AWS IoT Coreにデータをストリーミングする場合、そのデータをどう保存し、どう可視化するかは、ビッグデータ規模の分析を支える重要な後段の構成要素です。早い段階できちんと設計しておく必要があります。
前回の記事では、本番規模のIoTデバイス群をAWS IoT Registryに安全にオンボードし、IoT Coreへデータをストリーミングする方法を解説しました。続編となる本記事では、AWSプラットフォームに到達したデータを安全に保存・加工するために活用したい、各種AWSサーバーレスサービスを取り上げます。

概要
本記事は次の2つのセクションで構成されています。
- ストリーミングデータの保存
- ストリーミングデータの可視化
前編とは異なり、ここで扱う作業はAWSのウェブコンソール上で完結するため、プログラミングの知識は不要です。
取り上げるAWSサービスは、IoT Core Rules、IoT Analytics、DynamoDB、Quicksightの4つです。
ストリーミングデータの保存
IoTオンボードが成功しているかの確認
デバイスがIoT Registryに正しくオンボードされ、IoT Coreへのデータストリーミングが始まっていれば、AWS IoTのメインダッシュボードでメッセージが安定して届いている様子を確認できます。
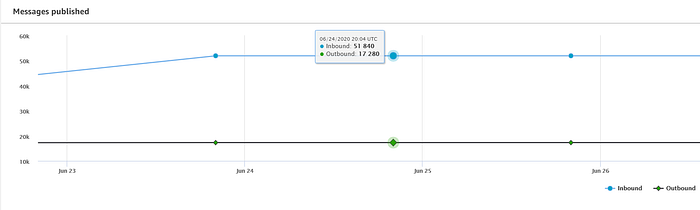
前編で紹介した温度ストリーミング用スクリプトは、5秒ごとに温度測定値をIoT Coreへ送信します。筆者は自宅にRaspberry Piを3台登録しており、それぞれ2階のロフト、1階のリビング、地下のベッドルームに設置しています。そのため、上図のとおり1日あたり51,840件(1台あたり17,280件)のメッセージが配信される計算になります。
IoTのウェブコンソールを使えば、これらのメッセージを処理・保存のために他のAWSサービスへ転送するのは非常に手軽です。送信先を問わず、IoTデータを別のAWSサービスへ流すには、ウェブコンソールでIoT Ruleを1つ作成するだけで済みます。ここでは、シンプルなDynamoDBテーブルを用意し、ストリーミングデータをすべてそこへ送る手順を見ていきましょう。
DynamoDBへのストリーミング
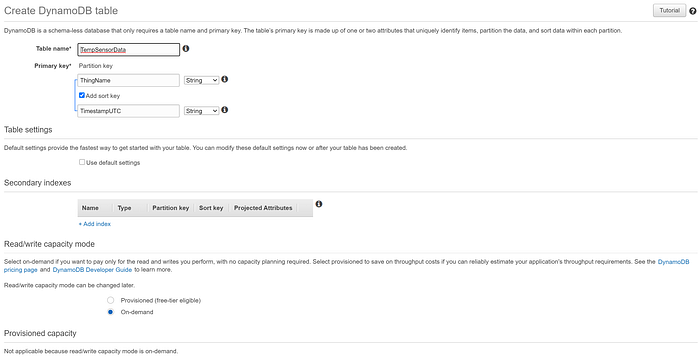
