Se você envia dados em streaming para o AWS IoT Core, armazenar e visualizar esses dados corretamente são peças críticas no fluxo posterior, e precisam ser arquitetadas com bastante antecedência para dar conta de análises em escala de big data.
Dando continuidade à minha discussão anterior sobre como integrar com segurança uma frota de dispositivos IoT em escala de produção ao AWS IoT Registry e enviar dados para o IoT Core, este artigo de continuação aborda diversos serviços serverless da AWS que você deve usar para armazenar e manipular esses dados com segurança depois que eles chegam à plataforma AWS.

Visão geral
Esta discussão está dividida nas seguintes seções:
- Armazenamento de dados em streaming
- Visualização de dados em streaming
Diferentemente da parte um, tudo o que será discutido aqui pode ser feito pelo console web da AWS, então não é necessária experiência em programação.
Os seguintes serviços da AWS serão abordados: IoT Core Rules, IoT Analytics, DynamoDB e Quicksight.
Armazenamento de dados em streaming
Verificação do onboarding bem-sucedido no IoT
Se você integrou os dispositivos com sucesso ao IoT Registry e começou a enviar dados em streaming para o IoT Core, deve ver um fluxo constante de mensagens chegando no dashboard principal do AWS IoT:
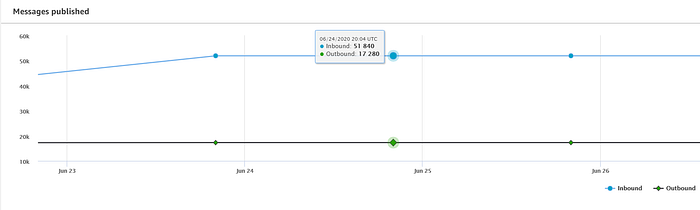
O script de streaming de temperatura que apresentei na parte um envia leituras de temperatura para o IoT Core a cada 5 segundos. Registrei três dispositivos Raspberry Pi na minha casa — um no loft do andar de cima, um na sala de estar do térreo e um em um quarto do andar inferior — e por isso esperava ver as 51.840 mensagens publicadas por dia mostradas acima (17.280 mensagens por dispositivo).
O console web do IoT facilita muito o encaminhamento dessas mensagens para diversos serviços da AWS para processamento e armazenamento. Independentemente do serviço de destino, enviar dados de IoT para outro serviço da AWS é tão simples quanto criar uma IoT Rule no console web. Vamos ver na prática como fazer isso, configurando uma tabela DynamoDB simples e enviando todos os dados em streaming para ela.
Streaming para o DynamoDB
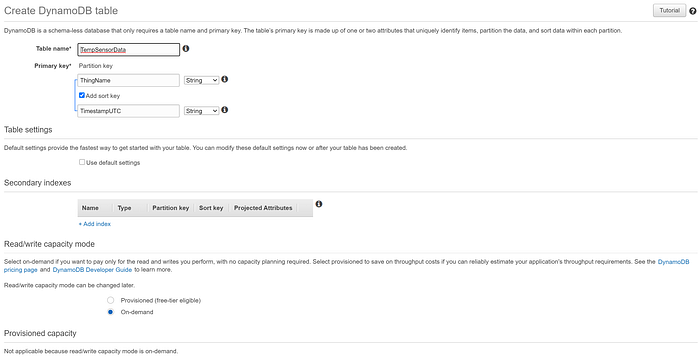
Crie uma tabela DynamoDB chamada "TempSensorData", com uma Partition key chamada "ThingName" e uma sort key chamada "TimestampUTC", correspondendo aos valores de chave primária enviados ao IoT Core. Configure a tabela para usar capacidade "On-demand" em vez de provisionada, para economizar dinheiro durante este pequeno exemplo de teste. Pronto! Quando configurarmos uma IoT Rule que encaminha dados para essa tabela, a regra vai identificar campos não-chave nos nossos dados e os preencher na tabela:
Depois que a tabela for provisionada com sucesso, volte para a plataforma do IoT Core, navegue até Act → Rules e crie uma nova regra. Dê a essa regra o nome "TemperatureSensorRule", forneça uma descrição e configure a Rule query statement para selecionar todos os valores enviados para o tópico de alto nível 'temperature'.
