Évoluer vers un système de messagerie plus scalable, fiable, fonctionnel et facile à maintenir prend tout son sens dans un environnement Kubernetes.
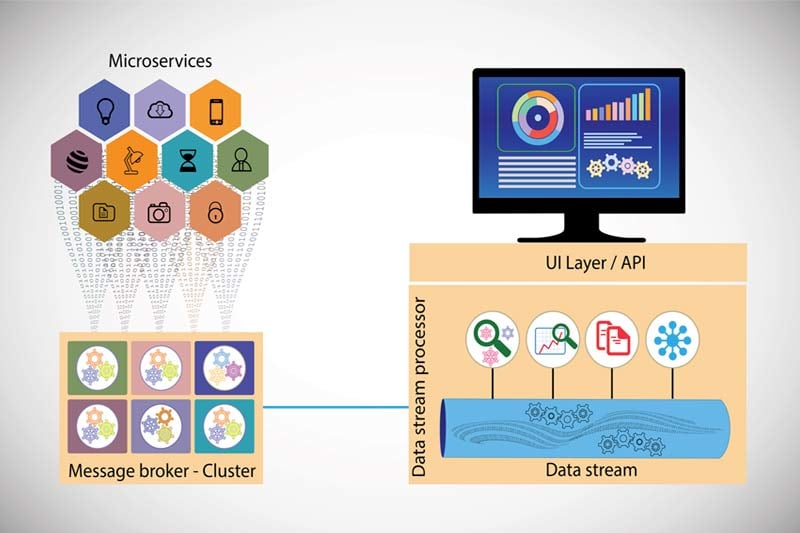
KubeMQ : une solution container-first pensée pour Kubernetes
Difficile de tirer un trait du jour au lendemain sur un système de messagerie aussi éprouvé que Kafka. Mais l'évolution vers une solution plus scalable, fiable, fonctionnelle et simple à maintenir devient incontournable, à mesure que les organisations adoptent une architecture conteneurisée fondée sur les microservices.
Selon les prévisions de Gartner, d'ici fin 2022, 75 % des organisations dans le monde s'appuieront sur Kubernetes et son approche conteneurisée pour gérer et faire évoluer leurs applications de production — un bond considérable face aux 30 % de 2019. Comme nous allons le voir, Kafka n'est pas conçu de manière optimale pour la conteneurisation. Une solution container-first a donc émergé pour le remplacer dans un univers piloté par Kubernetes.
L'innovation Kafka
Kafka a vu le jour pour répondre à un besoin précis de LinkedIn : disposer d'un système de collecte de données à faible latence pour les flux temps réel générés chaque jour par plus de 675 millions d'utilisateurs. Lors de son développement en 2010, l'infrastructure de données de LinkedIn était monolithique, on-premise et reposait sur Java. Kafka a hérité de ces caractéristiques : peu importe la plateforme sur laquelle votre application est bâtie, vous aurez besoin d'une Java Virtual Machine (JVM) dans votre infrastructure pour utiliser Kafka.
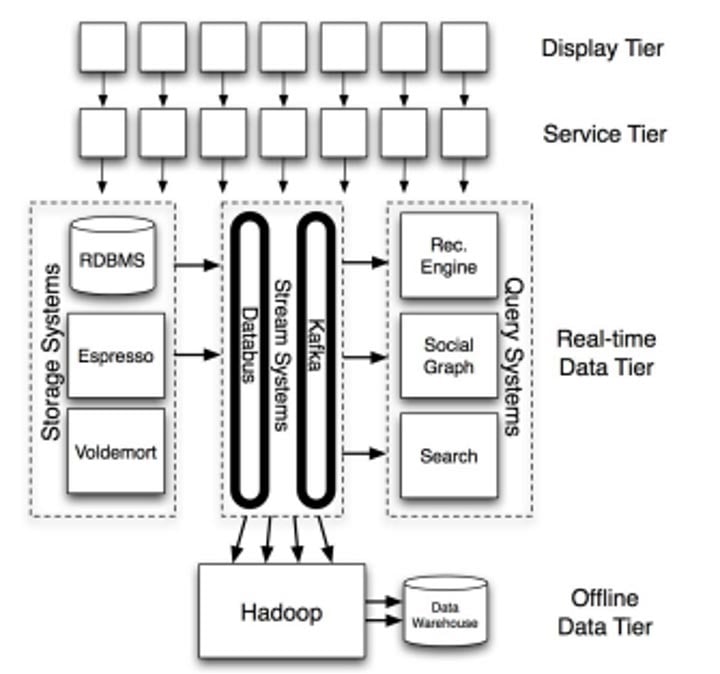
Vue d'ensemble de l'architecture de LinkedIn, centrée sur ses systèmes de données principaux.
