Wer Daten an AWS IoT Core streamt, muss frühzeitig durchdenken, wie diese Daten anschließend gespeichert und visualisiert werden – beides sind kritische nachgelagerte Komponenten, die Big-Data-Analysen überhaupt erst möglich machen.
In meinem vorigen Beitrag ging es darum, wie Sie eine produktionsreife Flotte von IoT-Geräten sicher in die AWS IoT Registry einbinden und Daten an IoT Core streamen. Dieser Folgeartikel zeigt, mit welchen Serverless-Services von AWS Sie diese Daten nach dem Eintreffen auf der Plattform sicher speichern und weiterverarbeiten.

Überblick
Der Beitrag gliedert sich in folgende Abschnitte:
- Speicherung von Streaming-Daten
- Visualisierung von Streaming-Daten
Anders als in Teil 1 lässt sich alles, was hier beschrieben wird, in der AWS-Webkonsole erledigen – Programmierkenntnisse sind nicht erforderlich.
Folgende AWS-Services werden behandelt: IoT Core Rules, IoT Analytics, DynamoDB und Quicksight.
Speicherung von Streaming-Daten
Erfolgskontrolle des IoT-Onboardings
Wenn Sie Geräte erfolgreich in die IoT Registry eingebunden haben und Daten an IoT Core streamen, sehen Sie im Haupt-Dashboard von AWS IoT einen kontinuierlichen Strom eingehender Nachrichten:
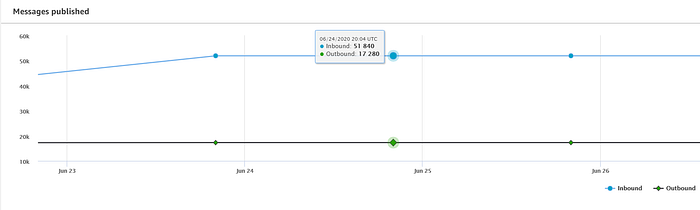
Das Skript zum Streamen von Temperaturdaten aus Teil 1 sendet alle 5 Sekunden einen Messwert an IoT Core. Bei mir zu Hause sind drei Raspberry Pis registriert – einer im Loft im Obergeschoss, einer im Wohnzimmer im Erdgeschoss und einer in einem Schlafzimmer im Untergeschoss. Daher erwarte ich die oben gezeigten 51.840 veröffentlichten Nachrichten pro Tag (17.280 pro Gerät).
Über die IoT-Webkonsole leiten Sie diese Nachrichten mühelos an verschiedene AWS-Services zur Verarbeitung und Speicherung weiter. Egal welcher Zielservice: IoT-Daten landen dort über eine simple IoT Rule, die Sie in der Webkonsole anlegen. Schauen wir uns das anhand einer einfachen DynamoDB-Tabelle an, an die wir alle Streaming-Daten senden.
Streaming an DynamoDB
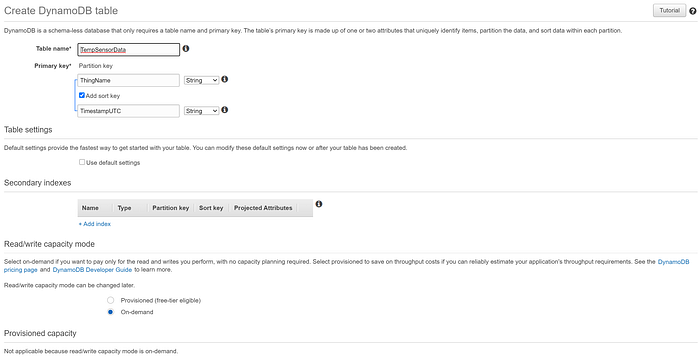
Legen Sie eine DynamoDB-Tabelle namens "TempSensorData" mit dem Partition Key "ThingName" und dem Sort Key "TimestampUTC" an, passend zu den Primärschlüsselwerten, die an IoT Core gestreamt werden. Stellen Sie die Tabelle für unser kleines Testbeispiel auf "On-demand"-Kapazität statt Provisioned, um Kosten zu sparen. Mehr ist nicht zu tun: Sobald wir gleich eine IoT Rule einrichten, die Daten an die Tabelle weiterleitet, erkennt sie die Nicht-Schlüssel-Felder unserer Daten und befüllt die Tabelle entsprechend:
Sobald die Tabelle bereitgestellt ist, wechseln Sie zurück zur IoT-Core-Plattform und navigieren Sie zu Act → Rules. Legen Sie dort eine neue Rule an. Nennen Sie sie "TemperatureSensorRule", hinterlegen Sie eine Beschreibung und konfigurieren Sie das Rule Query Statement so, dass alle Werte erfasst werden, die in das übergeordnete Topic "temperature" gestreamt werden.
