Der Schritt zu einem skalierbareren, zuverlässigeren, funktionsreicheren und wartungsärmeren Messaging-System ist in einer Kubernetes-Welt nur konsequent.
KubeMQ: die Container-First-Lösung für die Kubernetes-Welt
Ein bewährtes, in der Praxis erprobtes Messaging-System wie Kafka lässt sich nicht einfach abschreiben. Trotzdem führt kein Weg am Übergang zu einem skalierbareren, zuverlässigeren, funktionsreicheren und wartungsärmeren Messaging-System vorbei – schließlich setzen immer mehr Unternehmen auf microservice-basierte, containerisierte Architekturen.
Gartner prognostiziert, dass bis Ende 2022 75 % der Unternehmen weltweit Kubernetes und dessen containerisierten Ansatz nutzen werden, um Produktionsanwendungen zu betreiben und zu skalieren – ein gewaltiger Sprung gegenüber lediglich 30 % im Jahr 2019. Wie wir zeigen werden, ist Kafka für Containerisierung nicht optimal ausgelegt. Genau deshalb hat sich eine Container-First-Lösung etabliert, die Kafka in einer Kubernetes-getriebenen Welt ablöst.
Die Innovation hinter Kafka:
Kafka entstand, um den Bedarf von LinkedIn an einem Datenerfassungssystem mit niedriger Latenz für die Echtzeitdaten von täglich über 675 Millionen Nutzern zu decken. Während der Entwicklung 2010 war LinkedIns Dateninfrastruktur monolithisch, on-prem und Java-basiert. Diese Eigenschaften hat Kafka beibehalten – egal auf welcher Plattform Ihre Anwendung läuft: Wenn Sie Kafka einsetzen wollen, brauchen Sie eine Java Virtual Machine (JVM) in Ihrer Infrastruktur.
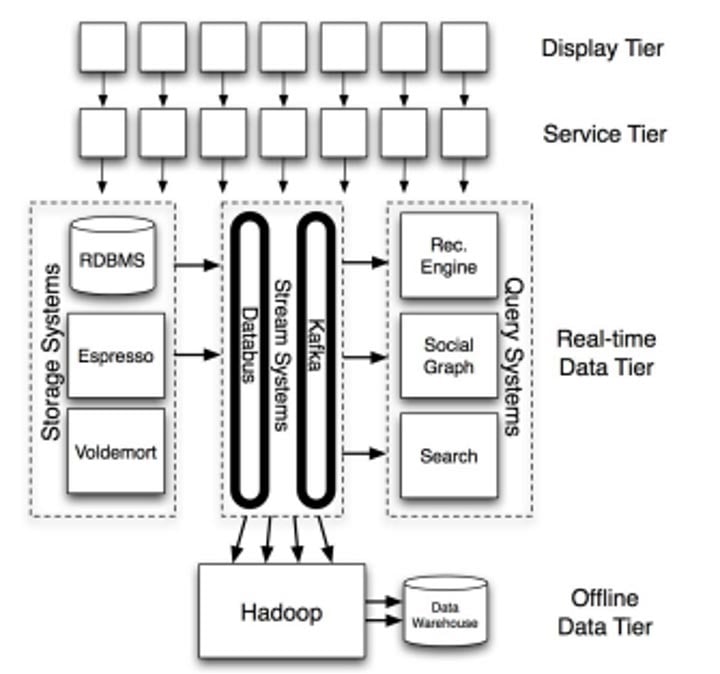
Ein stark vereinfachter Überblick über die Architektur von LinkedIn mit Fokus auf die zentralen Datensysteme.
Kafka- und Kubernetes-Deployment:
Wenn Sie zu Kubernetes migrieren und Kafka als Messaging-System wählen, sollten Sie folgende Anforderungen kennen:
- Ein Zookeeper-Orchestrator zur Verwaltung von Kafka-Brokern und Topics ist beim Aufbau eines K8s-Clusters mit Kafka unverzichtbar – ein einzelner Container bringt 600 MB für Kafka und 100 MB für Zookeeper auf die Waage.
