
GPUは現代のクラウドインフラに欠かせない存在となりました。AI、機械学習、大規模言語モデル(LLM)を取り入れたアプリケーション開発が広がるにつれ、GPU使用量は急増し、それを支えるKubernetesのクラウドコストも膨らんでいます。この流れは、Kubernetesリソース管理に新たな複雑さをもたらしています。それがGPU使用率の最適化です。
「GPUリクエストは、他のKubernetesリソースとは扱いが大きく異なります。Podに割り当てられるのはGPU1基まるごとか、ゼロかのいずれかで、分割割り当てができないため、GPUは活用しきれず無駄が生じやすいのです。GPUは時間あたりインフラコストの最大75%を占めることもあり、わずかな非効率でも金銭的な損失は大きくなります。だからこそ、過剰割り当てを解消できれば、コスト削減のインパクトは絶大です」と、PerfectScale by DoiTのCTO、Eli Birger氏は語ります。「実際のGPU使用率が見えなければ、Engineersはworkloadsのright-sizing、高度なPodスケジューリング戦略の実装、データに基づくインフラ判断のいずれも進められません」
こうした課題に応えるべく、PerfectScale by DoiTから新機能GPU Visibilityを提供開始しました。Kubernetesクラスター全体のGPU使用状況を一目で把握でき、非効率の発見、workloadsのright-sizing、GPUリソースの最大活用までを後押しします。
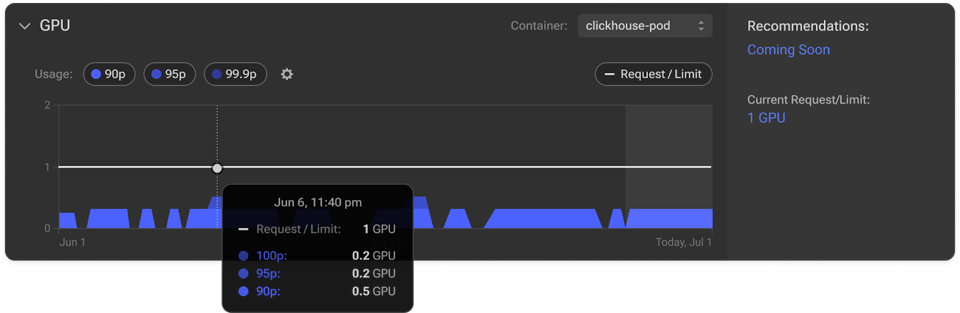