まず「TempSensorData」という名前のDynamoDBテーブルを作成します。Partition keyは「ThingName」、Sort keyは「TimestampUTC」とし、IoT Coreへ送られてくるプライマリキーの値と一致させます。今回のような小規模なテストではコスト抑制のため、容量モードはプロビジョンドではなく「オンデマンド」を選択します。設定はこれだけです。このテーブルへデータを転送するIoT Ruleを作成すると、ルールがキー以外のフィールドを自動的に認識し、テーブルに格納してくれます。
テーブルのプロビジョニングが完了したら、IoT Coreに戻り、Act → Rulesから新しいルールを作成します。ルール名は「TemperatureSensorRule」とし、説明を入力したうえで、上位の「temperature」トピックへ送られるすべての値を選択するようRule queryステートメントを設定します。
各デバイスがそれぞれ固有のトピックへストリーミングしている状況で、すべての温度値を取得するルールはどう書けばよいのでしょうか。これはIoT SQLのワイルドカードで実現できます。各デバイスは、3つのデバイスポリシー変数から構成される、デバイスごとに固有のトピックにストリーミングしていることを思い出してください。
temperature/${iot:Connection.Thing.Attributes[BuildingName]}/${iot:Connection.Thing.Attributes[Location]}/${iot:Connection.Thing.ThingName}
たとえば筆者の自宅にある3台のデバイスは、それぞれ次のトピックへ発行しています。
temperature/house417/loft/sensor_7210b5ba84f64cbbb406e98a1c3b3d32
temperature/house417/living_room/sensor_d51ea63b02bf4cb5b8ac9cf9b464ec3a
temperature/house417/downstairs_bedroom/sensor_b912a3f3c85f4b44ba60720ee43a1a94
#ワイルドカードは1階層以上のサブパスにマッチするため、IoT SQLルールで指定するトピックはtemperature/#となります。したがって使用するIoT SQLステートメントは次のとおりです。
SELECT * FROM ‘temperature/#’
続いて「Add action」をクリックし、DynamoDBテーブルへデータを送信するオプションを選びます。注意したいのは、必ず「DynamoDBv2」を選ぶことです。v1ではキー以外のフィールドが自動展開されず、メッセージ全体がJSON文字列として単一フィールドに格納されてしまいます。