- Die Performance von Kafka steht und fällt mit einem Netzwerk mit niedriger Latenz und hoher Bandbreite. Packen Sie nicht alle Kafka-Broker auf einen einzigen Node – das würde die Verfügbarkeit verringern. Verschiedene Availability Zones sind ein akzeptabler Kompromiss.
- Ist der Speicher im Container nicht persistent, gehen Daten nach einem Neustart verloren. EmptyDir wird für Kafka-Daten genutzt und übersteht Container-Neustarts. Beim Hochfahren muss der ausgefallene Broker dann allerdings erst sämtliche Daten replizieren – ein zeitaufwendiger Prozess. Verwenden Sie deshalb ein Persistent Volume, und der Speicher sollte nicht-lokal sein, damit Kubernetes nach Neustart oder Verschiebung flexibler einen anderen Node wählen kann.
- Kafka wurde in Java und Scala entwickelt. Ihr Team braucht daher fundierte Erfahrung in beiden Sprachen, um sauber tunen und debuggen zu können.
- Schließlich benötigen Sie ein Drittanbieter-Tool, um die Kafka-Performance zu überwachen.
Die Innovation hinter KubeMQ:
KubeMQ wurde von Anfang an für Kubernetes konzipiert. Standardmäßig kommt es als vorkonfigurierter Cluster. Seine größten Stärken: Zustandslosigkeit sowie ein einfaches Deployment und eine einfache Konfiguration durch jedes DevOps-Teammitglied mit Kubernetes-Erfahrung.
Spezielle Java- oder Scala-Kenntnisse sind nicht nötig. KubeMQ unterstützt alle Messaging-Pattern – synchron wie asynchron –, während Kafka ausschließlich asynchrone Pattern abdeckt.
Mit nur 30 MB ist der KubeMQ-Container extrem schlank und damit ein hervorragender Kandidat für die Integration in Microservices. Da KubeMQ konsequent für Kubernetes entwickelt wurde, ist es in jeder Art von Umgebung flexibel einsetzbar – ob Multi-Cloud, Hybrid oder Single Cloud. Die wichtigsten Vorteile im Überblick:
- Deployment via Operator für den kompletten Lifecycle-Betrieb
- Extrem schneller, kleiner und schlanker Docker-Container (in Go geschrieben)
- Asynchrones und synchrones Messaging mit Unterstützung für At-Most-Once- und At-Least-Once-Delivery-Modelle
- Unterstützung für persistente FIFO-basierte Queues, Publish-Subscribe-Events, Publish-Subscribe mit Persistenz (Events Store) sowie RPC-Command- und Query-Messaging-Pattern
- Unterstützung für gRPC-, REST- und WebSocket-Transportprotokolle mit TLS (sowohl im RPC- als auch im Stream-Modus)
- Unterstützung für Access-Control-Autorisierung und -Authentifizierung
- Unterstützung für Message-Verarbeitung und Smart Routing
- Keine Konfiguration des Message Brokers nötig (z. B. Queues, Exchanges)
- SDK-Support für .NET, Java, Python, Go und NodeJS
KubeMQ- und Kubernetes-Deployment:
So deployen Sie KubeMQ in einem Kubernetes-Cluster:
kubectl apply -f https://deploy.kubemq.io/community
Das war’s. Die ausführliche Dokumentation zu KubeMQ finden Sie auf der Docs-Seite, das KubeMQ-Git-Repo gibt es hier. Keine speziellen Netzwerkanforderungen, kein Speicher-Overhead durch große JVM-Container – jeder mit grundlegendem DevOps-Wissen kann KubeMQ ausrollen. Die kleinen, schlanken Docker-Container in Kombination mit der in Go geschriebenen Software sorgen für extrem hohe Geschwindigkeit.
Klingt großartig. Aber ich betreibe bereits einen Kafka-Cluster. Was tun?