では、GPU Visibilityがどのように非効率を浮き彫りにし、GPU使用率の最適化を後押しするのか、具体的に見ていきましょう。
GPU Visibilityで何ができるのか
PerfectScaleのGPU機能は、GPU使用率のメトリクスを収集し、クラスター全体の文脈の中で深い可視性をもたらす強力なソリューションです。Kubernetes環境を精緻に分析し、データに基づいた的確な最適化を実現します。
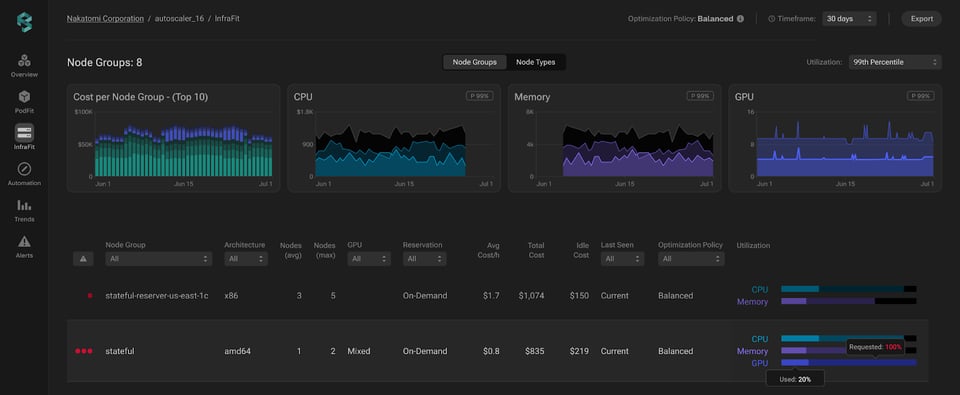
PerfectScaleのInfrafitを開けば、ノードグループごとのGPU使用率を詳細に確認できます。使用率チャートでは、インフラ全体のGPU使用量とリクエスト量がひと目で把握でき、活用しきれていないGPUやアイドル状態のキャパシティを素早く特定できます。重要度の高い領域から最適化に着手することで、GPUの無駄を減らし、コスト効率を底上げできます。
気になる領域を見つけたら、該当のノードグループをクリックするだけで、より詳細なインフラビューにドリルダウンできます。グループ内の個々のインスタンスの内訳と主要メトリクスがまとめて確認でき、原因の特定がスムーズです。
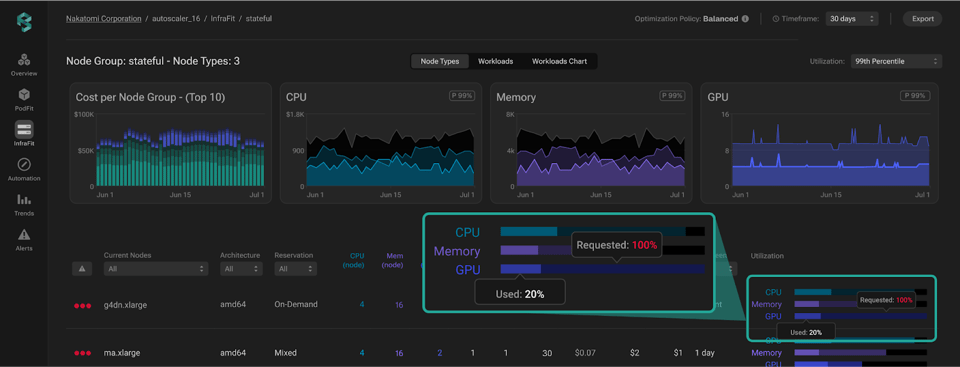
課題が見つかったら、次は対処方針を決める番です。本プラットフォームは、何が起きているのか(GPUを使い切れていない、必要以上のリソースが割り当てられたworkloadsがある、ほとんど稼働していないインスタンスがある、など)を整理し、最適な解決策を選ぶ判断材料を提供します。たとえば、workloadsに合わせてインスタンスをright-sizingする、負荷を平準化してビンパッキングを改善する、不要なインスタンスを停止する、といった手立てが考えられます。
