Se invia dati in streaming ad AWS IoT Core, archiviarli e visualizzarli correttamente sono passaggi a valle fondamentali, da progettare con largo anticipo per supportare analisi su scala big data.
Riprendendo la precedente trattazione su come effettuare l'onboarding sicuro di una flotta di dispositivi IoT in produzione nell'AWS IoT Registry e trasmettere dati a IoT Core, questo articolo di approfondimento illustra i diversi servizi serverless di AWS da impiegare per archiviare e manipolare in sicurezza tali dati una volta arrivati sulla piattaforma AWS.

Panoramica
L'articolo è suddiviso nelle seguenti sezioni:
- Archiviazione dei dati in streaming
- Visualizzazione dei dati in streaming
A differenza della prima parte, quanto vedremo qui può essere realizzato dalla console web di AWS, quindi non è richiesta alcuna esperienza di programmazione.
I servizi AWS trattati saranno: IoT Core Rules, IoT Analytics, DynamoDB e Quicksight.
Archiviazione dei dati in streaming
Verifica del corretto onboarding IoT
Se ha completato con successo l'onboarding dei dispositivi nell'IoT registry e avviato lo streaming dei dati verso IoT Core, dovrebbe vedere un flusso costante di messaggi in arrivo dal dashboard principale di AWS IoT:
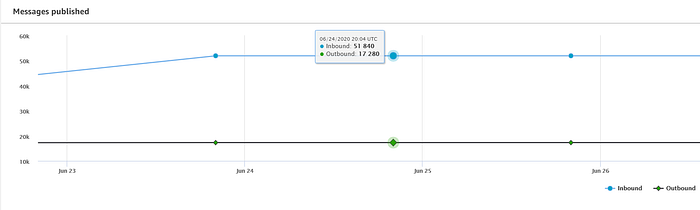
Lo script di streaming della temperatura fornito nella prima parte invia letture a IoT Core ogni 5 secondi. Ho registrato tre dispositivi Raspberry Pi nella mia abitazione — uno nel soppalco al piano superiore, uno nel salotto al piano terra e uno in una camera al piano inferiore — e mi aspetto quindi i 51.840 messaggi pubblicati al giorno mostrati sopra (17.280 messaggi per dispositivo).
La console web di IoT rende immediato l'inoltro di questi messaggi a vari servizi AWS per l'elaborazione e l'archiviazione. A prescindere dal servizio di destinazione, inviare dati IoT a un altro servizio AWS è semplice quanto creare una IoT Rule nella console web. Vediamo insieme come fare, configurando una semplice tabella DynamoDB e inoltrandole tutti i dati in streaming.
Streaming verso DynamoDB
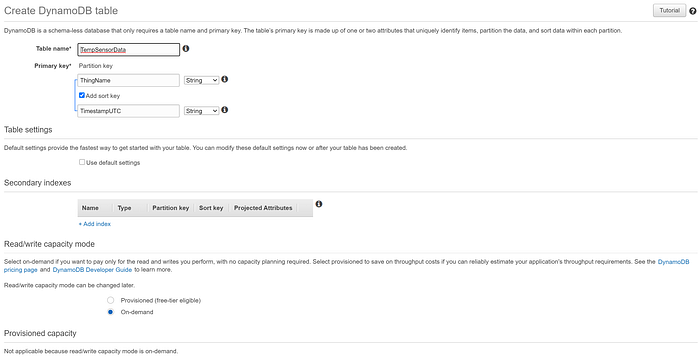
Crei una tabella DynamoDB chiamata "TempSensorData", con una Partition key "ThingName" e una sort key "TimestampUTC", coerenti con i valori della chiave primaria trasmessi a IoT Core. Imposti la tabella in modalità di capacità "On-demand" anziché provisioned, per contenere i costi durante questo piccolo test. Ed è tutto! Quando configureremo una IoT Rule che inoltra i dati a questa tabella, la regola identificherà i campi non chiave nei dati e li popolerà nella tabella:
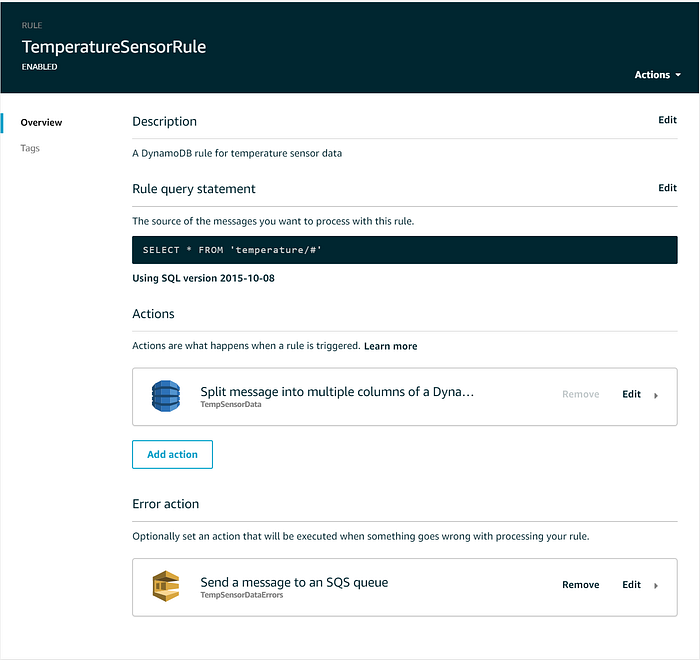
Una volta che il provisioning della tabella è andato a buon fine, torni alla piattaforma IoT Core e si rechi su Act → Rules, quindi crei una nuova regola. La chiami "TemperatureSensorRule", aggiunga una descrizione e imposti la Rule query statement in modo da selezionare tutti i valori trasmessi al topic 'temperature' di alto livello.
Come creare una regola che catturi tutti i valori di temperatura quando ciascun dispositivo trasmette al proprio topic univoco? Lo si può ottenere con i wildcard di IoT SQL. Si ricordi che ogni dispositivo trasmette a un topic definito da tre variabili di policy del dispositivo che, nel loro insieme, generano un topic univoco per dispositivo:
temperature/${iot:Connection.Thing.Attributes[BuildingName]}/${iot:Connection.Thing.Attributes[Location]}/${iot:Connection.Thing.ThingName}
Ad esempio, questi sono i topic su cui pubblicano i tre dispositivi installati in casa mia:
temperature/house417/loft/sensor_7210b5ba84f64cbbb406e98a1c3b3d32
temperature/house417/living_room/sensor_d51ea63b02bf4cb5b8ac9cf9b464ec3a
temperature/house417/downstairs_bedroom/sensor_b912a3f3c85f4b44ba60720ee43a1a94
Il topic IoT da indicare nella sua regola IoT SQL sarà temperature/#, dato che il wildcard # corrisponde a uno o più sottopercorsi. L'istruzione IoT SQL da utilizzare è quindi la seguente:
SELECT * FROM 'temperature/#'
A questo punto clicchi su "Add action" e scelga l'opzione che invia i dati a una tabella DynamoDB. Faccia attenzione: si assicuri di selezionare l'opzione "DynamoDBv2", poiché la v1 non popola automaticamente i campi non chiave e archivia invece l'intero messaggio nella tabella come un unico campo JSON-as-string:

Da qui, selezioni la tabella DynamoDB di destinazione per i dati in streaming e consenta al wizard di creare un ruolo che concede ad AWS IoT i permessi necessari per inviare i dati IoT alla tabella DynamoDB:
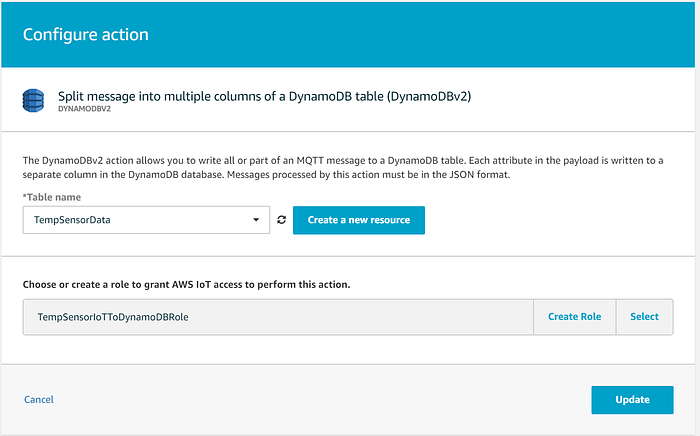
Una volta creata la IoT Core Rule, può eventualmente aggiungere un'Error action che inoltri i messaggi non recapitati, ad esempio, a una dead letter queue SQS o a un bucket S3. Una volta completata, la sua IoT Rule dovrebbe presentarsi così:
Dopo qualche secondo vedrà la tabella popolarsi con i dati:
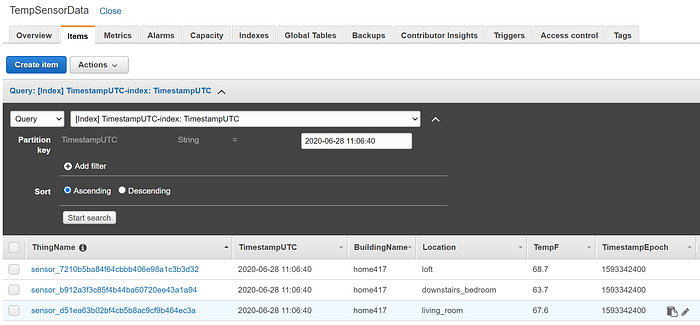