Wie lässt sich eine Rule erstellen, die alle Temperaturwerte erfasst, obwohl jedes Gerät in sein eigenes, gerätespezifisches Topic streamt? Die Antwort sind IoT-SQL-Wildcards. Zur Erinnerung: Jedes Gerät streamt in ein Topic, das durch drei Device-Policy-Variablen definiert wird, die zusammen ein gerätespezifisches Topic ergeben:
temperature/${iot:Connection.Thing.Attributes[BuildingName]}/${iot:Connection.Thing.Attributes[Location]}/${iot:Connection.Thing.ThingName}
So sehen zum Beispiel die Topics aus, in die die drei Geräte bei mir zu Hause publizieren:
temperature/house417/loft/sensor_7210b5ba84f64cbbb406e98a1c3b3d32
temperature/house417/living_room/sensor_d51ea63b02bf4cb5b8ac9cf9b464ec3a
temperature/house417/downstairs_bedroom/sensor_b912a3f3c85f4b44ba60720ee43a1a94
Das IoT-Topic in Ihrer IoT-SQL-Rule lautet temperature/#, da die Wildcard # auf einen oder mehrere Subpfade matcht. Das passende IoT-SQL-Statement sieht entsprechend so aus:
SELECT * FROM 'temperature/#'
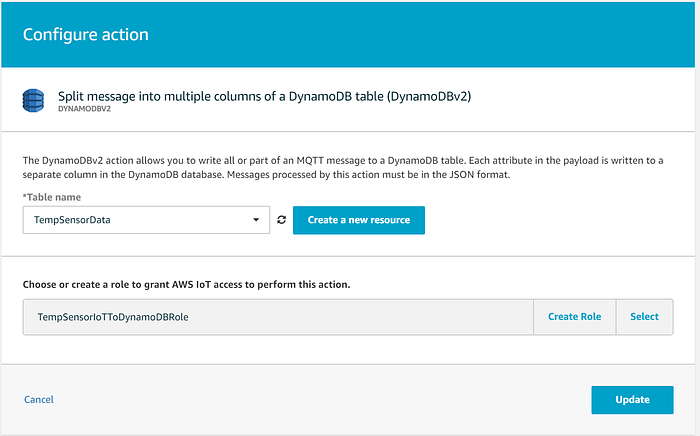
Klicken Sie nun auf "Add action" und wählen Sie die Option, die Daten in eine DynamoDB-Tabelle sendet. Achtung: Wählen Sie unbedingt "DynamoDBv2". Die v1-Variante befüllt Nicht-Schlüssel-Felder nicht automatisch, sondern legt die gesamte Nachricht als einzelnes JSON-String-Feld in der Tabelle ab:

Wählen Sie anschließend die DynamoDB-Tabelle aus, in die gestreamt werden soll, und lassen Sie den Assistenten eine Rolle erstellen, die AWS IoT die Berechtigung erteilt, Daten in die Tabelle zu schreiben:
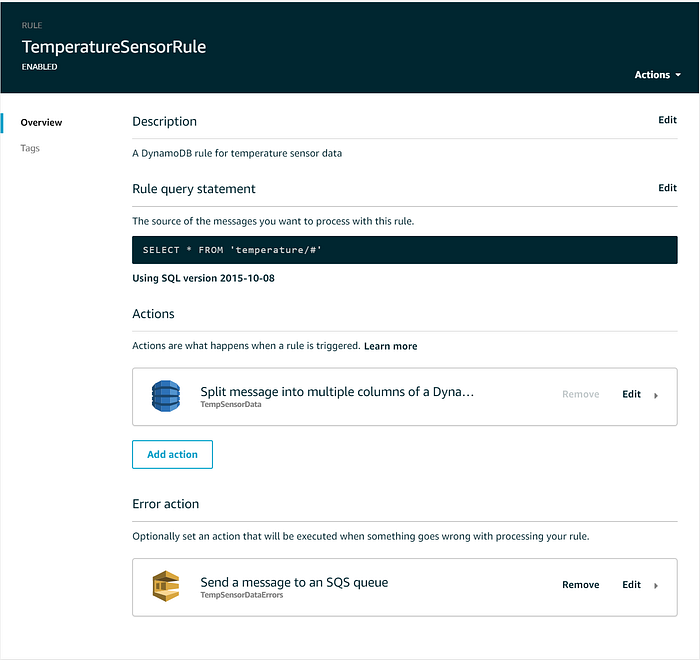
Sobald die IoT Core Rule angelegt ist, können Sie optional eine Error Action ergänzen, die fehlgeschlagene Zustellungen etwa an eine SQS Dead Letter Queue oder einen S3-Bucket weiterleitet. Fertig sollte Ihre IoT Rule in etwa so aussehen:
Nach wenigen Sekunden füllt sich die Tabelle mit Daten:
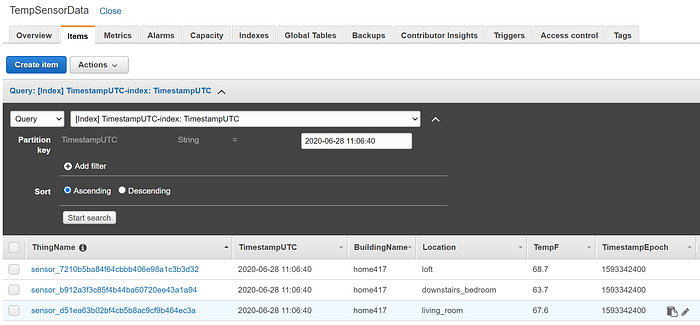
