
Les GPU sont devenus incontournables dans le cloud moderne. Avec l'adoption croissante de l'IA, du machine learning et des grands modèles de langage (LLM) pour faire évoluer les applications, leur utilisation explose, tout comme les coûts cloud Kubernetes nécessaires pour faire tourner ces workloads. Cette dynamique ajoute une nouvelle couche de complexité à la gestion des ressources Kubernetes : l'optimisation de l'utilisation des GPU.
" Contrairement aux autres ressources Kubernetes, les requêtes GPU obéissent à une logique particulière : un pod accède soit à un GPU entier, soit à rien. Sans allocation fractionnée, les GPU sont souvent sous-utilisés, ce qui génère du gaspillage. Comme ils peuvent représenter jusqu'à 75 % des coûts horaires d'infrastructure, la moindre inefficacité se traduit par une perte financière considérable. Éliminer la sur-allocation peut donc avoir un impact majeur et débloquer des économies significatives ", explique Eli Birger, CTO de PerfectScale by DoiT. " Sans visibilité sur l'utilisation réelle des GPU, les Engineers ne disposent pas des informations nécessaires pour faire du right-sizing sur les workloads, mettre en place des stratégies avancées d'ordonnancement de pods et prendre des décisions d'infrastructure fondées sur les données. "
Pour aider les équipes à relever ces défis, nous sommes ravis de présenter GPU Visibility de PerfectScale by DoiT — la fonctionnalité qui offre une vision claire de l'utilisation des GPU sur l'ensemble de vos clusters Kubernetes, pour identifier les inefficacités, ajuster vos workloads au plus juste et tirer pleinement parti de vos ressources GPU.
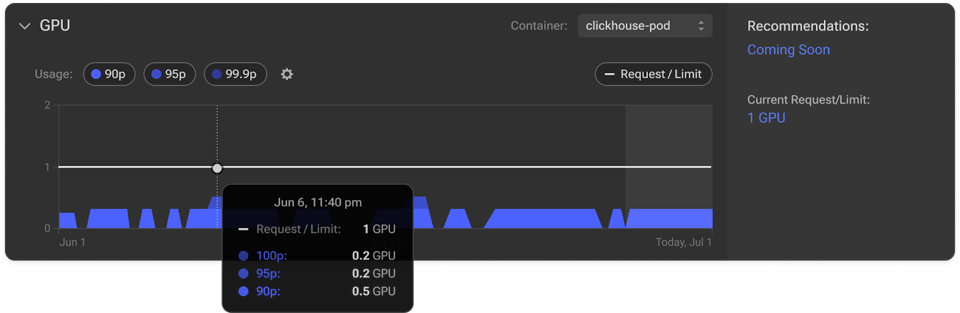
Voyons de plus près comment GPU Visibility révèle les inefficacités et simplifie l'optimisation de l'utilisation des GPU.
Que vous apporte GPU Visibility ?
La fonctionnalité GPU de PerfectScale collecte les métriques d'utilisation et offre une visibilité approfondie à l'échelle du cluster tout entier. Cette vue permet une analyse précise de l'environnement Kubernetes et ouvre la voie à une optimisation fiable, fondée sur les données.
