よりスケーラブルで信頼性が高く、機能豊富で保守しやすいメッセージング基盤への移行は、Kubernetes時代に理にかなった選択です。
KubeMQはKubernetes時代に最適化されたコンテナファーストのソリューション
Kafkaのように長年にわたり実績を積み重ねてきたメッセージング基盤を、いきなり手放すわけにはいきません。とはいえ、マイクロサービスベースのコンテナ化アーキテクチャを採用する企業が増える今、よりスケーラブルで信頼性が高く、機能豊富で保守しやすいメッセージング基盤への進化に踏み出すべき時期に来ています。
Gartnerの予測によると、2022年末までに世界の企業の75%がKubernetesとコンテナ化アプローチを活用して本番アプリケーションの管理・スケーリングを行うとされており、2019年のわずか30%から大きく伸びる見通しです。本記事で紹介するとおり、Kafkaはコンテナ化を前提に設計されているわけではなく、Kubernetes中心の世界ではKafkaに代わるコンテナファーストのソリューションが台頭してきています。
Kafkaの革新性
Kafkaはもともと、6億7,500万人を超えるLinkedInユーザーが日々生み出すリアルタイムデータを低レイテンシで収集するシステムとして開発されました。2010年の開発当時、LinkedInのデータ基盤はモノリシックでオンプレミス、Javaベースでした。Kafkaはこれらの特性をそのまま受け継いでいるため、アプリケーションがどのプラットフォーム上で動いていても、Kafkaを利用するならインフラ上でJava Virtual Machine(JVM)を稼働させる必要があります。
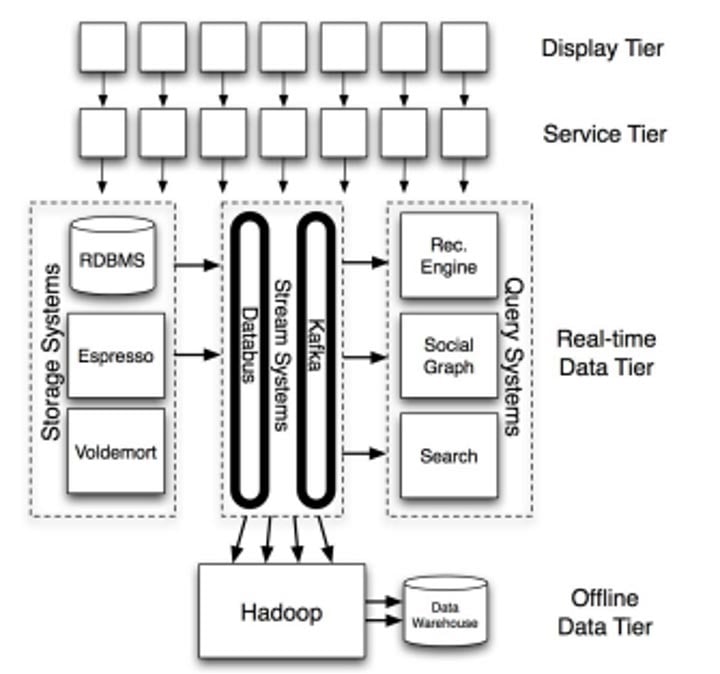
コアデータシステムを中心に据えた、LinkedInアーキテクチャの俯瞰図。
KafkaとKubernetesでのデプロイ
Kubernetesに移行し、メッセージング基盤としてKafkaを選ぶ場合の要件は次のとおりです。
- Kafkaを用いたK8sクラスタを構築する際、Kafkaブローカーやトピックを管理するためのZookeeperオーケストレーターが必須です。コンテナ1つあたりKafkaで600 MB、Zookeeperで100 MBの容量を要します。
- Kafkaのパフォーマンスは低レイテンシのネットワークと広い帯域に依存します。可用性を損なうため、すべてのブローカーを単一ノードに集約するのは避けましょう。アベイラビリティゾーンを分散させるのは妥当なトレードオフです。
- コンテナ内のストレージが永続的でなければ、再起動時にデータが失われます。KafkaのデータにはEmptyDirが使われ、コンテナの再起動時にも保持されます。とはいえコンテナ起動時に、障害の発生したブローカーがまずすべてのデータを複製する必要があり、これには時間がかかります。そのため永続ボリュームを利用し、再起動や再配置の際にKubernetesが別ノードを柔軟に選べるよう、ストレージはローカル外に置く必要があります。
- KafkaはJavaとScalaで書かれているため、適切なチューニングとデバッグには、JavaとScalaの双方に十分な経験を持つメンバーがチームに必要です。
- さらに、Kafkaのパフォーマンスを追跡・監視するためのサードパーティ製モニタリングツールも欠かせません。
KubeMQの革新性
KubeMQはKubernetesを前提に設計されており、デフォルトで構成済みクラスタとして提供されます。最大の強みはステートレスであること、そしてKubernetesの経験があるDevOpsチームメンバーであれば誰でも簡単にデプロイ・設定できる点です。
JavaやScalaの専門スキルは不要です。Kafkaが非同期メッセージングパターンしかサポートしないのに対し、KubeMQは同期・非同期を含むあらゆるメッセージングパターンに対応します。
KubeMQのコンテナはわずか30 MBと非常に軽量で、マイクロサービスへの組み込みに最適です。Kubernetesを前提に作られているため、マルチクラウド、ハイブリッド、シングルクラウドといったあらゆる環境にも柔軟に対応します。主な利点は次のとおりです。
- Operatorによってデプロイされ、ライフサイクル全体の運用に対応
- Goで実装された、超高速かつコンパクトで軽量なDockerコンテナ
- 非同期・同期メッセージングに対応し、At Most Once DeliveryとAt Least Once Deliveryの両モデルをサポート
- 永続的なFIFOキュー、Publish-Subscribeイベント、永続化付きPublish-Subscribe(Events Store)、RPCコマンド・クエリの各メッセージングパターンに対応
- gRPC、REST、WebSocketのトランスポートプロトコルに対応し、TLSもサポート(RPCモードとStreamモードの両方)
- アクセス制御による認可・認証に対応
- メッセージの分割処理とスマートルーティングに対応
- メッセージブローカーの設定(キューやエクスチェンジ等)が不要
- .Net、Java、Python、Go、NodeJS向けのSDKを提供
KubeMQとKubernetesでのデプロイ
KubernetesクラスタにKubeMQをデプロイする手順は次のとおりです。
kubectl apply -f https://deploy.kubemq.io/community
これで完了です。KubeMQの詳細なドキュメントはこちらをご覧ください。KubeMQのGitリポジトリはこちらから確認できます。特別なネットワーク要件はなく、JVMを稼働させる大きなコンテナによるメモリオーバーヘッドもありません。基本的なDevOpsの知識があれば誰でもデプロイ可能です。Goで書かれたソフトウェアと小さく軽量なDockerコンテナの組み合わせが、圧倒的な速度を生み出します。
KubeMQが素晴らしいのは分かった。でも、すでにKafkaクラスタを運用中ならどうすれば?