Auf dieser Basis ließen sich nun eigene Analyse- und Visualisierungsanwendungen entwickeln, die Daten aus DynamoDB lesen. Realistischer im Produktivbetrieb (und für eine reine Demo zu kostspielig) wäre es, IoT-Daten statt an DynamoDB an einen Kinesis-Firehose-Datenstrom weiterzuleiten. Dieser Firehose-Stream würde dann gebündelt in ein Data Warehouse wie Redshift und/oder einen Object Store wie S3 schreiben. Das Batch-Writing über Firehose ist entscheidend, um zu verhindern, dass Einzel-Writes aus produktiven IoT-Streams zu Performance-Problemen in Redshift oder zum Erreichen der S3-Schreibgrenzen führen. Redshift, DynamoDB und S3 sind allesamt hervorragende Quellen für Analyseanwendungen im Big-Data-Maßstab.
Sie könnten zum Beispiel einen Apache-Spark-Job auf AWS EMR oder ein Machine-Learning-Modell auf AWS Sagemaker aufsetzen und einen dieser Services aus DynamoDB, Redshift oder S3 lesen lassen.
In diesem Artikel konzentriere ich mich jedoch auf einen rein serverlosen Ansatz für Speicherung und Visualisierung, ganz ohne Programmierung. Schauen wir uns also an, wie wir Rohdaten und gefilterte Datensätze serverlos und mit Lifecycle-Policies im Time-Series-Datastore von IoT Analytics ablegen und anschließend mit Quicksight visualisieren. Da Quicksight nicht aus DynamoDB lesen kann, Redshift als Quelle für eine Demo etwas teuer ist und IoT Analytics unsere Anforderungen an serverlose, durchsatzstarke Datenspeicherung samt Abruf durch QuickSight problemlos erfüllt, setzen wir auf IoT Analytics als Datenspeicher der Wahl.
Streaming an IoT Analytics
Öffnen Sie den Service IoT Analytics und richten Sie über den Quick-Create-Assistenten in einem 1-Klick-Vorgang das Streaming aus unserem IoT-Core-Temperatur-Topic in IoT Analytics ein. Dabei werden erstellt:
- ein Channel, in dem die Roh-IoT-Daten aus IoT Core eintreffen, sowie die IoT Core Rule, die Daten in diesen Channel schiebt
- eine Pipeline, in der Channel-Daten optional gefiltert und transformiert werden
- ein Data Store für die Pipeline-Ausgabe mit zugehöriger Aufbewahrungsdauer
- ein gefiltertes Dataset aus dem Data Store mit eigener Aufbewahrungsdauer und periodischem Neuerzeugungsplan. Auf dieses gefilterte Dataset greift Quicksight für Insights und Visualisierungen zurück.