活用シナリオ
GPUインスタンスのright-sizing
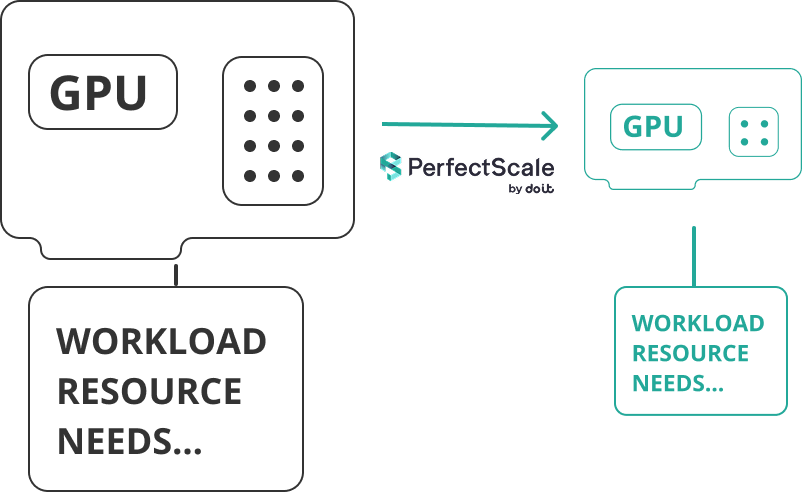
workloadsの多くは、GPUマシンの全容量までは必要としません。活用しきれていないインスタンスを見極めれば、高価なインスタンスを、用途に見合った小型でコスト効率の高いインスタンスへ置き換えられます。パフォーマンス要件を維持したまま、無駄な支出を抑えられます。
PerfectScaleのGPU Visibilityを使えば、調整効果が最も大きい箇所を見極め、データに裏付けされた判断ができます。
GPU分割で使用率を最大化
小型のGPUインスタンスへの切り替えはコスト削減に有効ですが、いつでも最善とは限りません。
たとえば共有MLパイプラインのように、複数マシンに分けるとスケールしづらく、よりきめ細かなリソース制御が求められるworkloadsもあります。こうしたケースでは、小型インスタンスだけでは期待するパフォーマンスや効率、柔軟性が得られないことがあります。
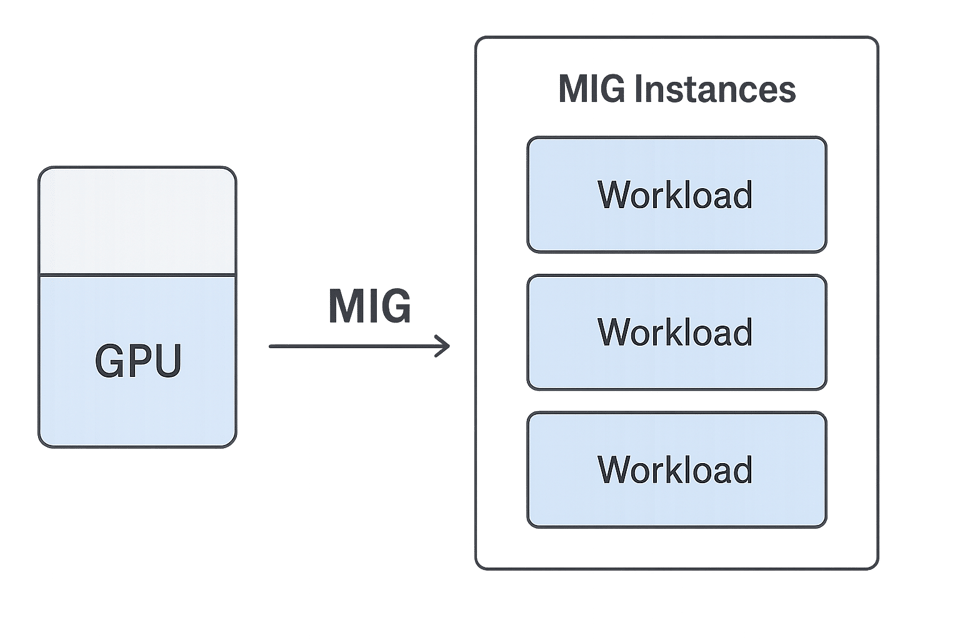
そこで有効なのが、NVIDIAのMulti-Instance GPU(MIG)です。MIGを使えば、1基の物理GPUを複数の小さな独立ユニットに分割でき、それぞれに専用の演算リソース、メモリ、帯域が割り当てられます。各ユニットは独立したGPUのようにふるまうため、小規模ジョブや並列ジョブを競合させずに同時実行できます。