続いて、データの送信先となるDynamoDBテーブルを選択し、AWS IoTがDynamoDBテーブルへデータを書き込むためのロールをウィザードに作成させます。
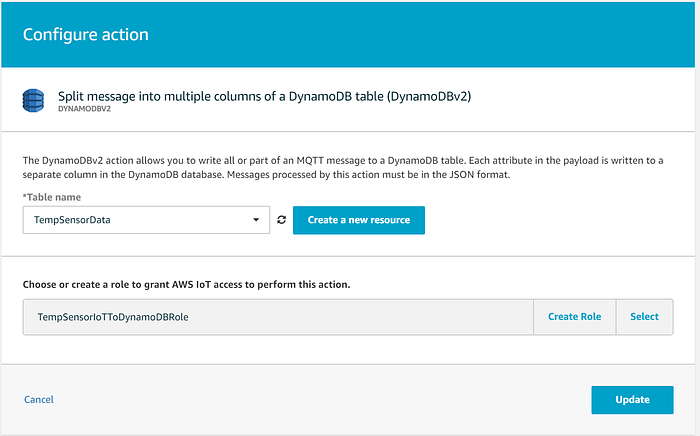
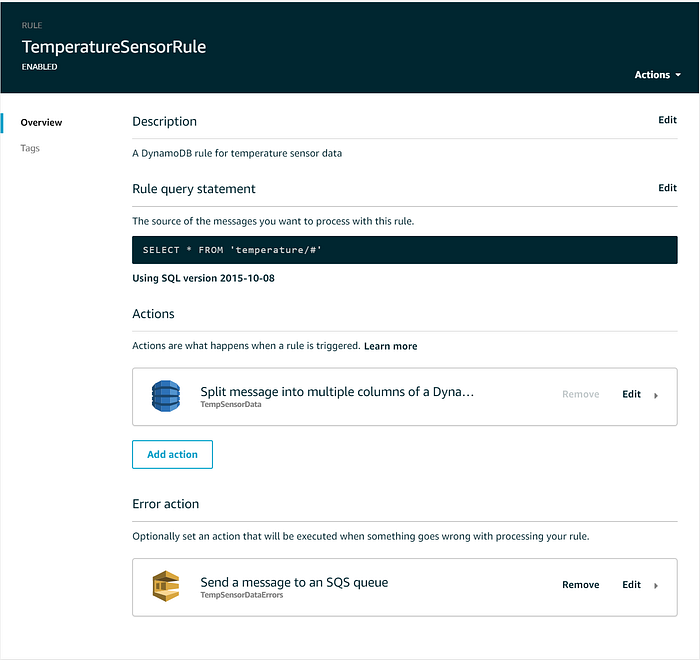
IoT Core Ruleを作成したら、必要に応じてエラーアクションを追加し、配信に失敗したメッセージをSQSのデッドレターキューやS3バケットなどへ送ることもできます。完成したIoT Ruleは次のような状態になります。
数秒もすれば、テーブルにデータが入っていく様子が確認できます。
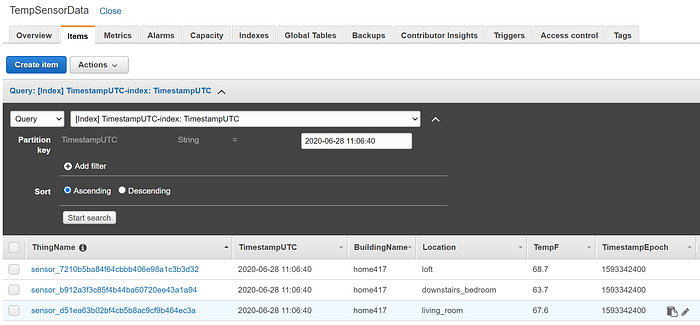
ここから、DynamoDBのデータを利用するカスタムの分析・可視化アプリケーションを構築することもできます。本番環境ではより現実的に(かつデモのウォークスルーには高コストすぎますが)、DynamoDBではなくKinesis Firehoseのデータストリームへ転送する構成も考えられます。Firehoseストリームは、Redshiftなどのデータウェアハウスや、S3などのオブジェクトストアへバッチで書き込みます。Firehoseのバッチ書き込みは、本番規模のIoTストリーミングデータを個別に書き込むことでRedshiftの性能が劣化したり、S3の書き込みスループット上限に達したりするのを防ぐうえで欠かせません。Redshift、DynamoDB、S3はいずれも、ビッグデータ規模の分析アプリケーションに適したデータソースです。
たとえば、AWS EMR上でApache Sparkジョブを構築したり、AWS Sagemaker上で機械学習モデルを動かしたりして、それらのサービスからDynamoDB、Redshift、S3のデータを読み込ませる構成も可能です。
ただし本記事では、コーディング不要の純粋なサーバーレス構成での保存と可視化に焦点を絞ります。具体的には、IoT Analyticsの時系列データストアを使い、ライフサイクルポリシーを伴う形で生データとフィルタ済みデータセットをサーバーレスに保存し、Quicksightで可視化する方法を見ていきます。QuicksightはDynamoDBから直接データを取得できず、Redshiftをソースにするのはデモ目的にはやや高コストです。一方、IoT Analyticsであればサーバーレスかつ高スループットなデータの保存と、QuickSightからの取得という要件を簡単に満たせるため、ここではIoT Analyticsをデータストアとして採用します。
IoT Analyticsへのストリーミング