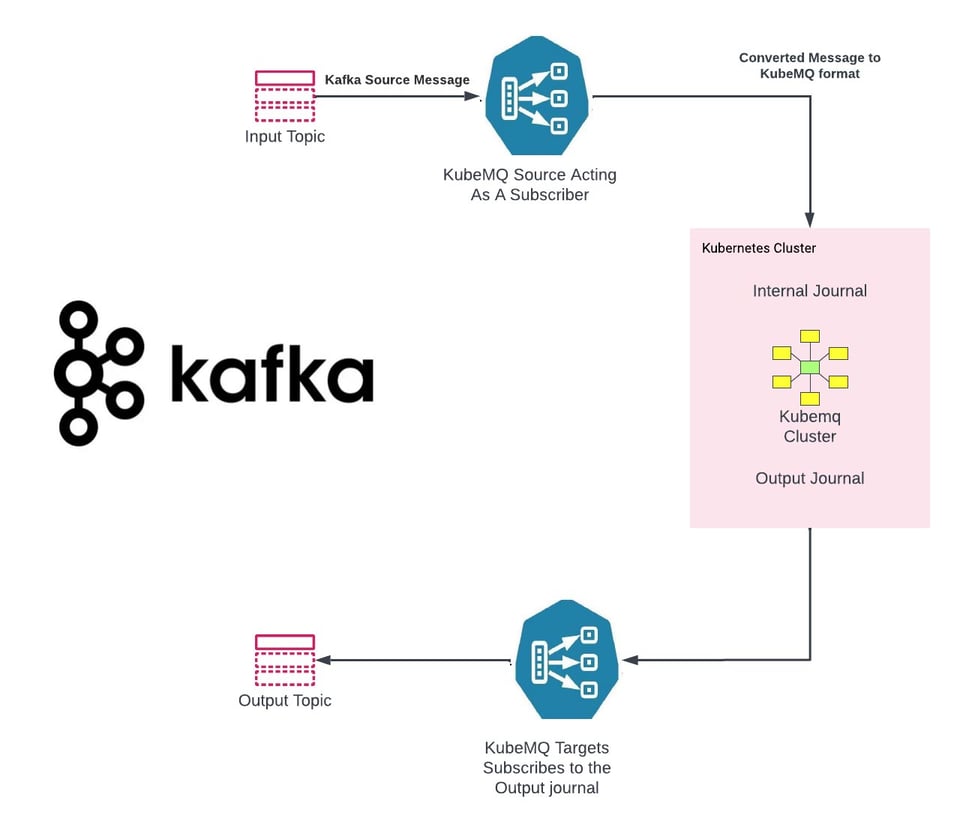
KubeMQでは、レガシーシステムからの移行を容易にする汎用コネクタを提供しています。
KubeMQ Source - https://github.com/kubemq-io/kubemq-sources
KubeMQ Targets - https://github.com/kubemq-io/kubemq-targets
Kafka向けKubeMQ Sourceの例 - https://github.com/kubemq-io/kubemq-sources/blob/master/examples/messaging/kafka/main.go
Kafka向けKubeMQ Targetの例 - https://github.com/kubemq-io/kubemq-targets/blob/master/examples/messaging/kafka/main.go
まとめ
スタックに組み込むメッセージング基盤をステートレス型かステートフル型かで迷ったときは、依存関係が少なく、処理が高速で、クラッシュからの復旧もシンプルなステートレス型を選ぶのが鉄則です。Kafkaとのパフォーマンス比較では、KubeMQはメッセージ処理速度が20%高速という結果を出しています。KubeMQ最大の利点は、永続化の有無を問わないPub/Sub、Request/Reply(同期・非同期)、At Least Once Delivery、ストリーミング、RPCといった幅広いパターンをサポートしている点にあります。Kafkaのように非同期パターンに縛られることはありません。
本件に限らず、クラウドインフラのあらゆる側面でサポートが必要な場合は、ぜひDoiT Internationalにご相談ください。2021 Google Cloud Sales Partner of the Yearに選出された当社は、Google WorkspaceおよびGoogle Cloud Platformにおいて、あらゆる規模のお客様に専門的なコンサルティングと無制限のワールドクラスサポートを提供しています。