Da qui potrebbe sviluppare applicazioni personalizzate di analytics e visualizzazione che leggano i dati da DynamoDB. In uno scenario di produzione più realistico (e troppo oneroso ai fini di una semplice demo), potrebbe inoltrare i dati IoT a un data stream Kinesis Firehose anziché a DynamoDB. Il flusso Firehose effettuerebbe poi scritture in batch verso un data warehouse come Redshift e/o un object store come S3: la scrittura in batch di Firehose è essenziale per evitare che le singole scritture, generate da dati IoT in streaming su scala produttiva, causino problemi di performance a Redshift o saturino i limiti di throughput di scrittura di S3. Redshift, DynamoDB e S3 sono tutte sorgenti eccellenti per applicazioni di analytics su scala big data.
Ad esempio, potrebbe sviluppare un job Apache Spark su AWS EMR oppure un modello di machine learning eseguito su AWS Sagemaker, e fare in modo che uno qualsiasi di questi servizi attinga da DynamoDB, Redshift o S3.
In questo articolo, però, vorrei concentrarmi su un approccio puramente serverless ad archiviazione e visualizzazione, che non richieda alcuna programmazione. Vediamo dunque come archiviare, in modalità serverless, i dati grezzi e i dataset filtrati con policy di lifecycle utilizzando il datastore time-series di IoT Analytics, per poi servirsi di Quicksight per la visualizzazione. Poiché Quicksight non può attingere da DynamoDB, Redshift come sorgente è un po' costoso ai fini di una demo e IoT Analytics soddisfa agevolmente i requisiti di archiviazione e recupero dati ad alto throughput in modalità serverless da QuickSight, procederemo proprio con IoT Analytics come data store di riferimento.
Streaming verso IoT Analytics
Acceda al servizio IoT Analytics e utilizzi il wizard Quick Create per avviare un processo di creazione in 1 click che invii in streaming i dati a IoT Analytics dal nostro topic temperature di IoT Core. Il processo creerà:
- un canale in cui arriveranno i dati IoT grezzi da IoT Core, oltre alla IoT Core Rule che instrada i dati verso questo canale;
- una pipeline in cui i dati del canale possono essere facoltativamente filtrati e trasformati;
- un data store per i dati in output dalla pipeline, con un periodo di conservazione associato;
- un dataset filtrato a partire dal data store, dotato di un proprio periodo di conservazione e di una pianificazione periodica di rigenerazione. Il dataset filtrato è ciò che Quicksight utilizzerà per generare insight e visualizzazioni.
