Si transmites datos a AWS IoT Core, almacenarlos y visualizarlos correctamente son piezas clave del flujo posterior que conviene diseñar con la debida antelación para soportar análisis a escala de big data.
Como continuación de mi artículo anterior sobre cómo incorporar de forma segura una flota de dispositivos IoT a escala de producción al AWS IoT Registry y transmitir datos a IoT Core, este artículo de seguimiento aborda los distintos servicios serverless de AWS que conviene usar para almacenar y manipular esos datos de forma segura una vez que llegan a la plataforma de AWS.

Visión general
Este artículo se divide en las siguientes secciones:
- Almacenamiento de datos en streaming
- Visualización de datos en streaming
A diferencia de la parte uno, todo lo que se cubre aquí puede hacerse desde la consola web de AWS, así que no se requiere experiencia en programación.
Se cubrirán los siguientes servicios de AWS: IoT Core Rules, IoT Analytics, DynamoDB y Quicksight.
Almacenamiento de datos en streaming
Verificación de incorporación exitosa a IoT
Si lograste incorporar dispositivos al registro de IoT y comenzaste a transmitir datos a IoT Core, deberías ver un flujo constante de mensajes llegando desde el dashboard principal de AWS IoT:
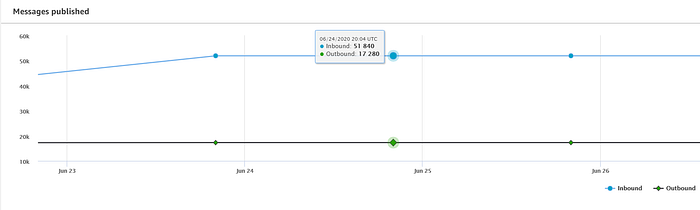
El script de streaming de temperatura que compartí en la parte uno envía lecturas a IoT Core cada 5 segundos. Registré tres dispositivos Raspberry Pi en mi casa: uno en el loft del piso superior, uno en la sala del piso principal y otro en una habitación de la planta baja. Por eso esperaba ver los 51,840 mensajes publicados al día que aparecen arriba (17,280 mensajes por dispositivo).
La consola web de IoT facilita enormemente el reenvío de estos mensajes a varios servicios de AWS para su procesamiento y almacenamiento. Sin importar el servicio de destino, enviar datos de IoT a otro servicio de AWS es tan simple como crear una IoT Rule en la consola web. Veamos cómo hacerlo configurando una tabla sencilla de DynamoDB y enviándole todos los datos en streaming.
Streaming hacia DynamoDB
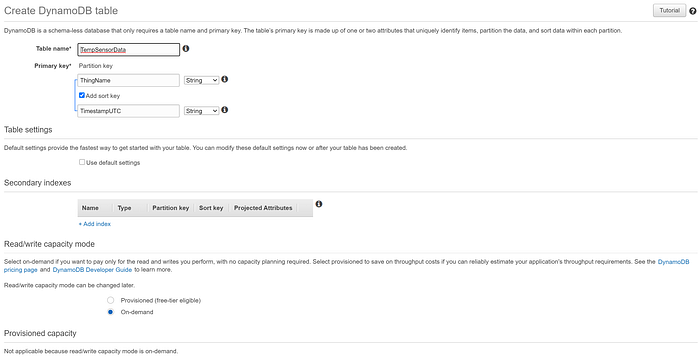
Crea una tabla de DynamoDB llamada "TempSensorData", con una Partition key de "ThingName" y una sort key de "TimestampUTC", de modo que coincidan con los valores de clave primaria que se transmiten a IoT Core. Configura la tabla en modo "On-demand" en lugar de aprovisionada para ahorrar dinero durante este pequeño ejemplo de prueba. ¡Eso es todo! Cuando configuremos una IoT Rule que reenvíe datos a esta tabla, la regla identificará los campos no clave de los datos y los completará en la tabla:
Una vez aprovisionada la tabla, vuelve a la plataforma IoT Core y ve a Act → Rules; luego crea una nueva regla. Ponle a esta regla el nombre "TemperatureSensorRule", agrega una descripción y configura la sentencia de consulta de la regla para seleccionar todos los valores transmitidos al tópico de alto nivel 'temperature'.