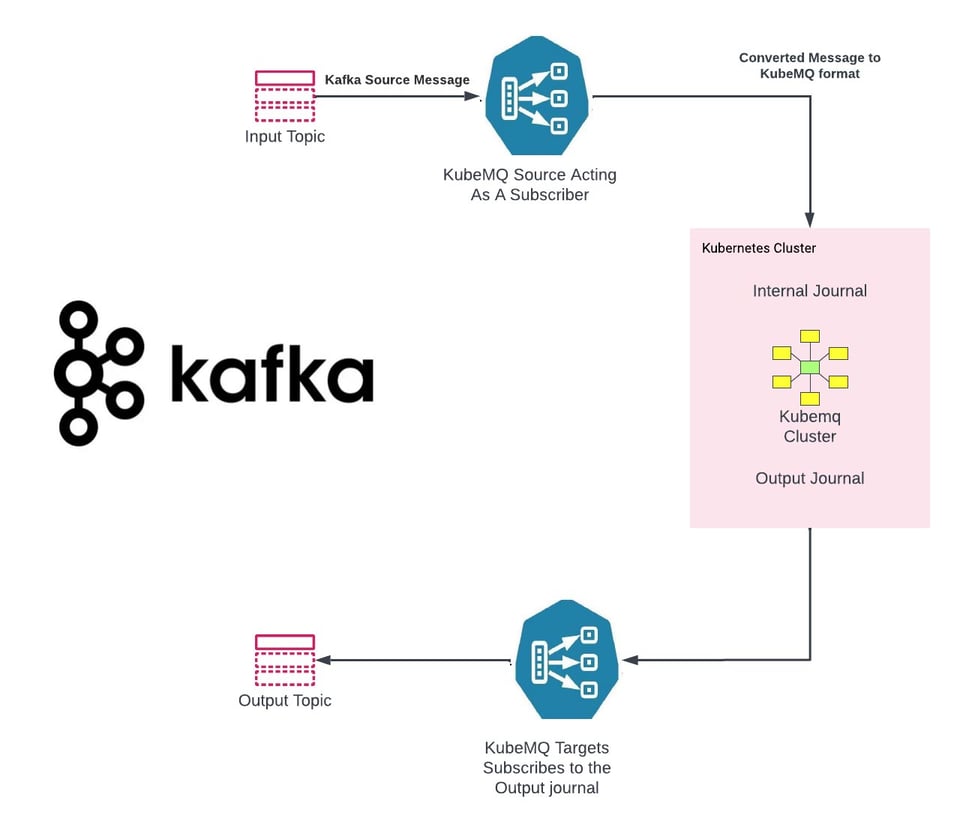
KubeMQ stellt universelle Konnektoren bereit, mit denen sich Legacy-Systeme problemlos zu KubeMQ migrieren lassen:
KubeMQ Source – https://github.com/kubemq-io/kubemq-sources
KubeMQ Targets – https://github.com/kubemq-io/kubemq-targets
Beispiel für KubeMQ Source für Kafka – https://github.com/kubemq-io/kubemq-sources/blob/master/examples/messaging/kafka/main.go
Beispiel für KubeMQ Target für Kafka – https://github.com/kubemq-io/kubemq-targets/blob/master/examples/messaging/kafka/main.go
Fazit
Wer für seinen Stack zwischen zustandslosen und zustandsbehafteten Messaging-Systemen wählt, ist mit zustandslosen Systemen grundsätzlich besser beraten: weniger Abhängigkeiten, schnellere Verarbeitung und ein einfacheres Recovery nach Abstürzen. Im Performance-Vergleich mit Kafka erreichte KubeMQ eine um 20 % schnellere Nachrichtenverarbeitung. Der größte Vorteil von KubeMQ: Es unterstützt Pub/Sub mit und ohne Persistenz, Request/Reply (sync, async), At-Least-Once-Delivery, Streaming-Pattern und RPC. Sie sind also nicht – wie bei Kafka – auf asynchrone Pattern festgelegt.
Wenn Sie hierbei oder bei anderen Themen rund um Ihre Cloud-Infrastruktur Unterstützung brauchen, sprechen Sie mit DoiT International. Erst kürzlich als Google Cloud Sales Partner of the Year 2021 ausgezeichnet, bieten wir fundierte Beratung gepaart mit unbegrenztem, erstklassigem Support für Kunden jeder Größe – über Google Workspace und die Google Cloud Platform hinweg.