Configurare tutti questi componenti di IoT Analytics è semplice quanto compilare i due campi del Quick Start qui sotto:
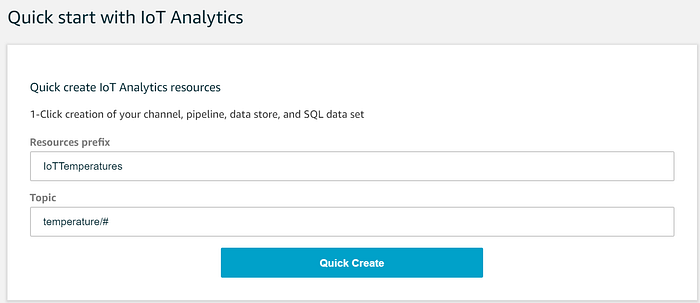
Il wizard creerà quindi le voci necessarie di Channel, Pipeline, Data Store e Data Set. Cosa fanno questi componenti di IoT Analytics e in cosa consiste l'azione del wizard non è del tutto trasparente: vediamo quindi i dettagli.
Un Channel di IoT Analytics è il punto di arrivo dei dati in streaming. Tornando all'elenco delle IoT Core Rules, noterà che il wizard ha creato una regola identica a quella DynamoDB configurata in precedenza, con la differenza che l'Action ora inoltra i dati al canale appena creato dal wizard nella piattaforma IoT Analytics. Tenga presente che, se desidera intercettare i recapiti di messaggi falliti, dovrà aggiornare la regola indicando una destinazione come una coda SQS:

Una Pipeline di IoT Analytics permette, in modo opzionale, di arricchire, trasformare e filtrare i messaggi in base ai loro attributi. Per il nostro esempio non serve manipolare i dati grezzi, quindi lasceremo invariate le impostazioni predefinite della Pipeline.
I Data store IoT sono il luogo in cui vengono conservati i dati in streaming, a tempo indeterminato o per un periodo definito. Dietro le quinte i dati sono archiviati in un bucket S3 gestito da AWS, quindi continua a beneficiare degli 11 nove di durabilità e del 99,99% di alta disponibilità di quel servizio. Se necessario, un data store può essere configurato per salvare i dati in un bucket S3 sotto il suo controllo, così da semplificare l'accesso e l'utilizzo dei dati IoT da parte di servizi che non si integrano altrettanto bene con IoT Analytics; per gli scopi di questa demo, però, ci limiteremo al bucket gestito dal servizio.