Como criar uma regra que captura todos os valores de temperatura sendo que cada dispositivo envia para seu próprio tópico exclusivo? Dá para fazer isso com wildcards de IoT SQL. Lembre-se de que cada dispositivo envia para um tópico definido por três variáveis de política do dispositivo que, em conjunto, formam um tópico exclusivo para cada dispositivo:
temperature/${iot:Connection.Thing.Attributes[BuildingName]}/${iot:Connection.Thing.Attributes[Location]}/${iot:Connection.Thing.ThingName}
Por exemplo, estes são os tópicos para os quais os três dispositivos da minha casa publicam:
temperature/house417/loft/sensor_7210b5ba84f64cbbb406e98a1c3b3d32
temperature/house417/living_room/sensor_d51ea63b02bf4cb5b8ac9cf9b464ec3a
temperature/house417/downstairs_bedroom/sensor_b912a3f3c85f4b44ba60720ee43a1a94
O tópico IoT a ser selecionado na sua regra IoT SQL será temperature/#, já que o wildcard # corresponde a um ou mais subcaminhos. Portanto, a instrução IoT SQL a ser usada é a seguinte:
SELECT * FROM 'temperature/#'
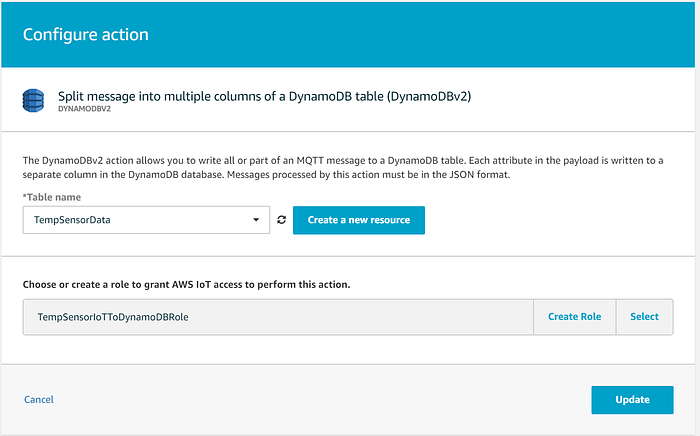
A partir daí, clique em "Add action" e selecione a opção que envia dados para uma tabela DynamoDB. Atenção: certifique-se de selecionar a opção 'DynamoDBv2", pois a opção v1 não preenche automaticamente os campos não-chave e, em vez disso, armazena a mensagem completa na tabela como um único campo JSON-as-string:

Em seguida, selecione sua tabela DynamoDB para receber os dados em streaming e permita que o assistente crie uma role concedendo permissões ao AWS IoT para enviar dados de IoT para a tabela DynamoDB:
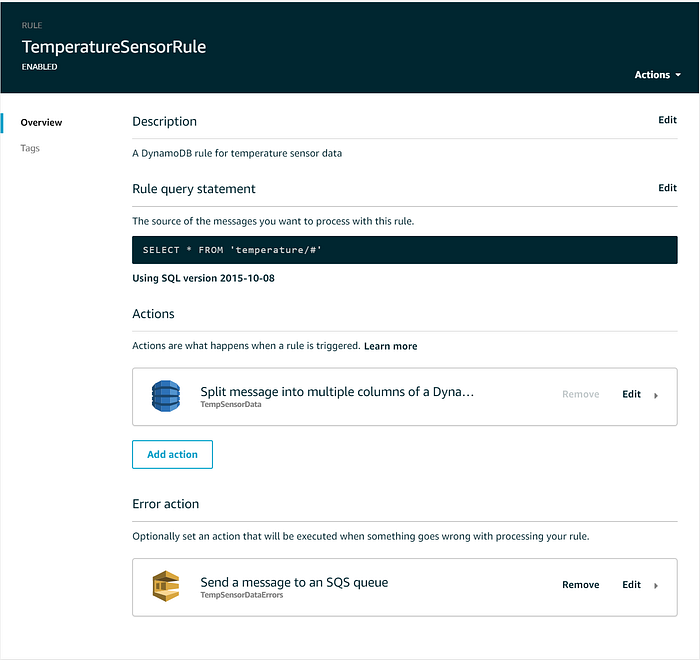
Depois que a IoT Core Rule for criada, você pode opcionalmente adicionar uma Error action que encaminha entregas de mensagens com falha para, por exemplo, uma fila SQS dead letter ou um bucket S3. Sua IoT Rule deve ficar assim quando concluída:
Depois de alguns segundos, você verá a tabela populada com dados:
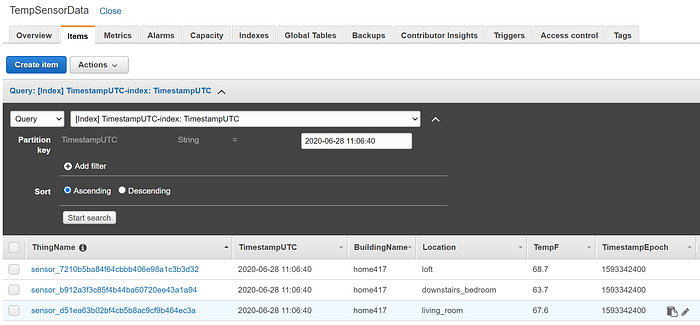
