In un mondo Kubernetes è logico evolvere verso un sistema di messaggistica più scalabile, affidabile, ricco di funzionalità e semplice da gestire.
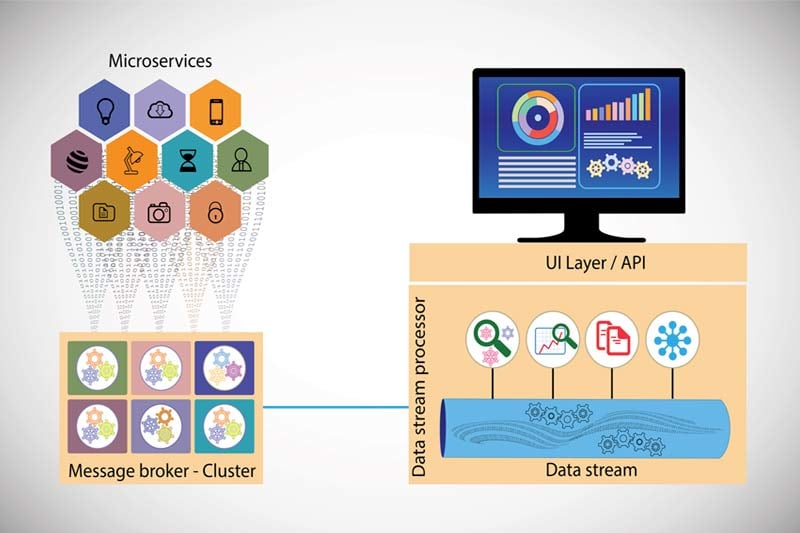
KubeMQ: una soluzione container-first per il mondo Kubernetes
Non si può liquidare con leggerezza un sistema di messaggistica solido e collaudato come Kafka, ma l'evoluzione verso una piattaforma più scalabile, affidabile, ricca di funzionalità e semplice da gestire è ormai necessaria, dal momento che molte organizzazioni stanno adottando architetture a microservizi basate su container.
Secondo le previsioni di Gartner, entro la fine del 2022 il 75% delle organizzazioni a livello globale utilizzerà Kubernetes e il suo approccio basato sui container per gestire e scalare le applicazioni in produzione: un balzo notevole rispetto al solo 30% del 2019. Come vedremo, Kafka non è progettato in modo ottimale per la containerizzazione e per questo è nata una soluzione container-first che lo sostituisce in un ecosistema governato da Kubernetes.
L'innovazione di Kafka
Kafka è nato per rispondere all'esigenza di LinkedIn: disporre di un sistema di raccolta dati a bassa latenza per i flussi in tempo reale generati ogni giorno da oltre 675 milioni di utenti. Quando Kafka era in fase di sviluppo, nel 2010, l'infrastruttura dati di LinkedIn era monolitica, on-prem e basata su Java. Kafka ha conservato quelle caratteristiche: indipendentemente dalla piattaforma su cui è costruita la Sua applicazione, per usare Kafka dovrà avere una Java Virtual Machine (JVM) in esecuzione nella Sua infrastruttura.
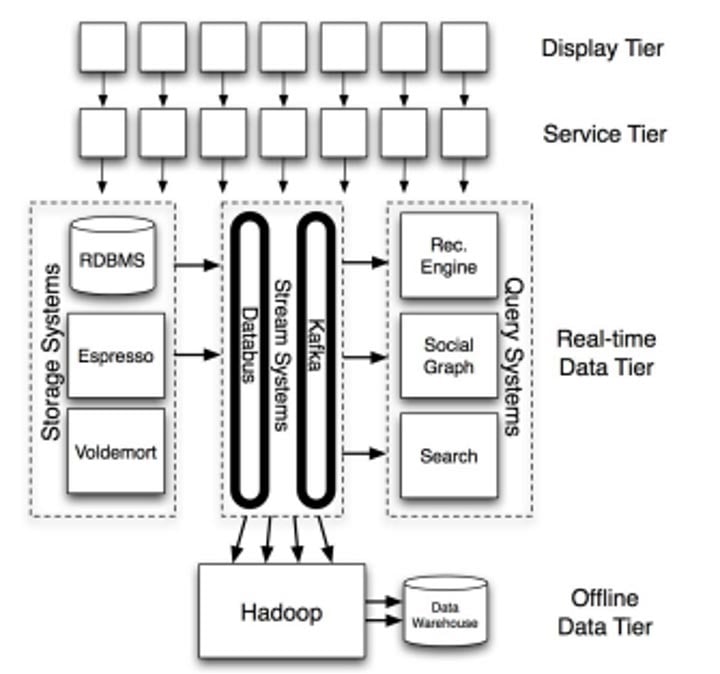
Una panoramica ad altissimo livello dell'architettura di LinkedIn, con focus sui sistemi dati principali.
