A evolução para um sistema de mensageria mais escalável, confiável, funcional e fácil de manter faz todo sentido em um mundo Kubernetes.
KubeMQ: uma solução container-first para um mundo Kubernetes
Não dá para simplesmente aposentar um sistema de mensageria consagrado e testado em batalha como o Kafka, mas a evolução para um sistema mais escalável, confiável, funcional e fácil de manter precisa começar, já que muitas organizações estão adotando o modelo de arquitetura baseado em microsserviços e containers.
O Gartner prevê que, até o final de 2022, 75% das organizações globais estarão usando Kubernetes e sua abordagem baseada em containers para gerenciar e escalar aplicações em produção — um salto e tanto em relação aos meros 30% de 2019. Como vamos mostrar, o Kafka não foi projetado de forma ideal para containerização, e por isso surgiu uma solução container-first para substituí-lo em um mundo orquestrado por Kubernetes.
A inovação do Kafka:
O Kafka nasceu para resolver a necessidade do LinkedIn de um sistema de coleta de dados de baixa latência para os dados em tempo real gerados diariamente por mais de 675 milhões de usuários. Em 2010, quando o Kafka estava em desenvolvimento, a infraestrutura de dados do LinkedIn era monolítica, on-prem e baseada em Java. O Kafka herdou essas características, então, não importa em qual plataforma sua aplicação foi construída, você vai precisar de uma Java Virtual Machine (JVM) rodando na sua infraestrutura para usar o Kafka.
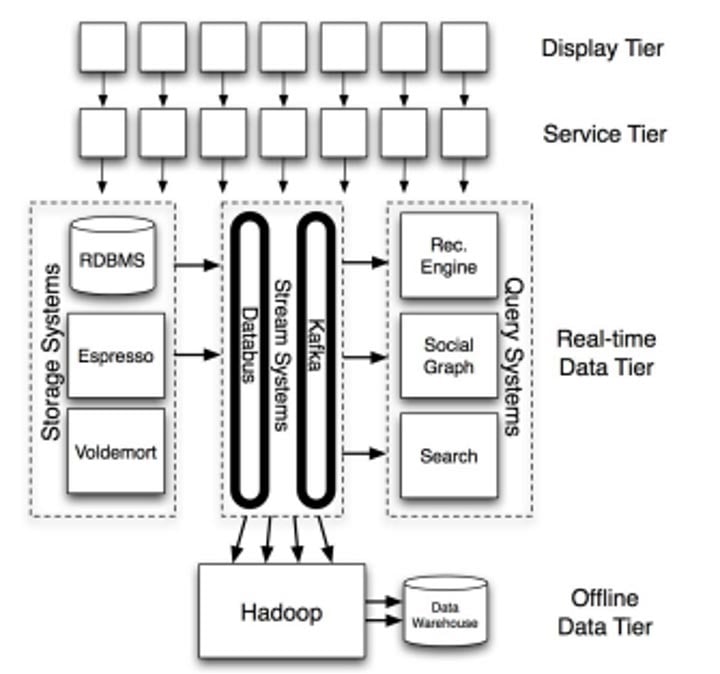
Uma visão geral em alto nível da arquitetura do LinkedIn, com foco nos sistemas centrais de dados.
Deploy do Kafka no Kubernetes:
Se você decidir migrar para o Kubernetes e escolher o Kafka como sistema de mensageria, estes são os requisitos:
- O orquestrador Zookeeper, responsável por gerenciar brokers e tópicos do Kafka, é obrigatório ao criar um cluster K8 com Kafka. Ou seja, um único container ocupa 600 MB para o Kafka e 100 MB para o Zookeeper.
- O desempenho do Kafka depende de uma rede de baixa latência e alta largura de banda. Quanto aos brokers, não tente colocar todos em um único nó, pois isso reduz a disponibilidade. Distribuir entre diferentes zonas de disponibilidade é um trade-off aceitável.
- Se o armazenamento do container não for persistente, os dados serão perdidos depois de um restart. O EmptyDir é usado para os dados do Kafka e mantém os dados se o container reiniciar. Assim, quando o container sobe, o broker que falhou precisa primeiro replicar todos os dados — um processo demorado. Por isso, o ideal é usar um volume de persistência, e o armazenamento precisa ser não local para que o Kubernetes tenha mais flexibilidade ao escolher outro nó depois de um restart ou realocação.
- O Kafka foi escrito em Java e Scala, então sua equipe precisa ter alguém com bastante experiência nas duas linguagens para fazer tuning e debugging adequados.
- Por fim, você vai precisar de uma ferramenta de monitoramento de terceiros para acompanhar o desempenho do Kafka.
A inovação do KubeMQ:
O KubeMQ foi desenhado pensando em Kubernetes desde o início. Por padrão, ele já vem em um cluster pré-configurado. Seus maiores trunfos são ser stateless e ter facilidade de deploy e configuração para qualquer integrante do time de DevOps com experiência em Kubernetes.
Não é preciso ter especialista em Java ou Scala. O KubeMQ suporta todos os padrões de mensageria — síncrono e assíncrono — enquanto o Kafka só trabalha com padrões assíncronos.
O container do KubeMQ é superleve: tem apenas 30 MB, o que o torna um ótimo candidato para integrar a microsserviços. Pensado para Kubernetes, o KubeMQ é bastante flexível em todo tipo de ambiente: multi-cloud, híbrido ou single cloud. Veja abaixo algumas das suas principais vantagens.