A partir daí, você poderia criar aplicações personalizadas de análise e visualização que consultam dados do DynamoDB. De forma mais realista em um cenário de produção (e cara demais para uma demonstração), você poderia encaminhar os dados de IoT para um data stream do Kinesis Firehose em vez do DynamoDB. Esse stream do Firehose faria, então, gravações em batch em um data warehouse como o Redshift e/ou em um object store como o S3 — e a gravação em batch do Firehose é fundamental para evitar que gravações individuais de dados em streaming de IoT em escala de produção causem problemas de desempenho no Redshift ou estourem os limites de throughput de gravação no S3. Redshift, DynamoDB e S3 são ótimas fontes para aplicações analíticas em escala de big data.
Por exemplo, você poderia criar um job do Apache Spark no AWS EMR ou um modelo de machine learning rodando no AWS Sagemaker e fazer com que qualquer um desses serviços puxe dados do DynamoDB, do Redshift ou do S3.
Mas, neste artigo, quero focar em uma abordagem puramente serverless para armazenamento e visualização, sem precisar escrever uma linha de código. Com isso em mente, vamos ver como podemos, de forma serverless, armazenar nossos dados brutos e datasets filtrados com políticas de ciclo de vida usando o data store de séries temporais do IoT Analytics e, depois, usar o Quicksight para visualização. Como o Quicksight não consegue puxar dados do DynamoDB, o Redshift como fonte é um pouco caro para uma demonstração, e o IoT Analytics atende facilmente aos nossos requisitos de armazenamento e recuperação serverless de dados em alto throughput pelo QuickSight, vamos seguir com o IoT Analytics como o data store escolhido.
Streaming para o IoT Analytics
Acesse o serviço IoT Analytics e use o assistente Quick Create para iniciar um processo de criação em 1 clique para enviar dados em streaming ao IoT Analytics a partir do nosso tópico de temperatura do IoT Core. Esse processo vai criar:
- Um channel onde os dados brutos de IoT chegam vindos do IoT Core, além da IoT Core Rule que move os dados para esse channel
- Um pipeline onde os dados do channel podem ser opcionalmente filtrados e transformados
- Um data store para os dados de saída do pipeline com um período de retenção associado
- Um dataset filtrado a partir do data store, com seu próprio período de retenção e cronograma de recriação periódica. O dataset filtrado é o que o Quicksight usará para gerar seus insights e visualizações.