Kafka e il deployment su Kubernetes
Se decide di migrare a Kubernetes scegliendo Kafka come sistema di messaggistica, questi sono i requisiti:
- L'orchestratore Zookeeper, per gestire i broker e i topic di Kafka, è imprescindibile quando si crea un cluster K8 con Kafka: un singolo container occupa 600 MB per Kafka e 100 MB per Zookeeper.
- Le prestazioni di Kafka dipendono da una rete a bassa latenza e da un'elevata larghezza di banda. Quanto ai broker Kafka, eviti di collocarli tutti su un unico nodo: comprometterebbe la disponibilità. Distribuirli su availability zone diverse è un compromesso accettabile.
- Se lo storage del container non è persistente, i dati vanno persi al riavvio. EmptyDir viene utilizzato per i dati di Kafka e mantiene i contenuti in caso di riavvio del container. All'avvio, però, il broker che era in errore deve replicare prima tutti i dati, un'operazione che richiede tempo. Per questo è opportuno usare un persistence volume e uno storage non locale, così che Kubernetes abbia maggiore flessibilità nella scelta di un altro nodo dopo un riavvio o uno spostamento.
- Kafka è stato sviluppato in Java e Scala: il Suo team dovrà quindi includere una risorsa con solida esperienza in entrambi i linguaggi per gestire correttamente tuning e debugging.
- Infine, servirà uno strumento di monitoraggio di terze parti per tracciare le prestazioni di Kafka.
L'innovazione di KubeMQ
KubeMQ è stato pensato fin dall'inizio per Kubernetes. Viene fornito di default in un cluster preconfigurato. I suoi punti di forza più rilevanti sono la natura stateless e la facilità di deployment e configurazione per qualsiasi membro del team DevOps con esperienza in Kubernetes.
Non servono competenze specialistiche in Java o Scala. KubeMQ supporta tutti i pattern di messaggistica – sia sincroni sia asincroni – mentre Kafka gestisce esclusivamente quelli asincroni.
Il container di KubeMQ è estremamente leggero, appena 30 MB: questo lo rende un candidato ideale per l'integrazione nei microservizi. Pensato per Kubernetes, KubeMQ si adatta con grande flessibilità a tutti i tipi di ambienti: multi-cloud, ibrido o single cloud. Di seguito alcuni dei suoi vantaggi principali.
- Deployment tramite Operator per la gestione completa del ciclo di vita
- Container Docker piccolo, leggero e velocissimo (scritto in Go)
- Messaggistica asincrona e sincrona con supporto per i modelli At Most Once Delivery e At Least Once Delivery
- Supporto per Queue durevoli basate su FIFO, Publish-Subscribe Events, Publish-Subscribe con persistenza (Events Store), pattern di messaggistica RPC Command e Query
- Supporto per i protocolli di trasporto gRPC, Rest e WebSocket con TLS (in modalità RPC e Stream)
- Supporto per autenticazione e autorizzazione tramite controllo degli accessi
- Supporto per message masticating e smart routing
- Nessuna configurazione di message broker richiesta (queue, exchange, ecc.)
- SDK disponibili per .Net, Java, Python, Go e NodeJS
KubeMQ e il deployment su Kubernetes
Questi sono i passaggi per il deployment di KubeMQ in un cluster Kubernetes:
kubectl apply -f https://deploy.kubemq.io/community
Tutto qui. Per una documentazione approfondita su KubeMQ può consultare la pagina dei docs. Il repository git di KubeMQ è disponibile qui. Non ci sono requisiti di rete particolari né overhead di memoria dovuto a container di grandi dimensioni che eseguono la JVM, e chiunque abbia conoscenze DevOps di base può occuparsi del deployment. L'uso di container Docker piccoli e leggeri, abbinato a un software scritto in Go, garantisce prestazioni elevatissime.
