Evolucionar hacia un sistema de mensajería más escalable, confiable, funcional y fácil de mantener tiene todo el sentido en un mundo Kubernetes.
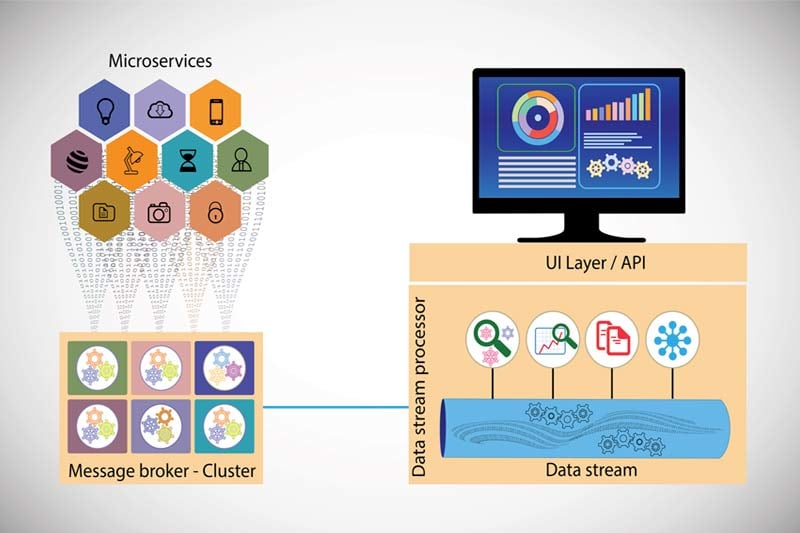
KubeMQ: una solución container-first pensada para Kubernetes
No se trata de descartar sin más un sistema de mensajería tan probado como Kafka, pero la transición hacia uno más escalable, confiable, funcional y fácil de mantener ya es inevitable, sobre todo ahora que tantas organizaciones están adoptando arquitecturas basadas en microservicios y contenedores.
Gartner anticipa que, para finales de 2022, el 75% de las organizaciones a nivel global usarán Kubernetes y su enfoque basado en contenedores para gestionar y escalar aplicaciones en producción: un salto enorme frente al 30% de 2019. Como veremos, Kafka no fue diseñado de forma óptima para correr en contenedores, así que ha surgido una alternativa container-first para reemplazarlo en un mundo dominado por Kubernetes.
La innovación de Kafka:
Kafka nació para resolver una necesidad concreta de LinkedIn: un sistema de recolección de baja latencia capaz de manejar los datos en tiempo real que generan a diario más de 675 millones de usuarios. Cuando Kafka estaba en desarrollo, en 2010, la infraestructura de datos de LinkedIn era monolítica, on-prem y basada en Java. Kafka heredó esas características, así que sin importar la plataforma sobre la que esté construida tu aplicación, vas a necesitar una Java Virtual Machine (JVM) corriendo en tu infraestructura si planeas usarlo.
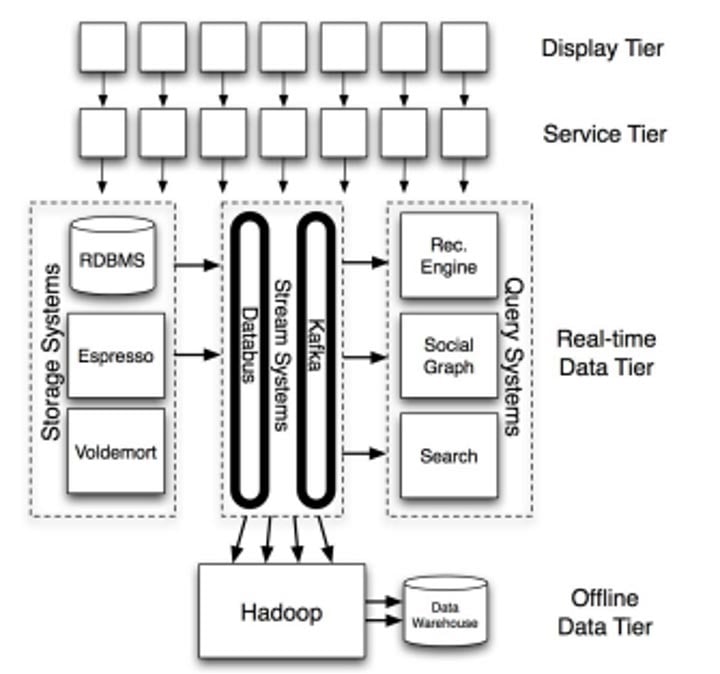
Una vista general de la arquitectura de LinkedIn, con foco en sus sistemas de datos centrales.