Configurar todos esses componentes do IoT Analytics é tão simples quanto preencher os dois campos do Quick Start a seguir:
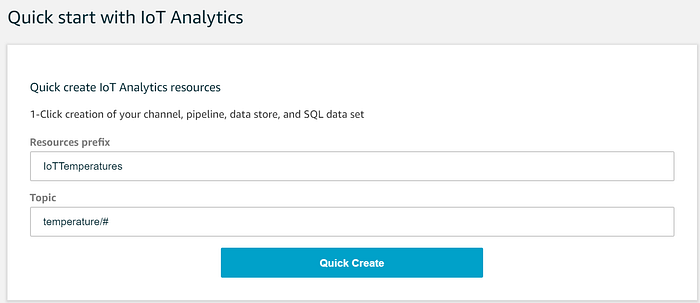
O assistente vai então criar as entradas necessárias de Channel, Pipeline, Data Store e Data Set. Como o que esses componentes do IoT Analytics fazem e o que o assistente executa nos bastidores não fica claro, vamos detalhar.
Um Channel do IoT Analytics é onde os dados em streaming chegam. Se você voltar à lista de IoT Core Rules, vai notar que o assistente criou uma regra idêntica à regra do DynamoDB que você configurou anteriormente, exceto que a Action agora encaminha dados para o channel que o assistente acabou de criar na plataforma IoT Analytics. Importante: se você quiser capturar entregas de mensagens com erro, vai precisar atualizar a regra para especificar um destino, como uma fila SQS:

Um Pipeline do IoT Analytics permite enriquecer, transformar e filtrar mensagens com base em seus atributos, de forma opcional. Manipular os dados brutos não é necessário no nosso exemplo, então vamos manter os padrões do Pipeline.
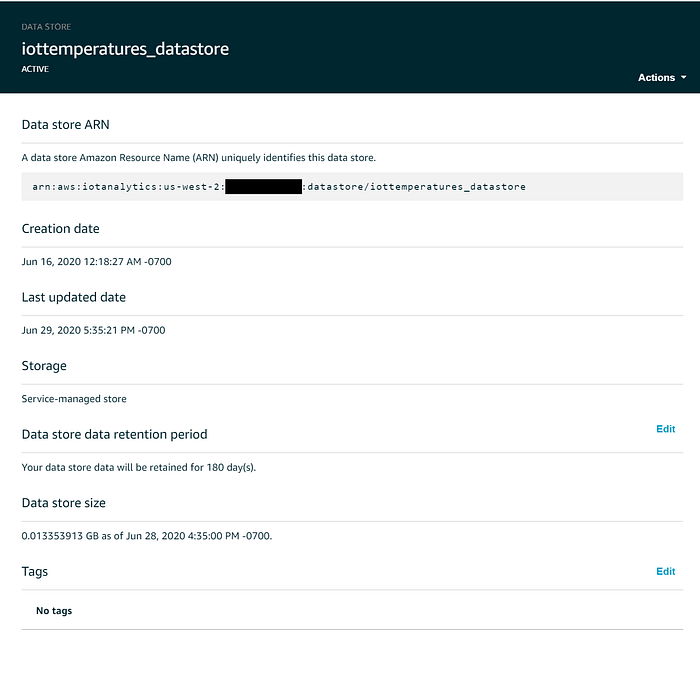
Os IoT Data stores são onde os dados em streaming são armazenados, seja indefinidamente ou por um período de tempo determinado. Nos bastidores, esses dados ficam guardados em um bucket S3 gerenciado pela AWS, então você continua se beneficiando dos 11 noves de durabilidade e dos 99,99% de alta disponibilidade desse serviço. Se quiser, é possível configurar um data store para salvar os dados em um bucket S3 controlado por você, facilitando a obtenção e o trabalho com dados de IoT em serviços que talvez não se integrem tão bem com o IoT Analytics; mas, para esta demonstração, vamos ficar com o bucket oculto gerenciado pelo serviço.