Das Einrichten all dieser IoT-Analytics-Komponenten ist so einfach wie das Ausfüllen der folgenden zwei Quick-Start-Felder:
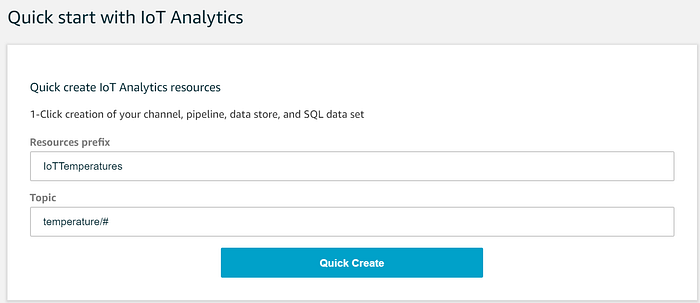
Der Assistent legt anschließend die nötigen Channel-, Pipeline-, Data-Store- und Data-Set-Einträge an. Was diese IoT-Analytics-Komponenten leisten und was der Assistent im Hintergrund tut, ist nicht auf den ersten Blick erkennbar – schauen wir uns die Details an.
Ein IoT Analytics Channel ist die Anlaufstelle für eintreffende Streaming-Daten. Wenn Sie in die Liste der IoT Core Rules zurückkehren, sehen Sie, dass der Assistent eine Rule angelegt hat, die mit der zuvor eingerichteten DynamoDB-Rule identisch ist – nur dass die Action Daten jetzt an den Channel weiterleitet, den der Assistent gerade in IoT Analytics erstellt hat. Hinweis: Wenn Sie fehlerhafte Zustellungen erfassen möchten, müssen Sie die Rule um ein Ziel wie eine SQS-Queue ergänzen:

Eine IoT Analytics Pipeline kann Nachrichten anhand ihrer Attribute optional anreichern, transformieren und filtern. In unserem Beispiel sind keine Manipulationen der Rohdaten nötig, daher belassen wir die Pipeline-Defaults wie sie sind.
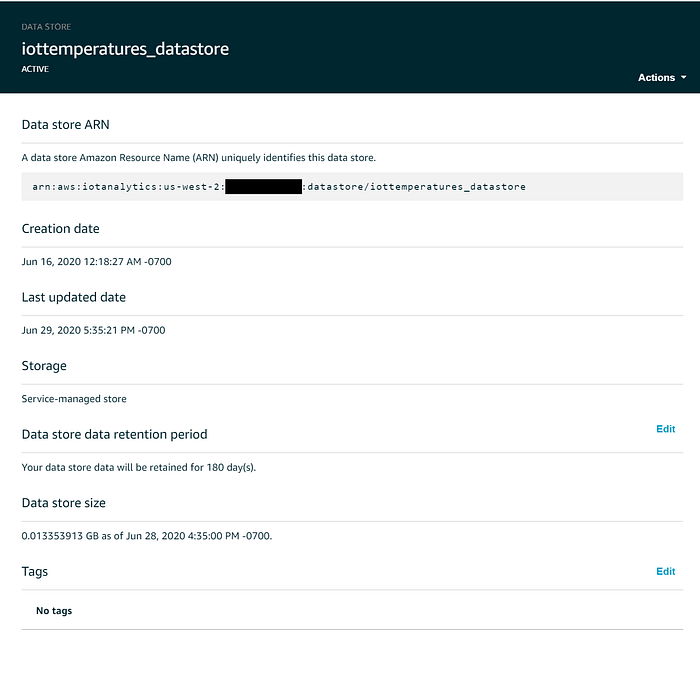
In IoT Data Stores werden Streaming-Daten gespeichert – entweder unbefristet oder für einen festgelegten Zeitraum. Im Hintergrund liegen diese Daten in einem von AWS verwalteten S3-Bucket, sodass Sie weiterhin von der Haltbarkeit von 11 Neunen und 99,99 % Hochverfügbarkeit dieses Services profitieren. Bei Bedarf lässt sich ein Data Store so konfigurieren, dass er Daten in einem von Ihnen kontrollierten S3-Bucket speichert. Das erleichtert den Zugriff auf IoT-Daten für Services, die nicht so eng mit IoT Analytics integriert sind. Für diese Demo bleiben wir aber beim verborgenen, service-managed Bucket.