¿Cómo crear una regla que capture todos los valores de temperatura cuando cada dispositivo transmite a su propio tópico exclusivo? Se logra con IoT SQL wildcards. Recuerda que cada dispositivo transmite a un tópico definido por tres variables de política del dispositivo que, en conjunto, crean un tópico exclusivo por dispositivo:
temperature/${iot:Connection.Thing.Attributes[BuildingName]}/${iot:Connection.Thing.Attributes[Location]}/${iot:Connection.Thing.ThingName}
Por ejemplo, estos son los tópicos en los que publican los tres dispositivos de mi casa:
temperature/house417/loft/sensor_7210b5ba84f64cbbb406e98a1c3b3d32
temperature/house417/living_room/sensor_d51ea63b02bf4cb5b8ac9cf9b464ec3a
temperature/house417/downstairs_bedroom/sensor_b912a3f3c85f4b44ba60720ee43a1a94
El tópico de IoT a seleccionar en tu regla IoT SQL será temperature/#, dado que el wildcard # coincide con uno o más subpaths. Por lo tanto, la sentencia IoT SQL a usar es la siguiente:
SELECT * FROM 'temperature/#'
Desde aquí, haz clic en "Add action" y elige la opción que envía datos a una tabla de DynamoDB. Ojo: asegúrate de seleccionar la opción 'DynamoDBv2', ya que la opción v1 no completa automáticamente los campos no clave, sino que almacena el mensaje completo en la tabla como un único campo de tipo JSON-as-string:

A continuación, selecciona la tabla de DynamoDB hacia la cual transmitir los datos y deja que el wizard cree un rol que otorgue a AWS IoT permisos para enviar datos de IoT a esa tabla:
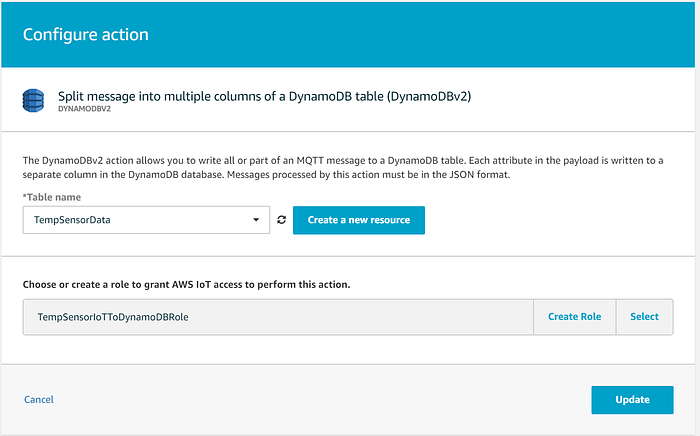
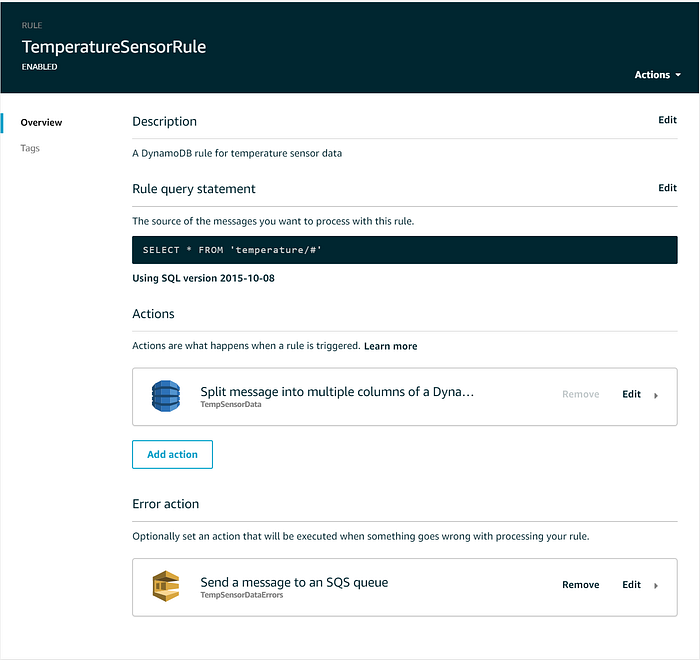
Una vez creada la IoT Core Rule, opcionalmente puedes agregar una Error action que envíe los mensajes con entrega fallida a, por ejemplo, una dead letter queue de SQS o un bucket de S3. Tu IoT Rule debería verse así una vez completada:
Después de unos segundos verás la tabla con datos:
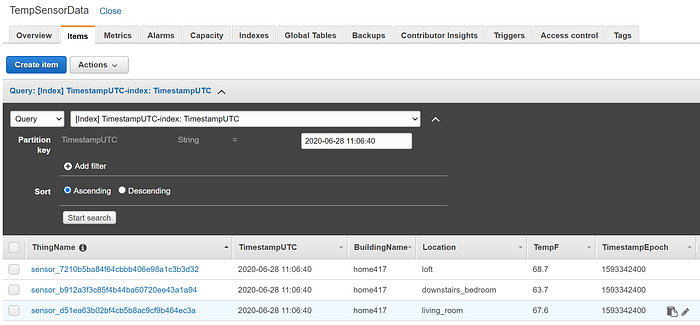