Por padrão, os dados enviados para um data store do IoT Analytics ficam retidos indefinidamente, mas você pode alterar isso no console web clicando em "Edit" ao lado de "Data store data retention period". Para manter sob controle os custos de IoT em escala de produção, é recomendável expirar os dados do Data Store após um período determinado. Configurei meus valores de temperatura para expirar depois de seis meses:

Um IoT Data Set é um subconjunto de um IoT Data Store criado com IoT SQL, que tem seu próprio período de retenção, além da capacidade de se recriar sob demanda ou em um cronograma recorrente. Assim como os Data Stores, os Data Sets são armazenados como arquivos CSV em um bucket gerenciado pelo serviço. Na prática, os Data Sets significam que você pode criar um conjunto de dados estático com base em um filtro personalizado (por exemplo, selecionar todos os dados de temperatura de uma janela curta, mas relevante), gerar esse conjunto de dados sob demanda uma única vez e mantê-lo indefinidamente para análises posteriores, deixando que as mensagens originais e brutas do data store expirem de acordo com um período de retenção que sua organização considere o melhor equilíbrio entre retenção de dados brutos e custo-benefício.
Alguns serviços da AWS que se integram ao IoT Analytics, como o Quicksight, só conseguem extrair dados de data sets, enquanto outros, como o SageMaker, podem extrair tanto de data stores quanto de data sets. Em geral, todos os serviços conseguem extrair de data sets. Por causa da conectividade mais limitada com os data stores e do impacto de custo de armazenar dados brutos indefinidamente no IoT Analytics, em um caso de uso de produção vale a pena se acostumar com a metodologia de criar datasets discretos e filtrados para usar em análises ou na geração de modelos de ML, deixando o data store bruto expirar com o tempo, a menos que sua organização considere aceitável pagar pelo armazenamento histórico completo dos dados de IoT.