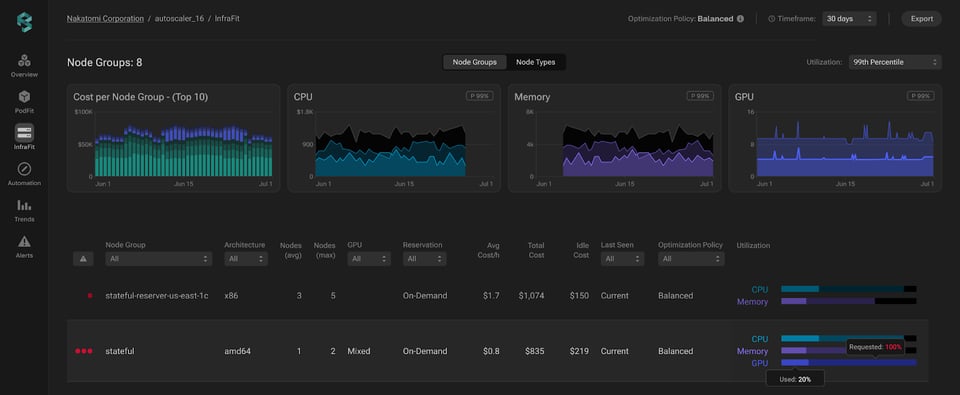
Rendez-vous sur Infrafit de PerfectScale pour accéder aux indicateurs détaillés d'utilisation GPU de vos node groups. Le graphique d'utilisation présente une répartition claire de la consommation et des requêtes GPU sur l'ensemble de l'infrastructure. Très utile pour repérer rapidement les capacités GPU sous-utilisées ou inactives, prioriser les efforts d'optimisation sur les zones les plus critiques, réduire le gaspillage et améliorer le rapport coût-efficacité global.
Une fois une zone problématique identifiée, il suffit de cliquer sur le node group correspondant pour ouvrir une vue d'infrastructure plus détaillée. Ce niveau de granularité offre une décomposition complète des instances du groupe, accompagnée des métriques clés pour chacune.
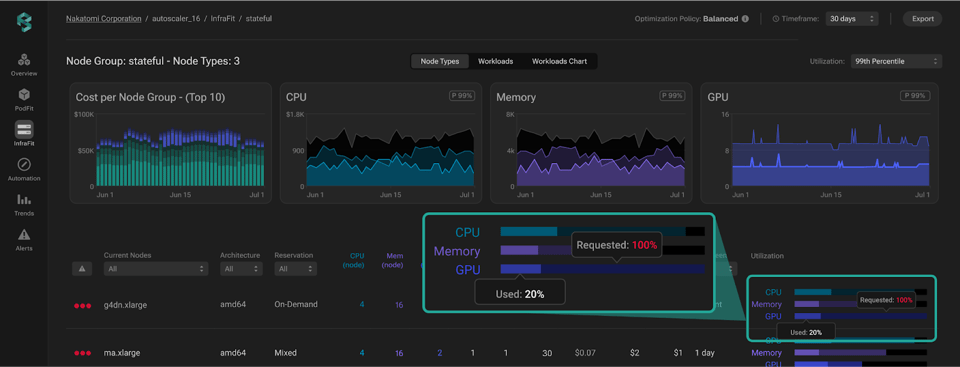
Une fois le problème détecté, reste à décider comment le résoudre. La plateforme vous aide à comprendre l'origine du dysfonctionnement (GPU partiellement utilisés, workloads sur-provisionnés ou instances qui tournent à vide) et à choisir la bonne stratégie pour y remédier. Vous pouvez par exemple ajuster la taille des instances pour mieux les adapter au workload, équilibrer la charge et améliorer le bin-packing, ou éteindre les instances inutiles.
Cas d'usage concrets
Right-sizing des instances GPU
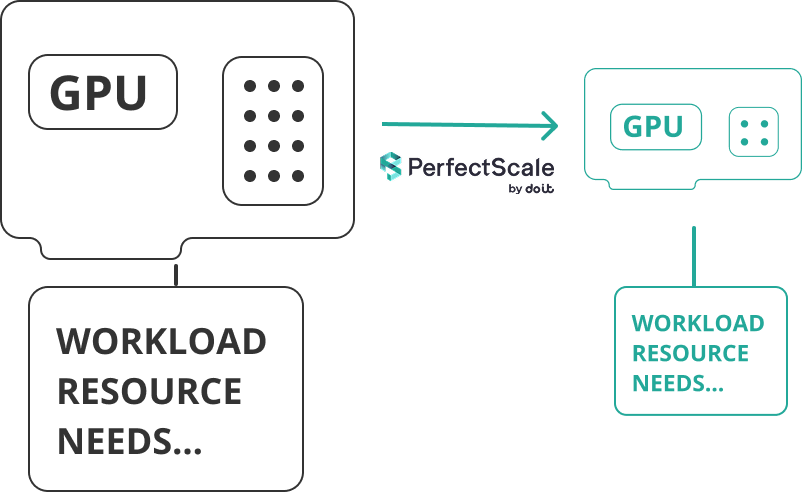
Souvent, les workloads n'ont pas besoin de toute la capacité de la machine GPU. En identifiant les instances sous-utilisées, vous pouvez remplacer les plus coûteuses par des alternatives plus petites et plus économiques, mieux adaptées à la tâche. Résultat : moins de dépenses inutiles, sans compromis sur les performances.