Déploiement de Kafka sur Kubernetes
Si vous décidez de migrer vers Kubernetes en optant pour Kafka comme système de messagerie, voici les prérequis :
- L'orchestrateur Zookeeper, qui gère les brokers Kafka et les topics, est indispensable pour créer un cluster K8s avec Kafka. Un seul conteneur pèse 600 Mo pour Kafka et 100 Mo pour Zookeeper.
- Les performances de Kafka dépendent d'un réseau à faible latence et d'une bande passante élevée. Évitez de placer tous les brokers Kafka sur un même nœud, sous peine de réduire la disponibilité. Répartir les brokers sur différentes zones de disponibilité constitue un compromis acceptable.
- Si le stockage du conteneur n'est pas persistant, les données seront perdues au redémarrage. EmptyDir est utilisé pour les données Kafka et persiste lors d'un redémarrage du conteneur. Au démarrage, le broker défaillant doit d'abord répliquer toutes les données, un processus chronophage. C'est pourquoi il faut utiliser un volume de persistance, et le stockage doit être non local pour que Kubernetes dispose de plus de souplesse pour choisir un autre nœud après redémarrage ou relocalisation.
- Kafka a été conçu en Java et Scala : votre équipe doit donc compter une personne possédant une solide expérience dans ces deux langages pour assurer un tuning et un débogage corrects.
- Enfin, il vous faudra un outil de monitoring tiers pour suivre les performances de Kafka.
L'innovation KubeMQ
KubeMQ a été conçu nativement pour Kubernetes. Il est livré par défaut sous forme de cluster préconfiguré. Ses atouts majeurs : son fonctionnement stateless et la simplicité de déploiement et de configuration pour tout membre d'une équipe DevOps maîtrisant Kubernetes.
Inutile de mobiliser des compétences pointues en Java ou Scala. KubeMQ prend en charge tous les modèles de messagerie — synchrone comme asynchrone — alors que Kafka se limite aux modèles asynchrones.
Le conteneur KubeMQ est ultra-léger : 30 Mo seulement, ce qui en fait un excellent candidat pour s'intégrer à des microservices. Pensé pour Kubernetes, KubeMQ s'adapte avec souplesse à tous types d'environnements : multi-cloud, hybride ou mono-cloud. Voici quelques-uns de ses principaux atouts :
- Déployé avec un Operator pour une gestion complète du cycle de vie
- Conteneur Docker ultra-rapide (écrit en Go), compact et léger
- Messagerie asynchrone et synchrone avec prise en charge des modèles At Most Once Delivery et At Least Once Delivery
- Prise en charge des modèles de messagerie : Queue durable basée FIFO, Publish-Subscribe Events, Publish-Subscribe avec persistance (Events Store), RPC Command et Query
- Protocoles de transport gRPC, REST et WebSocket avec support TLS (modes RPC et Stream)
- Authentification et autorisation par contrôle d'accès
- Découpage de messages et routage intelligent
- Aucune configuration de message broker requise (queues, exchanges, etc.)
- SDK disponibles pour .Net, Java, Python, Go et NodeJS
Déploiement de KubeMQ sur Kubernetes
Voici les étapes pour déployer KubeMQ dans un cluster Kubernetes :
kubectl apply -f https://deploy.kubemq.io/community
Et voilà, c'est terminé. Pour une documentation complète sur KubeMQ, rendez-vous sur la page de documentation. Le dépôt git de KubeMQ est disponible ici. Aucune exigence réseau particulière, aucune surcharge mémoire liée à de gros conteneurs exécutant la JVM : toute personne disposant de bases en DevOps peut le déployer. Des conteneurs Docker compacts et légers, combinés à un logiciel écrit en Go, lui confèrent une rapidité d'exécution remarquable.