PerfectScaleなら、フル容量を必要としないworkloadsを抱える、活用しきれていないGPUを簡単に見つけられます。小型マシンに乗り換えるのではなく、大型GPUをそのまま残してMIGインスタンスに分割し、各スライスをworkloadsの要件に合わせて割り当てるという選択肢が取れます。
KAI Schedulerで効率を高める
GPUを常時必要としないタスクもあります。たとえば、エフェメラルなworkloads、CI/CDジョブ、CPU待ちが長いモデル学習ステップなどです。これらは短時間しかGPUを使わないため、ジョブごとに専用GPUを充てるのはリソースとコストの大きな浪費につながります。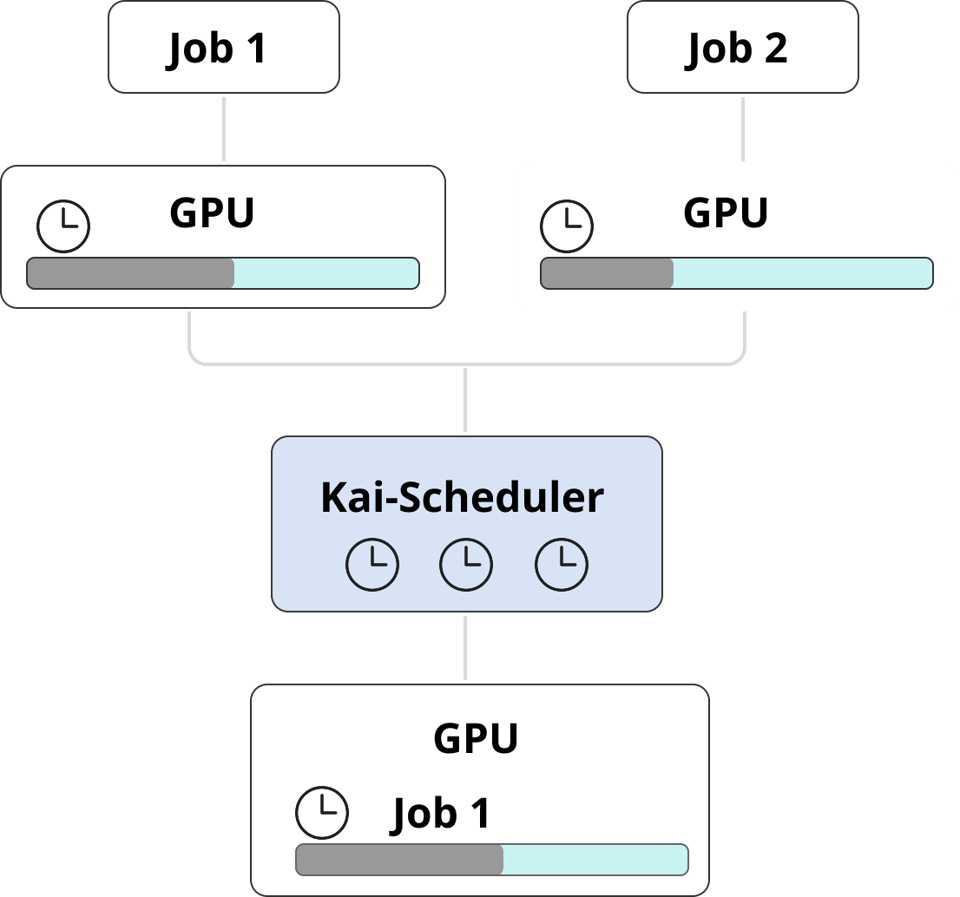
PerfectScaleのGPU Visibilityなら、割り当てたGPUを使い切っていないworkloadsといったパターンを簡単に見つけ出せます。そこからKai-Schedulerを導入すれば、複数のジョブを1基のGPUに集約でき、パフォーマンスを損なわずに使用率を最大化し、コストを抑えられます。
ここまで、PerfectScaleがGPUの無駄を可視化し、最適化戦略の実行を後押しする様子をご紹介しました。あとは、得られた知見を実践に移すだけです。
詳細はドキュメントポータルをご覧ください。専門家のサポートが必要であれば、テクニカルセッションをご予約いただけます。
PerfectScaleをまだお使いでない方へ。 今すぐ無料でスタート。K8s最適化への第一歩をシンプルに踏み出せます。