
Le GPU sono ormai parte integrante dell'infrastruttura cloud moderna. Con la crescente adozione di AI, machine learning e large language model (LLM) per far evolvere le applicazioni, l'utilizzo delle GPU cresce rapidamente, e con esso i costi cloud Kubernetes per sostenere questi workloads. Una tendenza che aggiunge un ulteriore livello di complessità alla gestione delle risorse Kubernetes: l'ottimizzazione dell'utilizzo delle GPU.
"A differenza di altre risorse Kubernetes, le richieste di GPU vengono gestite in modo diverso: un pod ottiene l'accesso a un'intera GPU oppure non ne ottiene affatto. In assenza di allocazione frazionata, le GPU restano spesso sottoutilizzate, generando spreco. Considerando che le GPU possono incidere fino al 75% sui costi orari di infrastruttura, qualsiasi inefficienza si traduce in uno spreco economico rilevante. Eliminare la sovra-allocazione può quindi avere un impatto enorme e sbloccare risparmi consistenti," ha dichiarato Eli Birger, CTO di PerfectScale by DoiT. "Senza visibilità sull'effettivo utilizzo delle GPU, gli engineer non dispongono degli insight necessari per fare il right-sizing dei workloads, adottare strategie avanzate di pod scheduling e prendere decisioni infrastrutturali basate sui dati."
Per aiutare i team ad affrontare queste sfide, siamo lieti di presentare GPU Visibility di PerfectScale by DoiT: la funzionalità che offre un quadro chiaro dell'utilizzo delle GPU sui suoi cluster Kubernetes e le permette di individuare le inefficienze, fare il right-sizing dei workloads e sfruttare appieno le sue risorse GPU.
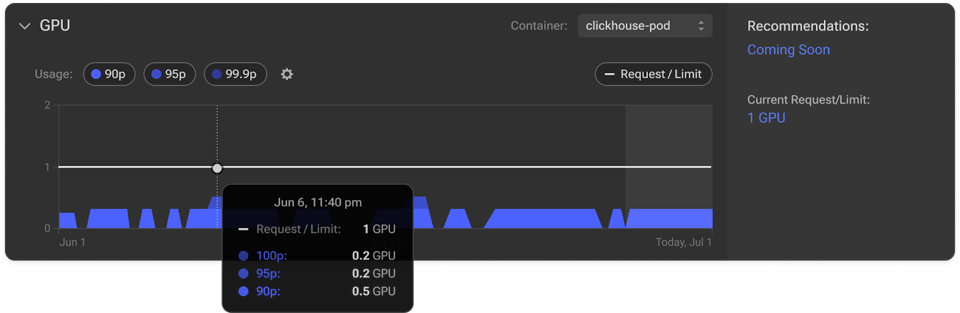
Vediamo da vicino come GPU Visibility aiuta a far emergere le inefficienze e a ottimizzare con facilità l'utilizzo delle GPU.
Cosa offre GPU Visibility?
La funzionalità GPU di PerfectScale è una soluzione potente che raccoglie le metriche di utilizzo delle GPU e offre una visibilità approfondita nel contesto dell'intero cluster. Questa vista consente un'analisi puntuale dell'ambiente Kubernetes, abilitando un'ottimizzazione precisa e guidata dai dati.