Despliegue de Kafka en Kubernetes:
Si decides migrar a Kubernetes y eliges Kafka como sistema de mensajería, estos son los requisitos:
- El orquestador Zookeeper para gestionar los brokers y topics de Kafka es indispensable al crear un cluster de K8s con Kafka, así que un solo contenedor pesa 600 MB para Kafka y 100 MB para Zookeeper.
- El rendimiento de Kafka depende de una red de baja latencia y alto ancho de banda. En cuanto a los brokers, no intentes colocarlos todos en un mismo nodo, porque eso reduce la disponibilidad. Distribuirlos en distintas zonas de disponibilidad es un compromiso aceptable.
- Si el almacenamiento del contenedor no es persistente, los datos se pierden tras el reinicio. EmptyDir se usa para los datos de Kafka y se conserva si el contenedor se reinicia. Aun así, al arrancar de nuevo, el broker caído debe replicar primero todos los datos, un proceso que toma bastante tiempo. Por eso conviene usar un volumen persistente, y el almacenamiento debe ser no local para que Kubernetes tenga más flexibilidad al elegir otro nodo después de un reinicio o reubicación.
- Kafka se desarrolló en Java y Scala, así que tu equipo necesita contar con alguien con experiencia sólida en ambos lenguajes para hacer el tuning y el debugging adecuados.
- Por último, vas a necesitar una herramienta de monitoreo de terceros para hacerle seguimiento al rendimiento de Kafka.
La innovación de KubeMQ:
KubeMQ se construyó pensando en Kubernetes desde el primer día. Se entrega por defecto en un cluster preconfigurado. Sus mayores fortalezas son su naturaleza stateless y la facilidad con la que cualquier integrante de un equipo de DevOps con experiencia en Kubernetes puede desplegarlo y configurarlo.
No hace falta tener un perfil especializado en Java o Scala. KubeMQ admite todos los patrones de mensajería —síncronos y asíncronos—, mientras que Kafka solo soporta patrones asíncronos.
El contenedor de KubeMQ es súper liviano: apenas 30 MB, lo que lo convierte en un excelente candidato para integrarse en microservicios. Al estar diseñado pensando en Kubernetes, KubeMQ es muy flexible con todo tipo de entornos: multi-cloud, híbridos o de una sola nube. Estas son algunas de sus principales ventajas:
- Se despliega con Operator para gestionar el ciclo de vida completo
- Velocidad altísima (escrito en Go), con un contenedor Docker pequeño y liviano
- Mensajería asíncrona y síncrona con soporte para los modelos At Most Once Delivery y At Least Once Delivery
- Admite Queue duradera basada en FIFO, Publish-Subscribe Events, Publish-Subscribe with Persistence (Events Store), RPC Command y patrones de mensajería Query
- Admite los protocolos de transporte gRPC, Rest y WebSocket con soporte TLS (en modo RPC y Stream)
- Admite control de acceso, autorización y autenticación
- Admite procesamiento de mensajes y enrutamiento inteligente
- No requiere configuración del message broker (queues, exchanges, etc.)
- SDK disponibles para .Net, Java, Python, Go y NodeJS
Despliegue de KubeMQ en Kubernetes:
Estos son los pasos para desplegar KubeMQ en un cluster de Kubernetes:
kubectl apply -f https://deploy.kubemq.io/community
Eso es todo, listo. Si quieres profundizar en la documentación de KubeMQ, puedes consultar la página de docs. El repo de git de KubeMQ está aquí. No hay requisitos especiales de red, no hay sobrecarga de memoria por contenedores grandes corriendo JVM, y cualquier persona con conocimientos básicos de DevOps puede desplegarlo. El uso de contenedores Docker pequeños y livianos, junto con software escrito en Go, lo hace increíblemente rápido.
Wow, KubeMQ se ve genial. Pero ya tengo un Cluster de Kafka funcionando. ¿Qué hago?