Desde aquí podrías construir aplicaciones personalizadas de analítica y visualización que extraigan datos de DynamoDB. En un entorno de producción real (y demasiado costoso para los fines de un demo), lo más realista sería reenviar los datos de IoT a un data stream de Kinesis Firehose en lugar de DynamoDB. Ese stream de Firehose escribiría por lotes en un data warehouse como Redshift y/o en un object store como S3, y la escritura por lotes de Firehose es clave para evitar que las escrituras individuales de datos IoT a escala de producción provoquen problemas de rendimiento en Redshift o lleguen a los límites de throughput de escritura de S3. Redshift, DynamoDB y S3 son excelentes fuentes para aplicaciones de analítica a escala de big data.
Por ejemplo, podrías construir un job de Apache Spark sobre AWS EMR o un modelo de machine learning corriendo en AWS Sagemaker, y que cualquiera de esos servicios extraiga datos desde DynamoDB, Redshift o S3.
Sin embargo, en este artículo me gustaría enfocarme en un enfoque puramente serverless de almacenamiento y visualización en el que no haya que escribir código. Con eso en mente, veamos cómo, de forma serverless, podemos almacenar nuestros datos crudos y datasets filtrados con políticas de ciclo de vida usando el datastore de series temporales de IoT Analytics, y luego usar Quicksight para la visualización. Dado que Quicksight no puede extraer datos desde DynamoDB, que Redshift como fuente resulta algo costoso para los fines de un demo, y que IoT Analytics cumple sin problema con nuestros requisitos de almacenamiento serverless de alto throughput y consulta desde QuickSight, avanzaremos con IoT Analytics como almacén de datos elegido.
Streaming hacia IoT Analytics
Ve al servicio IoT Analytics y usa el wizard Quick Create para iniciar un proceso de creación con un solo clic que transmita datos hacia IoT Analytics desde nuestro tópico de temperatura de IoT Core. Este proceso creará:
- Un canal donde llegarán los datos crudos de IoT desde IoT Core, así como la IoT Core Rule que mueve los datos hacia ese canal
- Un pipeline donde los datos del canal pueden filtrarse y transformarse opcionalmente
- Un data store para los datos de salida del pipeline con un período de retención asociado
- Un dataset filtrado a partir del data store con su propio período de retención y un calendario periódico de regeneración. Ese dataset filtrado es el que Quicksight usará para crear sus insights y visualizaciones.