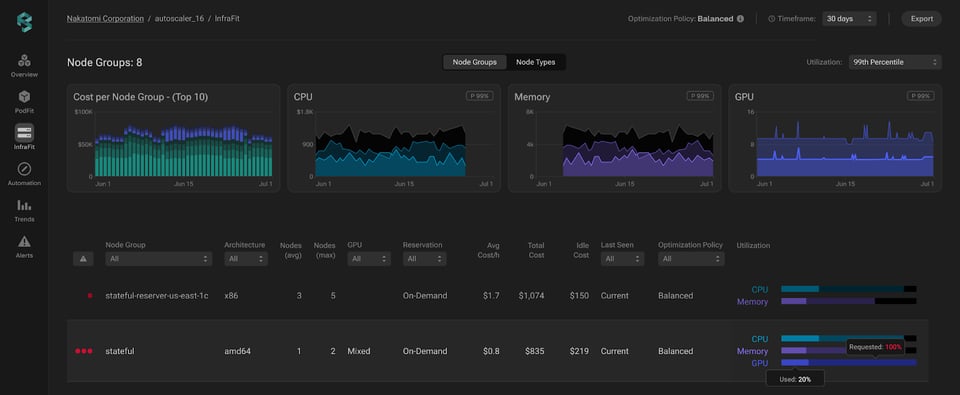
Acceda a Infrafit di PerfectScale per consultare gli insight dettagliati sull'utilizzo delle GPU dei suoi node group. Il grafico di utilizzo offre una panoramica chiara dell'uso delle GPU e delle relative richieste su tutta l'infrastruttura. È una vista particolarmente utile per individuare rapidamente la capacità GPU sottoutilizzata o inattiva, dare priorità agli interventi di ottimizzazione sulle aree più critiche, ridurre lo spreco di GPU e migliorare l'efficienza complessiva dei costi.
Una volta individuata un'area problematica, basta un clic sul node group corrispondente per accedere a una vista infrastrutturale più di dettaglio. Questo livello di granularità offre una panoramica completa delle singole istanze del gruppo, con le metriche chiave per ciascuna di esse.
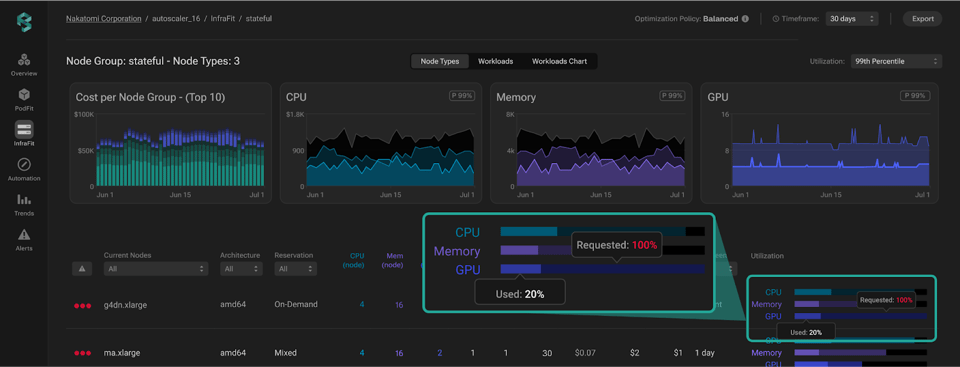
Una volta individuato il problema grazie alla visibilità offerta, il passo successivo è decidere come risolverlo. La piattaforma la aiuta a capire cosa non funziona (GPU non sfruttate al massimo, workloads provisionati con più risorse del necessario o istanze attive senza un reale carico di lavoro) e a scegliere la strategia giusta. Per esempio, può fare il right-sizing delle istanze per adattarle meglio al workload, bilanciare il carico e migliorare il bin-packing oppure spegnere le istanze non necessarie.
Scenari d'uso
Right-sizing delle istanze GPU
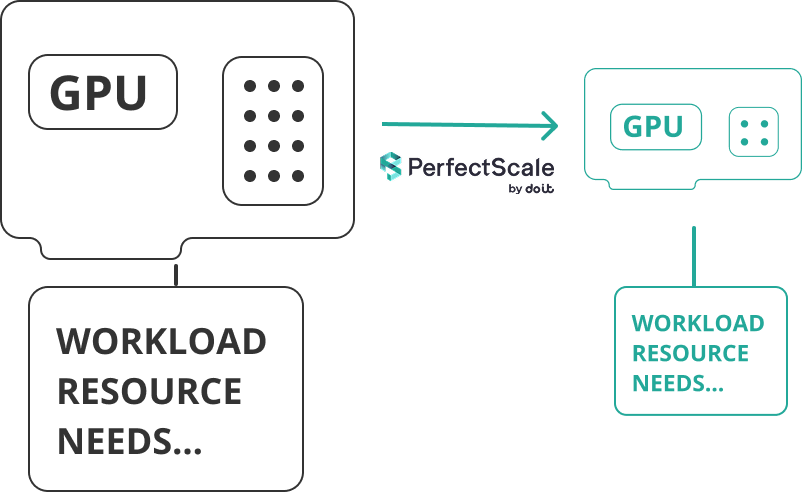
In molti casi, i workloads non richiedono l'intera capacità della macchina GPU. Identificando le istanze sottoutilizzate, può sostituire quelle più costose con alternative più piccole ed economiche, meglio dimensionate per l'attività. Una scelta che riduce la spesa superflua senza compromettere i requisiti di performance.