- Deploy via Operator para operação completa do ciclo de vida
- Container Docker pequeno e leve, extremamente rápido (escrito em Go)
- Mensageria assíncrona e síncrona, com suporte aos modelos At Most Once Delivery e At Least Once Delivery
- Suporte a Queue durável baseada em FIFO, Publish-Subscribe Events, Publish-Subscribe com persistência (Events Store), RPC Command e padrões de mensageria Query
- Suporte aos protocolos de transporte gRPC, Rest e WebSocket, com TLS (modos RPC e Stream)
- Suporte a autorização e autenticação por controle de acesso
- Suporte a roteamento inteligente e tratamento de mensagens
- Sem necessidade de configurar message broker (filas, exchanges etc.)
- SDKs para .Net, Java, Python, Go e NodeJS
Deploy do KubeMQ no Kubernetes:
Estes são os passos para implantar o KubeMQ em um cluster Kubernetes:
kubectl apply -f https://deploy.kubemq.io/community
Pronto, é só isso. Para a documentação completa do KubeMQ, consulte a página de docs. O repositório git do KubeMQ está aqui. Não há requisitos especiais de rede, nem overhead de memória causado por containers grandes rodando JVM, e qualquer pessoa com noções básicas de DevOps consegue fazer o deploy. Containers Docker pequenos e leves combinados com um software escrito em Go fazem tudo rodar muito rápido.
Show, o KubeMQ é incrível. Mas eu já tenho um cluster Kafka rodando. E agora?
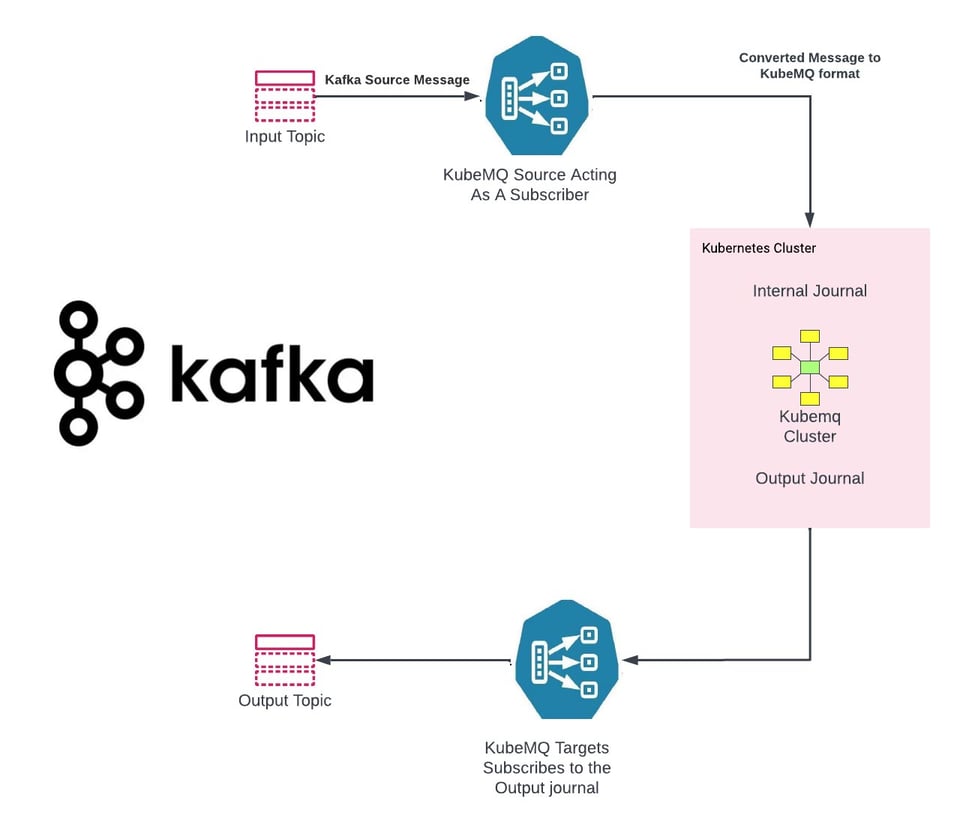
O KubeMQ desenvolveu conectores universais que facilitam a migração de sistemas legados para o KubeMQ:
KubeMQ Source - https://github.com/kubemq-io/kubemq-sources
KubeMQ Targets - https://github.com/kubemq-io/kubemq-targets
Exemplo de KubeMQ Source para Kafka - https://github.com/kubemq-io/kubemq-sources/blob/master/examples/messaging/kafka/main.go
Exemplo de KubeMQ Target para Kafka - https://github.com/kubemq-io/kubemq-targets/blob/master/examples/messaging/kafka/main.go
Para fechar
Na hora de escolher entre sistemas de mensageria stateless ou stateful para integrar à sua stack, vale sempre apostar nos stateless: menos dependências, processamento mais rápido e recuperação menos complexa quando o sistema de mensageria cai. Em testes de desempenho contra o Kafka, o KubeMQ entregou processamento de mensagens 20% mais rápido. A grande vantagem do KubeMQ é o suporte a Pub/Sub com ou sem persistência, Request/Reply (sync, async), at least once delivery, padrões de streaming e RPC. Você não fica preso só a padrões assíncronos, como acontece com o Kafka.
Se precisar de ajuda com isso ou com qualquer outro aspecto da sua infraestrutura na nuvem, fale com a DoiT International. Recém-eleita Google Cloud Sales Partner of the Year 2021, a DoiT oferece consultoria especializada e suporte ilimitado de nível mundial para clientes de todos os portes no Google Workspace e no Google Cloud Platform.