Per impostazione predefinita, i dati inviati in streaming a un data store di IoT Analytics vengono conservati a tempo indeterminato; la modifica può però essere effettuata dalla console web cliccando su "Edit" accanto a "Data store data retention period". Per contenere i costi IoT in produzione, è opportuno far scadere i dati del Data Store dopo un certo periodo. Io ho impostato la scadenza dei valori di temperatura a sei mesi:

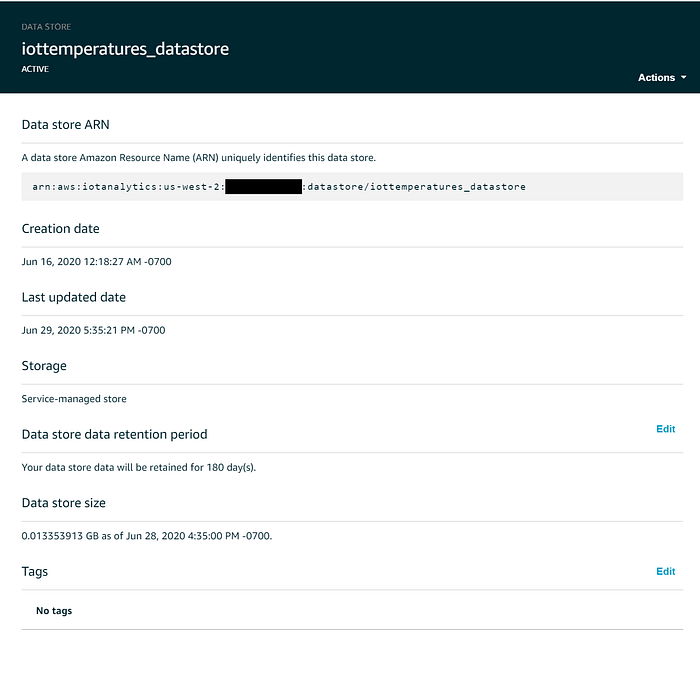
Un IoT Data Set è un sottoinsieme di un IoT Data Store creato con IoT SQL, che dispone di un proprio periodo di conservazione e della capacità di rigenerarsi su richiesta o secondo una pianificazione ricorrente. Come i Data Store, i Data Set vengono salvati come file CSV in un bucket gestito dal servizio. In sostanza, i Data Set le permettono di creare un set di dati statico basato su un filtro personalizzato (ad esempio, selezionare tutti i dati di temperatura in un intervallo di tempo ristretto ma significativo), generarlo una volta sola su richiesta e conservarlo a tempo indeterminato per le analisi a valle, lasciando invece scadere i messaggi originali e grezzi del data store secondo un periodo di conservazione che la sua organizzazione ritiene il migliore compromesso tra ricchezza dei dati grezzi e sostenibilità dei costi.
Alcuni servizi AWS che si integrano con IoT Analytics, come Quicksight, attingono solo dai data set, mentre altri come SageMaker possono attingere sia dai data store sia dai data set. In generale, tutti i servizi dovrebbero essere in grado di leggere dai data set. Vista la connettività più limitata con i data store e l'impatto economico della conservazione a tempo indeterminato dei dati grezzi in IoT Analytics, in un contesto di produzione