Per prendere decisioni sicure e guidate dai dati, può sfruttare la GPU visibility di PerfectScale e capire dove questo intervento ha davvero senso.
Massimizzare l'utilizzo con il GPU splitting
Passare a istanze GPU più piccole è spesso un ottimo modo per ridurre i costi, ma non sempre è l'approccio migliore o più efficace.
Alcuni workloads, come ad esempio le pipeline ML condivise, non scalano bene se distribuiti su macchine separate e possono richiedere un controllo più stringente delle risorse. In questi casi, le istanze più piccole da sole potrebbero non garantire le performance, l'efficienza o la flessibilità necessarie.
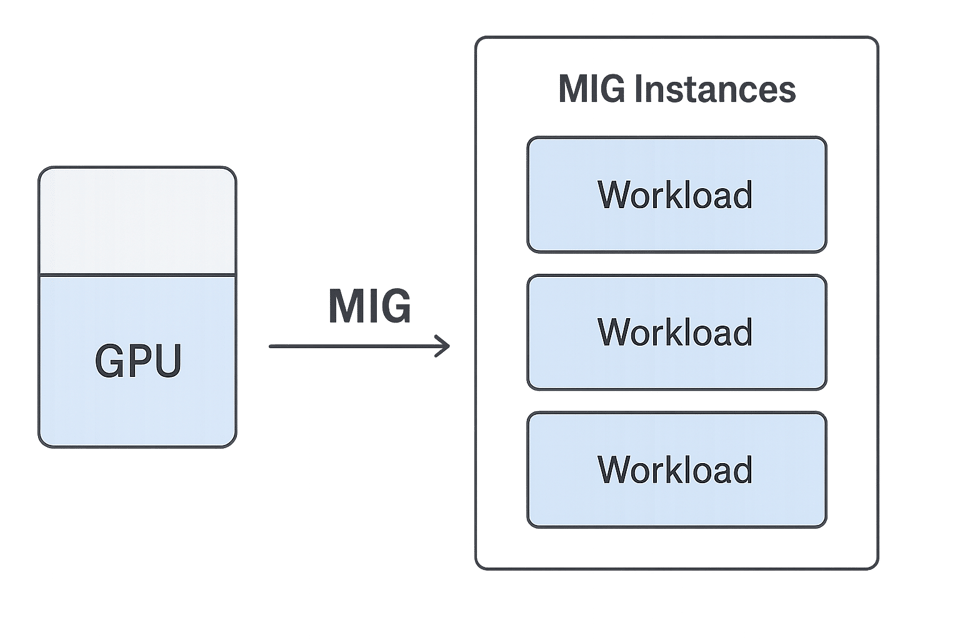
È qui che la Multi-Instance GPU (MIG) di NVIDIA può fare la differenza. MIG consente di suddividere una singola GPU fisica in più unità isolate e di dimensioni ridotte, ciascuna con capacità di calcolo, memoria e larghezza di banda dedicate. Queste porzioni si comportano come GPU indipendenti, permettendole di eseguire in parallelo più job piccoli senza conflitti.
PerfectScale rende semplice individuare le GPU sottoutilizzate che eseguono workloads non in grado di sfruttarne l'intera capacità. Invece di passare a una macchina più piccola, può mantenere la GPU più grande e suddividerla in istanze MIG, calibrando ciascuna porzione sulle esigenze specifiche del workload.