Configurar todos estos componentes de IoT Analytics es tan sencillo como llenar los siguientes dos campos del Quick Start:
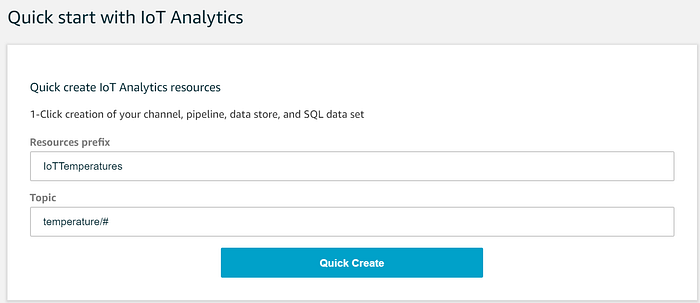
El wizard creará entonces los Channel, Pipeline, Data Store y Data Set requeridos. Lo que hacen estos componentes de IoT Analytics y lo que ejecuta el wizard no es transparente, así que repasemos los detalles.
Un IoT Analytics Channel es donde llegan los datos en streaming. Si vuelves a la lista de IoT Core Rules, notarás que el wizard creó una regla idéntica a la regla de DynamoDB que configuraste antes, salvo que la Action ahora reenvía los datos al canal que el wizard acaba de crear en la plataforma IoT Analytics. Ten en cuenta que si quieres capturar las entregas de mensajes erróneas, deberás actualizar la regla para especificar un destino, como una cola SQS:

Un IoT Analytics Pipeline te permite enriquecer, transformar y filtrar mensajes opcionalmente según sus atributos. La manipulación de datos crudos no se requiere en nuestro ejemplo, así que dejaremos los valores por defecto del Pipeline tal cual.
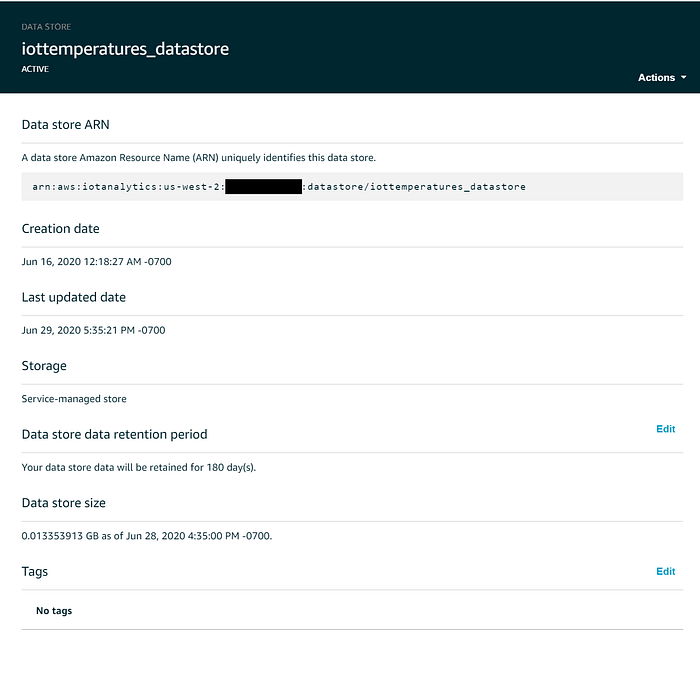
Los IoT Data stores son donde se almacenan los datos en streaming, ya sea de forma indefinida o por un período específico. Detrás de escena, estos datos se guardan en un bucket de S3 administrado por AWS, así que sigues beneficiándote de los 11 nueves de durabilidad y el 99.99% de alta disponibilidad de ese servicio. Si lo deseas, un data store puede configurarse para guardar los datos en un bucket de S3 que tú controles, lo que facilita acceder y trabajar con datos IoT desde servicios que tal vez no se integren tan bien con IoT Analytics, pero para los fines de este demo nos quedaremos con el bucket oculto administrado por el servicio.