KubeMQ semble idéal. Mais j'utilise déjà un cluster Kafka. Que faire ?
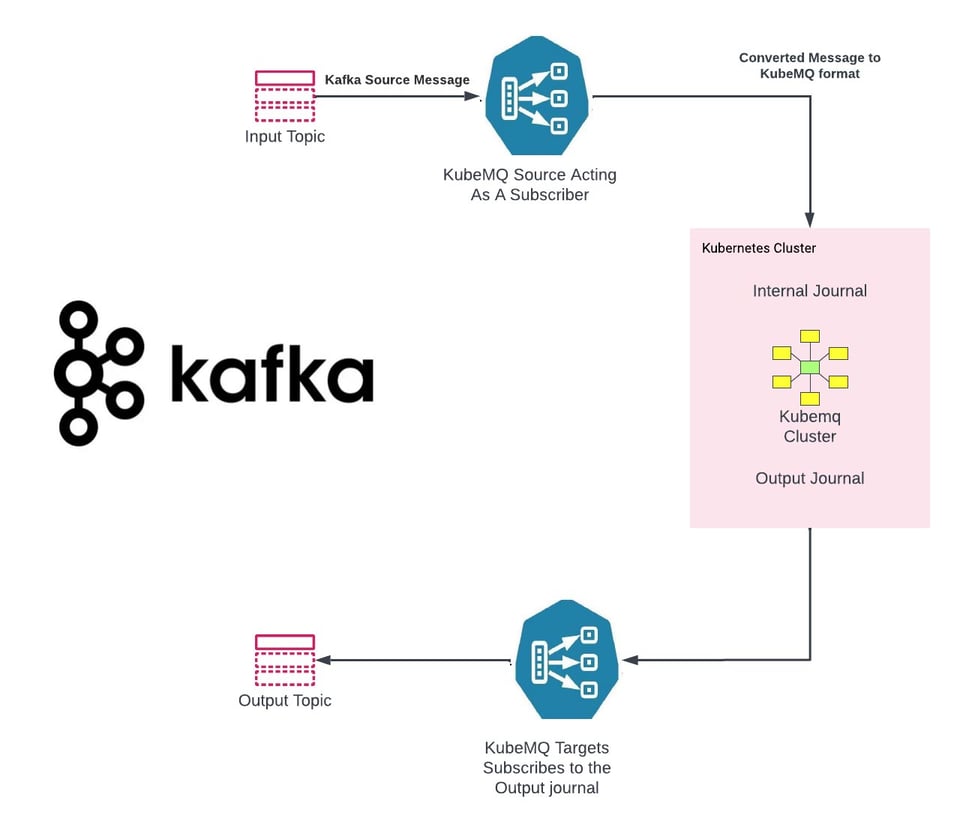
KubeMQ a développé des connecteurs universels qui simplifient la migration des systèmes existants vers KubeMQ :
KubeMQ Source - https://github.com/kubemq-io/kubemq-sources
KubeMQ Targets - https://github.com/kubemq-io/kubemq-targets
Exemple de KubeMQ Source pour Kafka - https://github.com/kubemq-io/kubemq-sources/blob/master/examples/messaging/kafka/main.go
Exemple de KubeMQ Target pour Kafka - https://github.com/kubemq-io/kubemq-targets/blob/master/examples/messaging/kafka/main.go
En résumé
Au moment de choisir entre un système de messagerie stateless ou stateful pour votre stack, mieux vaut privilégier le stateless : moins de dépendances, des temps de traitement plus rapides et une reprise sur incident bien moins complexe. Lors de tests de performance face à Kafka, KubeMQ a affiché une vitesse de traitement des messages supérieure de 20 %. Le plus grand atout de KubeMQ : la prise en charge du Pub/Sub avec ou sans persistance, du Request/Reply (sync et async), de la livraison at least once, des modèles de streaming et du RPC. Fini la contrainte des seuls modèles asynchrones imposée par Kafka.
Si vous avez besoin d'aide sur ce sujet ou sur tout autre aspect de votre infrastructure cloud, contactez DoiT International. Récemment distingué Google Cloud Sales Partner of the Year 2021, nous proposons une expertise de conseil associée à un support illimité de classe mondiale, pour des clients de toutes tailles sur Google Workspace et Google Cloud Platform.