Pour décider en toute confiance sur la base des données, appuyez-vous directement sur la visibilité GPU de PerfectScale et repérez les cas où cet ajustement a le plus d'impact.
Maximiser l'utilisation grâce au GPU splitting
Passer à des instances GPU plus petites est souvent un excellent moyen de réduire les coûts, mais ce n'est pas toujours l'approche la plus pertinente ni la plus efficace.
Certains workloads — les pipelines ML partagés, par exemple — se prêtent mal à la répartition entre plusieurs machines et exigent un contrôle plus fin des ressources. Dans ces situations, des instances plus petites ne suffisent pas à atteindre le niveau de performance, d'efficacité ou de flexibilité recherché.
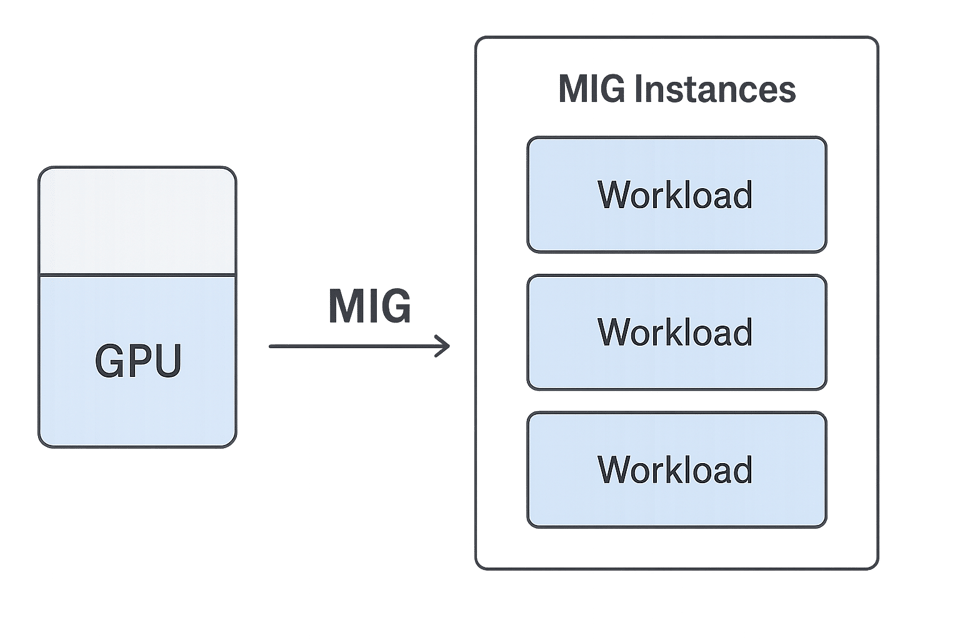
C'est là que le Multi-Instance GPU (MIG) de NVIDIA entre en jeu. MIG permet de découper un GPU physique en plusieurs unités plus petites et isolées, chacune dotée de ses propres ressources de calcul, de mémoire et de bande passante. Elles se comportent comme des GPU distincts, ce qui permet d'exécuter en parallèle plusieurs petits jobs sans conflit.
PerfectScale facilite le repérage des GPU sous-utilisés qui exécutent des workloads ne nécessitant pas leur pleine capacité. Plutôt que de basculer vers une machine plus petite, vous pouvez conserver le GPU le plus puissant et le diviser en instances MIG, en adaptant chaque tranche aux besoins spécifiques du workload.