Por defecto, los datos transmitidos a un data store de IoT Analytics se retienen indefinidamente; sin embargo, esto puede modificarse desde la consola web haciendo clic en "Edit" junto a "Data store data retention period". Para mantener bajos los costos de IoT a escala de producción, conviene que los datos del Data Store expiren tras cierto período. Configuré que mis valores de temperatura expiren después de seis meses:

Un IoT Data Set es un subconjunto de un IoT Data Store creado con IoT SQL, que cuenta con su propio período de retención y con la capacidad de regenerarse a demanda o de forma programada. Al igual que los Data Stores, los Data Sets se almacenan como archivos CSV en un bucket administrado por el servicio. En definitiva, los Data Sets te permiten crear un dataset estático basado en un filtro personalizado (por ejemplo, seleccionar todos los datos de temperatura de un rango de tiempo acotado pero interesante), generar ese dataset una sola vez bajo demanda y conservarlo de forma indefinida para analítica posterior, mientras dejas que los mensajes originales del data store crudo expiren según un período de retención que tu organización considere el balance más eficaz entre retención de datos crudos y costo.
Algunos servicios de AWS que se integran con IoT Analytics, como Quicksight, solo pueden consumir data sets, mientras que otros, como SageMaker, pueden hacerlo tanto desde data stores como desde data sets. Por lo general, todos los servicios deberían poder consumir desde data sets. Debido a la conectividad más limitada con los data stores y a las implicaciones de costo de almacenar datos crudos de forma indefinida en IoT Analytics, en un caso de uso de producción conviene adoptar la metodología de