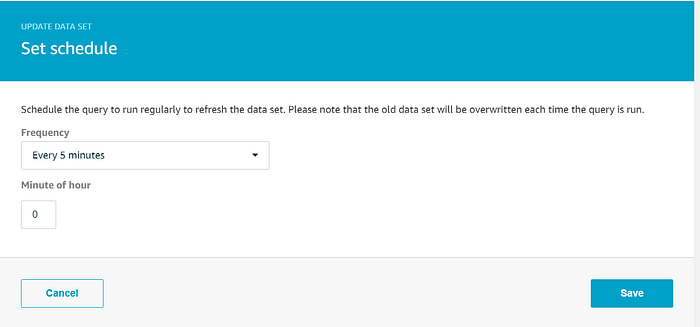
O assistente terá criado um data set que seleciona todos os dados do data store, mas precisamos fazer duas atualizações nele. Como pretendemos usar todos os dados do data store na nossa visualização do Quicksight, vamos manter a consulta SQL como está. Queremos que o Quicksight use os dados de temperatura mais atualizados em seus gráficos, então, em vez de executar a recriação do data set sob demanda, vamos configurar uma cron job para recriar o dataset a cada 5 minutos. Clique em "Edit" ao lado de "Schedule" e defina a frequência de recriação desejada:
Queremos que o data set seja retido por 180 dias, igualando o período de retenção do nosso data store, e queremos desabilitar a retenção de múltiplas versões:
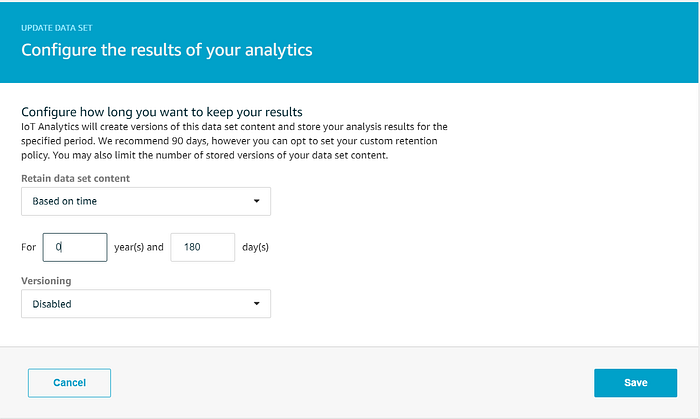
O data set a ser usado pelo Quicksight deve ficar assim:
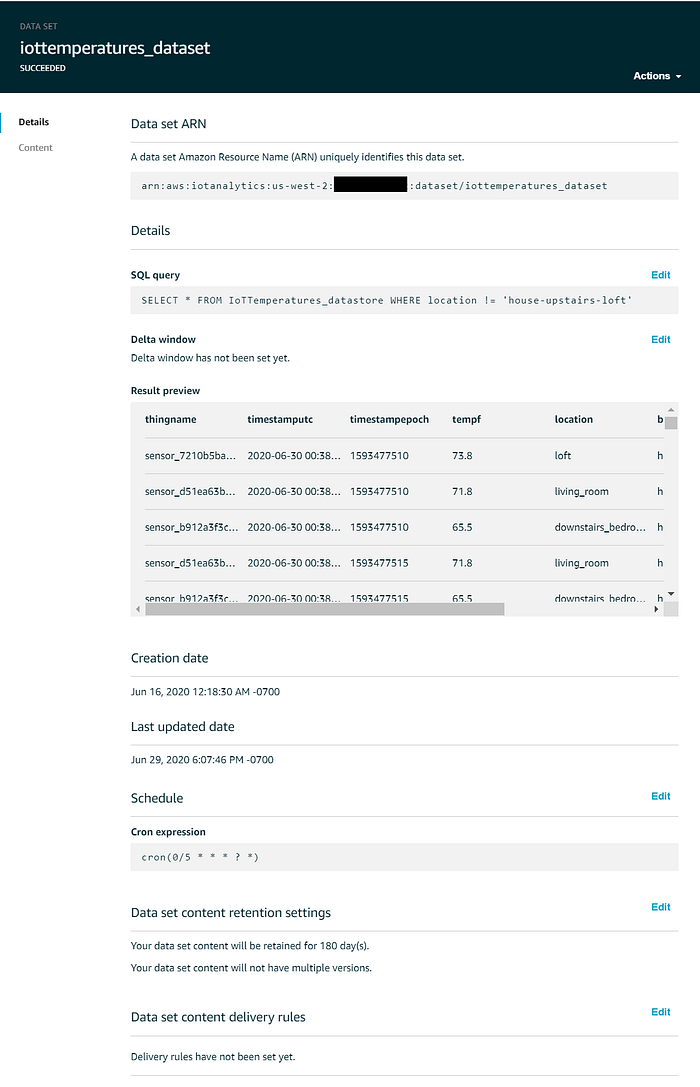
Visualização de dados em streaming
Com nosso dataset de temperatura pronto, vamos conferir os recursos de visualização do AWS Quicksight. Acesse o serviço Quicksight e selecione o tipo de conta QuickSight "Standard edition" para deixar sua demonstração mais barata:

Tirando o jargão de marketing, o SPICE é simplesmente o motor de computação em memória do Quicksight, voltado a gerar análises e visualizações ad hoc rapidamente. Com os dados de apenas alguns dispositivos IoT domésticos, a camada gratuita de 1 GB do SPICE será mais que suficiente para este passo a passo.