Gagner en efficacité avec KAI Scheduler
Certaines tâches n'ont pas besoin d'un GPU en permanence : workloads éphémères, jobs CI/CD ou étapes d'entraînement de modèles ponctuées de longues attentes CPU. Elles ne mobilisent le GPU que brièvement, et attribuer un GPU dédié à chacune représente un gaspillage considérable de ressources et d'argent.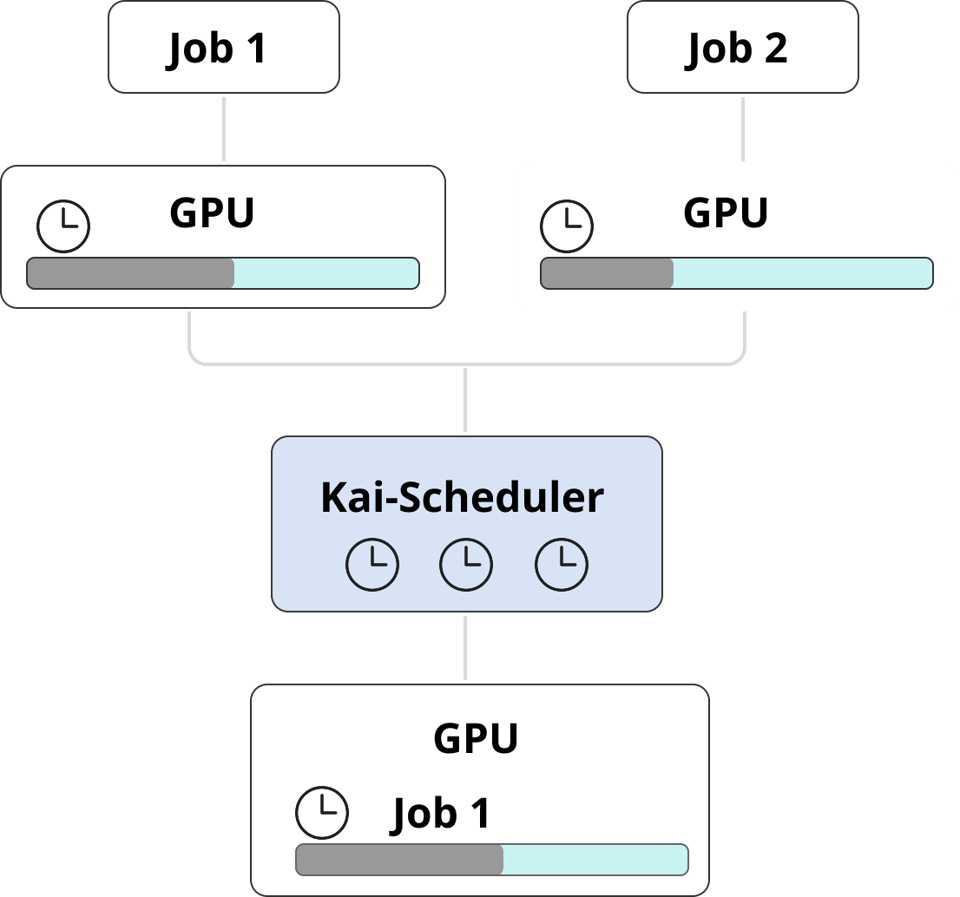
Avec la visibilité GPU de PerfectScale, vous repérez facilement ces schémas : des workloads qui n'exploitent pas pleinement le GPU qui leur est alloué. Une fois identifiés, déployez Kai-Scheduler pour consolider plusieurs jobs sur un seul GPU, maximiser l'utilisation et réduire les coûts sans sacrifier les performances.
Vous avez vu comment PerfectScale aide à révéler le gaspillage GPU et à appliquer des stratégies d'optimisation intelligentes. Place à l'action !
Approfondissez le sujet sur notre portail de documentation, ou planifiez une session technique avec notre équipe pour un accompagnement expert.
Vous n'utilisez pas encore PerfectScale ? Démarrez gratuitement dès aujourd'hui et simplifiez votre optimisation K8s.