Standardmäßig werden Daten, die in einen IoT-Analytics-Data-Store gestreamt werden, unbefristet aufbewahrt. Das lässt sich in der Webkonsole jedoch ändern, indem Sie neben "Data store data retention period" auf "Edit" klicken. Um die Kosten im Produktivbetrieb niedrig zu halten, sollten Sie Data-Store-Daten nach einem definierten Zeitraum verfallen lassen. Ich habe meine Temperaturwerte so eingestellt, dass sie nach sechs Monaten ablaufen:

Ein IoT Data Set ist eine per IoT SQL erzeugte Teilmenge eines IoT Data Stores mit eigener Aufbewahrungsdauer und der Möglichkeit, sich auf Abruf oder nach einem wiederkehrenden Zeitplan neu zu erzeugen. Wie Data Stores werden Data Sets als CSV-Dateien in einem service-managed Bucket abgelegt. Konkret heißt das: Sie können auf Basis eines individuellen Filters einen statischen Datensatz erstellen (zum Beispiel alle Temperaturdaten aus einem engen, aber spannenden Zeitfenster), diesen Datensatz einmalig auf Abruf erzeugen und ihn unbefristet für nachgelagerte Analysen aufbewahren – während die ursprünglichen Rohdaten im Data Store gemäß einer Aufbewahrungsdauer ablaufen, die Ihre Organisation als bestmögliche Balance zwischen Rohdaten-Vorhaltung und Wirtschaftlichkeit definiert.
Manche AWS-Services, die mit IoT Analytics integriert sind – etwa Quicksight – beziehen Daten ausschließlich aus Data Sets, während andere wie SageMaker sowohl Data Stores als auch Data Sets nutzen können. Generell sollten alle Services aus Data Sets lesen können. Aufgrund der eingeschränkteren Anbindung an Data Stores und der Kostenfolgen einer unbefristeten Rohdaten-Speicherung in IoT Analytics sollten Sie sich in Produktivszenarien angewöhnen, diskrete, gefilterte Datasets für Analysen oder die Erstellung von ML-Modellen zu erzeugen – wobei der Roh-Data-Store mit der Zeit ausläuft, sofern Ihre Organisation nicht bereit ist, für die vollständige historische Speicherung der IoT-Daten zu zahlen.