IoT Analyticsサービスに移動し、Quick Createウィザードで、IoT Coreの温度トピックからIoT Analyticsへデータを流す仕組みをワンクリックで構築します。このプロセスでは、以下が一括で作成されます。
- IoT Coreから生のIoTデータが届くチャネルと、そこへデータを流すIoT Core Rule
- チャネルのデータを必要に応じてフィルタリング・変換できるパイプライン
- パイプラインの出力データを保存するデータストア(保持期間付き)
- データストアからフィルタリングされたデータセット(独自の保持期間と定期的な再作成スケジュール付き)。Quicksightはこのフィルタ済みデータセットをもとにインサイトと可視化を行います。
これらのIoT Analyticsコンポーネントの設定は、Quick Startの次の2つのフィールドを埋めるだけで完了します。
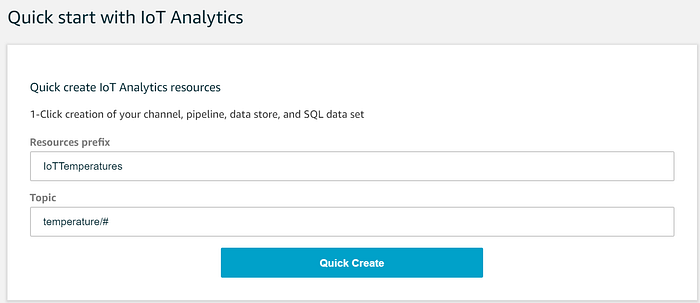
ウィザードは続いて、必要なChannel、Pipeline、Data Store、Data Setの各エントリを作成します。これらのIoT Analyticsコンポーネントが何をしているのか、ウィザードが裏で何を行っているのかは見えにくいので、順を追って解説します。
IoT Analytics Channelは、ストリーミングデータが最初に到着する場所です。IoT Core Rulesの一覧に戻ると、ウィザードが先ほどのDynamoDB用ルールとほぼ同じルールを作成しているのが分かります。違いは、アクションがIoT Analytics上に作成されたチャネルへデータを転送する設定になっている点だけです。配信に失敗したメッセージを補足したい場合は、ルールを編集してSQSキューなどの送信先を指定する必要があります。

IoT Analytics Pipelineでは、メッセージの属性をもとにエンリッチメント、変換、フィルタリングを任意で行えます。今回の例では生データの加工は不要なので、Pipelineはデフォルトのままにしておきます。
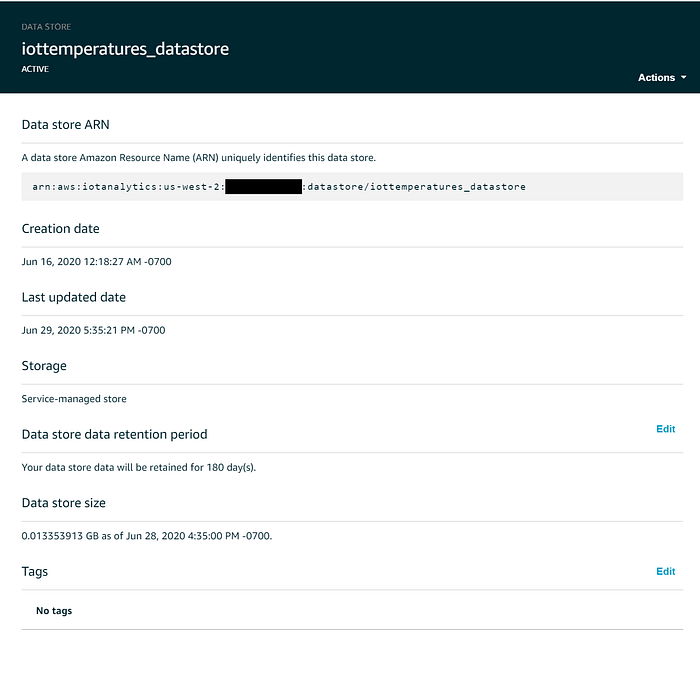
IoT Data Storeは、ストリーミングデータの保存先で、無期限または指定期間の保存が可能です。裏側ではAWSが管理するS3バケットに保存されており、同サービスの99.999999999%(イレブンナイン)の耐久性と99.99%の高可用性をそのまま享受できます。必要であれば、データストアを自身が管理するS3バケットに保存するよう構成することもでき、IoT Analyticsとの連携が弱いサービスからもIoTデータを扱いやすくなります。ただし本デモでは、サービス管理の非公開バケットをそのまま使います。