conviene adottare l'approccio di creare dataset discreti e filtrati da utilizzare per analytics o per la generazione di modelli ML, lasciando scadere il data store grezzo nel tempo, a meno che la sua organizzazione non ritenga sostenibile pagare per la conservazione completa dello storico dei dati IoT.
Il wizard avrà creato un data set che seleziona tutti i dati dal data store; tuttavia dobbiamo apportare due modifiche. Vogliamo utilizzare tutti i dati del data store per la nostra visualizzazione Quicksight, quindi lasciamo invariata la query SQL. Vogliamo invece che Quicksight si basi sui dati di temperatura più aggiornati: anziché rigenerare il data set su richiesta, configuriamo un cron job che lo ricrei ogni 5 minuti. Clicchi su "Edit" accanto a "Schedule" e imposti la frequenza di rigenerazione desiderata:
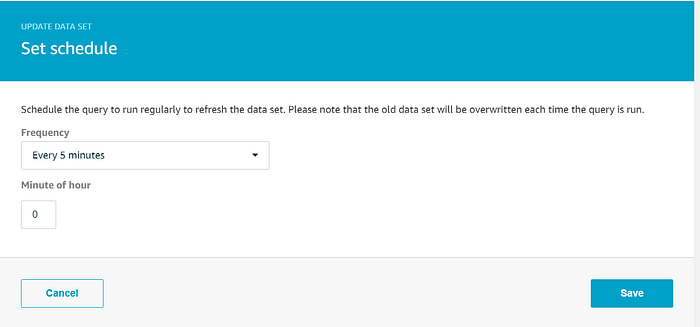
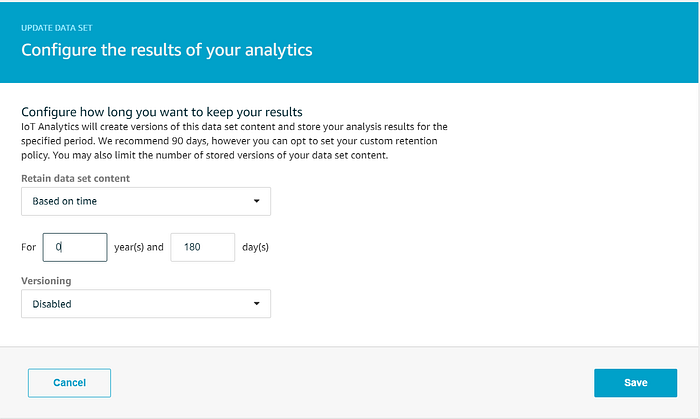
Vogliamo che il data set venga conservato per 180 giorni, in linea con il periodo di conservazione del data store, e disattivare la conservazione di più versioni:
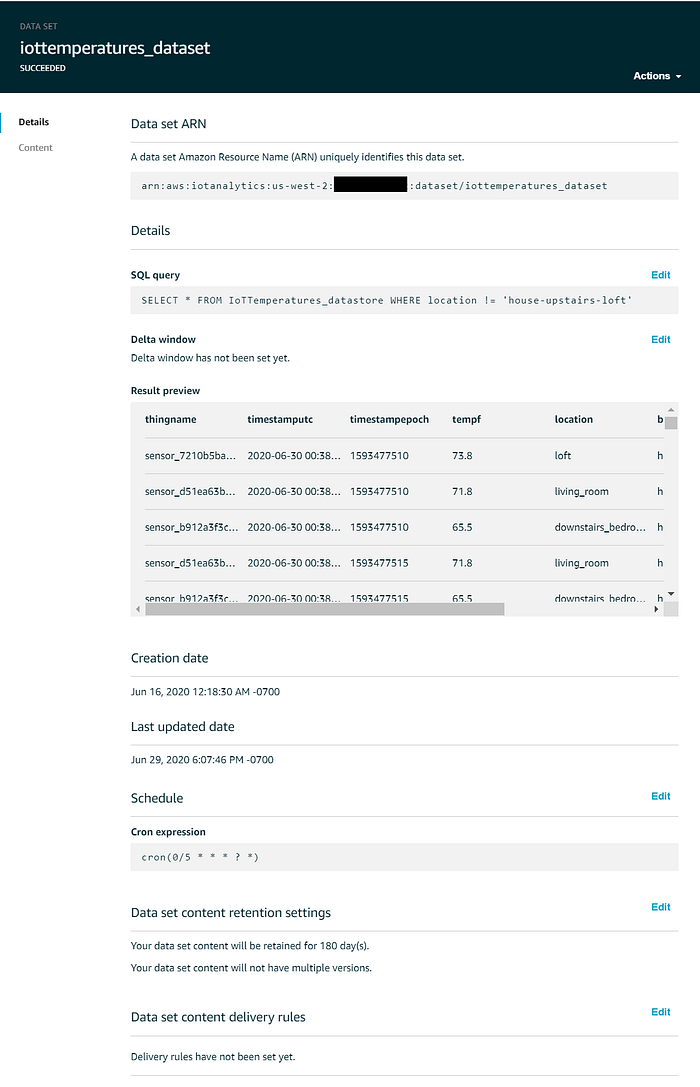
Il data set da utilizzare per Quicksight dovrebbe presentarsi così:
Visualizzazione dei dati in streaming
Con il dataset di temperatura pronto, vediamo da vicino le capacità di visualizzazione di AWS Quicksight. Acceda al servizio Quicksight e selezioni il tipo di account QuickSight "Standard edition" per mantenere bassi i costi della demo:

Al di là della terminologia di marketing, SPICE è semplicemente il motore di calcolo in-memory di Quicksight, pensato per generare rapidamente analisi e visualizzazioni ad hoc. Con i dati provenienti da pochi dispositivi IoT domestici, il livello gratuito SPICE da 1 GB sarà più che sufficiente per questa guida.