Aumentare l'efficienza con KAI Scheduler
Alcune attività non hanno bisogno di una GPU in modo continuativo: pensi ad esempio ai workloads effimeri, ai job CI/CD o alle fasi di training di un modello con lunghe attese sulla CPU. Queste utilizzano la GPU solo per brevi periodi e assegnare a ciascun job una GPU dedicata significa sprecare risorse e denaro in modo significativo.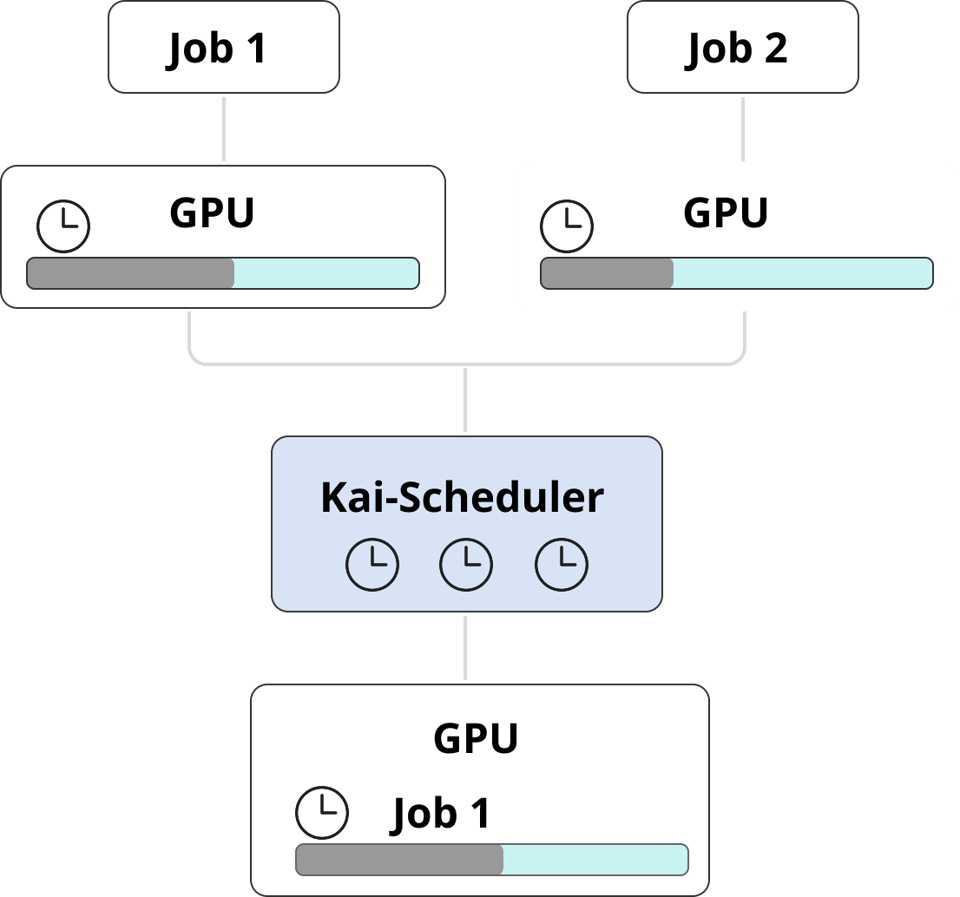
Con la GPU visibility di PerfectScale, può individuare facilmente pattern come quello dei workloads che non sfruttano appieno la GPU assegnata. Una volta identificati, può adottare Kai-Scheduler per consolidare più job su un'unica GPU, massimizzandone l'utilizzo e riducendo i costi senza rinunciare alle performance.
Ha visto come PerfectScale aiuta a scoprire lo spreco di GPU e ad applicare strategie di ottimizzazione intelligenti. Ora è il momento di tradurre questi insight in azione!
Approfondisca sul nostro Documentation Portal oppure prenoti una sessione tecnica con il nostro team per ricevere assistenza specializzata.
Non usa ancora PerfectScale? Inizi gratis oggi e semplifichi il suo percorso di ottimizzazione K8s.