デフォルトでは、IoT Analyticsデータストアに流れ込んだデータは無期限に保持されますが、ウェブコンソールで「Data store data retention period」の横にある「Edit」をクリックすれば変更できます。本番規模のIoTでコストを抑えるには、一定期間が過ぎたData Storeのデータを期限切れにする設定が望ましいでしょう。筆者は温度値を6カ月で期限切れになるよう設定しました。

IoT Data Setは、IoT SQLで作成されるIoT Data Storeのサブセットで、独自の保持期間を持ち、オンデマンドまたは定期スケジュールで再作成できます。Data Storeと同様、Data Setはサービス管理バケットにCSVファイルとして保存されます。Data Setを使えば、カスタムフィルタに基づく静的なデータセット(たとえば、特に注目したい時間帯の温度データだけを抽出したものなど)をオンデマンドで一度だけ生成し、それを後段の分析用に無期限に保持しつつ、生データのストアメッセージは組織として最適と判断した保持期間で期限切れにする、といった運用が可能になります。
IoT Analyticsと連携するAWSサービスのうち、QuicksightなどはData Setからしかデータを取得できませんが、SageMakerなどはData StoreとData Setの両方から取得できます。基本的には、ほぼすべてのサービスがData Setから取得できると考えておけばよいでしょう。Data Storeとの連携が限定的であること、IoT Analyticsで生データを無期限に保存するコストの観点からも、本番ユースケースでは、分析やMLモデル生成に使う個別のフィルタ済みデータセットを作成する手法に慣れておくのがおすすめです。生データのストアは、組織がIoTデータの全履歴を保管するコストを許容しない限り、時間の経過とともに期限切れにしていくのが望ましい運用です。
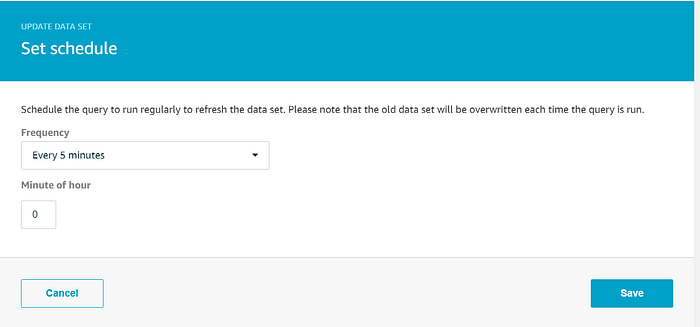
ウィザードはデータストアからすべてのデータを抽出するデータセットを作成しますが、ここでは2点だけ修正します。Quicksightでの可視化にはデータストア内のすべてのデータを使う想定なので、SQLクエリはそのままにします。一方、Quicksightのグラフには常に最新の温度データを反映させたいので、オンデマンド実行ではなく、5分ごとにデータセットを再作成するcronジョブを設定しましょう。「Schedule」の横の「Edit」をクリックし、希望する再作成頻度を設定します。