Una volta completata la creazione del suo account QuickSight, verrà indirizzato a un dashboard che elenca diverse analisi di esempio fornite di default dal servizio. Cliccando su "Manage data" in alto a destra, vedrà anche le sorgenti che alimentano queste analisi di esempio. Prima di creare un dashboard di analisi della temperatura IoT, dobbiamo configurare il nostro data set di IoT Analytics come sorgente dati. Clicchi su "New dataset" dalla schermata "Manage data" e selezioni IoT Analytics dall'elenco delle sorgenti supportate:
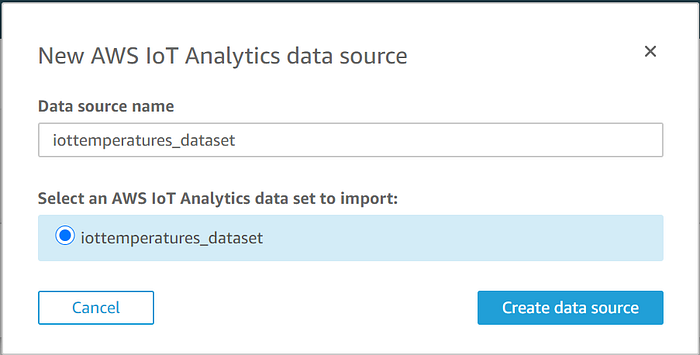
Verrà mostrato il data store di IoT Analytics che abbiamo creato. Lo selezioni e clicchi "Create data source", quindi clicchi "Visualize" al termine:
Si troverà davanti un AutoGraph vuoto:

Sapendo che i dati di serie temporale sono ben rappresentati da un grafico a linee, selezioni quell'opzione sotto "Visual types". L'area di lavoro si trasformerà di conseguenza, permettendoci di aggiungere una dimensione sull'asse x, dei valori e un colore di raggruppamento:

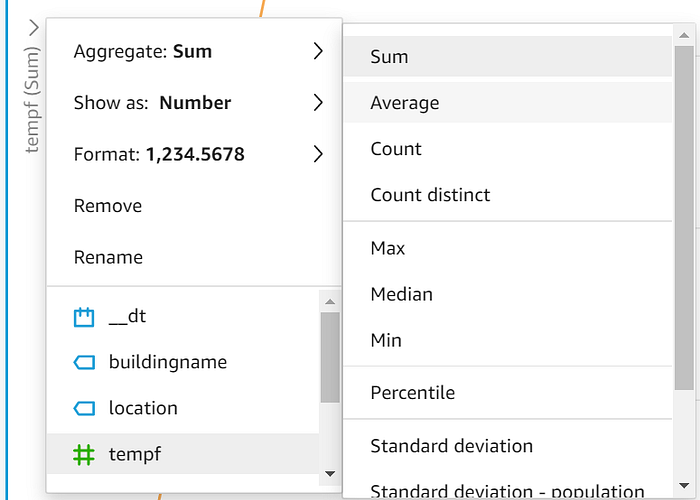
Trascini "timestamputc" sull'asse X, "tempf" su Value e "location" su Color. Una volta visualizzati i dati, apra il menu a discesa sull'asse y e cambi il valore mostrato da Sum a Average:
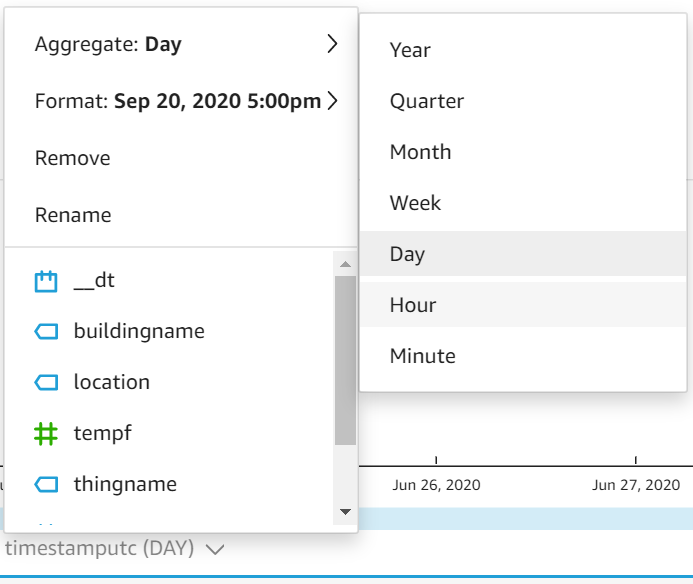
Modifichi quindi l'asse x in modo che aggreghi i valori medi di temperatura per Hour anziché per Day:
Per migliorare la scala verticale dei dati, clicchi sull'icona dell'ingranaggio nell'angolo in alto a destra del grafico per accedere all'elenco delle opzioni di formattazione visiva. Scelga l'asse y e selezioni l'opzione "Auto (based on data range)" anziché l'impostazione predefinita "Auto (starting at 0)":

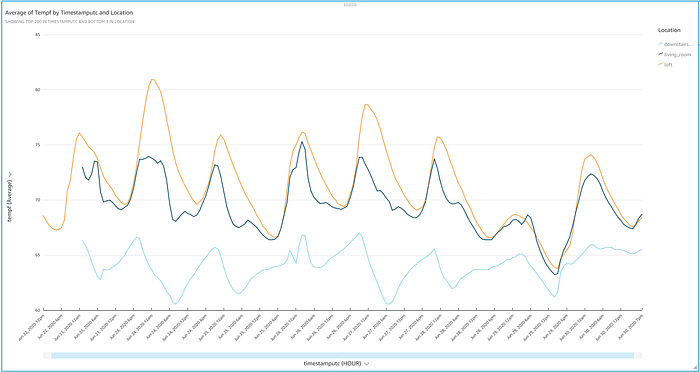
Et voilà! Ora ha davanti un grafico elegante che mostra i valori di temperatura trasmessi via IoT, con l'andamento ciclico tipico delle ore del giorno. Bastano pochi secondi per cogliere alcuni elementi interessanti:
- Il progetto conferma la mia impressione che il piano inferiore della casa sia una sorta di paese delle nevi, nonostante il termostato al piano terra sia rimasto fisso a 72 gradi per tutto l'esperimento.
- Il piano terra registra un'ampia variabilità di temperatura, >5 gradi, pur cercando di mantenere i 72 gradi e malgrado i doppi vetri presenti in tutta la casa. Forse è il momento di passare a un termostato smart e far controllare l'impianto HVAC?
- Mi ha sorpreso quanto sia variabile e poco rinfrescato il soppalco, soprattutto nelle giornate calde come il 24 giugno. Il soppalco si trova nella stessa stanza aperta del termostato, e proprio sopra di esso, eppure nelle giornate calde come quella del 24 risulta circa 8 gradi più caldo dello spazio sottostante a 3 metri di distanza.
- Aprire le finestre nelle giornate più fresche, come il 25, il 26 e il 29, ha permesso di equiparare le temperature di soppalco e salotto, mentre il piano inferiore è comunque rimasto gelido. Niente sostituisce davvero una brezza fresca che attraversa la casa!
Per essere certo che la sua visualizzazione QuickSight sia sempre allineata al data set di IoT Analytics aggiornato regolarmente, torni al dataset Quicksight di origine e configuri una pianificazione di refresh:

Ora dispone di un dashboard di visualizzazione aggiornato regolarmente, da condividere con altre persone della sua azienda tramite il dominio Quicksight, per dati IoT in streaming su scala produttiva: il tutto senza dover gestire manualmente l'infrastruttura di archiviazione, trasferimento e visualizzazione dei dati.
Si conclude qui il nostro percorso tra le best practice per streaming, archiviazione e visualizzazione dei dati IoT in produzione. Spero si sia divertito a scoprire tendenze di temperatura interessanti nella sua abitazione e che, lungo il cammino, abbia imparato qualcosa in più sul serverless su AWS. In bocca al lupo per il suo percorso nell'IoT!