KubeMQ è fantastico. Ma sto già usando un cluster Kafka. Come procedo?
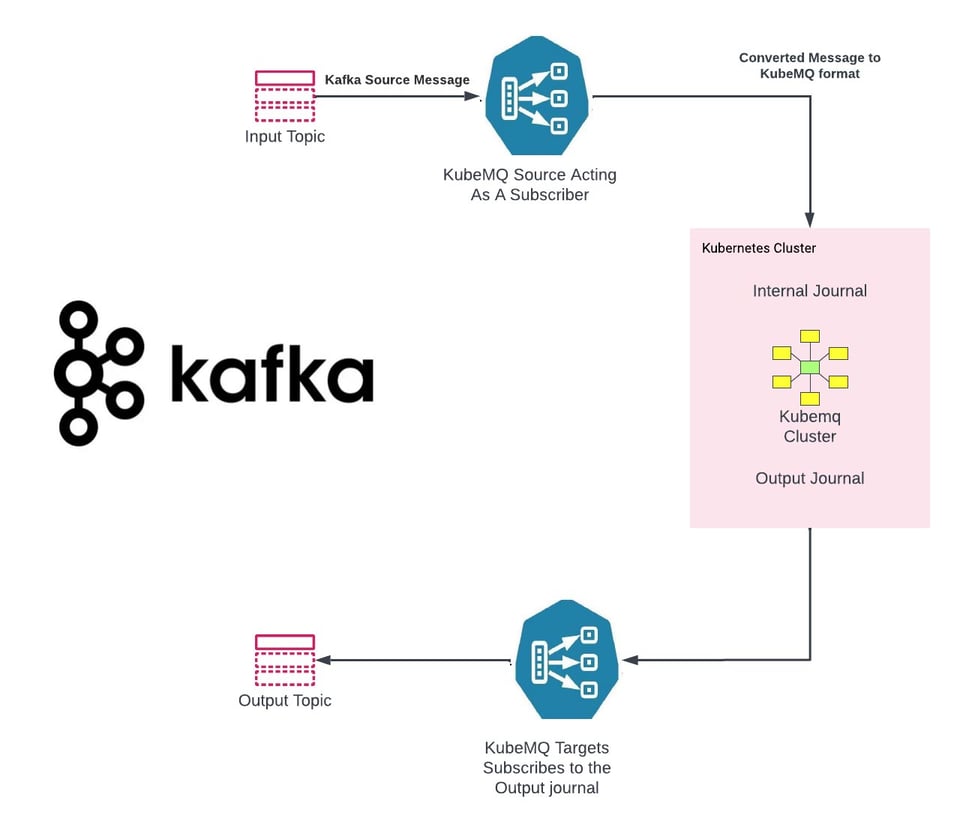
KubeMQ ha sviluppato connettori universali che semplificano la migrazione dei sistemi legacy verso KubeMQ:
KubeMQ Source - https://github.com/kubemq-io/kubemq-sources
KubeMQ Targets - https://github.com/kubemq-io/kubemq-targets
Esempio di KubeMQ Source per Kafka - https://github.com/kubemq-io/kubemq-sources/blob/master/examples/messaging/kafka/main.go
Esempio di KubeMQ Target per Kafka - https://github.com/kubemq-io/kubemq-targets/blob/master/examples/messaging/kafka/main.go
In sintesi
Dovendo scegliere tra sistemi di messaggistica stateless e stateful da integrare nel proprio stack, conviene sempre orientarsi verso quelli stateless: meno dipendenze, tempi di elaborazione più rapidi e un recupero meno complesso in caso di crash. Nei test di performance rispetto a Kafka, KubeMQ ha fatto registrare una velocità di elaborazione dei messaggi superiore del 20%. Il suo vantaggio più rilevante è il supporto a Pub/Sub con o senza persistenza, Request/Reply (sync, async), at least once delivery, pattern di streaming e RPC. Non si è vincolati ai soli pattern asincroni come accade con Kafka.
Se desidera assistenza su questo o su qualsiasi altro aspetto della Sua infrastruttura cloud, si rivolga a DoiT International. Recentemente premiati come 2021 Google Cloud Sales Partner of the Year, offriamo consulenza specialistica abbinata a un supporto illimitato e di livello mondiale a clienti di ogni dimensione su Google Workspace e Google Cloud Platform.