データセットの保持期間は、データストアと合わせて180日に設定し、複数バージョンの保持は無効にします。
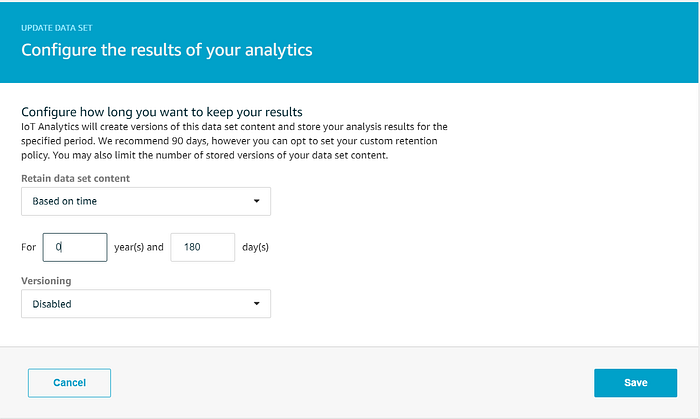
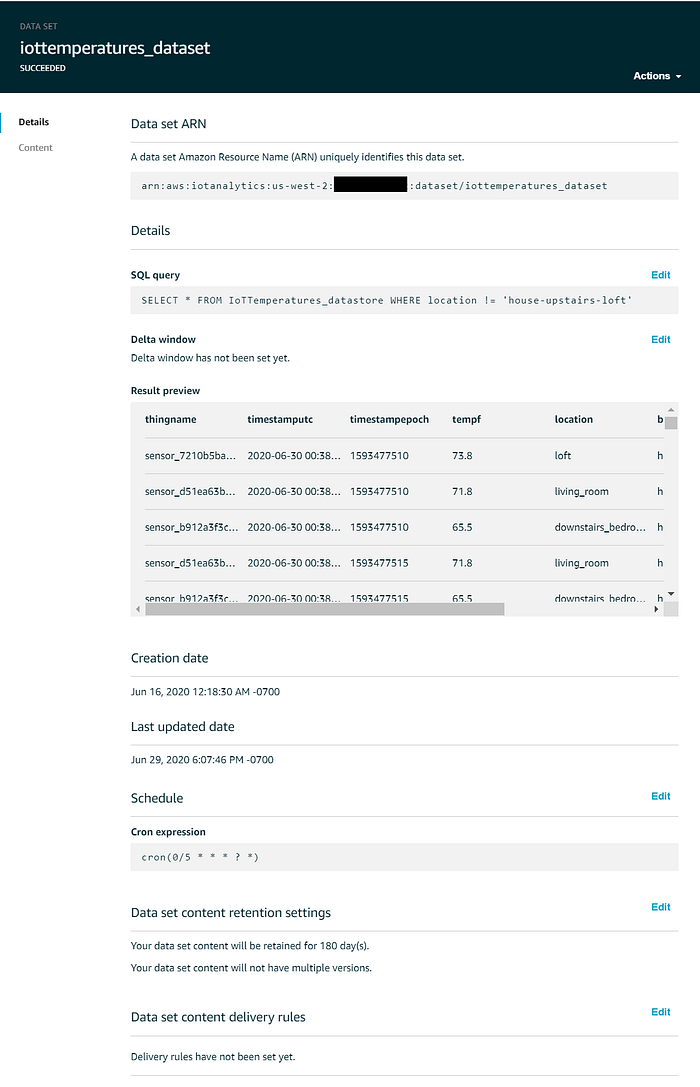
Quicksightで使うデータセットは、最終的に次のような状態になっているはずです。
ストリーミングデータの可視化
温度データセットの準備が整ったので、AWS Quicksightの可視化機能を見ていきましょう。Quicksightサービスに移動し、デモのコストを抑えるためにアカウントタイプは「Standard edition」を選びます。

マーケティング的な表現を抜きにすれば、SPICEはQuicksightのインメモリ計算エンジンで、アドホックな分析や可視化を高速に生成するためのものです。家庭のIoTデバイス数台分のデータであれば、無料枠の1 GB SPICEだけで本ウォークスルーには十分すぎるほどです。
QuickSightアカウントの作成が完了すると、デフォルトで用意されているサンプル分析がいくつか並んだダッシュボードが表示されます。右上の「Manage data」をクリックすれば、それらサンプルを支えているデータソースも確認できます。IoTの温度分析ダッシュボードを作成する前に、まずIoT Analyticsデータセットをデータソースとして登録する必要があります。「Manage data」画面で「New dataset」をクリックし、対応ソース一覧からIoT Analyticsを選択します。
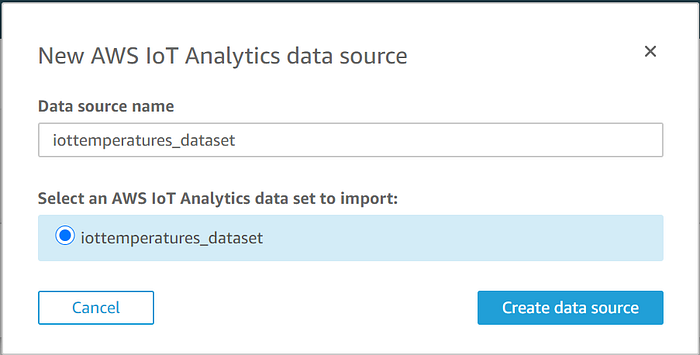
先ほど作成したIoT Analyticsデータストアが表示されます。それを選択して「Create data source」をクリックし、完了したら「Visualize」をクリックします。
すると、空のAutoGraphが表示されます。

時系列データは折れ線グラフとの相性がよいので、「Visual types」から折れ線グラフを選びます。これでワークスペースが切り替わり、X軸の項目、値、グループ分け用の色を指定できるようになります。

「timestamputc」をX軸に、「tempf」をValueに、「location」をColorにドラッグ&ドロップします。データが可視化されたら、Y軸のドロップダウン矢印を選び、表示値をSum(合計)からAverage(平均)に変更します。
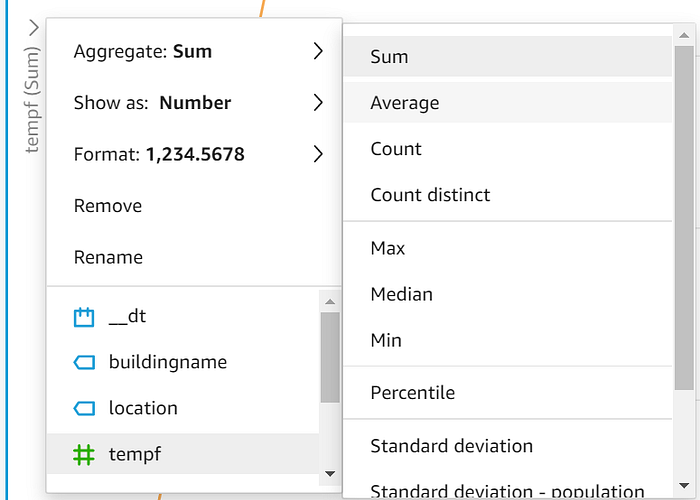
