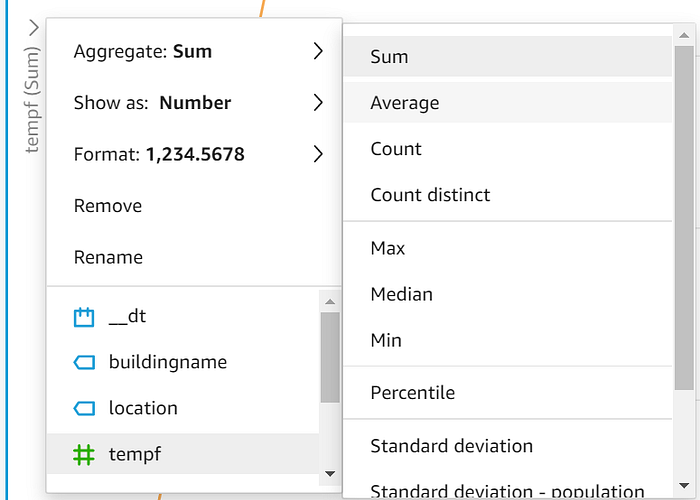
Glissez-déposez timestamputc sur l'axe X, tempf dans Value et location dans Color. Une fois vos données visualisées, cliquez sur la flèche déroulante de l'axe y et passez la valeur affichée de Sum à Average :
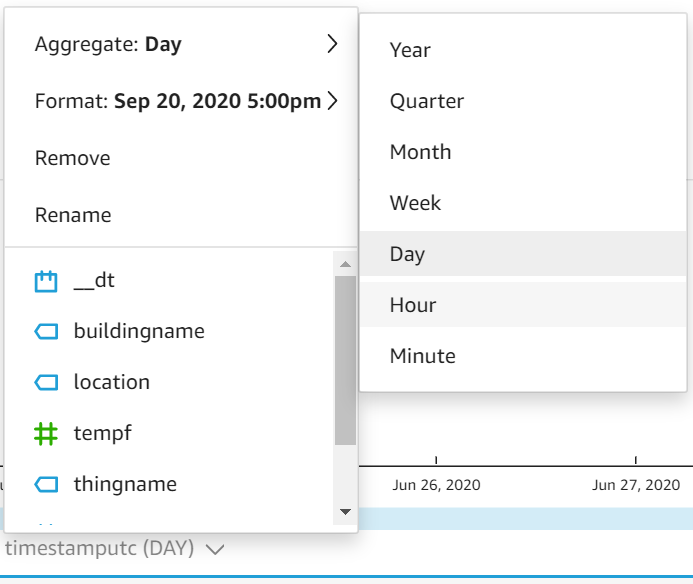
Modifiez ensuite votre axe x pour agréger les températures moyennes par heure (Hour) plutôt que par jour (Day) :
Pour mieux mettre vos données à l'échelle verticalement, cliquez sur l'icône d'engrenage en haut à droite de la figure pour afficher la liste des options de mise en forme visuelle. Choisissez l'axe y et sélectionnez l'option Auto (based on data range) plutôt que l'option par défaut Auto (starting at 0) :

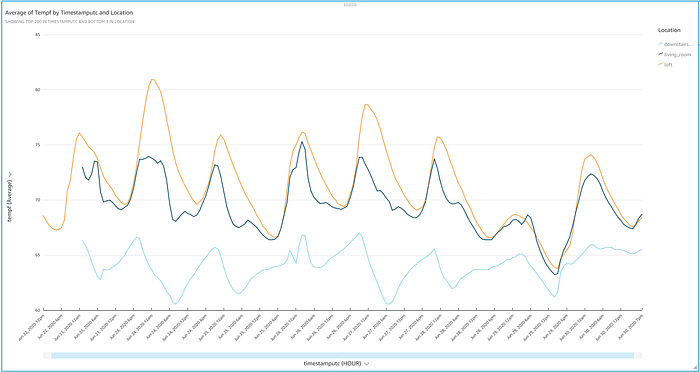
Et voilà ! Vous obtenez maintenant une figure soignée affichant les températures diffusées par IoT, qui montent et descendent au fil de la journée. Quelques observations intéressantes apparaissent au premier coup d'œil :
- Ce projet a confirmé mon impression : la partie inférieure de ma maison tient du royaume des glaces, alors que le thermostat du rez-de-chaussée est réglé sur une température constante de 72 °F (environ 22 °C) tout au long de l'expérience.
- Le rez-de-chaussée affiche une variabilité importante de plus de 5 degrés alors qu'il tente de maintenir 72 °F, et ce malgré le double vitrage présent dans toute la maison. Il est peut-être temps d'investir dans un thermostat connecté et de faire vérifier mon système CVC ?
- J'ai été surpris de constater à quel point la mezzanine est variable et mal climatisée, en particulier les jours de chaleur comme le 24 juin. Elle se trouve dans la même pièce ouverte que le thermostat et juste au-dessus de lui ; pourtant, les jours chauds comme le 24, on y relève environ 8 degrés de plus que dans l'espace situé 3 mètres en dessous.
- Ouvrir les fenêtres lors de journées plus fraîches comme les 25, 26 et 29 a permis d'égaliser les températures de la mezzanine et du salon, même si l'étage inférieur est resté glacial. Rien ne remplace une brise fraîche qui traverse la maison !
Pour que votre visualisation QuickSight reste systématiquement à jour avec votre data set IoT Analytics régulièrement actualisé, retournez sur le dataset source Quicksight et configurez un calendrier d'actualisation :

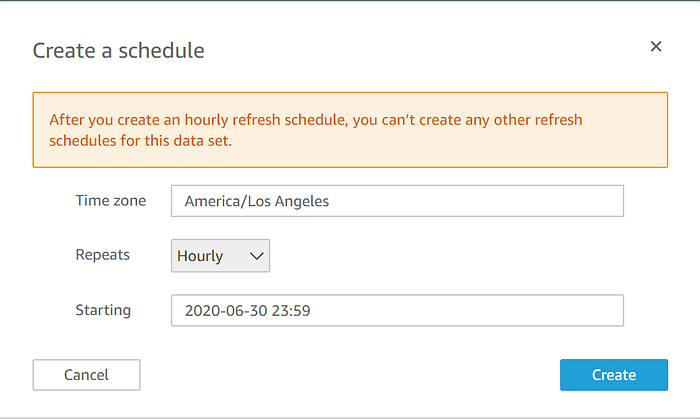
Vous disposez désormais d'un dashboard de visualisation régulièrement mis à jour, que vous pouvez partager avec d'autres collaborateurs de votre entreprise via le domaine Quicksight, pour des données IoT diffusées à l'échelle de la production — le tout sans avoir à maintenir manuellement l'infrastructure de stockage, de transfert et de visualisation des données.
Voilà qui conclut ce tour d'horizon des bonnes pratiques à l'échelle de la production pour le streaming, le stockage et la visualisation de données IoT ! J'espère que vous avez pris plaisir à repérer des tendances de température intéressantes chez vous et que vous avez appris quelques notions sur le serverless sur AWS au passage. Bonne route dans votre aventure IoT !