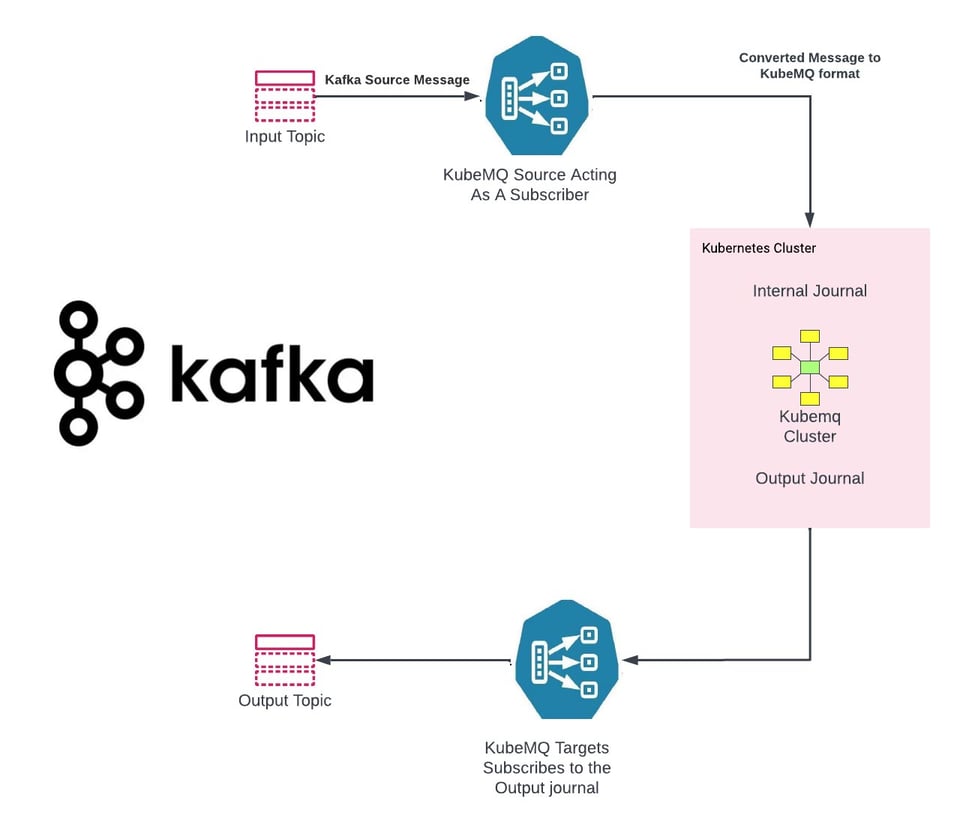
KubeMQ desarrolló conectores universales que facilitan la migración de sistemas heredados a KubeMQ:
KubeMQ Source - https://github.com/kubemq-io/kubemq-sources
KubeMQ Targets - https://github.com/kubemq-io/kubemq-targets
Ejemplo de KubeMQ Source para Kafka - https://github.com/kubemq-io/kubemq-sources/blob/master/examples/messaging/kafka/main.go
Ejemplo de KubeMQ Target para Kafka - https://github.com/kubemq-io/kubemq-targets/blob/master/examples/messaging/kafka/main.go
Para cerrar
A la hora de elegir entre sistemas de mensajería stateless o stateful para integrarlos a tu stack, siempre conviene apostar por los stateless: implican menos dependencias, tiempos de procesamiento más rápidos y una recuperación menos compleja ante caídas del sistema de mensajería. En pruebas de rendimiento frente a Kafka, KubeMQ logró un procesamiento de mensajes un 20% más rápido. Su mayor ventaja es que admite Pub/Sub con o sin persistencia, Request/Reply (sync, async), at least once delivery, patrones de streaming y RPC. No te quedas atado únicamente a patrones async, como ocurre con Kafka.
Si necesitas ayuda con esto o con cualquier otro aspecto de tu infraestructura en la nube, conversa con DoiT International. Recientemente reconocidos como 2021 Google Cloud Sales Partner of the Year, ofrecemos consultoría experta junto con soporte ilimitado de clase mundial a clientes de todos los tamaños en Google Workspace y Google Cloud Platform.