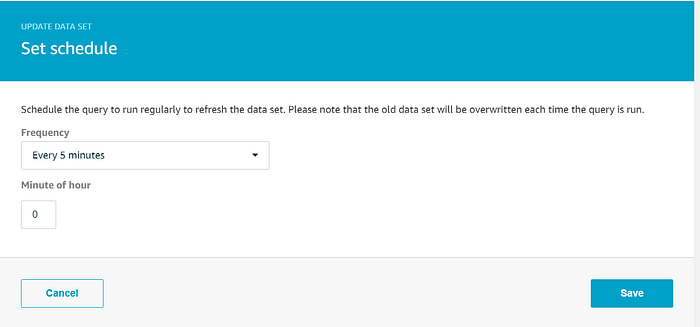
Der Assistent hat ein Dataset angelegt, das alle Daten aus dem Data Store auswählt. Wir nehmen daran zwei Anpassungen vor. Da wir tatsächlich alle Daten des Data Stores für unsere Quicksight-Visualisierung nutzen wollen, lassen wir die SQL-Abfrage unverändert. Damit Quicksight stets möglichst aktuelle Temperaturdaten in den Diagrammen verwendet, soll das Dataset nicht on-demand, sondern alle 5 Minuten per Cron-Job neu erzeugt werden. Klicken Sie neben "Schedule" auf "Edit" und legen Sie die gewünschte Frequenz für die Neuerstellung fest:
Das Dataset soll passend zur Aufbewahrungsdauer unseres Data Stores 180 Tage vorgehalten werden, und wir deaktivieren die Aufbewahrung mehrerer Versionen:
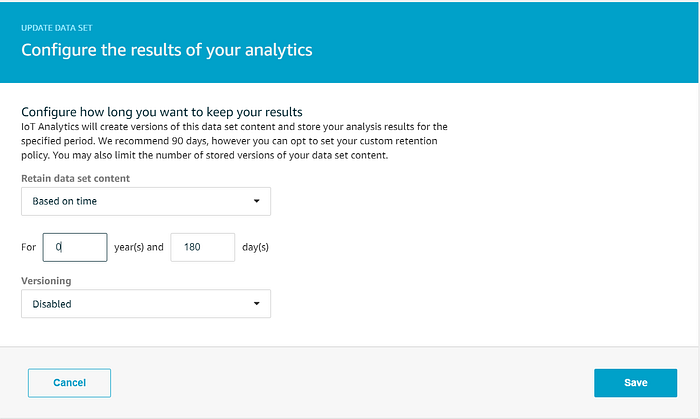
Das für Quicksight verwendete Dataset sollte nun in etwa so aussehen:
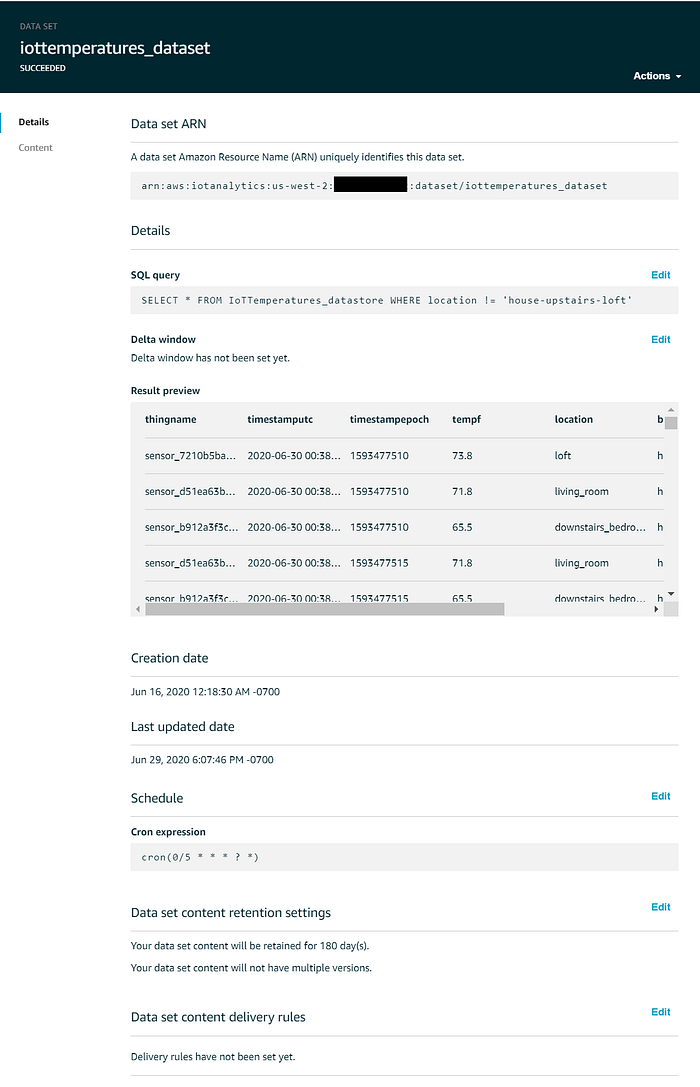
Visualisierung von Streaming-Daten
Mit unserem Temperatur-Dataset im Gepäck schauen wir uns nun die Visualisierungsfunktionen von AWS Quicksight an. Öffnen Sie den Quicksight-Service und wählen Sie als QuickSight-Account-Typ die "Standard edition", um die Demo günstig zu halten:

Hinter dem Marketing-Begriff verbirgt sich Folgendes: SPICE ist schlicht die In-Memory-Berechnungs-Engine von Quicksight, mit der sich Ad-hoc-Analysen und Visualisierungen schnell erstellen lassen. Mit den Daten weniger heimischer IoT-Geräte reicht das kostenlose 1-GB-SPICE-Kontingent für unser Beispiel mehr als aus.
Sobald Ihr QuickSight-Account fertig erstellt ist, gelangen Sie zu einem Dashboard mit mehreren Beispiel-Analysen, die der Service standardmäßig bereitstellt. Über "Manage data" oben rechts sehen Sie auch die Datenquellen, auf denen die Beispiele basieren. Bevor wir ein Dashboard für die IoT-Temperaturanalyse erstellen, müssen wir unser IoT-Analytics-Dataset als Datenquelle einrichten. Klicken Sie auf der Seite "Manage data" auf "New dataset" und wählen Sie aus der Liste der unterstützten Quellen IoT Analytics aus:
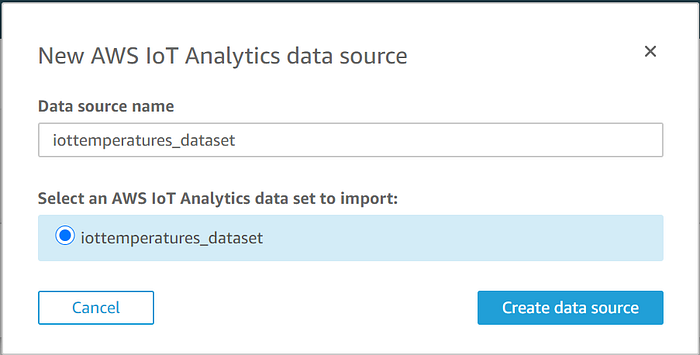
Der zuvor erstellte IoT-Analytics-Data-Store wird angezeigt. Wählen Sie ihn aus, klicken Sie auf "Create data source" und anschließend auf "Visualize":
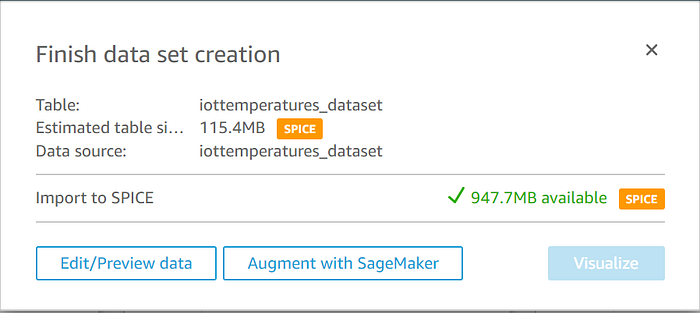
Sie landen daraufhin in einem leeren AutoGraph:

Da sich Zeitreihendaten gut über ein Liniendiagramm darstellen lassen, wählen Sie unter "Visual types" diese Option. Daraufhin verändert sich der Arbeitsbereich und Sie können eine X-Achsen-Dimension, Werte und eine Group-by-Farbe hinzufügen:

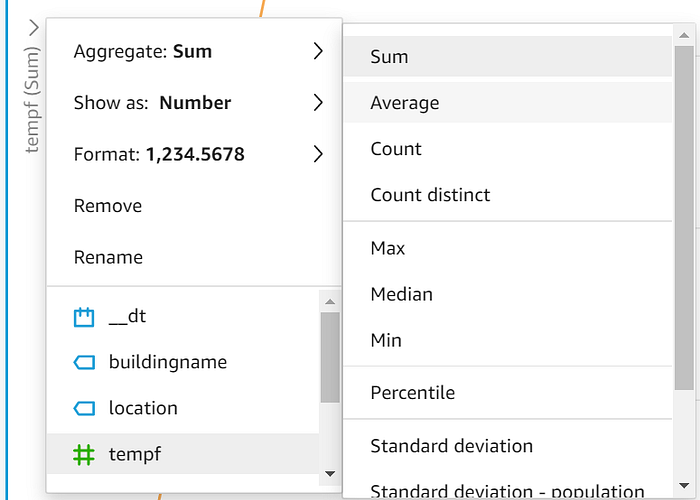
Ziehen Sie "timestamputc" per Drag-and-drop auf die X-Achse, "tempf" auf Value und "location" auf Color. Sobald Ihre Daten visualisiert sind, klicken Sie auf den Dropdown-Pfeil an der Y-Achse und ändern Sie den dargestellten Wert von Sum auf Average:
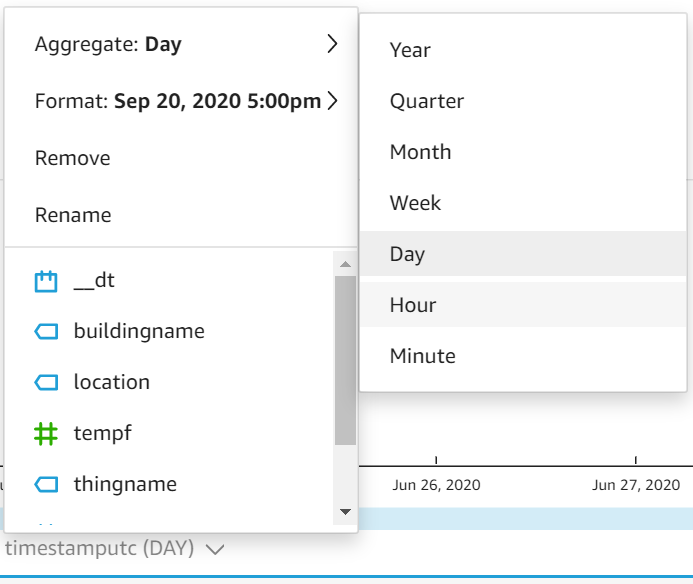
Stellen Sie als Nächstes die X-Achse so um, dass die durchschnittlichen Temperaturwerte nach Stunde statt nach Tag aggregiert werden:
Um die Daten vertikal besser zu skalieren, klicken Sie auf das Zahnradsymbol oben rechts im Diagramm, um die visuellen Formatierungsoptionen einzublenden. Wählen Sie die Y-Achse und dort die Option "Auto (based on data range)" anstelle des Standards "Auto (starting at 0)":

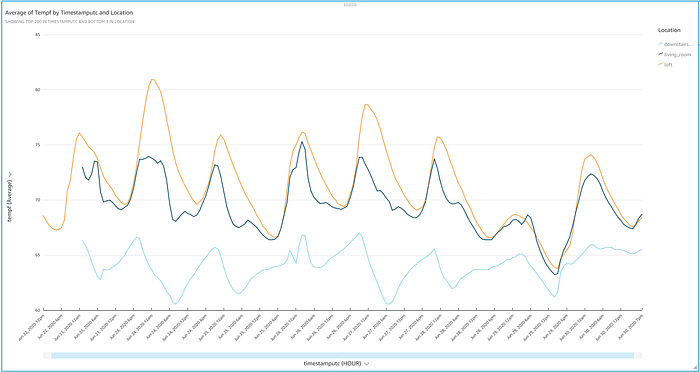
Et voilà! Sie sehen nun ein elegantes Diagramm mit den per IoT gestreamten Temperaturwerten und ihrem typischen Auf und Ab im Tagesverlauf. Schon ein kurzer Blick liefert ein paar interessante Erkenntnisse:
- Das Projekt bestätigt meinen Verdacht, dass das Untergeschoss meines Hauses ein Winterwunderland ist – und das, obwohl der Thermostat im Erdgeschoss während des gesamten Experiments konstant auf 72 °F eingestellt war.
- Im Erdgeschoss zeigen sich Schwankungen von mehr als 5 Grad, obwohl im ganzen Haus doppelt verglaste Fenster verbaut sind und der Thermostat 72 °F halten soll. Vielleicht wird es Zeit für ein smartes Thermostat – und einen Check der Klimaanlage?
- Überrascht hat mich, wie stark die Temperatur im Loft schwankt und wie schlecht es gekühlt wird, besonders an heißen Tagen wie dem 24. Juni. Das Loft befindet sich im selben offenen Raum wie der Thermostat und liegt direkt darüber – dennoch ist es an heißen Tagen wie dem 24. rund 8 Grad wärmer als der Bereich 3 Meter darunter.
- Geöffnete Fenster an kühleren Tagen wie dem 25., 26. und 29. glichen die Temperaturen in Loft und Wohnzimmer an, während es im Untergeschoss weiterhin frostig blieb. Es geht eben nichts über eine kühle Brise, die durchs Haus zieht!
Damit Ihre QuickSight-Visualisierung dauerhaft mit dem regelmäßig aktualisierten IoT-Analytics-Dataset Schritt hält, gehen Sie zurück zum Quicksight-Quell-Dataset und richten Sie einen Aktualisierungszeitplan ein:

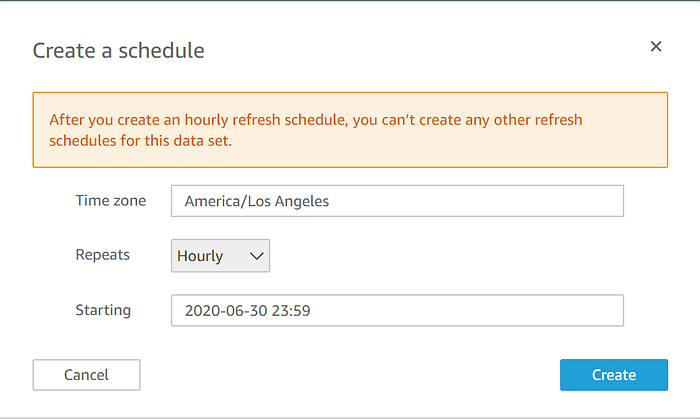
Sie verfügen jetzt über ein regelmäßig aktualisiertes Visualisierungs-Dashboard, das Sie über die Quicksight-Domain auch anderen Personen in Ihrem Unternehmen für IoT-Streaming-Daten im Produktivmaßstab bereitstellen können – und das ganz ohne manuellen Betrieb der Infrastruktur für Speicherung, Datentransport und ansprechende Visualisierung.
Damit endet unsere Tour durch Best Practices für IoT-Daten-Streaming, Speicherung und Visualisierung im Produktivbetrieb! Ich hoffe, Sie hatten Spaß daran, spannende Temperaturtrends in Ihrem eigenen Zuhause aufzuspüren, und konnten unterwegs ein paar Dinge über Serverless auf AWS lernen. Viel Erfolg auf Ihrem IoT-Weg!