Quando sua conta do QuickSight terminar de ser criada, você será levado a um dashboard que lista vários exemplos de análises que o serviço fornece por padrão. Se clicar em "Manage data" no canto superior direito, também vai ver as fontes de dados que alimentam essas análises de exemplo. Antes de criar um dashboard de análise de temperatura IoT, precisamos configurar nosso data set do IoT Analytics como uma fonte de dados. Clique em "New dataset" na tela "Manage data" e escolha IoT Analytics na lista de fontes suportadas:
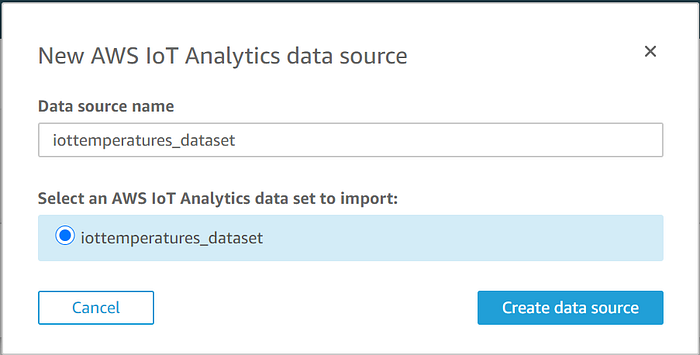
O data store do IoT Analytics que criamos será exibido. Selecione-o, clique em "Create data source" e, em seguida, clique em "Visualize" quando concluído:
Isso vai te levar a um AutoGraph vazio:

Sabendo que dados de séries temporais ficam bem representados em um gráfico de linha (Line chart), selecione essa opção em "Visual types". Isso vai transformar o workspace e permitir adicionar uma dimensão no eixo X, valores e uma cor de agrupamento (group-by):

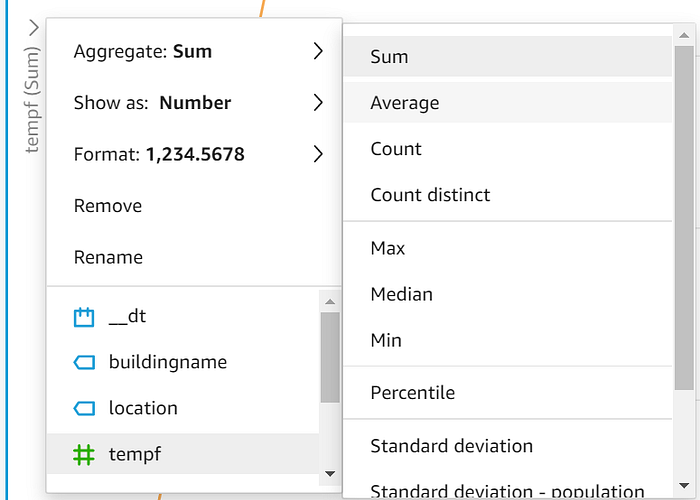
Arraste e solte "timestamputc" no eixo X, "tempf" em Value e "location" em Color. Quando seus dados estiverem visualizados, selecione a seta suspensa do eixo Y e altere o valor exibido de Sum para Average:
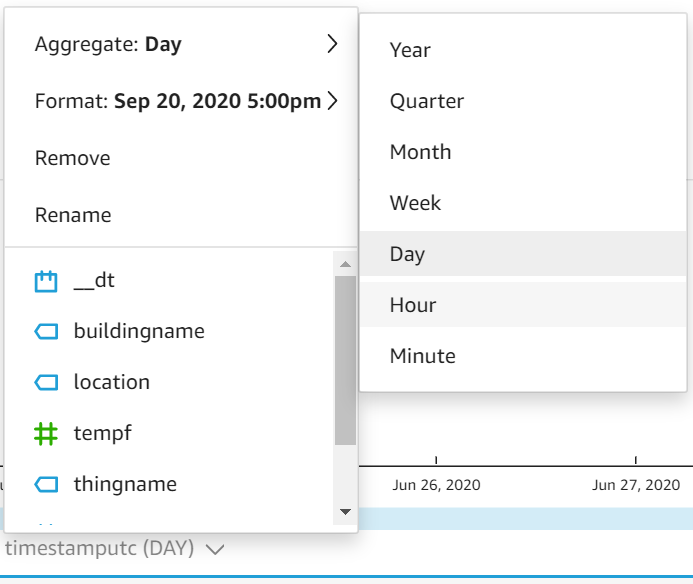
Em seguida, altere o eixo X para agregar os valores médios de temperatura por Hora em vez de Dia:
Para escalar verticalmente os dados de forma mais adequada, clique no ícone de engrenagem no canto superior direito do gráfico para exibir uma lista de opções de formatação visual. Escolha o eixo Y e selecione a opção "Auto (based on data range)" em vez do padrão "Auto (starting at 0)":

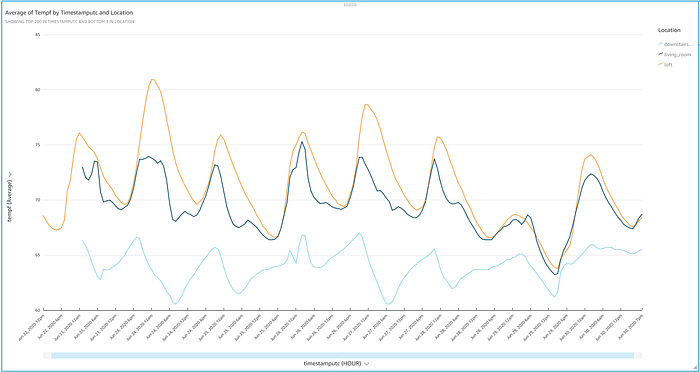
E voilà! Agora você deve ver um gráfico elegante exibindo os valores de temperatura transmitidos via IoT, que sobem e descem ao longo do dia. Dá para identificar alguns aspectos interessantes só de bater o olho no gráfico:
- Este projeto confirmou minha impressão de que a parte inferior da minha casa parece um "país das maravilhas de inverno", apesar de o termostato no térreo estar configurado em constantes 72 graus durante todo o experimento.
- O térreo apresenta grande variabilidade de temperatura, >5 graus, ao tentar manter os 72 graus, mesmo com janelas de vidro duplo em toda a casa. Talvez seja hora de comprar um termostato inteligente e mandar revisar o ar-condicionado?
- Fiquei surpreso com o quanto o loft é instável e mal refrigerado, especialmente em dias quentes, como 24 de junho. O loft fica no mesmo cômodo aberto que o termostato e diretamente acima dele, mas em dias quentes, como o dia 24, ele chega a ficar cerca de 8 graus mais quente que o espaço 3 metros abaixo.
- Abrir as janelas em dias mais frescos, como nos dias 25, 26 e 29, equilibrou as temperaturas do loft e da sala de estar, embora o andar inferior ainda tenha conseguido se manter gelado. Não tem nada que substitua uma brisa fresca passando pela casa!
Para garantir que sua visualização no QuickSight esteja sempre alinhada com seu data set do IoT Analytics atualizado regularmente, volte ao dataset de origem do Quicksight e configure um cronograma de atualização:

Pronto: agora você tem um dashboard de visualização atualizado com regularidade, que pode ser disponibilizado para outras pessoas da sua empresa pelo domínio do Quicksight, para dados em streaming de IoT em escala de produção — tudo isso sem precisar manter manualmente a infraestrutura de armazenamento, transporte e visualização caprichada dos dados.
E assim encerramos este tour pelas boas práticas em escala de produção para streaming, armazenamento e visualização de dados de IoT! Espero que você tenha se divertido identificando tendências interessantes de temperatura na sua própria casa e aprendido algumas coisas sobre serverless na AWS pelo caminho. Boa sorte na sua jornada de IoT!