crear datasets filtrados y discretos para usarlos en analítica o en la generación de modelos de ML, dejando que el data store crudo expire con el tiempo, salvo que tu organización considere aceptable pagar por el almacenamiento del historial completo de los datos IoT.
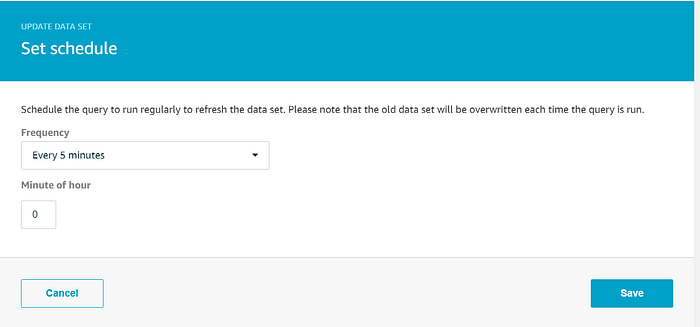
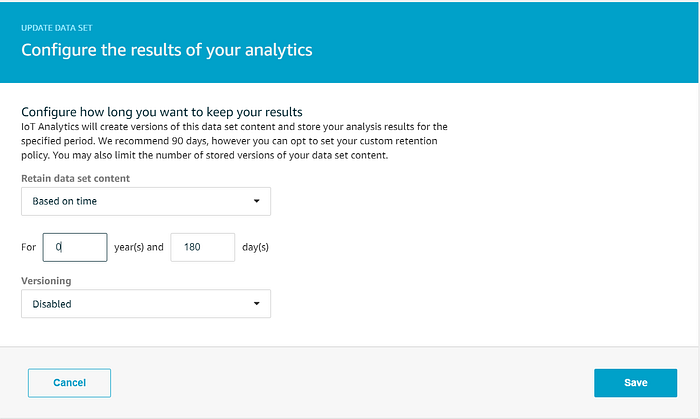
El wizard habrá creado un dataset que selecciona todos los datos del data store; sin embargo, necesitamos hacerle dos ajustes. Sí planeamos utilizar todos los datos del data store para nuestra visualización en Quicksight, así que dejaremos la consulta SQL tal cual. Queremos que Quicksight muestre los datos de temperatura más actualizados en sus gráficos, así que en lugar de regenerar el dataset bajo demanda, configuremos un cron job para regenerarlo cada 5 minutos. Haz clic en "Edit" junto a "Schedule" y configura la frecuencia de regeneración deseada:
Queremos que el dataset se conserve durante 180 días, igualando el período de retención del data store, y queremos deshabilitar la retención de múltiples versiones:
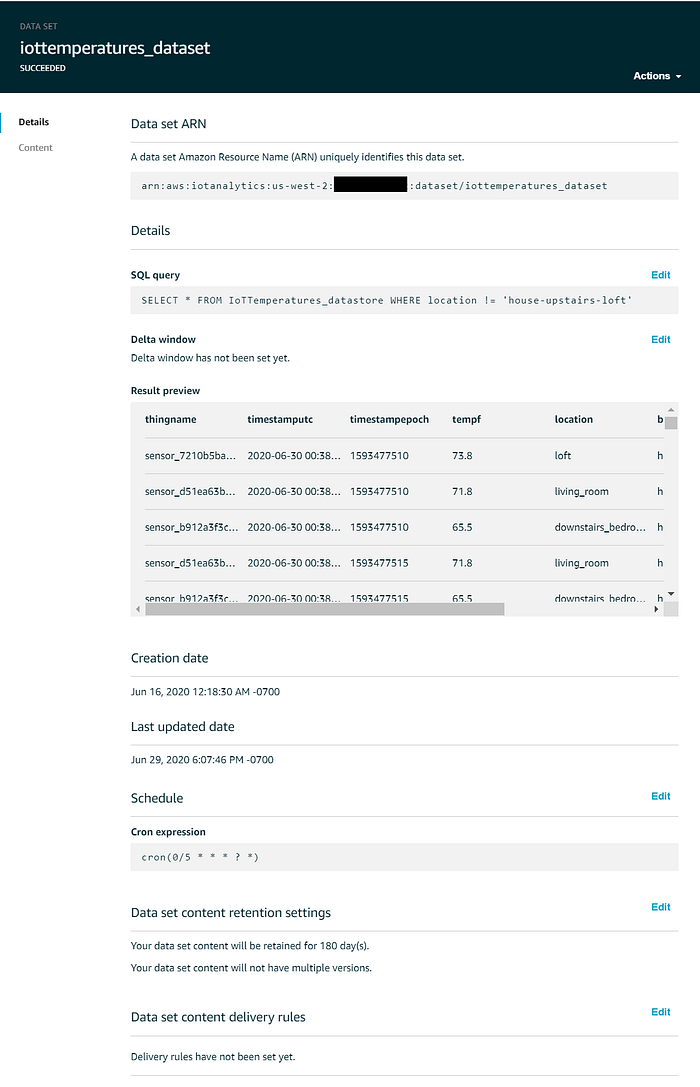
El dataset que se usará para Quicksight debería verse así:
Visualización de datos en streaming
Con nuestro dataset de temperatura listo, veamos las capacidades de visualización de AWS Quicksight. Ve al servicio Quicksight y elige el tipo de cuenta QuickSight "Standard edition" para mantener tu demo económico:

Más allá de los términos de marketing, SPICE no es más que el motor de cómputo en memoria de Quicksight, pensado para generar análisis y visualizaciones ad hoc con rapidez. Con los datos de apenas unos pocos dispositivos IoT domésticos, el tier gratuito de 1 GB de SPICE será más que suficiente para este recorrido.