続いて、X軸の集計単位をDay(日)からHour(時間)に変更し、平均温度を時間単位で集計するようにします。
データを縦方向により見やすく表示するため、グラフ右上の歯車アイコンをクリックして書式設定オプションの一覧を開きます。Y軸を選び、デフォルトの「Auto (starting at 0)」ではなく「Auto (based on data range)」を選択します。

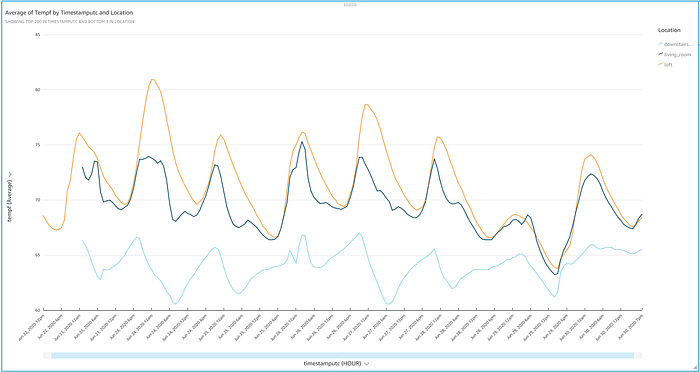
これで完成です。IoT経由でストリーミングされた温度値が、1日の中で上下する様子を美しいグラフで確認できるようになりました。グラフをひと目見るだけでも、いくつか興味深い特徴に気づきます。
- このプロジェクトによって、実験中ずっと1階のサーモスタットを華氏72度に固定していたにもかかわらず、家の下の階は冬の不思議の国のように寒い、という筆者の実感が裏付けられました。
- 家中が二重ガラス窓であるにもかかわらず、1階は72度を維持しようとする中で5度を超える大きな温度変動を見せています。そろそろスマートサーモスタットを導入し、HVACを点検してもらう頃合いかもしれません。
- 意外だったのは、ロフトの温度がこれほど変動しやすく、6月24日のような暑い日には十分に冷えていなかったことです。ロフトはサーモスタットと同じオープンスペースにあり、しかもその真上に位置しているにもかかわらず、24日のような暑い日には、約3メートル下のフロアより約8度も高くなっています。
- 25日、26日、29日のような涼しい日に窓を開けると、ロフトとリビングの気温は均一化されました。それでも地下は相変わらず冷え切ったままです。家中を抜ける涼しい風に勝るものはありません。
QuickSightの可視化を、定期的に更新されるIoT Analyticsデータセットと常に同期させるには、Quicksightのソースデータセットに戻り、更新スケジュールを設定します。

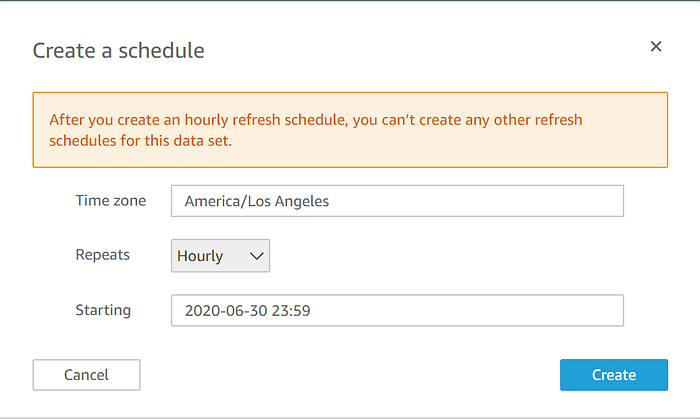
これで、本番規模のIoTストリーミングデータを対象に、データの保存・転送・美しい可視化を行うインフラを手作業で運用することなく、定期的に更新される可視化ダッシュボードを構築できました。Quicksightドメインを通じて、社内の他のメンバーにも共有できます。
以上で、本番規模のIoTデータのストリーミング・保存・可視化に関するベストプラクティスのツアーは終了です。ご自宅の温度傾向から面白い発見を楽しんでいただき、その過程でAWSのサーバーレスについて少しでも学んでいただけたなら幸いです。皆さんのIoTジャーニーがうまくいきますように。