Una vez que tu cuenta de QuickSight termine de crearse, llegarás a un dashboard que lista varios análisis de ejemplo que el servicio provee por defecto. Si haces clic en "Manage data" en la esquina superior derecha, también verás las fuentes de datos que alimentan esos análisis de ejemplo. Antes de crear un dashboard de análisis de temperatura IoT, debemos configurar nuestro dataset de IoT Analytics como fuente de datos. Haz clic en "New dataset" desde la pantalla "Manage data" y elige IoT Analytics de la lista de fuentes soportadas:
Se mostrará el data store de IoT Analytics que creamos. Selecciónalo y haz clic en "Create data source"; luego haz clic en "Visualize" cuando termine:
Esto te llevará a un AutoGraph vacío:

Como los datos de series temporales se representan bien con un Line chart, selecciona esa opción dentro de "Visual types". Esto transformará el espacio de trabajo y nos permitirá agregar una dimensión de eje X, valores y un color de agrupación:

Arrastra y suelta "timestamputc" al eje X, "tempf" a Value y "location" a Color. Una vez visualizados los datos, abre la flecha desplegable de tu eje Y y cambia el valor mostrado de Sum a Average:
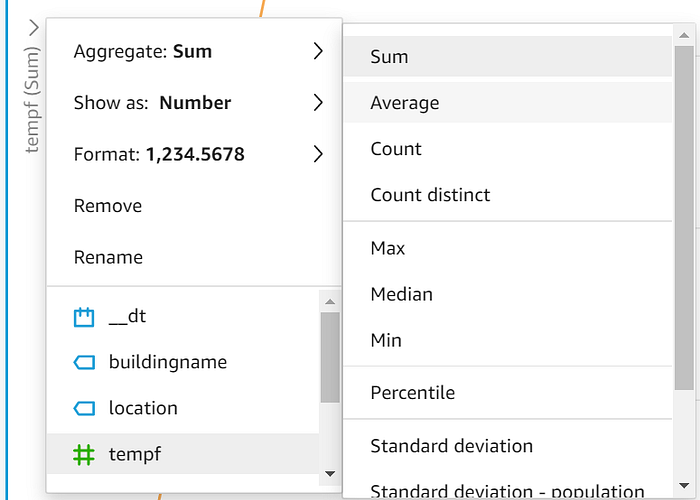
A continuación, cambia tu eje X para que agregue los valores promedio de temperatura por Hora en lugar de por Día:
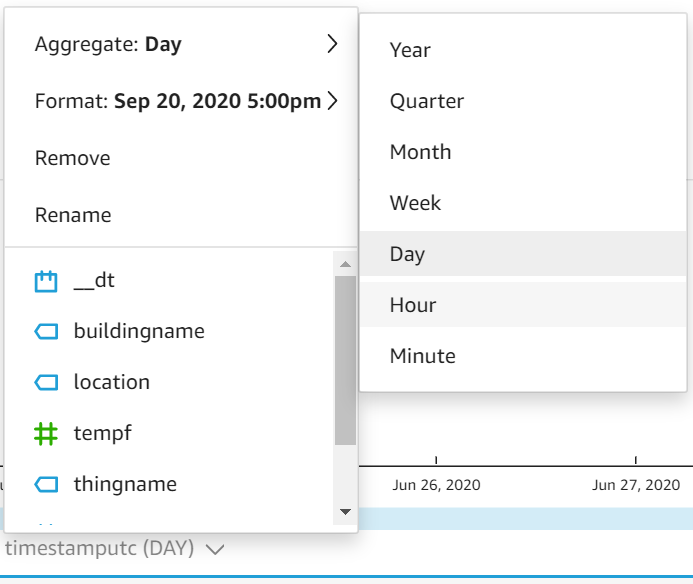
Para escalar mejor tus datos verticalmente, haz clic en el ícono de engranaje en la esquina superior derecha de tu figura para mostrar la lista de opciones de formato visual. Elige el eje Y y selecciona "Auto (based on data range)" en lugar de la opción por defecto "Auto (starting at 0)":

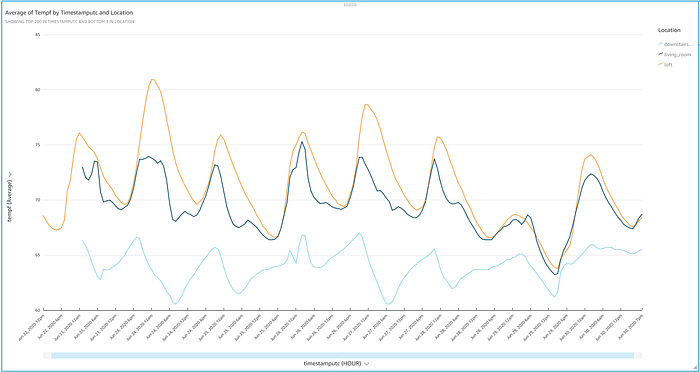
¡Y voilà! Ahora deberías ver una elegante figura con los valores de temperatura transmitidos vía IoT que suben y bajan a lo largo del día. Con solo echar un vistazo al gráfico podemos identificar varios detalles interesantes:
- Este proyecto confirmó mi sospecha de que la planta baja de mi casa es un páramo invernal a pesar de que el termostato del piso principal estuvo configurado en 72 grados constantes durante todo el experimento.
- El piso principal muestra una variabilidad grande, de más de 5 grados, mientras intenta mantener los 72 grados a pesar de tener ventanas de doble panel en toda la casa. ¿Será hora de conseguir un termostato inteligente y revisar el HVAC?
- Me sorprendió lo variable y mal climatizado que está el loft, sobre todo en días calurosos como el 24 de junio. El loft está en la misma habitación abierta que el termostato y directamente sobre él, y aun así, en días calurosos como el 24, el loft está unos 8 grados más caliente que el espacio que está 10 pies por debajo.
- Abrir las ventanas en días más frescos como el 25, 26 y 29 igualó las temperaturas del loft y la sala, aunque la planta baja siguió helada. ¡No hay sustituto para una brisa fresca recorriendo tu casa!
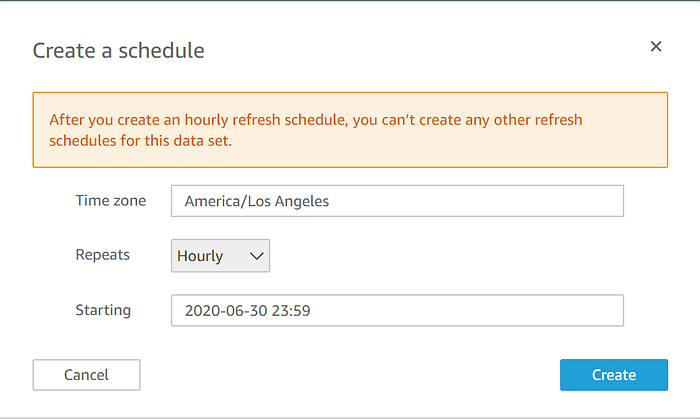
Para asegurarte de que tu visualización en QuickSight esté siempre alineada con tu dataset de IoT Analytics que se refresca con regularidad, vuelve al dataset fuente de Quicksight y configura un calendario de actualización:

Ahora tienes un dashboard de visualización actualizado con regularidad que puedes compartir con otras personas de tu empresa a través del dominio de Quicksight para datos IoT en streaming a escala de producción, todo sin tener que mantener manualmente la infraestructura de almacenamiento, transporte y visualización impactante de los datos.
¡Con esto concluye el recorrido por las buenas prácticas a escala de producción para streaming, almacenamiento y visualización de datos IoT! Espero que te hayas divertido identificando tendencias interesantes de temperatura en tu propia casa y que hayas aprendido un par de cosas sobre serverless en AWS por el camino. ¡Mucha suerte en tu camino con IoT!